
- 1某大厂外包员工抢了个红包,被要求退回,太侮辱人了!千万别做外包,狗都不如...
- 2hbase_使用中遇到的问题(NotServingRegionException)_.notservingregionexception
- 3获取网络连接名称“本地连接”的两种方法_autoit 读取网络连接名
- 4基于 Github Action 的 CI/CD 流程_github cicd demo
- 5斯坦福NLP名课带学详解 | CS224n 第16讲 - 指代消解问题与神经网络方法(NLP通关指南·完结)_nlp nps
- 6【Linux】小知识点温习---命令
- 7Python中的self详细解析_python def 函数的参数self
- 8Android 8.0 调取系统摄像头和相册选择图片_安卓相册替换摄像头
- 9产品经理如何写好一份简历_如何写好产品经理简历
- 10ZYNQ基本用法------DDR(1)_zynq ddr
Linux·eventfd 原理与实践
赞
踩
1. eventfd/timerfd 简介
目前越来越多的应用程序采用事件驱动的方式实现功能,如何高效地利用系统资源实现通知的管理和送达就愈发变得重要起来。在Linux系统中,eventfd是一个用来通知事件的文件描述符,timerfd是的定时器事件的文件描述符。二者都是内核向用户空间的应用发送通知的机制,可以有效地被用来实现用户空间的事件/通知驱动的应用程序。
简而言之,就是eventfd用来触发事件通知,timerfd用来触发将来的事件通知。
开发者使用eventfd相关的系统调用,需要包含头文件;对于timerfd,则是。
系统调用eventfd/timerfd自linux 2.6.22版本加入内核,由Davide Libenzi最初实现和维护。
2. 接口及参数介绍
eventfd
对于eventfd,只有一个系统调用接口
int eventfd(unsigned int initval, int flags);创建一个eventfd对象,或者说打开一个eventfd的文件,类似普通文件的open操作。
该对象是一个内核维护的无符号的64位整型计数器。初始化为initval的值。
flags可以以下三个标志位的OR结果:
- EFD_CLOEXEC:FD_CLOEXEC,简单说就是fork子进程时不继承,对于多线程的程序设上这个值不会有错的。
- EFD_NONBLOCK:文件会被设置成O_NONBLOCK,一般要设置。
- EFD_SEMAPHORE:(2.6.30以后支持)支持semophore语义的read,简单说就值递减1。
这个新建的fd的操作很简单:
read(): 读操作就是将counter值置0,如果是semophore就减1。
write(): 设置counter的值。
注意,还支持epoll/poll/select操作,当然,以及每种fd都都必须实现的close。
timerfd
对于timerfd,有三个涉及的系统调用接口
- int timerfd_create(int clockid, int flags);
- int timerfd_settime(int fd, int flags,
- const struct itimerspec *new_value,
- struct itimerspec *old_value);
- int timerfd_gettime(int fd, struct itimerspec *curr_value);
timerfd_create就是用来创建新的timerfd对象,clockid可以指定时钟的种类,比较常用的有两种:CLOCK_REALTIME(实时时钟)或 CLOCK_MONOTONIC(单调递增时钟)。实时时钟是指系统的时钟,它可以被手工修改。而后者单调递增时钟则是不会被系统时钟的人为设置的不连续所影响的。通常选择后者。而flags的选择,TFD_CLOEXEC和TFD_NONBLOCK的意义就比较直接了。
timerfd_settime函数用来设置定时器的过期时间expiration。itmerspec结构定义如下:
- struct timespec {
- time_t tv_sec; /* Seconds */
- long tv_nsec; /* Nanoseconds */
- };
- struct itimerspec {
- struct timespec it_interval; /* Interval for periodic timer */
- struct timespec it_value; /* Initial expiration */
- };
该结构包含两个时间间隔:it_value是指第一次过期时间,it_interval是指第一次到期之后的周期性触发到期的间隔时间,(设为0的话就是到期第一次)。
old_value如果不为NULL,将会用调用时间来更新old_value所指的itimerspec结构对象。
timerfd_gettime():返回当前timerfd对象的设置值到curr_value指针所指的对象。
read():读操作的语义是:如果定时器到期了,返回到期的次数,结果存在一个8字节的整数(uint64_6);如果没有到期,则阻塞至到期,或返回EAGAIN(取决于是否设置了NONBLOCK)。
另外,支持epoll,同eventfd。
3. 使用实例 - 实现高性能消费者线程池
生产者-消费者设计模式是常见的后台架构模式。本实例将实现多个生产者和多个消费者的事件通知框架,用以阐释eventfd/timerfd在线程通信中作为通知实现的典型场景。
本实例采用以下设计:生产者创建eventfd/timerfd并在事件循环中注册事件;消费者线程池中的线程共用一个epoll对象,每个消费者线程并行地进行针对eventfd或timerfd触发的事件循环的轮询(epoll_wait)。
eventfd对应实现
- typedef struct thread_info {
- pthread_t thread_id;
- int rank;
- int epfd;
- } thread_info_t;
-
- static void *consumer_routine(void *data) {
- struct thread_info *c = (struct thread_info *)data;
- struct epoll_event *events;
- int epfd = c->epfd;
- int nfds = -1;
- int i = -1;
- uint64_t result;
-
- log("Greetings from [consumer-%d]", c->rank);
- events = calloc(MAX_EVENTS_SIZE, sizeof(struct epoll_event));
- if (events == NULL) handle_error("calloc epoll events\n");
-
- for (;;) {
- nfds = epoll_wait(epfd, events, MAX_EVENTS_SIZE, 1000); // poll every second
- for (i = 0; i < nfds; i++) {
- if (events[i].events & EPOLLIN) {
- log("[consumer-%d] got event from fd-%d", c->rank, events[i].data.fd);
- // consume events (reset eventfd)
- read(events[i].data.fd, &result, sizeof(uint64_t));
- close(events[i].data.fd); // NOTE: need to close here
- }
- }
- }
- }
-
- static void *producer_routine(void *data) {
- struct thread_info *p = (struct thread_info *)data;
- struct epoll_event event;
- int epfd = p->epfd;
- int efd = -1;
- int ret = -1;
-
- log("Greetings from [producer-%d]", p->rank);
- while (1) {
- sleep(1);
- // create eventfd (no reuse, create new every time)
- efd = eventfd(1, EFD_CLOEXEC|EFD_NONBLOCK);
- if (efd == -1) handle_error("eventfd create: %s", strerror(errno));
- // register to poller
- event.data.fd = efd;
- event.events = EPOLLIN | EPOLLET; // Edge-Triggered
- ret = epoll_ctl(epfd, EPOLL_CTL_ADD, efd, &event);
- if (ret != 0) handle_error("epoll_ctl");
- // trigger (repeatedly)
- write(efd, (void *)0xffffffff, sizeof(uint64_t));
- }
- }
-
- int main(int argc, char *argv[]) {
- struct thread_info *p_list = NULL, *c_list = NULL;
- int epfd = -1;
- int ret = -1, i = -1;
- // create epoll fd
- epfd = epoll_create1(EPOLL_CLOEXEC);
- if (epfd == -1) handle_error("epoll_create1: %s", strerror(errno));
- // producers
- p_list = calloc(NUM_PRODUCERS, sizeof(struct thread_info));
- if (!p_list) handle_error("calloc");
- for (i = 0; i < NUM_PRODUCERS; i++) {
- p_list[i].rank = i;
- p_list[i].epfd = epfd;
- ret = pthread_create(&p_list[i].thread_id, NULL, producer_routine, &p_list[i]);
- if (ret != 0) handle_error("pthread_create");
- }
- // consumers
- c_list = calloc(NUM_CONSUMERS, sizeof(struct thread_info));
- if (!c_list) handle_error("calloc");
- for (i = 0; i < NUM_CONSUMERS; i++) {
- c_list[i].rank = i;
- c_list[i].epfd = epfd;
- ret = pthread_create(&c_list[i].thread_id, NULL, consumer_routine, &c_list[i]);
- if (ret != 0) handle_error("pthread_create");
- }
- // join and exit
- for (i = 0; i < NUM_PRODUCERS; i++) {
- ret = pthread_join(p_list[i].thread_id, NULL);
- if (ret != 0) handle_error("pthread_join");
- }
- for (i = 0; i < NUM_CONSUMERS; i++) {
- ret = pthread_join(c_list[i].thread_id, NULL);
- if (ret != 0) handle_error("pthread_join");
- }
- free(p_list);
- free(c_list);
- return EXIT_SUCCESS;
- }

执行过程(2个生产者,4个消费者):
- [1532099804] Greetings from [producer-0]
- [1532099804] Greetings from [producer-1]
- [1532099804] Greetings from [consumer-0]
- [1532099804] Greetings from [consumer-1]
- [1532099804] Greetings from [consumer-2]
- [1532099804] Greetings from [consumer-3]
- [1532099805] [consumer-3] got event from fd-4
- [1532099805] [consumer-3] got event from fd-5
- [1532099806] [consumer-0] got event from fd-4
- [1532099806] [consumer-0] got event from fd-4
- [1532099807] [consumer-1] got event from fd-4
- [1532099807] [consumer-1] got event from fd-5
- [1532099808] [consumer-3] got event from fd-4
- [1532099808] [consumer-3] got event from fd-5
- ^C
结果符合预期(附:源码链接)
注意,推荐在eventfd在打开时设置NON_BLOCKING,并在注册至epoll监听对象时设为EPOLLET(尽管一次8字节的read就可以读完整个计数器到用户空间),因为毕竟,只有采用了非阻塞IO和边沿触发,epoll的并发能力才能完全发挥极致。
另外,本实例中的eventfd消费地非常高效,fd号几乎不会超过5(前四个分别为stdin/stdout/stderr/eventpoll),但实际应用中往往在close前会执行一些事务,随着消费者线程的增加,eventfd打开的文件也会增加(这个数值得上限由系统的ulimit -n决定)。然而,eventfd打开、读写和关闭都效非常高,因为它本质并不是文件,而是kernel在内核空间(内存中)维护的一个64位计数器而已。
timerfd对应实现
main函数和consumer线程实现几乎一致,而producer线程创建timerfd,并注册到事件循环中。
timer的it_value设为1秒,即第一次触发为1秒以后;it_interval设为3秒,即后续每3秒再次触发一次。
注意,timerfd_settime函数的位置与之前eventfd的write的相同,二者达到了类似的设置事件的作用,只不过这次是定时器事件。
- static void *producer_routine(void *data) {
- struct thread_info *p = (struct thread_info *)data;
- struct epoll_event event;
- int epfd = p->epfd;
- int tfd = -1;
- int ret = -1;
- struct itimerspec its;
- its.it_value.tv_sec = 1; // initial expiration
- its.it_value.tv_nsec = 0;
- its.it_interval.tv_sec = 3; // interval
- its.it_interval.tv_nsec = 0;
-
- log("Greetings from [producer-%d]", p->rank);
- // create timerfd
- tfd = timerfd_create(CLOCK_MONOTONIC, TFD_CLOEXEC|TFD_NONBLOCK);
- if (tfd == -1) handle_error("timerfd create: %s", strerror(errno));
- // register to poller
- event.data.fd = tfd;
- event.events = EPOLLIN | EPOLLET; // Edge-Triggered
- ret = epoll_ctl(epfd, EPOLL_CTL_ADD, tfd, &event);
- if (ret != 0) handle_error("epoll_ctl");
- // register timer expired in future
- ret = timerfd_settime(tfd, 0, &its, NULL);
- if (ret != 0) handle_error("timerfd settime");
- return (void *)0;
- }
执行过程(2个生产者,4个消费者):
- [1532099143] Greetings from [producer-1]
- [1532099143] Greetings from [consumer-1]
- [1532099143] Greetings from [consumer-2]
- [1532099143] Greetings from [consumer-3]
- [1532099143] Greetings from [consumer-0]
- [1532099143] Greetings from [producer-0]
- [1532099144] [consumer-3] got event from fd-4
- [1532099144] [consumer-3] got event from fd-5
- [1532099147] [consumer-3] got event from fd-4
- [1532099147] [consumer-3] got event from fd-5
- [1532099150] [consumer-0] got event from fd-4
- [1532099150] [consumer-0] got event from fd-5
- [1532099153] [consumer-1] got event from fd-4
- [1532099153] [consumer-1] got event from fd-5
- ^C
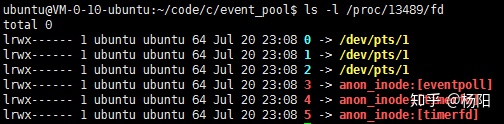
从上图可以看出,运行时打开的fd-4和fd-5两个文件描述符即是timerfd。
结果符合预期(附:源码链接)
4. 典型应用场景及优势
引用eventfs的Manual中NOTE段落的第一句话:
Applications can use an eventfd file descriptor instead of a pipe in all cases where a pipe is used simply to signal events.
在信号通知的场景下,相比pipe有非常大的资源和性能优势。其根本在于counter(计数器)和channel(数据信道)的区别。
- 第一,是打开文件数量的巨大差别。由于pipe是半双工的传统IPC方式,所以两个线程通信需要两个pipe文件,而用eventfd只要打开一个文件。众所周知,文件描述符可是系统中非常宝贵的资源,linux的默认值也只有1024而已。那开发者可能会说,1相比2也只节省了一半嘛。要知道pipe只能在两个进程/线程间使用,并且是面向连接(类似TCP socket)的,即需要之前准备好两个pipe;而eventfd是广播式的通知,可以多对多的。如上面的NxM的生产者-消费者例子,如果需要完成全双工的通信,需要NxMx2个的pipe,而且需要提前建立并保持打开,作为通知信号实在太奢侈了,但如果用eventfd,只需要在发通知的时候瞬时创建、触发并关闭一个即可。
- 第二,是内存使用的差别。eventfd是一个计数器,内核维护几乎成本忽略不计,大概是自旋锁+唤醒队列(后续详细介绍),8个字节的传输成本也微乎其微。但pipe可就完全不是了,一来一回数据在用户空间和内核空间有多达4次的复制,而且更糟糕的是,内核还要为每个pipe分配至少4K的虚拟内存页,哪怕传输的数据长度为0。
- 第三,对于timerfd,还有精准度和实现复杂度的巨大差异。由内核管理的timerfd底层是内核中的hrtimer(高精度时钟定时器),可以精确至纳秒(1e-9秒)级,完全胜任实时任务。而用户态要想实现一个传统的定时器,通常是基于优先队列/二叉堆,不仅实现复杂维护成本高,而且运行时效率低,通常只能到达毫秒级。
所以,第一个最佳实践法则:当pipe只用来发送通知(传输控制信息而不是实际数据),放弃pipe,放心地用eventfd/timerfd,"in all cases"。
另外一个重要优势就是eventfd/timerfd被设计成与epoll完美结合,比如支持非阻塞的读取等。事实上,二者就是为epoll而生的(但是pipe就不是,它在Unix的史前时代就有了,那时不仅没有epoll连Linux都还没诞生)。应用程序可以在用epoll监控其他文件描述符的状态的同时,可以“顺便“”一起监控实现了eventfd的内核通知机制,何乐而不为呢?
所以,第二个最佳实践法则:eventfd配上epoll才更搭哦。
5. 内核实现细节
eventfd在内核源码中,作为syscall实现在内核源码的 fs/eventfd.c下。从Linux 2.6.22版本引入内核,在2.6.27版本以后加入对flag的支持。以下分析参考Linux 2.6.27源码。
内核中的数据结构:eventfd_ctx
该结构除了包括之前所介绍的一个64位的计数器,还包括了等待队列头节点(较新的kernel中还加上了一个kref)。
定义和初始化过程核心代码如下,比较直接:内核malloc,设置count值,创建eventfd的anon_inode。
- struct eventfd_ctx {
- wait_queue_head_t wqh;
- __u64 count;
- };
以下为创建eventfd的函数的片段,比较直接。
- SYSCALL_DEFINE2(eventfd2, unsigned int, count, int, flags) {
- // ...
- ctx = kmalloc(sizeof(*ctx), GFP_KERNEL);
- if (!ctx)
- return -ENOMEM;
- init_waitqueue_head(&ctx->wqh);
- ctx->count = count;
- fd = anon_inode_getfd("[eventfd]", &eventfd_fops, ctx,
- flags & (O_CLOEXEC | O_NONBLOCK));
- // ...
- }
稍提一下,等待队列是内核中的重要数据结构,在进程调度、异步通知等多种场景都有很多的应用。其节点结构并不复杂,即自带自旋锁的双向循环链表的节点,如下:
- struct __wait_queue_head {
- spinlock_t lock;
- struct list_head task_list;
- };
- typedef struct __wait_queue_head wait_queue_head_t;
等待队列中存放的是task(内存中对线程的抽象)的结构。
操作等待队列的函数主要是和调度相关的函数,如:wake_up和schedule,它们位于sched.c中,前者即唤醒当前等待队列中的task,后者为当前task主动让出CPU时间给等待队列中的其他task。这样,便通过等待队列实现了多个task在运行中(TASK_RUNNING)和IO等待(TASK_INTERRUPTABLE)中的状态切换。
让我们一起复习下,系统中进程的状态转换:

- TASK_RUNNING: 正在在CPU上运行,或者在执行队列(run queue)等待被调度执行。
- TASK_INTERRUPTIBLE: 睡眠中等待默写事件出现,task可以被信号打断,一旦接收到信号或显示调用了wake-up,转为TASK_RUNNING状态。常见于IO等待中。
清楚了task的两种状态以及run queue / wait queue原理,read函数就不难理解了。
以下是read函数的实现:
- static ssize_t eventfd_read(struct file *file, char __user *buf, size_t count,
- loff_t *ppos)
- {
- struct eventfd_ctx *ctx = file->private_data;
- ssize_t res;
- __u64 ucnt;
- DECLARE_WAITQUEUE(wait, current);
-
- if (count < sizeof(ucnt))
- return -EINVAL;
- spin_lock_irq(&ctx->wqh.lock);
- res = -EAGAIN;
- ucnt = ctx->count;
- if (ucnt > 0)
- res = sizeof(ucnt);
- else if (!(file->f_flags & O_NONBLOCK)) {
- __add_wait_queue(&ctx->wqh, &wait);
- for (res = 0;;) {
- set_current_state(TASK_INTERRUPTIBLE);
- if (ctx->count > 0) {
- ucnt = ctx->count;
- res = sizeof(ucnt);
- break;
- }
- if (signal_pending(current)) {
- res = -ERESTARTSYS;
- break;
- }
- spin_unlock_irq(&ctx->wqh.lock);
- schedule();
- spin_lock_irq(&ctx->wqh.lock);
- }
- __remove_wait_queue(&ctx->wqh, &wait);
- __set_current_state(TASK_RUNNING);
- }
- if (res > 0) {
- ctx->count = 0;
- if (waitqueue_active(&ctx->wqh))
- wake_up_locked(&ctx->wqh);
- }
- spin_unlock_irq(&ctx->wqh.lock);
- if (res > 0 && put_user(ucnt, (__u64 __user *) buf))
- return -EFAULT;
-
- return res;
- }
read操作目的是要将count值返回用户空间并清零。ctx中的count值是共享数据,通过加irq自旋锁实现对其的独占安全访问,spin_lock_irq函数可以禁止本地中断和抢占,在SMP体系中也是安全的。从源码可以看出,如果是对于(通常的epoll中的,也是上面实例中的)非阻塞读,count大于0则直接返回并清零,count等于0则直接返回EAGAIN。
对于阻塞读,如果count值为0则加入等待队列并阻塞,直到值不为0时(被其他线程更新)返回。阻塞是如何实现的呢?是通过TASK_INTERRUPTABLE状态下的循环加schedule。注意,schedule前释放了自旋锁,意味着允许其他线程更新值,只要值被更新大于0且又再次获得cpu时间,那么就可以跳出循环继续执行而返回了。
考虑一个情景,两个线程几乎同时read请求,那么:两个都会被加入到等待队列中,当第一个抢到自旋锁,返回了大于1的res并重置了count为0,此时它会(在倒数第二个if那里) 第一时间唤醒等待队列中的其他线程,此时第二个线程被调度到,于是开始了自己的循环等待。即实现了:事件只会通知到第一个接收到的线程。
那么问题来了:我们知道在其他线程write后,阻塞的read线程是马上返回的。那么如何能在count置一旦不为0时,等待的调度的阻塞读线程可以尽快地再次获得cpu时间,从而继续执行呢?关键在于write函数也有当确认可以成功返回时,主动调用wakeup_locked的过程,这样就能实现write后立即向等待队列通知的效果了。
write操作与read操作过程非常相似,不在此展开。
关于poll操作的核心代码如下:
- // ...
- spin_lock_irqsave(&ctx->wqh.lock, flags);
- if (ctx->count > 0)
- events |= POLLIN;
- if (ctx->count == ULLONG_MAX)
- events |= POLLERR;
- if (ULLONG_MAX - 1 > ctx->count)
- events |= POLLOUT;
- spin_unlock_irqrestore(&ctx->wqh.lock, flags);
在count值大于0时,返回了设置POLLIN标志的事件,使得用户层的应用可以通过epoll监控 eventfd的可读事件状态。
6. 本篇小结
通过对eventfd/timerfd的接口和实现的了解,可以看出其不仅功能实用,而且调用方式简单。另外,其实现是非常精巧高效的,构建于内核众多系统基础核心功能之上,为用户态的应用封装了十分高效简单的事件通知机制。

