
- 1Explain 关键字_explain关键字
- 2顺序表中的基本操作(详细代码图解+注释+算法步骤)_顺序表的基本操作代码
- 3meterpreter使用详解_meterpreter gettid
- 4单片机和嵌入式的异同_与单片机相比嵌入式的相同点
- 5万字长文解读最新最全的大数据技术体系图谱!
- 6访问网站显示不安全是什么原因?怎么解决?_为什么访问一个网站会显示不是安全链接
- 7Springboot计算机毕业设计基于标签电影推荐微信小程序【附源码】开题+论文+mysql+程序+部署_基于springboot影视分享
- 8NLP自然语言处理中oov的词的解释_nlp oov
- 9芯片设计围炉札记
- 10李善友《第一性原理》读后感-总结_第一性原理心得体会
通义千问 - Code Qwen能力算法赛道季军方案
赞
踩
在23年最后一月,我们团队VScode参加了天池通义千问AI挑战赛 - Code Qwen能力算法赛道,经过初赛和复赛的评测,我们最后取得季军的成绩,团队成员来自中科院计算所、B站等单位,在这里非常感谢队友的努力付出,下面是一些我们参加比赛的历程和方案分享,欢迎大家讨论和交流。
比赛背景
代码是人类创造的高质量语言之一,通过高度的抽象来代替形式多样的自然语言,最终转换为具体程序来代替人类完成任务,其具有精确性、逻辑性和可执行性等优点。所以代码能力也成为大语言模型(LLMs)的核心能力,我们期待 LLMs 可以帮助人类进行辅助编程、漏洞修复、甚至是全自动代码生成等工作。
如何通过高质量的数据微调提升基础语言模型的代码能力仍然是一个开放且具有挑战的问题,Qwen AI挑战赛由阿里云和NVIDIA主办,天池平台和魔搭联合承办,是聚焦于通义千问大模型微调训练的竞赛,其主要目标是通过高质量的数据探索和拓展开源模型 Qwen 1.8B 及 Qwen 72B 的代码能力上限。
初赛方案
高质量的数据是大模型提升效果的关键,初赛阶段主要聚焦在如何通过 SFT 提升基础模型的代码能力,需要选手基于最新开源的 Qwen 1.8 模型作为基础模型,所以初赛我们上分的关键主要通过收集高质量的代码数据提升模型的在++Python, JavaScript, Java, Go, C++, Rust++六种编程语言的代码生成能力。
评测基准-Human Eval简介
Human Eval - HumanEval是一个用于评估代码生成模型性能的数据集,由OpenAI在2021年推出。这个数据集包含164个手工编写的编程问题,每个问题都包括一个函数签名、文档字符串(docstring)、函数体以及几个单元测试。这些问题涵盖了语言理解、推理、算法和简单数学等方面。这些问题的难度也各不相同,有些甚至与简单的软件面试问题相当。 这个数据集的一个重要特点是,它不仅仅依赖于代码的语法正确性,还依赖于功能正确性。也就是说,生成的代码需要通过所有相关的单元测试才能被认为是正确的。这种方法更接近于实际编程任务,因为在实际编程中,代码不仅需要语法正确,还需要能够正确执行预定任务。结果通过pass@k表示,其中k表示模型一次性生成多少种不同的答案中,至少包含1个正确的结果。例如Pass@1就是只生成一个答案,准确的比例。如果是Pass@10表示一次性生成10个答案其中至少有一个准确的比例。目前,收集的包含Pass@1、Pass@10和Pass@100

https://huggingface.co/datasets/bigcode/humanevalpack
数据样例如下:
{
"task_id": "Python/0",
"prompt": "from typing import List\n\n\ndef has_close_elements(numbers: List[float], threshold: float) -> bool:\n \"\"\" Check if in given list of numbers, are any two numbers closer to each other than\n given threshold.\n >>> has_close_elements([1.0, 2.0, 3.0], 0.5)\n False\n >>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)\n True\n \"\"\"\n",
"declaration": "from typing import List\n\n\ndef has_close_elements(numbers: List[float], threshold: float) -> bool:\n",
"canonical_solution": " for idx, elem in enumerate(numbers):\n for idx2, elem2 in enumerate(numbers):\n if idx != idx2:\n distance = abs(elem - elem2)\n if distance < threshold:\n return True\n\n return False\n",
"buggy_solution": " for idx, elem in enumerate(numbers):\n for idx2, elem2 in enumerate(numbers):\n if idx != idx2:\n distance = elem - elem2\n if distance < threshold:\n return True\n\n return False\n",
"bug_type": "missing logic",
"failure_symptoms": "incorrect output",
"entry_point": "has_close_elements",
"import": ""
"test_setup": ""
"test": "\n\n\n\n\ndef check(has_close_elements):\n assert has_close_elements([1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.3) == True\n assert has_close_elements([1.0, 2.0, 3.9, 4.0, 5.0, 2.2], 0.05) == False\n assert has_close_elements([1.0, 2.0, 5.9, 4.0, 5.0], 0.95) == True\n assert has_close_elements([1.0, 2.0, 5.9, 4.0, 5.0], 0.8) == False\n assert has_close_elements([1.0, 2.0, 3.0, 4.0, 5.0, 2.0], 0.1) == True\n assert has_close_elements([1.1, 2.2, 3.1, 4.1, 5.1], 1.0) == True\n assert has_close_elements([1.1, 2.2, 3.1, 4.1, 5.1], 0.5) == False\n\ncheck(has_close_elements)",
"example_test": "def check(has_close_elements):\n assert has_close_elements([1.0, 2.0, 3.0], 0.5) == False\n assert has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3) == True\ncheck(has_close_elements)\n",
"signature": "has_close_elements(numbers: List[float], threshold: float) -> bool",
"docstring": "Check if in given list of numbers, are any two numbers closer to each other than\ngiven threshold.\n>>> has_close_elements([1.0, 2.0, 3.0], 0.5)\nFalse\n>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)\nTrue",
"instruction": "Write a Python function `has_close_elements(numbers: List[float], threshold: float) -> bool` to solve the following problem:\nCheck if in given list of numbers, are any two numbers closer to each other than\ngiven threshold.\n>>> has_close_elements([1.0, 2.0, 3.0], 0.5)\nFalse\n>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)\nTrue"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
数据字段如下,其中所有 split 中的数据字段都是相同的:
-
task_id:表示问题的语言(Python/JavaScript/Java/Go/C++/Rust)和任务id(从0到163)
-
prompt:依赖代码延续的模型的提示
-
declaration:函数的声明(与提示相同,但没有文档字符串)
-
canonical_solution:通过该问题的所有单元测试的正确解决方案
-
buggy_solution:与相同,canonical_solution但有一个微妙的人为编写的错误,导致单元测试失败
-
bug_type:错误的类型([ 、、、、、、]buggy_solution之一)missing logicexcess logicvalue misuseoperator misusevariable misusefunction misuse
-
failure_symptoms:错误导致的问题([ 、、incorrect output]之一)stackoverflowinfinite loop
-
entry_point: 函数名称
-
import:解决方案所需的导入(仅适用于 Go)
-
test_setup:测试执行所需的导入(仅适用于 Go)
-
test:问题的单元测试
-
example_test:与test可以提供给模型的其他单元测试不同的单元测试(本文中未使用这些)
-
signature:函数的签名
-
docstring:描述问题的文档字符串
-
instruction:表单中的 HumanEvalSynthesize 指令Write a {language_name} function {signature} to solve the following problem:\n{docstring}
评测基准-MBPP简介
MBPP - MBPP(Mostly Basic Programming Problems)是一个数据集,主要包含了974个短小的Python函数问题,由谷歌在2021年推出,这些问题主要是为初级程序员设计的。数据集还包含了这些程序的文本描述和用于检查功能正确性的测试用例。 结果通过pass@k表示,其中k表示模型一次性生成多少种不同的答案中,至少包含1个正确的结果。例如Pass@1就是只生成一个答案,准确的比例。如果是Pass@10表示一次性生成10个答案其中至少有一个准确的比例。目前,收集的包含Pass@1、Pass@10和Pass@100
https://huggingface.co/datasets/mbpp
数据样例如下
{
'task_id': 1,
'text': 'Write a function to find the minimum cost path to reach (m, n) from (0, 0) for the given cost matrix cost[][] and a position (m, n) in cost[][].',
'code': 'R = 3\r\nC = 3\r\ndef min_cost(cost, m, n): \r\n\ttc = [[0 for x in range(C)] for x in range(R)] \r\n\ttc[0][0] = cost[0][0] \r\n\tfor i in range(1, m+1): \r\n\t\ttc[i][0] = tc[i-1][0] + cost[i][0] \r\n\tfor j in range(1, n+1): \r\n\t\ttc[0][j] = tc[0][j-1] + cost[0][j] \r\n\tfor i in range(1, m+1): \r\n\t\tfor j in range(1, n+1): \r\n\t\t\ttc[i][j] = min(tc[i-1][j-1], tc[i-1][j], tc[i][j-1]) + cost[i][j] \r\n\treturn tc[m][n]',
'test_list': [
'assert min_cost([[1, 2, 3], [4, 8, 2], [1, 5, 3]], 2, 2) == 8',
'assert min_cost([[2, 3, 4], [5, 9, 3], [2, 6, 4]], 2, 2) == 12',
'assert min_cost([[3, 4, 5], [6, 10, 4], [3, 7, 5]], 2, 2) == 16'],
'test_setup_code': '',
'challenge_test_list': []
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
数据字段含义如下:
-
source_file: 未知
-
text/ prompt: 编程任务描述
-
code:编程任务的解决方案
-
test_setup_code/ test_imports:导入执行测试所需的代码
-
test_list:验证解决方案的测试列表
-
challenge_test_list:进一步探索解决方案的更具挑战性的测试列表
比赛思路
因为涉及多种编语言,训练比以往的指令微调相对复杂,我们直接采用了官方的MFTCoder 基线方案,项目框架如下:
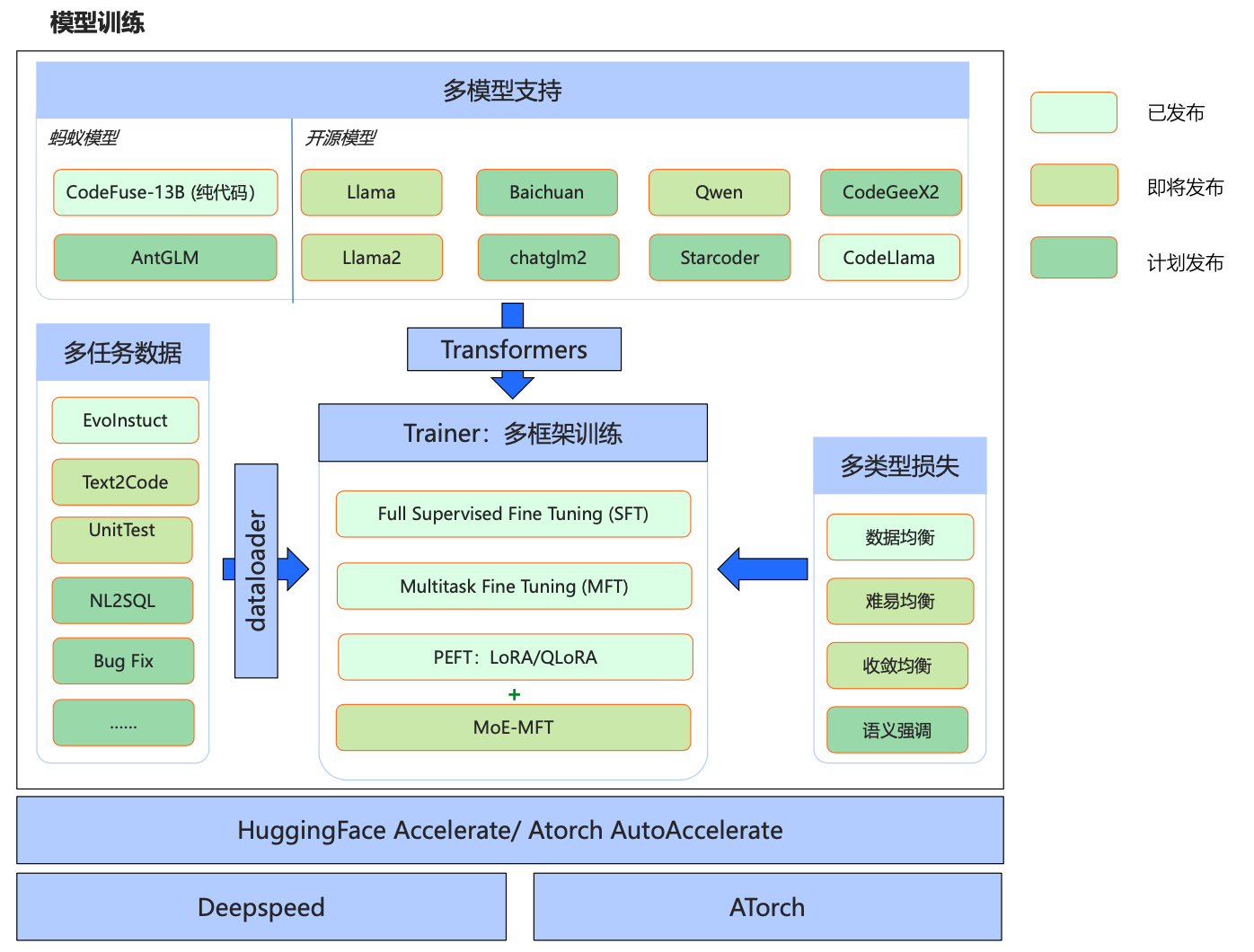
项目优势如下:
✅ 多任务:一个模型同时支持多个任务,会保证多个任务之间的平衡,甚至可以泛化到新的没有见过的任务上去;
✅ 多模型:支持最新的多个开源模型,包括gpt-neox,llama,llama-2,baichuan,Qwen,chatglm2等;
✅ 多框架:同时支持HuggingFace 和 ATorch 框架;
✅ 高效微调:支持LoRA和QLoRA,可以用很少的资源去微调很大的模型,且训练速度能满足几乎所有微调场
首先下载MFTCoder项目,需要切换到codeqwen_competition分支,然后切换到mft_peft_hf:https://github.com/codefuse-ai/MFTCoder/tree/codeqwen_competition/mft_peft_hf,启动命令如下:
关键参数如下data_paths:值必须是字符串格式的路径列表,例如“[路径1,路径2,路径3]”。每个路径代表一个下游任务,且其中可包含一个或多个JSONL文件。路径数量可以是一个或多个。
# Specify the number of GPU cards per node. Please set according to your specific situation!
N_GPU_PER_NODE=1
# Specify the number of nodes (machines) can be used. Please set according to your specific situation!
N_NODE=1
accelerate launch \
--num_machines $N_NODE \
--num_processes $(($N_NODE*$N_GPU_PER_NODE)) \
--use_deepspeed \
--deepspeed_multinode_launcher 'standard' \
--zero_stage 2 \
--offload_optimizer_device 'cpu' \
--offload_param_device 'none' \
--gradient_accumulation_steps 1 \
--gradient_clipping 1.0 \
--zero3_init_flag false \
--zero3_save_16bit_model false \
--main_training_function 'main' \
--mixed_precision 'bf16' \
--dynamo_backend 'no' \
--same_network \
--machine_rank $RANK \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--rdzv_backend 'static' \
mft_accelerate.py --train_config configs/qwen_train_config_1_8B.json
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
预测脚本如下:src/evaluation/launch_generate_codeqwen.sh
N_NODE=1
N_GPU_PER_NODE=1
- 1
- 2
tasks=(humanevalsynthesize-python humanevalsynthesize-java humanevalsynthesize-js humanevalsynthesize-cpp humanevalsynthesize-go humanevalsynthesize-rust humanevalfixtests-python humanevalfixtests-java humanevalfixtests-js humanevalfixtests-cpp humanevalfixtests-go humanevalfixtests-rust mbpp)
model=/path/to/local/model/checkpoint
model_name={your-model-name}
generation_base_dir=/path/to/hold/generated/results
if [ ! -d $generation_base_dir ]; then
mkdir $generation_base_dir
fi
batch_size=1
n_samples=1
# For qwen base model, eos is ‘<|endoftext|>’; for fine-tuned qwen model, eos is ‘<|im_end|>’
eos_token=“<|im_end|>”
# SFT Format
user=user
assistant=assistant
system=system
end_tag=“<|im_end|>”
start_tag=“<|im_start|>”
# If you need to set system prompt, set it here, otherwise you can set it as empty string. Decide whether to add system prompt by yourself.
system="$start_tag"$system$'\n'"$end_tag"$'\n'
for task in "${tasks[@]}"; do
if [ "$task" == "mbpp" ]; then
prefix="$system""$start_tag"${user}$'\n'
suffix="$end_tag"$'\n'"$start_tag"${assistant}
else
prefix=""
suffix=""
fi
generations_path=$generation_base_dir/generations_$model_name/generations_$task\_$model_name.json
if [ ! -d $generation_base_dir/generations_$model_name ]; then
mkdir $generation_base_dir/generations_$model_name
fi
echo "start to launch ...."
accelerate launch \
--num_machines $N_NODE \
--num_processes $(($N_NODE*$N_GPU_PER_NODE)) \
main.py \
--model $model \
--task $task \
--prompt instruct \
--n_samples $n_samples \
--batch_size $batch_size \
--max_length_generation 2000 \
--do_sample False \
--temperature 0.2 \
--precision bf16 \
--eos "$eos_token" \
--seed 999999999 \
--add_special_tokens True \
--trust_remote_code \
--generation_only \
--save_generations_path $generations_path \
--prefix "$prefix" \
--suffix "$suffix"
echo "Task $task done"
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
初赛一开始期间,我们通过官方的Evol-instruction-66k和 CodeExercise-Python-27k两个代码指令数据集微调之后,发现Python的synthesize的分数上涨比较大,后续加入了c++和java的代码数据,也会发现分数会上涨,通过实验可以发现:
-
通过收集完整的6中语言的代码生成数据可以提升模型每个编程语言的效果;
-
因为本项目训练策略是通过设置多个数据集实现多任务训练和多损失优化,我们尝试将搜集的数据集按照编程语言种类的方式进行组织起来,结果发现模型效果会变差,后续分析原因主要是将编程语言当做任务组织的方式会导致不同语言之间效果的相互制约,并且训练数据中每种语言token的比例失衡比较严重,导致loss优化偏离较大。
以下是我们收集到的代码数据:
-
https://huggingface.co/datasets/TokenBender/code_instructions_122k_alpaca_style
-
https://huggingface.co/datasets/code_x_glue_cc_clone_detection_big_clone_bench
-
https://huggingface.co/datasets/theblackcat102/evol-codealpaca-v1
-
https://huggingface.co/datasets/codeparrot/xlcost-text-to-code
-
https://huggingface.co/datasets/ise-uiuc/Magicoder-Evol-Instruct-110K:与evol-codealpaca-v1
-
https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1
-
https://huggingface.co/datasets/WizardLM/WizardLM_evol_instruct_70
-
https://huggingface.co/datasets/codefuse-ai/Evol-instruction-66k
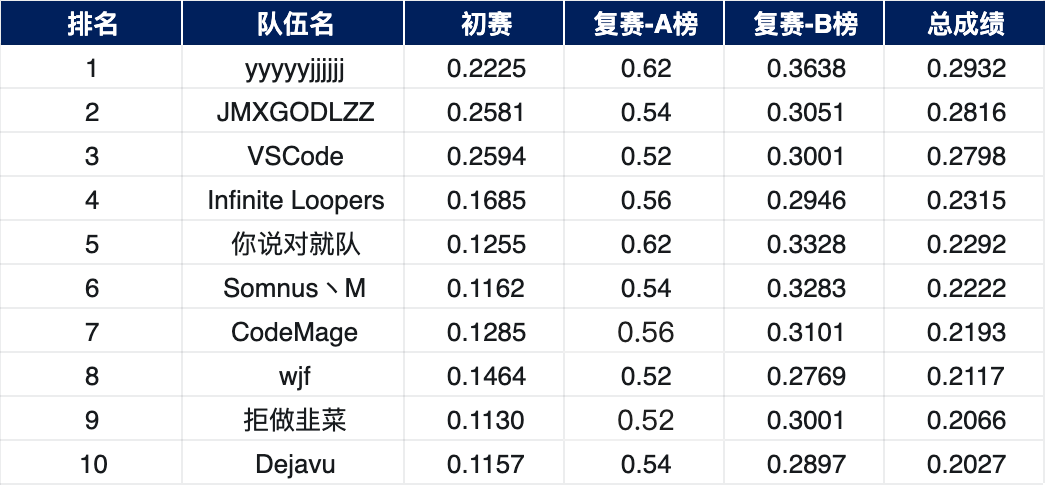
通过上述数据集筛选去重之后,初赛效果如下:
作为一个多任务学习框架MFTCoder,面临着数据的重大挑战:不平衡、任务异质性和不同的收敛速度。 为了应对这些挑战,MFTCoder 集成了专门为缓解这些不平衡而设计的一组损失函数。为了解决数据不平衡的问题,我们首先确保所有任务的所有样本在一个时代。 为了避免模型偏向具有大量数据的任务,我们引入了权重分配损失计算期间的策略。 具体来说,我们支持两种权重计算方案:一种是基于数量 任务样本和另一个基于参与损失计算的有效令牌的数量。
前者比较多简单,但在处理有效数量差异极大的任务时,它可能表现不佳标记,例如二元分类任务(例如“是”或“否”回答或单选考试任务)。另一方面,后一种根据实际参与损失计算的有效代币数量的权重分配方案可以缓解这些问题。 加权损失计算的具体公式如公式1所示。公式1中,N表示任务总数, M _ i M\_{i} M_i 表示第 i 个任务的样本数, T _ i j T\_{ij} T_ij 表示有效样本数第 i 个任务的第 j 个样本的 token(即参与损失计算的 token), t _ i j k t\_{ijk} t_ijk指第 k 个有效 token第 i 个任务的第 j 个样本。
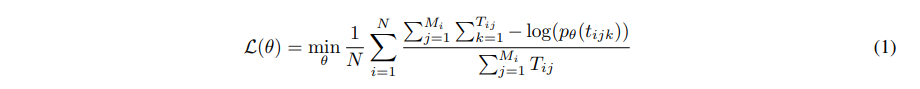
为了解决任务异质性问题,我们从焦点损失方法中汲取灵感,并将其纳入MFT 编码器。 我们实现了两种不同级别的焦点损失函数来满足不同的粒度。 一个在样本级别运行,如公式 2 所示,而另一个则在任务级别运行,如公式 3 所示。
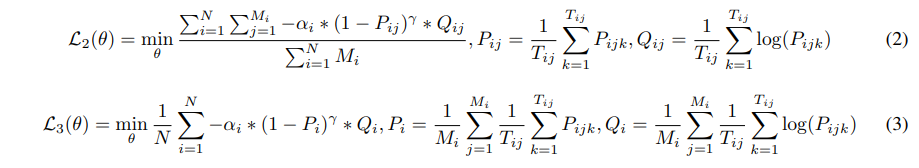
def loss_func_mft(outputs, labels, task_mask, task_id, weighted_loss_mode, loss_mask=None):
"""
loss function for MFT loss
:param outputs:
:param labels:
:param task_mask:
:param task_id:
:param weighted_loss_mode:
:param loss_mask:
:return:
"""
# task_id shape: [[1], [2], [4], [3], ..., [1]]
weighted = weighted_loss_mode
lm_logits = outputs["logits"]
labels = labels.to(device=lm_logits.device)
task_mask = task_mask.to(device=lm_logits.device)
task_id = task_id.to(device=lm_logits.device)
shift_logits = lm_logits.contiguous()
labels = labels.contiguous()
bsz, seq_len = labels.shape
# loss_mask = None
if loss_mask is None:
ineffective_tokens_per_sample = (labels==-100).sum(dim=1)
effective_tokens_per_sample = - (ineffective_tokens_per_sample - seq_len)
effective_tokens = bsz * seq_len - ineffective_tokens_per_sample.sum()
loss_fct = CrossEntropyLoss(reduction='none', ignore_index=-100)
else:
loss_mask = loss_mask.to(device=lm_logits.device)
loss_fct = CrossEntropyLoss(reduction='none')
losses = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), labels.view(-1)) # [B * L, 1]
losses = losses.contiguous().view(bsz, -1)
token_losses = losses.clone().detach().float() if loss_mask is None else losses.clone().detach().float() * loss_mask # [B, L]
task_mask_trans = torch.transpose(task_mask, 0, 1)
if weighted_loss_mode == "case3" or weighted_loss_mode == "case4":
unique_id = torch.unique(task_id)
loss = 0.0
for i, w in enumerate(unique_id):
row_idx = torch.squeeze(task_id) == w.item()
if weighted_loss_mode == "case3":
if loss_mask is None:
loss += torch.sum(losses[row_idx, :]) / torch.sum(effective_tokens_per_sample[row_idx])
else:
loss += torch.sum((losses * loss_mask)[row_idx, :]) / torch.sum(loss_mask[row_idx, :])
elif weighted_loss_mode == "case4":
if loss_mask is None:
loss += torch.mean(torch.sum(losses, dim=1)[row_idx] / effective_tokens_per_sample[row_idx])
else:
loss += torch.mean(torch.sum(losses * loss_mask, dim=1)[row_idx] / torch.sum(loss_mask, dim=1)[row_idx])
loss /= len(unique_id)
elif weighted_loss_mode == "case2":
if loss_mask is None:
loss = torch.mean(torch.sum(losses, dim=1) / effective_tokens_per_sample)
else:
loss = torch.mean(torch.sum(losses * loss_mask, dim=1) / torch.sum(loss_mask, dim=1))
elif weighted_loss_mode == "case1":
# flatten losses & loss_mask tensor
if loss_mask is None:
losses = losses.view(-1)
loss = torch.sum(losses) / effective_tokens
else:
loss_mask = loss_mask.view(-1)
losses = losses.view(-1)
loss = torch.sum(losses * loss_mask) / loss_mask.sum()
# fix task order
task_loss = torch.zeros(len(ID2TASK)).to(device=task_id.device)
task_num = torch.zeros(len(ID2TASK)).to(device=task_id.device)
for i, w in enumerate(unique_id):
row_idx = torch.squeeze(task_id) == w.item()
if loss_mask is None:
task_loss[w] = torch.sum(token_losses[row_idx, :]) / torch.sum(effective_tokens_per_sample[row_idx])
task_num[w] = len(effective_tokens_per_sample[row_idx])
else:
task_loss[w] = torch.sum((losses * loss_mask)[row_idx, :]) / torch.sum(loss_mask[row_idx, :])
return loss, task_loss, task_num
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
复赛方案
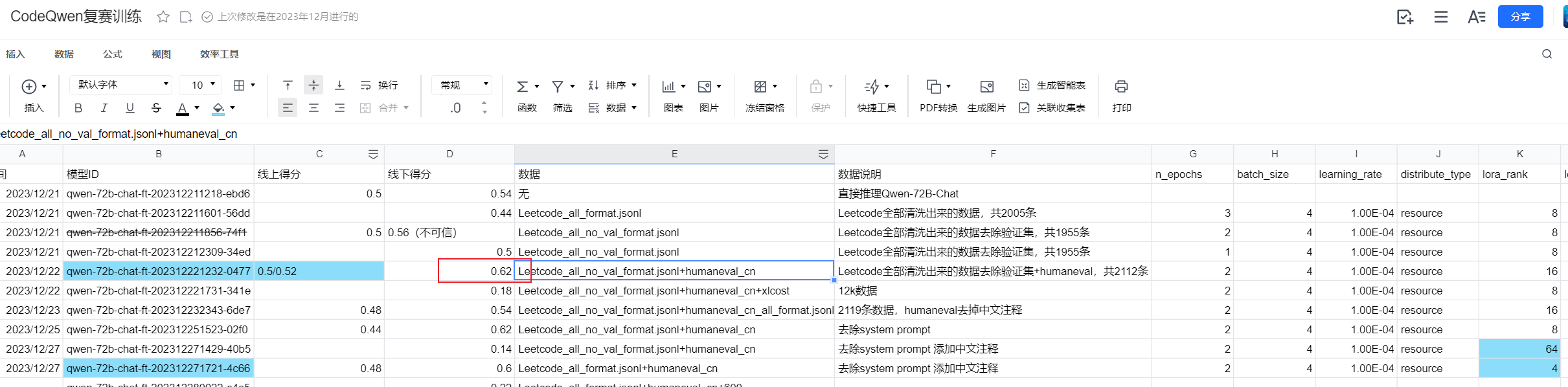
通过官方给定的50条验证集来看,复赛测试集主要是关于Leetcode题目的代码数据,所以我们团队通过收集LeetCode相关数据,构建成类似验证集的数据集格式,然后上传到训练平台对Qwen-72B进行训练,其中我们也对训练后的模型进行本地评估验证集,最后提交的是我们线下分数最高的模型(线下分数为0.62),虽然复赛A榜分数只有0.5,但是在B榜渠道0.2798的分数。
其中复赛比较关键的地方是需要保证构建的训练数据是符合Python编码规范的,千万不要有缩进、语法错误!其次需要对模型训练在验证集上的正确评估,计算测试用例通过的比例,trust cv!


