
Generative Adversarial Text to Image Synthesis
ICML 2016
摘要:本文将文本和图像练习起来,根据文本生成图像,结合 CNN 和 GAN 来有效的进行无监督学习。
Attribute Representation: 是一个非常具有意思的方向。由图像到文本,可以看做是一个识别问题;从文本到图像,则不是那么简单。
因为需要解决这两个小问题:
1. learning a text feature representation that captures the important visual deatails ;
2. use these features to synthesize a compelling image that a human might mistake for real.
幸运的是,深度学习对这两个问题都有了较好的解决方案,即:自然语言表示 和 image synthesis 。
但是,仍然存在的一个问题是:the distribution of images conditioned on a text description is highly multimodal,in the sense that there are very many plausible configurations of pixels that correctly illustrate the description.

Background :
1. GANs.
此处略,参考相关博客。
2. Deep symmetric structured joint embedding.
为了得到一个视觉上可以判别的文本表示(text description),我们采用了一个 CVPR 2016 的一篇文章,利用 CNN 和 recurrent text encoder 根据一张 Image 学一个对应的函数。这个 text classifier 是通过以下的 structure loss 进行训练:
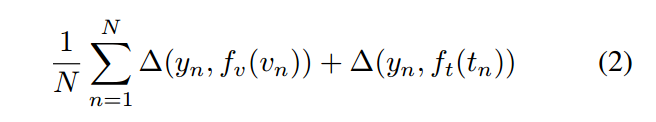
其中,$\{ v_n, t_n, y_n \}$ 是训练数据集合, $\delta$ 是 0-1 loss,$v_n$ 是image,$t_n$ 是 text description,$y_n$ 是class label。
分类器 $f_t$, $f_v$ 参数化如下:

其中,一个是 image encoder,一个是 text encoder。当一张图像有了其类别信息的时候,文本的编码应该有更高的兼容性得分,反之亦然。(The intuition here is that a text encoding should have a higher compatibility score with image of the corresponding class and vice-versa。)
Method :
我们的方法是为了基于text feature,训练一个深度卷积产生式对抗网络 (DC-GAN)。
1. Network architecture .
基本概念:产生器 G ;判别器 D ;
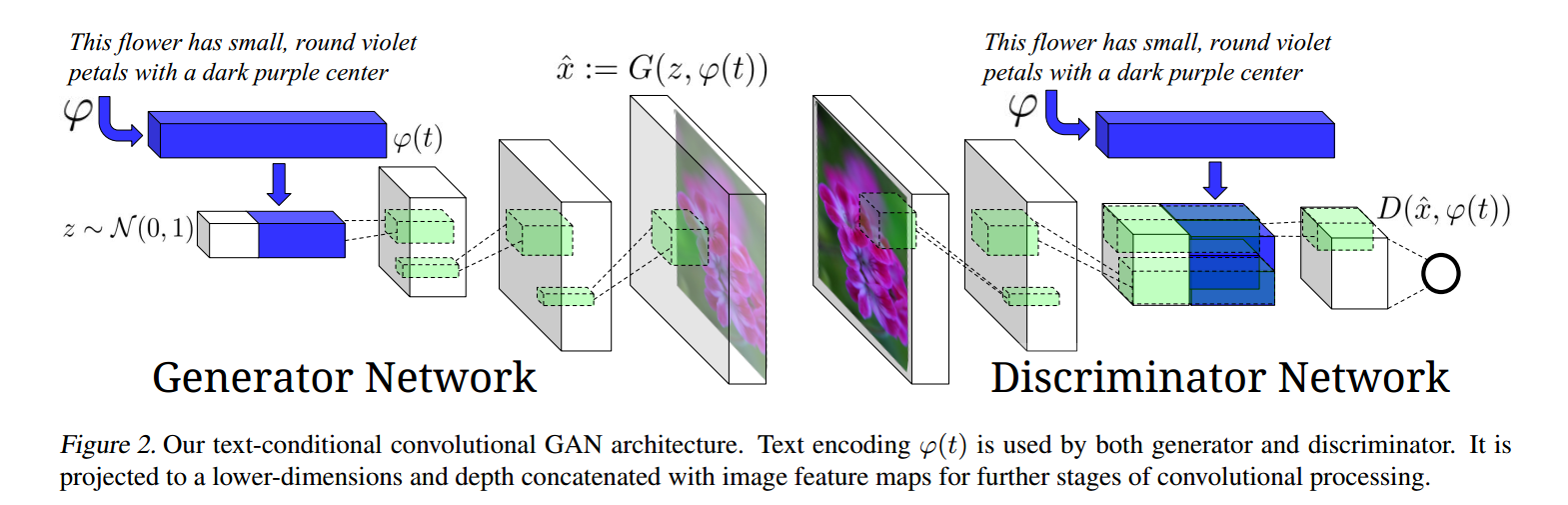
以上,就是本文提出的整个网络框架。
首先看产生器 G,将文本信息经过预处理得到其特征表达,然后将其和 noise vector 组合在一起,输入到接下来的反卷积网络中,最终生成一幅图像;
再看判别器,将图像进行卷积操作后,我们将本文信息在 depth 方向上组合原本图像卷积得到的feature 上,然后得到一个二元值。
2. Matching-aware discriminator (GAN-CLS) :
最直接的方法进行 conditional GAN 的训练是将 pairs (text, image) 看做是一个联合的观察(Joint Observations),然后训练判别器来判断这个 pair 是 real or false。这种条件是 naive 的,当处于 the discriminator 没有明显的 notion 是否 real training images match the text embedding context。
在 naive GAN,the discriminator 观察到两种输入:real image 和 匹配的 text;以及 synthetic images 和 随意的 text。所以,必须显示的将两种 errors 分开:
unrealistic images (for any text), and realistic images of the wrong class that mismatch the conditioning information。
基于这可能会增加了学习 dynamics 的复杂性,我们修改了 GAN 训练来分开这些 error source。
除了在训练阶段,提供 real / fake inputs 给 discriminator 之外,我们增添了第三种输入,即:real images with mismatched text,which the discriminator must learn to score as fake。通过学习 image / text 的 matching,还要学习 image realism (图像的真实性),判别器可以提供额外的信息给产生器(the discriminator can provide an additional signal to the generator)。
算法 1 总结了训练的过程。

3. Learning with manifold interpolation (GAN-INT) 流型插值
Deep network have been shown to learn representations in which interpolations between embedding pairs tend to be near the data manifold.
深度学习发现当接近数据流型的数据对之间进行插值 来学习表示。
受到这个发现的启发:我们可以产生一个 large amount of additional text embeddings by simply interpolating between embeddings of training set captions。
关键是,这些插值的 text embeddings 不需要对应上任何真实的 human-written text,所以,不需要额外的 labeling cost。
这个就可以看做是:在产生器的目标中增加一个额外的项:

由于插值的 embeddings 是伪造的,判别器并没有对应的 image and text pairs 来进行训练。但是,D 学习到了是否当前 image 和 text 相匹配。
4. Inverting the generator for style transfer.
如果 text encoding 可捕获图像的 content,比如:flower shape 和 colors,然后 为了保证一个真实的图像,the noise sample Z 应该可以捕获 style factors,如:背景颜色和姿态。有了一个 trained GAN,我们可能希望转换一个图像的类型,根据特定的文本描述的内容。为了达到这个目的,我们可以训练一个 CNN 来翻转 G 以使得从样本进行回归 到 Z。我们利用一个简单的 squared loss 来训练 style encoder:
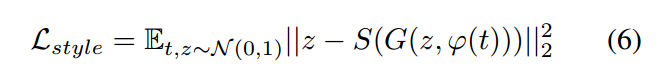
其中,S 是 style encoder network。有了训练的产生器 和 类型编码,style transfer 根据样本 t 从一张 query image x 执行下列步骤:

其中, x 是结果图像, s 是预测的 style。
Experiments .

