
- 1Windows用VM虚拟机安装MacOS Ventura 13.6系统全流程教程_主机windows虚拟客户机macos
- 2Python 调用 JS 的方式_python如何运行js代码
- 3torch torchvision torchaudio 版本匹配_torch 2.0.0对应的torchaudio版本
- 4TortoiseGit - 可视化的Git - 学习1_tortoisegit 可视化
- 5使用Innosetup对软件进行打包_inno setup function
- 6AI多模态教程:从0到1搭建VisualGLM图文大模型案例_ai模型搭建
- 7在国企和央企当程序员体验,太真实了。。
- 8MQTT入门指南(一)ubuntu16.04上安装MQTT服务端_ppa:mosquitto-dev 不存在
- 92023.11.5通过flask从mysql数据库中取出数据并使用echart生成饼图_flask echarts
- 10M1 Mac安装MySQL教程;my.cnf文件配置;环境变量配置;完全卸载MySQL教程,亲测有效_mac下载mysql教程
使用 RAG 创建 LLM 应用程序_rag开发应用
赞
踩
如果您考虑为您的文件或网站制作一个能够回应您的个性化机器人,那么您来对地方了。我可以帮助您使用Langchain和RAG策略来创建这样一个机器人。
了解ChatGPT的局限性和LLMs
ChatGPT和其他大型语言模型(LLMs)经过广泛训练,以理解语言的语义和连贯性。尽管它们具有令人印象深刻的能力,但这些模型也存在一些限制,需要在特定用例中进行仔细考虑。
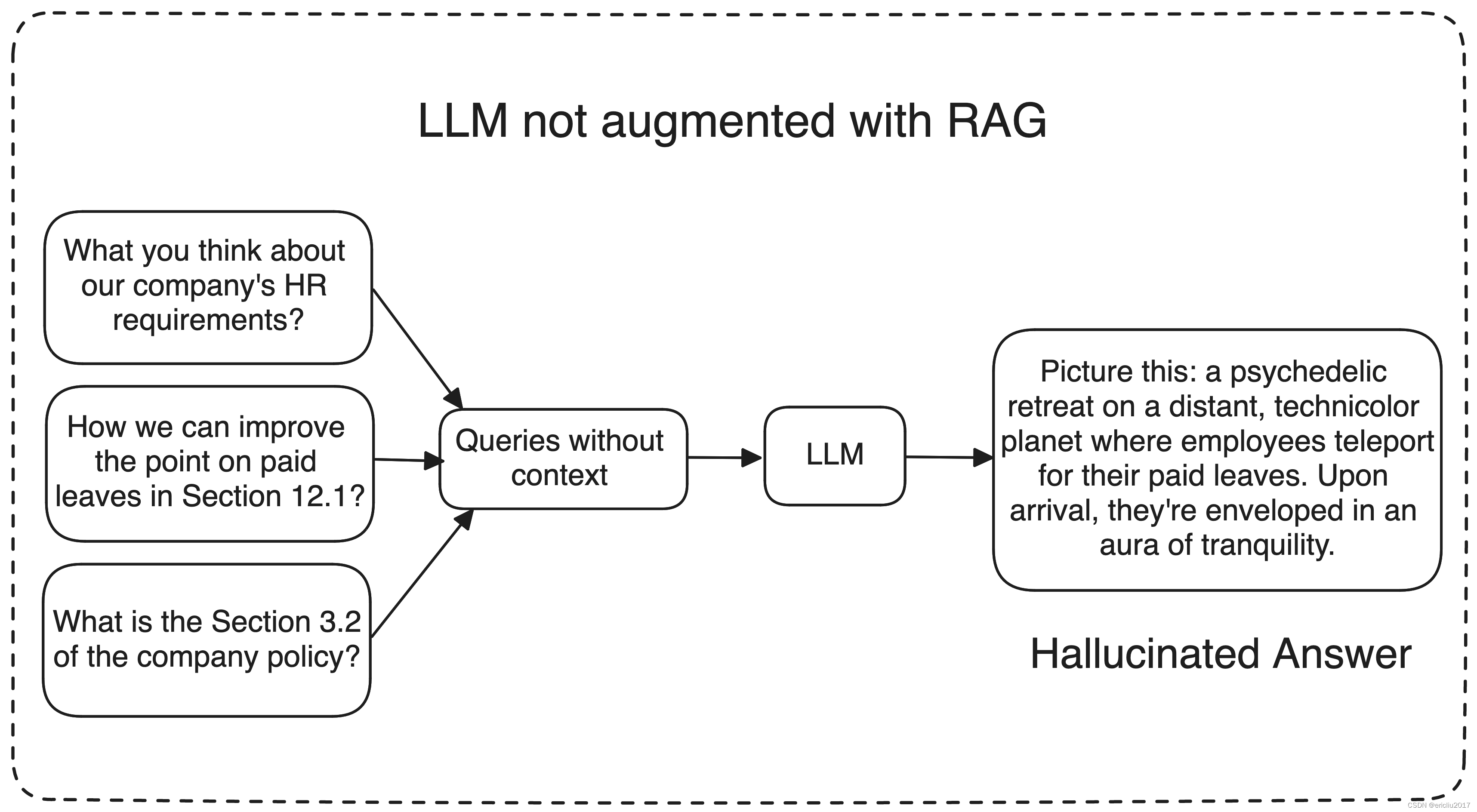
一个重要的挑战是可能出现幻觉,模型可能会生成不准确或与上下文无关的信息。
想象一下,要求模型改进您公司的政策;在这种情况下,ChatGPT和其他大型语言模型可能会难以提供准确的回答,因为它们缺乏对您公司数据的训练。
相反,它们可能会生成毫无意义或无关的回复,这可能没有帮助。那么,我们如何确保LLM理解我们的特定数据,并相应地生成回复呢?这就是检索增强生成(RAG)等技术发挥作用的地方。
RAG是什么?
RAG或检索增强生成使用三种主要工作流程来生成并提供更好的响应
-
信息检索:当用户提出问题时,AI系统从维护良好的知识库或外部来源(如数据库、文章、API或文档存储库)中检索相关数据。
这是通过将查询转换为机器可以理解的数字格式或向量来实现的。 -
LLM: 然后将检索到的数据呈现给LLM或大型语言模型,以及用户的查询。 LLM使用这些新知识和其训练数据来生成响应。
-
最终,LLM生成的响应更准确和相关,因为它已经通过检索到的信息进行了增强。
我是说我们从我们的知识库中为LLM提供了一些额外信息,这使得LLMs能够提供更具上下文相关和事实性的回答,解决了模型仅仅是在产生幻觉或提供无关答案的问题。
再举个公司政策的例子。假设你有一个处理与公司政策相关查询的人力资源机器人。
现在,如果有人询问有关政策的具体内容,机器人可以从知识库中提取最新的政策文件,将相关上下文传递给精心设计的提示,然后进一步传递给LLM以生成回应。
为了让事情更简单,想象一个LLM就像你博学的朋友,似乎什么都知道,从地理到计算机科学,从政治到哲学。现在,想象你自己问这个朋友一些问题:
- 周末谁负责洗我的衣服?
- “谁住在我隔壁?”
- 我更喜欢哪个牌子的花生酱?
很可能你的朋友无法回答这些问题。大多数时候是这样。
但假设这位遥远的朋友随着时间变得更加亲近,他经常来你家,很了解你的父母,你们经常一起出去玩,你们一起外出,等等等等.. 你懂的。
我的意思是他正在获取关于你的个人和内部信息。现在,当你提出同样的问题时,他可以以更相关的方式回答这些问题,因为他更适合你的个人见解。
同样,一个LLM在提供额外信息或访问您的数据时,不会猜测或产生幻觉。相反,它可以利用这些访问的数据提供更相关和准确的答案。
具体步骤如下,用于创建任何RAG应用程序..
- 从您的数据来源中提取相关信息。
- 把信息分成小块。
- 将这些块存储为它们的嵌入到一个向量数据库中。
- 创建一个提示模板,该模板将与查询和上下文一起输入到LLM中。
- 使用相同的嵌入模型将查询转换为其相关的嵌入。
- 从向量数据库中获取与查询相关的 k 个相关文档。
- 将相关文件传递给LLM并获取回复。
常见问题解答
-
我们将在这个任务中使用Langchain,基本上它就像一个包装器,让你更好地交流和管理你的LLM操作。请注意,Langchain更新非常快,一些功能和其他类可能会移动到不同的模块中。
所以如果有什么东西不起作用,只需检查一下你是否从正确的来源导入了库! -
我们将使用Hugging Face,这是一个用于构建、训练和部署最先进的机器学习模型的开源库,特别是关于自然语言处理。要使用HuggingFace,我们需要访问令牌,请在这里获取您的访问令牌。
-
对于我们的模型,我们将需要两个关键组件:一个LLM(大型语言模型)和一个嵌入模型。虽然像OpenAI这样的付费来源提供了这些,但我们将利用开源模型,以确保所有人都能够访问。
-
现在我们需要一个向量数据库来存储我们的嵌入。为此,我们有LanceDB——它就像一个超级智能的数据湖,可以处理大量信息。它是一流的向量数据库,使其成为处理向量嵌入等复杂数据的首选。而最棒的部分呢?
它不会在你的口袋里留下一丝痕迹,因为它是开源的,可以免费使用! -
为了简化流程,我们的数据摄取过程将涉及使用一个URL和一些PDF文件。如果需要,您可以整合其他数据源,但目前我们将专注于这两种数据源。
有了Langchain作为接口,Hugging Face用于获取模型,再加上开源组件,我们已经准备就绪!这样一来,我们既能节省一些开支,又能拥有所需的一切。让我们继续下一步。
环境设置
我正在使用 MacBook Air M1,需要注意的是,某些依赖和配置可能会因使用的系统类型而有所不同。现在打开你喜欢的编辑器,创建一个 Python 环境并安装相关的依赖。
- # Create a virtual environment
- python3 -m venv env
-
- # Activate the virtual environment
- source env/bin/activate
-
- # Upgrade pip in the virtual environment
- pip install --upgrade pip
-
- # Install required dependencies
- pip3 install lancedb langchain langchain_community prettytable sentence-transformers huggingface-hub bs4 pypdf pandas
-
- # This is optional, I did it for removing a warning
- pip3 uninstall urllib3
- pip3 install 'urllib3<2.0'
现在在相同的目录中创建一个 .env 文件,将您的 Hugging Face api 凭据放在其中,就像这样
HUGGINGFACEHUB_API_TOKEN = hf_KKNWfBqgwCUOHdHFrBwQ.....
确保名称“HUGGINGFACEHUB_API_TOKEN”保持不变,因为这对于身份验证至关重要。
如果您喜欢直接的方法,而不依赖外部包或文件加载,您可以在代码中直接配置环境变量,就像这样。
- HF_TOKEN = "hf_KKNWfBqgwCUOHdHFrBwQ....."
- os.environ["HUGGINGFACEHUB_API_TOKEN"] = HF_TOKEN
在项目的根目录中创建一个名为data的文件夹,用于存储PDF文档的中央存储库。您可以添加一些用于测试的示例PDF;例如,我正在使用Yolo V7和Transformers论文进行演示。重要的是要注意,这个指定的文件夹将作为我们数据摄取的主要来源。
好像一切都井井有条,我们已经准备就绪了!
步骤1:提取相关信息
为了让您的RAG应用程序运行起来,我们首先需要做的是从各种数据源中提取相关信息。无论是网页、PDF文件、notion链接、谷歌文档,都需要首先从其原始来源中提取信息。

这将摄取URL链接和PDF中的所有数据。
步骤2:将信息分解成较小的部分
我们已经拥有开发RAG应用所需的所有数据。现在,是时候将这些信息分解成更小的部分。之后,我们将利用嵌入模型将这些部分转换为它们各自的嵌入。但为什么这很重要呢?
就像这样想:如果你被要求一次性阅读一本100页的书,然后被问及一个特定的问题,从整本书中检索必要的信息来回答将是具有挑战性的。
然而,如果你被允许将书分成更小、可管理的部分——比如每部分10页——并且每个部分都标有从0到9的索引,那么这个过程就变得简单得多。
当相同问题在此分解后提出时,您可以根据其索引轻松找到相关的块,然后提取需要回答问题的信息。
把这本书想象成你提取的信息,每10页代表一小部分数据,目录页则是嵌入。基本上,我们会对这些部分应用嵌入模型,将信息转化为它们各自的嵌入。
作为人类,我们可能无法直接理解或与这些嵌入产生共鸣,但它们可以作为我们应用程序中块的数值表示。这就是你可以在Python中做到这一点的方式。
- from langchain.text_splitter import RecursiveCharacterTextSplitter
-
- text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1000, chunk_overlap = 50)
- chunks = text_splitter.split_documents(docs)
现在chunk_size参数指定了一个块可以包含的最大字符数,而chunk_overlap参数指定了相邻两个块之间应该重叠的字符数。
将chunk_overlap设置为50后,相邻块的最后50个字符将彼此共享。
这种方法有助于防止重要信息分散在两个块中,确保每个块包含足够的上下文信息,以便进行后续处理或分析。
相邻块边界共享的信息可以使文本内容更流畅地过渡和理解。
选择chunk_size和chunk_overlap参数的最佳策略很大程度上取决于文档的性质和应用程序的目的。
步骤3:创建嵌入并将其存储到向量数据库中
我们有两种主要方法来为我们的文本块生成嵌入。第一种方法涉及下载模型,管理预处理,并独立进行计算。
我们也可以利用Hugging Face的模型中心,该中心提供了各种预训练模型,用于各种自然语言处理任务,包括嵌入生成。
选择后一种方法可以让我们利用Hugging Face的嵌入模型之一。通过这种方法,我们只需将我们的文本块提供给所选的模型,从而避免在本地机器上进行资源密集型的计算。

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

