- 1Linux C/C++之IO多路复用(poll,epoll)_c++ .events = pollin
- 2嵌入式软件工程师可以考哪些专业相关证书? 想考些证书,有利于今后找工作,可以考哪些?_嵌入式软件工程师可以考哪些证书
- 3什么是云原生?以及应用落地_数据中心应用系统是基于云原生
- 4Verilog 不可综合部分
- 5文心一言4.0API接入指南_文心一言url
- 6字节跳动简历冷却期_【职位内推第 32 期】腾讯/字节跳动/小米/滴滴/36氪/宝马 | 实习 | 北京&广州...
- 7MacBook Pro打不开IDEA解决方法_intelij idea 2023 mac打开报错
- 8一文了解Web3社交网络Solcial_web3社区一般称呼成员用什么
- 9每天一个设计模式之 -- 过滤器模式
- 10stm32---串口接口标准_stm32f205 串口
【PostgreSQL内核学习(二)—— 查询分析】_postgresql 查询
赞
踩
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书
查询处理
在PostgreSQL中,查询处理是指处理和执行SQL查询语句的整个过程。这个过程涵盖了从接收客户端发送的查询到返回结果的整个流程。**PostgreSQL查询处理涵盖了从接收客户端发送的SQL查询到返回结果的整个过程。**其主要职责包括:
- 查询解析:接收客户端发送的SQL查询,并进行语法和语义解析,确保查询语句正确且符合数据库规范。如果查询语句存在错误,将向客户端返回相应的错误信息。
- 查询重写:对已解析的查询进行重写和转换,应用查询优化规则和重写规则来改进查询的执行计划。通过查询重写,可以将查询转换为更高效的形式,以便更快地获取所需的数据。
- 查询优化:根据查询的代价模型和统计信息,创建多个可能的执行计划,并选择最优的执行计划以最小化查询的总成本。优化器会尝试不同的执行策略,比较它们的代价,并选择执行成本最低的方案。
- 执行计划生成:根据查询优化器选择的最佳执行计划,生成一个由操作符组成的执行计划树。这个执行计划树描述了查询在数据库中的执行过程,包括数据访问、连接、过滤、排序等操作。
- 查询执行:按照生成的执行计划,执行查询操作。查询引擎会根据执行计划中的操作符逐步执行查询,从数据库中获取数据,并进行相应的数据操作和计算。
- 锁定和并发控制:在执行查询时,确保正确的锁定机制和并发控制,以防止数据不一致和并发冲突。这对于多用户同时访问数据库的情况至关重要。
- 统计信息维护:在查询执行过程中,维护和更新数据库中的统计信息,包括表和索引的数据分布、行数估计等。这些统计信息对于优化器的选择非常重要。
- 查询缓存管理:在查询处理过程中,尝试在查询缓存中查找相同查询的执行计划,从而避免重复的查询编译和优化,提高查询性能。
- 错误处理和异常处理:负责捕获和处理查询执行过程中可能发生的错误和异常情况,并向客户端返回相应的错误信息。
查询处理是数据库系统的核心功能之一,它直接影响到数据库的性能和响应时间。PostgreSQL的查询处理器通过查询解析、优化、执行和并发控制等职责来确保高效、可靠地处理各种类型的SQL查询。优化器和执行引擎的优化算法和策略在此过程中发挥着至关重要的作用。
以下分别展示了查询处理的完整流程图和查询处理的各模块说明。
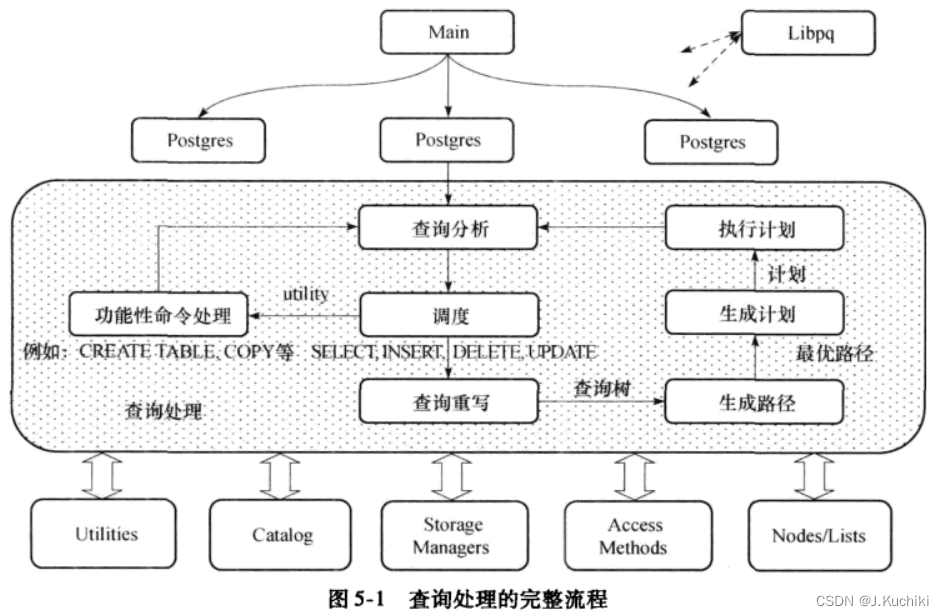
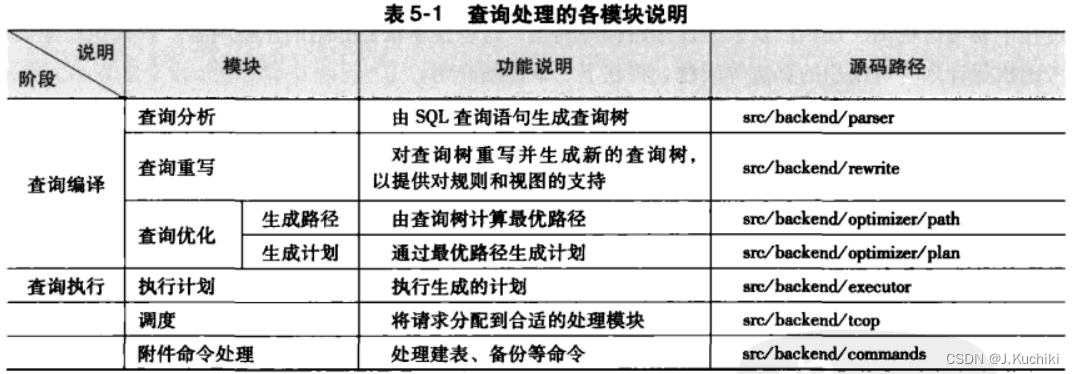
查询分析
查询处理与查询分析的关系
查询分析是查询处理的一个子过程。查询处理是一个更广泛的概念,包含了整个查询的生命周期,从接收查询到最终的结果返回。在查询处理过程中,查询分析是其中的一个重要组成部分。查询分析的结果会影响到查询优化器的选择,从而影响最终的执行计划生成和查询执行阶段。通过查询分析,我们可以了解查询的执行情况,并进行必要的优化,以提高查询的性能和数据库的整体性能。
查询分析和查询处理是数据库查询过程中的两个重要环节。查询分析用于分析已执行查询的性能并优化查询,而查询处理负责整个查询的处理和执行。查询分析是查询处理过程的一部分,通过优化查询分析结果,可以改善整个查询处理的性能和效率。
查询分析执行流程
查询分析是查询编译的第一个模块,它包括词法分析、语法分析和语义分析三个部分。它将用户输人的SQL命令转换为查询树(Query结构)。其中词法分析和语法分析分别借助词法分析工具Lex和语法分析工具Yacc来完成各自的工作。
查询分析的基本流程如下所示:

如下展示了查询分析中主要的函数调用关系:
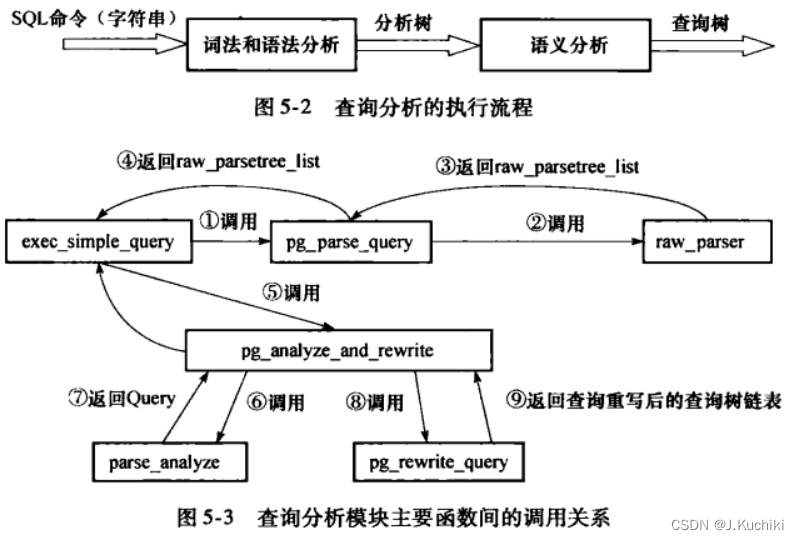
对于用户的SQL命令,统一由exec_simple_query函数处理,该函数将调用pg_parse_query完成词法和语法分析并产生分析树,接下来调用pg_analyze_and_rewrite函数逐个对分析树进行语义分析和重写:在该函数中又会调用函数 parse _ analyzer进行语义分析并创建查询树(Query 结构),函数pg_rewrite _query则负责对查询树进行重写。
查询分析的处理过程如下:
- exec_simple_query调用函数 pg_parse_query进入词法和语法分析的主体处理过程,然后函数pg_parse_query调用词法和语法分析的人口函数raw_parser生成分析树(原始分析树链表raw_parse-tree_list)。
注:exec_simple_query函数源码如下所示,路径在:/postgresql-10.1/src/backend/tcop/postgres.c下。
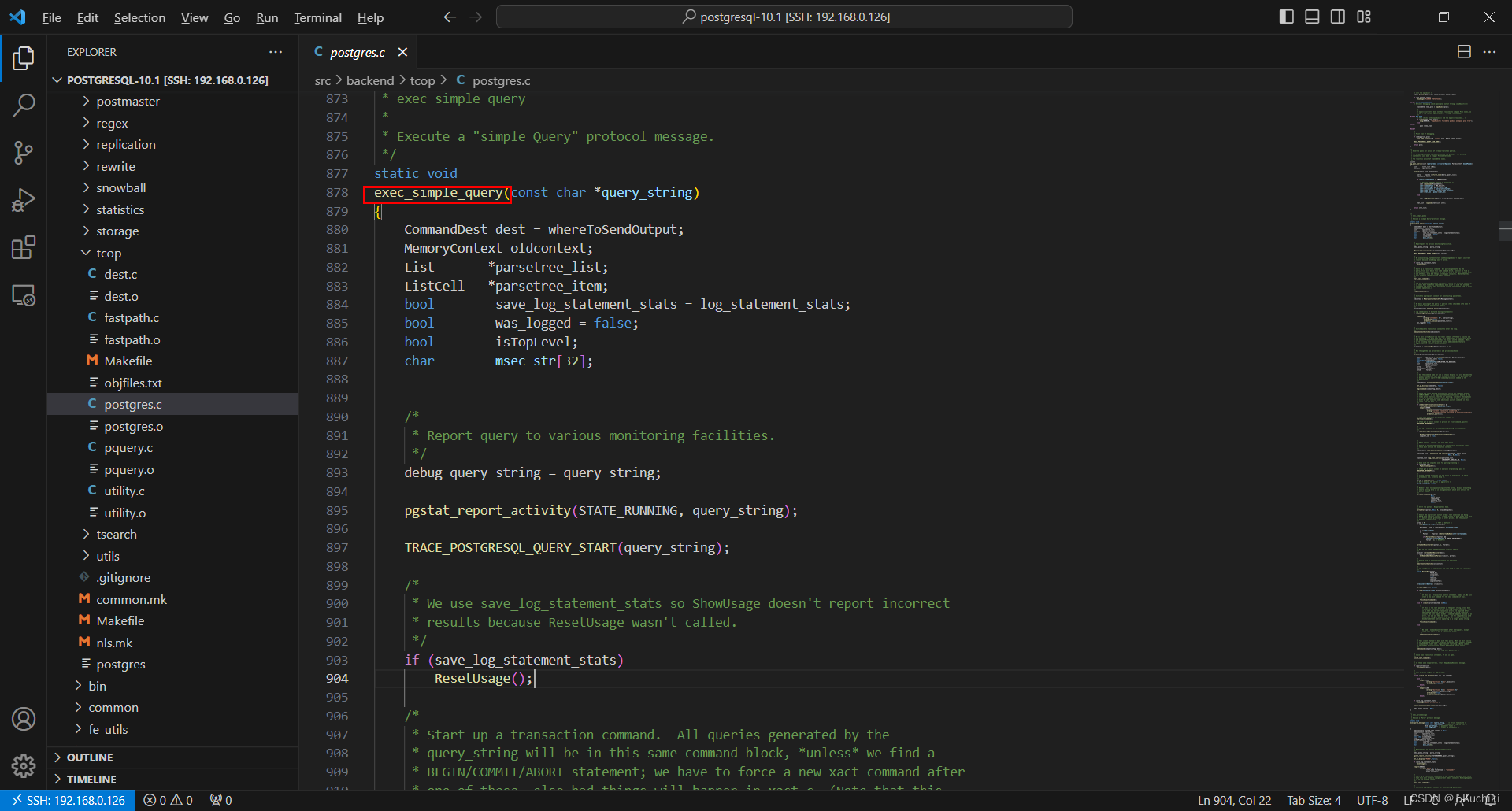
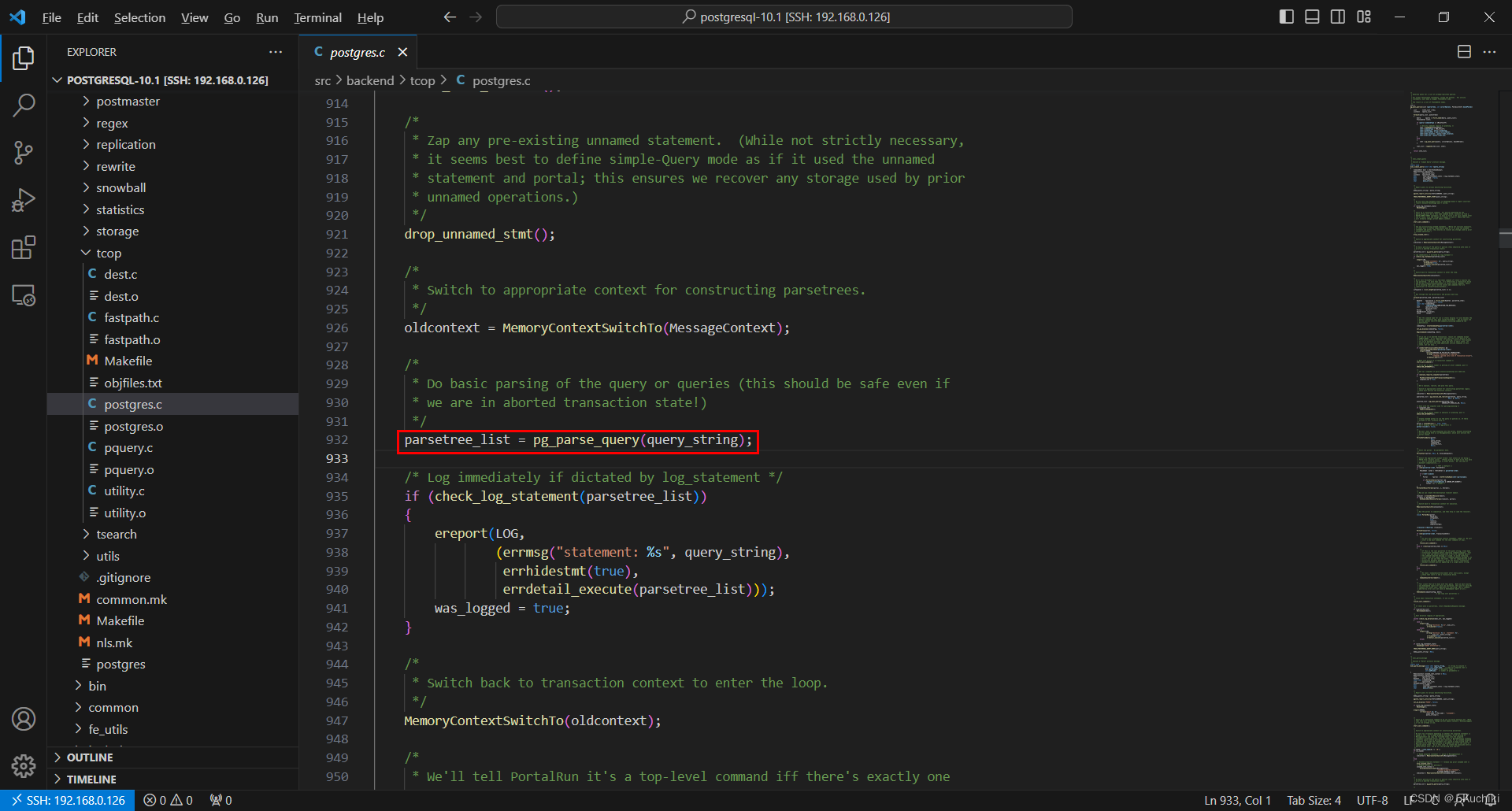
- 函数pg_parse_query返回分析树给外部函数。函数pg_parse_query的源码如下所示。
/*
* pg_parse_query - 解析输入的SQL查询语句,返回解析树的列表
*
* 输入参数:
* query_string - 要解析的SQL查询字符串
*
* 返回值:
* List类型的指针,包含解析树的列表
*
* 该函数的作用是将输入的SQL查询字符串解析成解析树的列表,并返回该列表。
* 解析树是一个由C语言数据结构构成的树状表示,用于表示SQL查询的结构和逻辑。
*/
List *
pg_parse_query(const char *query_string)
{
List *raw_parsetree_list;
// 记录查询解析开始的追踪日志
TRACE_POSTGRESQL_QUERY_PARSE_START(query_string);
// 如果需要记录解析器统计信息,就重置统计信息
if (log_parser_stats)
ResetUsage();
// 调用原始解析器进行解析,得到原始解析树列表
raw_parsetree_list = raw_parser(query_string);
// 如果需要记录解析器统计信息,就显示统计信息
if (log_parser_stats)
ShowUsage("PARSER STATISTICS");
// 可选的调试检查:通过copyObject()函数复制原始解析树列表,用于调试
// 这里通过比较原始解析树列表和复制后的列表来检查copyObject()和equal()是否正确
#ifdef COPY_PARSE_PLAN_TREES
{
List *new_list = copyObject(raw_parsetree_list);
// 这里比较两个列表是否相等,以确保copyObject()正确工作
if (!equal(new_list, raw_parsetree_list))
elog(WARNING, "copyObject() failed to produce an equal raw parse tree");
else
raw_parsetree_list = new_list;
}
#endif
// 记录查询解析结束的追踪日志
TRACE_POSTGRESQL_QUERY_PARSE_DONE(query_string);
// 返回原始解析树列表
return raw_parsetree_list;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
其中,raw_parser为词法和语法分析的入口函数。
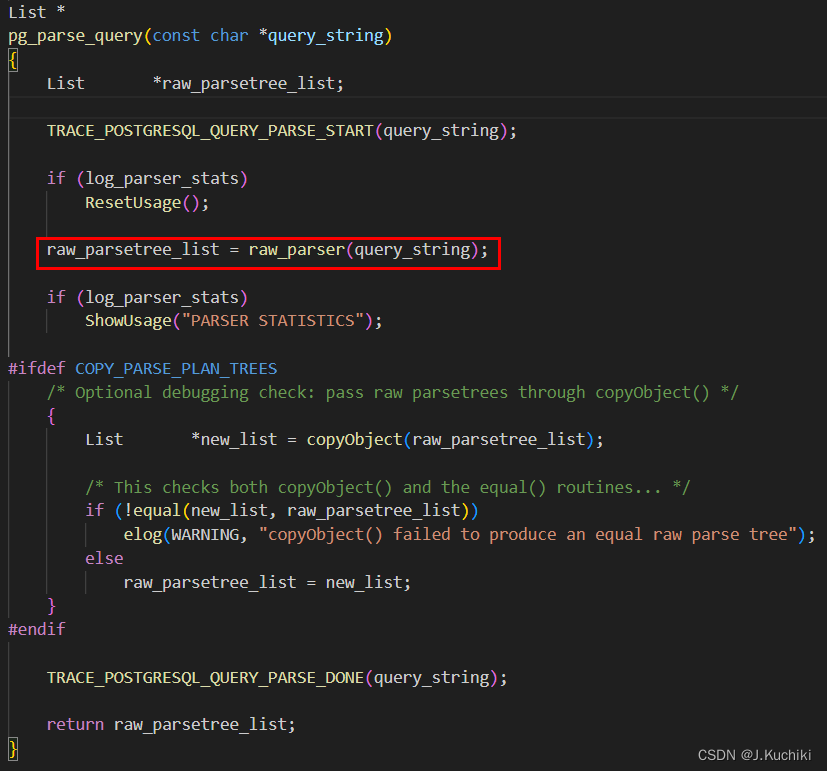
raw_parser函数(在src/backend/parser/parser.c下)主要通过调用采用Lex和Yacc配合预生成的base_yyparse函数来实现词法分析和语法分析的工作。raw_parser的源代码如下所示。
/*
* raw_parser
* Given a query in string form, do lexical and grammatical analysis.
* 对给定的查询字符串进行词法和语法分析。
*
* Returns a list of raw (un-analyzed) parse trees. The immediate elements
* of the list are always RawStmt nodes.
* 返回一个原始(未经分析)解析树列表。该列表的直接元素总是RawStmt节点。
*/
List *
raw_parser(const char *str)
{
core_yyscan_t yyscanner;
base_yy_extra_type yyextra;
int yyresult;
/* initialize the flex scanner */
/* 初始化flex扫描器 */
yyscanner = scanner_init(str, &yyextra.core_yy_extra,
ScanKeywords, NumScanKeywords);
/* base_yylex() only needs this much initialization */
/* base_yylex()只需要这么多的初始化 */
yyextra.have_lookahead = false;
/* initialize the bison parser */
/* 初始化bison解析器 */
parser_init(&yyextra);
/* Parse! */
/* 开始解析! */
yyresult = base_yyparse(yyscanner);
/* Clean up (release memory) */
/* 清理(释放内存) */
scanner_finish(yyscanner);
if (yyresult) /* error */
return NIL;
return yyextra.parsetree;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
返回值为List结构体,定义如下:(路径为:src/include/nodes/pg_list.h)
typedef struct ListCell ListCell;
typedef struct List
{
NodeTag type; /* T_List, T_IntList, or T_OidList */
int length;
ListCell *head;
ListCell *tail;
} List;
struct ListCell
{
union
{
void *ptr_value;
int int_value;
Oid oid_value;
} data;
ListCell *next;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这段代码定义了一个简单的链表数据结构 List,它由节点 ListCell 组成。每个节点可以存储不同类型的数据,并通过指针 next 连接在一起,形成一个链表。
- exec_simple_query接着调用函数pg_analyze_and_rewrite进行语义分析和查询重写。首先调用函数parse_analyze进行语义分析并生成查询树(用Query结构体表示),之后会将查询树传递给函数pg_rewrite_query进行查询重写。
pg_analyze_and_rewrite的源代码如下:
/*
* Given a raw parsetree (gram.y output), and optionally information about
* types of parameter symbols ($n), perform parse analysis and rule rewriting.
* 给定一个原始解析树(gram.y的输出),以及可选的参数符号($n)的类型信息,
* 执行解析分析和规则重写。
*
* A list of Query nodes is returned, since either the analyzer or the
* rewriter might expand one query to several.
* 返回一个Query节点的列表,因为解析分析器或重写器可能会将一个查询展开成多个查询。
*
* NOTE: for reasons mentioned above, this must be separate from raw parsing.
* 注意:由于上述原因,这必须与原始解析分开。
*/
List *
pg_analyze_and_rewrite(RawStmt *parsetree, const char *query_string,
Oid *paramTypes, int numParams,
QueryEnvironment *queryEnv)
{
Query *query;
List *querytree_list;
TRACE_POSTGRESQL_QUERY_REWRITE_START(query_string);
/*
* (1) Perform parse analysis.
* (1) 执行解析分析
*/
if (log_parser_stats)
ResetUsage();
// 调用parse_analyze()函数进行解析分析,得到解析后的Query节点
query = parse_analyze(parsetree, query_string, paramTypes, numParams,
queryEnv);
// 如果需要记录解析器统计信息,就显示统计信息
if (log_parser_stats)
ShowUsage("PARSE ANALYSIS STATISTICS");
/*
* (2) Rewrite the queries, as necessary
* 重写查询,必要时进行重写
*/
// 调用pg_rewrite_query()函数重写查询
querytree_list = pg_rewrite_query(query);
// 记录查询重写结束的追踪日志
TRACE_POSTGRESQL_QUERY_REWRITE_DONE(query_string);
// 返回重写后的查询列表
return querytree_list;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
在 PostgreSQL 中,Query 节点是解析分析器生成的一个重要数据结构,用于表示一条SQL查询语句的逻辑结构。Query 节点是由解析器在解析 SQL 查询时构建的,它以树状结构的形式表示查询的各个部分和子句。
在查询处理的过程中,Query 节点会经历多个阶段的处理,例如解析分析、查询重写、优化和执行等。通过 Query 节点,PostgreSQL 可以在内部进行各种操作,从而执行和优化复杂的查询语句。在数据库内部,多个 Query 节点可能相互关联形成一个查询计划的树状结构,代表整个查询的执行计划和逻辑流程。
Query的结构如下:
/*
* Query -
* Parse analysis turns all statements into a Query tree
* for further processing by the rewriter and planner.
*
* Utility statements (i.e. non-optimizable statements) have the
* utilityStmt field set, and the rest of the Query is mostly dummy.
*
* Planning converts a Query tree into a Plan tree headed by a PlannedStmt
* node --- the Query structure is not used by the executor.
*/
/*
* Query -
* 解析分析将所有语句转换成一个Query树,以便后续由重写器和规划器进行进一步处理。
* 实用语句(即不可优化的语句)会设置utilityStmt字段,而Query的其余部分大多是虚拟的。
* 规划将Query树转换成由PlannedStmt节点为头的Plan树 --- 执行器不使用Query结构。
*/
typedef struct Query
{
NodeTag type; /* 结点类型,必须为 T_Query */
QueryCommandType commandType; /* 查询类型,例如 SELECT、INSERT、UPDATE 等 */
bool canSetTag; /* 命令类型是否可以设置标记(用于DML) */
bool hasAggs; /* 查询中是否含有聚合函数 */
bool hasWindowFuncs; /* 查询中是否含有窗口函数 */
bool hasSubLinks; /* 查询中是否含有子查询 */
bool hasDistinctOn; /* 查询中是否含有DISTINCT ON子句 */
bool hasRecursive; /* 查询中是否包含递归CTE */
bool hasModifyingCTE; /* 查询中是否含有修改的CTE */
bool hasForUpdate; /* 查询中是否含有FOR UPDATE子句 */
bool hasRowSecurity; /* 查询中是否使用行级安全性 */
bool hasPartialPlans; /* 查询中是否包含部分计划 */
List *rtable; /* 查询的表引用列表(RangeTblEntry节点的列表) */
FromExpr *jointree; /* 查询的关联表达式树(FROM子句) */
List *targetList; /* 查询的目标列表(TargetEntry节点的列表) */
List *returningList; /* 查询的 RETURNING 子句列表 */
List *groupClause; /* 查询的 GROUP BY 子句列表 */
Node *havingQual; /* 查询的 HAVING 子句 */
List *distinctClause; /* 查询的 DISTINCT 子句列表 */
List *sortClause; /* 查询的 ORDER BY 子句列表 */
List *limitOffset; /* 查询的 OFFSET 子句 */
List *limitCount; /* 查询的 LIMIT 子句 */
List *rowMarks; /* 查询中的行标记列表(RowMarkClause节点的列表) */
List *setOperations; /* SET操作子查询的列表(SetOperationStmt节点的列表) */
Node *constraintDeps; /* 查询约束的依赖关系(IndexedExpr节点的链表) */
List *withCheckOptions; /* WITH CHECK OPTION的列表 */
List *returningLists; /* 规范化CTE RETURNING 子句的列表(TargetEntry节点的列表) */
List *placeholder_list; /* 用于构建树状查询计划的占位符(Placeholder节点的列表) */
List *query_parallel; /* 查询中的并行计划的列表(Query节点的列表) */
Node *partColsUpdated; /* 对于处理过的的ROW类型属性,列更新模式的布尔表达式 */
int commandTypeIndexId; /* 记录为特定命令类型重新编号的RangeTblEntry索引 */
int resultRelation; /* 查询结果的目标表的范围表条目索引 */
int utilityStmt; /* 对于UTILITY命令,此处包含原始StatementType值 */
/*
* The following two fields identify the portion of the source text string
* containing this query. They are typically only populated in top-level
* Queries, not in sub-queries. When not set, they might both be zero, or
* both be -1 meaning "unknown".
*/
int stmt_location; /* 在原始字符串中的语句的位置 */
int stmt_len; /* 在原始字符串中的语句的长度 */
} Query;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
介绍完以上流程,接着我们回到raw_parser函数中,raw_parser是通过Lex和Yacc生成的代码来进行词法和语法分析并生成分析树。Lex和Yacc是词法与语法分析工具,两者相配合可以生成用于词法和语法分析的C语言源代码。在raw_parser中,就是通过调用采用它俩预生成的函数base_yyparse来实现词法和语法分析工作。
Lex和Yacc
Lex和Yacc是两个经典的工具,用于构建词法分析器(Lexical Analyzer)和语法分析器(Parser)。它们是编译器设计和开发过程中非常重要的工具,用于处理输入的源代码,并将其转换成抽象语法树或其他数据结构以便进一步处理。
Lex:
Lex(也称为Flex)是一个词法分析器生成器。它接受一个包含词法规则的输入文件,并生成一个用于扫描源代码的词法分析器。词法分析器读取源代码字符流,识别出各个词法单元(token),并将它们传递给语法分析器。每个词法规则由正则表达式和相应的动作代码组成,用于识别不同的词法单元。
Yacc:
Yacc(也称为Bison)是一个语法分析器生成器。它接受一个包含语法规则的输入文件,并生成一个用于解析源代码的语法分析器。语法分析器接收词法分析器传递的词法单元,根据语法规则构建抽象语法树或解析树。每个语法规则由一系列产生式(产生式左侧是非终结符,右侧是终结符或非终结符)和相应的动作代码组成,用于构造语法分析树。
使用Lex和Yacc,编译器开发人员可以将源代码转换为抽象语法树,从而更方便地进行语义分析、优化和代码生成。它们可以大大简化编译器的设计和开发过程,使得编译器的实现更加模块化和可维护。除了编译器,Lex和Yacc也被广泛用于解析和处理其他领域的文本数据,例如配置文件解析、网络协议解析等。
词法分析工具Lex


以下是一个简单的 Lex 文件示例,用于识别简单的算术表达式中的运算符和数字:
%{
#include <stdio.h>
%}
// 定义一些词法单元的模式
DIGIT [0-9]
OPERATOR [+|\-|*|/]
WHITESPACE [ \t\n]
%%
// 正则表达式和对应的动作代码
{DIGIT}+ { printf("NUMBER: %s\n", yytext); }
{OPERATOR} { printf("OPERATOR: %s\n", yytext); }
{WHITESPACE} { /* 忽略空格和换行符 */ }
. { printf("INVALID CHARACTER: %s\n", yytext); }
%%
int main(void) {
// 初始化词法分析器
yylex();
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
在这个例子中,我们定义了一些词法单元的模式,例如 DIGIT 表示数字的正则表达式 [0-9],OPERATOR 表示运算符的正则表达式 [+-*/],WHITESPACE 表示空格和换行符的正则表达式 [ \t\n]。
在 %% 之后,我们定义了一系列正则表达式和对应的动作代码。例如,当遇到一串数字时,我们执行 {DIGIT}+ 中的动作代码,打印出 NUMBER: 后跟着该数字的文本。同样,当遇到一个运算符时,我们执行 {OPERATOR} 中的动作代码,打印出 OPERATOR: 后跟着该运算符的文本。对于空格和换行符,我们只是忽略它们,不做任何动作。
最后,我们使用 yylex() 来启动词法分析器,它会读取标准输入中的字符流并执行相应的动作代码。通过运行该示例程序并输入一些算术表达式,我们可以看到词法分析器输出的识别结果。
让我们假设你输入以下算术表达式:
12 + 34 * 5 - 6 / 2
那么程序的输出结果将是:
NUMBER: 12
OPERATOR: +
NUMBER: 34
OPERATOR: *
NUMBER: 5
OPERATOR: -
NUMBER: 6
OPERATOR: /
NUMBER: 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

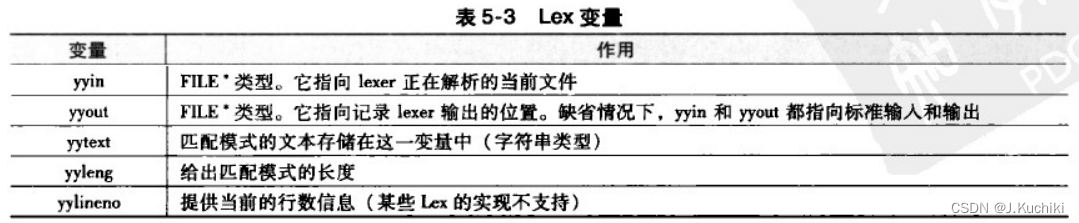
Lex 生成的扫描器在成功识别模式后,通过Lex变量(参见表5-3)存储该模式对应的值,并将其返回给上层调用者(通常是 Yacc生成的语法分析器)。
语法分析工具Yacc
Yacc(Yet Another Compiler Compiler)是一种语法分析器生成器,用于构建语法分析器(Parser)。它接受一个包含语法规则的输入文件,并生成一个用于解析源代码的语法分析器。
Yacc 解析输入的文法规则,并根据这些规则构建一个 LALR(Look-Ahead Left-to-Right Rightmost derivation)语法分析器。LALR 语法分析器用于将输入的源代码解析成语法树或抽象语法树,从而进行进一步的语义分析、优化和代码生成。
Yacc 通常与 Lex(词法分析器生成器)配合使用。在 Lex 中识别出词法单元后,Yacc 将这些词法单元组合成更复杂的语法结构,形成一个完整的解析树。这样,Lex 和 Yacc 一起构成了编译器的前端(Frontend),负责将输入的源代码转换为抽象语法树或解析树,以便进行后续的编译器处理。
案例:当我们在计算器中输入简单的算术表达式时,我们可以使用 Yacc 来构建一个语法分析器。以下是一个简单的 Yacc 示例,用于解析类似于 1 + 2 * 3 这样的算术表达式:
// Yacc
%{
#include <stdio.h>
#include <stdlib.h>
%}
// 定义词法分析器返回的词法单元
%token NUMBER
%token PLUS
%token TIMES
// 定义语法规则
%left PLUS
%left TIMES
%%
// 语法规则和对应的动作代码
expression: NUMBER
{ printf("%d\n", $1); }
;
expression: expression PLUS expression
{ $$ = $1 + $3; }
;
expression: expression TIMES expression
{ $$ = $1 * $3; }
;
%%
int yylex(void) {
int c = getchar();
if (c == '+') return PLUS;
if (c == '*') return TIMES;
if (isdigit(c)) {
ungetc(c, stdin);
scanf("%d", &yylval);
return NUMBER;
}
return c;
}
int main(void) {
// 初始化语法分析器
yyparse();
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
解释:在这个示例中,我们定义了三个词法单元 NUMBER、PLUS 和 TIMES,分别用于表示数字、加号和乘号。然后我们定义了三条语法规则,用于描述算术表达式的结构。在每个规则的右侧,我们执行一些动作代码,用于计算表达式的值。
在 yylex() 函数中,我们实现了一个简单的词法分析器,它从标准输入中读取字符,并根据输入的字符返回相应的词法单元。例如,如果遇到加号,则返回 PLUS,如果遇到数字,则读取完整的数字,并返回 NUMBER 并保存数字的值。
最后,在 main() 函数中,我们调用 yyparse() 来启动语法分析器,它会读取词法分析器返回的词法单元,并根据定义的语法规则构建解析树。然后我们可以计算和输出表达式的值。
当输入 1 + 2 * 3 时,程序将输出 7,因为它正确地处理了乘法优先级。这个简单的示例演示了如何使用 Yacc 来构建一个简单的语法分析器,从而解析和计算算术表达式。请注意,此示例是简化的,实际的语法分析器可能需要处理更复杂的语法规则和错误处理。
使用Lex和Yacc的案例
当使用 Lex 和 Yacc 结合时,经典的案例之一是构建一个简单的计算器,可以解析和计算简单的算术表达式。让我们来看一个使用 Lex 和 Yacc 结合的计算器示例:
- Lex 文件(calculator.lex):
%{
#include <stdio.h>
#include "y.tab.h" // 包含 Yacc 生成的头文件
%}
DIGIT [0-9]
OPERATOR [+|\-|*|/]
%%
{DIGIT}+ { yylval = atoi(yytext); return NUMBER; }
{OPERATOR} { return *yytext; }
[ \t\n] { /* 忽略空格和换行符 */ }
. { return *yytext; }
%%
int yywrap() {
return 1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- Yacc 文件(calculator.y):
%{
#include <stdio.h>
%}
%token NUMBER
%left '+' '-'
%left '*' '/'
%%
expression:
NUMBER { $$ = $1; }
| expression '+' expression { $$ = $1 + $3; }
| expression '-' expression { $$ = $1 - $3; }
| expression '*' expression { $$ = $1 * $3; }
| expression '/' expression { $$ = $1 / $3; }
| '(' expression ')' { $$ = $2; }
;
%%
int main() {
yyparse();
return 0;
}
int yyerror(const char *msg) {
fprintf(stderr, "Error: %s\n", msg);
return 1;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 编译和运行:
首先,我们需要生成 Lex 和 Yacc 的解析器和词法分析器代码。在终端中执行以下命令:
lex calculator.lex
yacc -d calculator.y
gcc lex.yy.c y.tab.c -o calculator
(需要安装flex包:sudo apt install flex)
(需要安装byacc包:sudo apt install byacc)
执行命令后可以看到生成的文件:
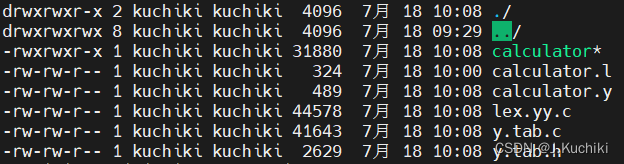
然后,我们可以运行生成的计算器程序:./calculator
词法和语法分析
词法分析和语法分析是解析 SQL 查询语句的两个重要步骤。
- 词法分析(Lexical Analysis):
词法分析是将输入的 SQL 查询字符串分解为一系列词法单元(tokens)的过程。每个词法单元代表 SQL 查询中的一个独立元素,例如关键字、标识符、运算符、常量等。词法分析器(通常由 Lex 或 Flex 工具生成)会按照预定义的规则扫描输入字符串,并将识别出的词法单元传递给语法分析器。
在 Postgres 中,词法分析器将 SQL 查询字符串转换为一系列词法单元,每个词法单元包含一个标记(token)和可能的附加信息(例如标识符的名称、常量的值等)。这些词法单元将在语法分析阶段用于构建语法树。 - 语法分析(Syntax Analysis):
语法分析是将词法分析得到的词法单元序列转换为抽象语法树(Abstract Syntax Tree,简称 AST)的过程。在这个阶段,语法分析器(通常由 Yacc 或 Bison 工具生成)会根据预定义的语法规则对词法单元进行组合,并生成一棵表示 SQL 查询结构的语法树。
在 Postgres 中,语法分析器将通过递归下降或其他解析算法,根据 SQL 查询语句的语法规则构建语法树。语法树的节点表示查询语句的不同部分,例如 SELECT 子句、FROM 子句、WHERE 子句等。每个节点都包含了查询的结构和语义信息。
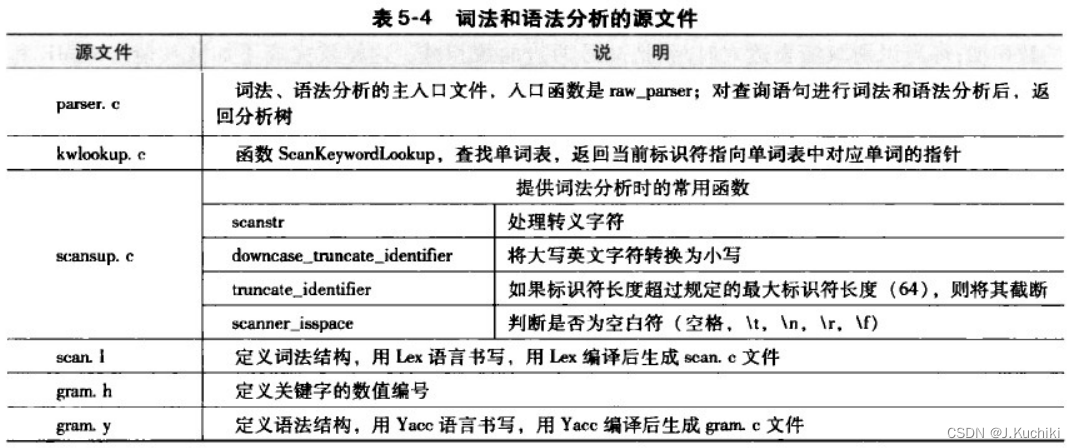
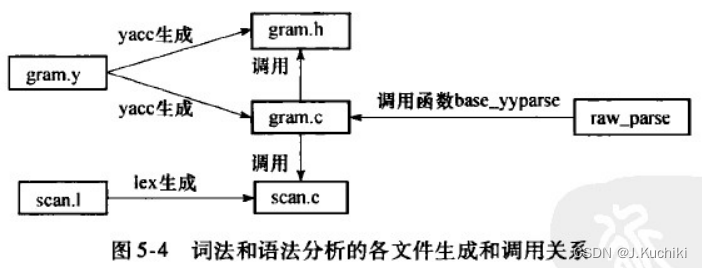
词法和语法分析的入口函数是raw_parser,该函数返回的List结构用于存储生成的分析树。
以SELECT语句为例讲解 PostgreSQL中查询语句如何被解析并生成分析树。


SelectStmt: select_no_parens %prec UMINUS
| select_with_parens %prec UMINUS
;
select_with_parens:
'(' select_no_parens ')' { $$ = $2; }
| '(' select_with_parens ')' { $$ = $2; }
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对如上代码的详细解释:
- SelectStmt 是一个非终结符,代表 SELECT 查询语句的规则。
- select_no_parens 和 select_with_parens 也是非终结符,分别代表不带括号和带括号的 SELECT 查询语句的规则。
- %prec UMINUS 是一个优先级声明,它表示在解析 SELECT 查询语句时,应该优先考虑 -(负号)运算符。这是为了处理负号运算符在 SELECT 查询语句中的正确优先级。
- ‘|’ 是一个选择符,它表示在解析 SELECT 查询语句时可以选择使用 select_no_parens 或 select_with_parens 中的任意一个规则。
- 在 select_with_parens 规则中,我们定义了两个产生式,分别处理带括号的 SELECT 查询语句:
(1)‘(’ select_no_parens ‘)’ { $$ = $2; }:这个产生式表示带括号的 SELECT 查询语句中,括号内的查询语句由 select_no_parens 规则来处理。$$ 表示当前规则的结果,$2 表示括号内的查询语句的结果。这里的意思是去掉外层的括号,直接将括号内的查询语句作为整个 SELECT 查询语句的结果。
(2)‘(’ select_with_parens ‘)’ { $$ = $2; }:这个产生式表示带括号的 SELECT 查询语句中,括号内的查询语句由 select_with_parens 规则来处理。与前一个产生式类似,它也去掉外层的括号,直接将括号内的查询语句作为整个 SELECT 查询语句的结果。
不带括号的SELECT的语法定义如下:
select_no_parens:
simple_select { $$ = $1; }
| select_clause sort_clause
{
insertSelectOptions((SelectStmt *) $1, $2, NIL,
NULL, NULL, NULL,
yyscanner);
$$ = $1;
}
| select_clause opt_sort_clause for_locking_clause opt_select_limit
{
insertSelectOptions((SelectStmt *) $1, $2, $3,
list_nth($4, 0), list_nth($4, 1),
NULL,
yyscanner);
$$ = $1;
}
| select_clause opt_sort_clause select_limit opt_for_locking_clause
{
insertSelectOptions((SelectStmt *) $1, $2, $4,
list_nth($3, 0), list_nth($3, 1),
NULL,
yyscanner);
$$ = $1;
}
| with_clause select_clause
{
insertSelectOptions((SelectStmt *) $2, NULL, NIL,
NULL, NULL,
$1,
yyscanner);
$$ = $2;
}
| with_clause select_clause sort_clause
{
insertSelectOptions((SelectStmt *) $2, $3, NIL,
NULL, NULL,
$1,
yyscanner);
$$ = $2;
}
| with_clause select_clause opt_sort_clause for_locking_clause opt_select_limit
{
insertSelectOptions((SelectStmt *) $2, $3, $4,
list_nth($5, 0), list_nth($5, 1),
$1,
yyscanner);
$$ = $2;
}
| with_clause select_clause opt_sort_clause select_limit opt_for_locking_clause
{
insertSelectOptions((SelectStmt *) $2, $3, $5,
list_nth($4, 0), list_nth($4, 1),
$1,
yyscanner);
$$ = $2;
}
;
select_clause:
simple_select { $$ = $1; }
| select_with_parens { $$ = $1; }
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
上述代码是在 PostgreSQL 的语法规则中描述 SELECT 查询语句的一部分,使用了 Bison(Yacc)的语法规则。代码段中定义了多个产生式来处理不同形式的 SELECT 查询。
- select_no_parens 是一个非终结符,代表不带括号的 SELECT 查询语句的规则。
- select_clause 也是一个非终结符,它代表简单的 SELECT 查询或带括号的 SELECT 查询。
- 在 select_no_parens 规则中,有多个产生式来处理不同形式的 SELECT 查询:
(1)simple_select:这个产生式表示一个简单的 SELECT 查询,没有排序、限制或锁定选项。$$ = $1; 表示将结果设置为 simple_select 规则的结果。
(2)select_clause sort_clause:这个产生式表示一个带排序选项的 SELECT 查询。insertSelectOptions 函数用于将排序选项插入到查询中。$1 代表 select_clause 规则的结果,而 $2 代表 sort_clause 规则的结果。$$ = $1; 表示将结果设置为 select_clause 规则的结果。
(3)其他产生式与上面类似,用于处理带排序、限制、锁定等选项的 SELECT 查询。- select_clause 规则中,也有两个产生式:
simple_select 和 select_with_parens:这两个产生式与 select_no_parens 规则中的对应产生式相同,用于处理简单的 SELECT 查询和带括号的 SELECT 查询。
从以上代码可以看出,一条不带括号的SELECT语句可以定义为一条简单的SELECT语句(用标识符simple_select表示),也可以定义为在简单SELECT语句后接排序子句(标识符sort_clause),LIMIT子句(标识符select_limit)等构成的复杂语句。可以看到,对于整个语句的语法分析实际上是将语句拆分成很多小的语法单元,然后分别对这些小的单元进行分析。因此,只要弄清楚各个小语法单元的做法,就可以把它们组合在一起形成整个语法树。这里我们着重分析simple_select的语法定义。

源码如下:
simple_select:
SELECT opt_all_clause opt_target_list
into_clause from_clause where_clause
group_clause having_clause window_clause
{
SelectStmt *n = makeNode(SelectStmt);
n->targetList = $3;
n->intoClause = $4;
n->fromClause = $5;
n->whereClause = $6;
n->groupClause = $7;
n->havingClause = $8;
n->windowClause = $9;
$$ = (Node *)n;
}
| SELECT distinct_clause target_list
into_clause from_clause where_clause
group_clause having_clause window_clause
{
SelectStmt *n = makeNode(SelectStmt);
n->distinctClause = $2;
n->targetList = $3;
n->intoClause = $4;
n->fromClause = $5;
n->whereClause = $6;
n->groupClause = $7;
n->havingClause = $8;
n->windowClause = $9;
$$ = (Node *)n;
}
| values_clause { $$ = $1; }
| TABLE relation_expr
{
/* same as SELECT * FROM relation_expr */
ColumnRef *cr = makeNode(ColumnRef);
ResTarget *rt = makeNode(ResTarget);
SelectStmt *n = makeNode(SelectStmt);
cr->fields = list_make1(makeNode(A_Star));
cr->location = -1;
rt->name = NULL;
rt->indirection = NIL;
rt->val = (Node *)cr;
rt->location = -1;
n->targetList = list_make1(rt);
n->fromClause = list_make1($2);
$$ = (Node *)n;
}
| select_clause UNION all_or_distinct select_clause
{
$$ = makeSetOp(SETOP_UNION, $3, $1, $4);
}
| select_clause INTERSECT all_or_distinct select_clause
{
$$ = makeSetOp(SETOP_INTERSECT, $3, $1, $4);
}
| select_clause EXCEPT all_or_distinct select_clause
{
$$ = makeSetOp(SETOP_EXCEPT, $3, $1, $4);
}
;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
源码分析:
1.第一个产生式
SELECT opt_all_clause opt_target_list
into_clause from_clause where_clause
group_clause having_clause window_clause
{
SelectStmt *n = makeNode(SelectStmt);
n->targetList = $3;
n->intoClause = $4;
n->fromClause = $5;
n->whereClause = $6;
n->groupClause = $7;
n->havingClause = $8;
n->windowClause = $9;
$$ = (Node *)n;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这个产生式表示处理普通的 SELECT 查询,其中包含了多个可选子句,如 DISTINCT、INTO、WHERE、GROUP BY、HAVING、WINDOW。当解析到这种形式的 SELECT 查询时,使用产生式的动作部分将解析到的各个子句信息填入 SelectStmt 结构体中,并将结果设置为该结构体的指针。
2.第二个产生式
SELECT distinct_clause target_list
into_clause from_clause where_clause
group_clause having_clause window_clause
{
SelectStmt *n = makeNode(SelectStmt);
n->distinctClause = $2;
n->targetList = $3;
n->intoClause = $4;
n->fromClause = $5;
n->whereClause = $6;
n->groupClause = $7;
n->havingClause = $8;
n->windowClause = $9;
$$ = (Node *)n;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这个产生式表示处理带 DISTINCT 子句的 SELECT 查询。与前一个产生式类似,将解析到的子句信息填入 SelectStmt 结构体中,并将结果设置为该结构体的指针。
3.第三个产生式
values_clause
{
$$ = $1;
}
- 1
- 2
- 3
- 4
这个产生式表示处理 VALUES 子句,用于创建一个虚拟表以供查询。
4.第三个产生式
TABLE relation_expr
{
/* same as SELECT * FROM relation_expr */
ColumnRef *cr = makeNode(ColumnRef);
ResTarget *rt = makeNode(ResTarget);
SelectStmt *n = makeNode(SelectStmt);
cr->fields = list_make1(makeNode(A_Star));
cr->location = -1;
rt->name = NULL;
rt->indirection = NIL;
rt->val = (Node *)cr;
rt->location = -1;
n->targetList = list_make1(rt);
n->fromClause = list_make1($2);
$$ = (Node *)n;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这个产生式表示处理形如 TABLE name 的查询,其效果相当于 SELECT * FROM name,即选择表 name 的所有列。
5.后续三个产生式
select_clause UNION all_or_distinct select_clause
{
$$ = makeSetOp(SETOP_UNION, $3, $1, $4);
}
select_clause INTERSECT all_or_distinct select_clause
{
$$ = makeSetOp(SETOP_INTERSECT, $3, $1, $4);
}
select_clause EXCEPT all_or_distinct select_clause
{
$$ = makeSetOp(SETOP_EXCEPT, $3, $1, $4);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这三个产生式分别表示处理 UNION、INTERSECT 和 EXCEPT 三种集合操作,将两个 SELECT 查询进行合并。
总结:
以上代码中的产生式定义了不同形式的 SELECT 查询,并通过动作部分将解析到的子句信息填入 SelectStmt 结构体中,用于构建查询语句的抽象语法树。这些语法规则将用于在 PostgreSQL 中解析 SELECT 查询语句,并生成对应的抽象语法树,表示查询的结构。
SelectStmt结构体如下所示:(路径:src/include/nodes/parsenodes.h)
typedef struct SelectStmt
{
NodeTag type;
/*
* These fields are used only in "leaf" SelectStmts.
*/
List *distinctClause; /* NULL, list of DISTINCT ON exprs, or
* lcons(NIL,NIL) for all (SELECT DISTINCT) */
IntoClause *intoClause; /* target for SELECT INTO */
List *targetList; /* the target list (of ResTarget) */
List *fromClause; /* the FROM clause */
Node *whereClause; /* WHERE qualification */
List *groupClause; /* GROUP BY clauses */
Node *havingClause; /* HAVING conditional-expression */
List *windowClause; /* WINDOW window_name AS (...), ... */
/*
* In a "leaf" node representing a VALUES list, the above fields are all
* null, and instead this field is set. Note that the elements of the
* sublists are just expressions, without ResTarget decoration. Also note
* that a list element can be DEFAULT (represented as a SetToDefault
* node), regardless of the context of the VALUES list. It's up to parse
* analysis to reject that where not valid.
*/
List *valuesLists; /* untransformed list of expression lists */
/*
* These fields are used in both "leaf" SelectStmts and upper-level
* SelectStmts.
*/
List *sortClause; /* sort clause (a list of SortBy's) */
Node *limitOffset; /* # of result tuples to skip */
Node *limitCount; /* # of result tuples to return */
List *lockingClause; /* FOR UPDATE (list of LockingClause's) */
WithClause *withClause; /* WITH clause */
/*
* These fields are used only in upper-level SelectStmts.
*/
SetOperation op; /* type of set op */
bool all; /* ALL specified? */
struct SelectStmt *larg; /* left child */
struct SelectStmt *rarg; /* right child */
/* Eventually add fields for CORRESPONDING spec here */
} SelectStmt;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
中文版本如下:
typedef struct SelectStmt
{
NodeTag type; // 结点类型标记
/*
* 这些字段仅在“叶子”SelectStmt中使用。
*/
List *distinctClause; // DISTINCT子句,可以是NULL,表示没有DISTINCT,或者是DISTINCT ON表达式的列表,或者是lcons(NIL, NIL)表示所有的(SELECT DISTINCT)
IntoClause *intoClause; // SELECT INTO的目标
List *targetList; // 目标列表,即SELECT后面的表达式列表(ResTarget)
List *fromClause; // FROM子句,表示查询的数据来源
Node *whereClause; // WHERE条件,用于过滤查询结果
List *groupClause; // GROUP BY子句,表示按照哪些列进行分组
Node *havingClause; // HAVING条件表达式,用于过滤分组后的结果
List *windowClause; // WINDOW子句,表示定义的窗口函数
/*
* 在表示VALUES列表的"叶子"节点中,上面的字段都为空,取而代之的是设置了这个字段。
* 注意,子列表的元素只是表达式,没有ResTarget装饰。
* 还要注意,列表元素可以是DEFAULT(表示为SetToDefault节点),而不管VALUES列表的上下文是什么。解析分析时将在不合法的情况下拒绝。
*/
List *valuesLists; // 未转换的表达式列表的列表
/*
* 这些字段在“叶子”SelectStmt和上层SelectStmt中都使用。
*/
List *sortClause; // 排序子句(SortBy列表)
Node *limitOffset; // 跳过的结果元组数目
Node *limitCount; // 返回的结果元组数目
List *lockingClause; // FOR UPDATE子句(LockingClause列表)
WithClause *withClause; // WITH子句
/*
* 这些字段仅在上层SelectStmt中使用。
*/
SetOperation op; // 集合操作的类型
bool all; // 是否指定了ALL
struct SelectStmt *larg; // 左子树
struct SelectStmt *rarg; // 右子树
/* 最终在这里添加CORRESPONDING spec的字段 */
} SelectStmt;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
举例:
假设我们有以下简单的 SELECT 查询语句:
SELECT column1, column2 FROM table_name WHERE column3 = 10;
查询语句的解析过程如下:
3. 词法分析(Lexical Analysis):
词法分析器将查询字符串分解为一系列词法单元(tokens)。在这个例子中,可能的词法单元包括:
SELECT (关键字)
column1 (标识符)
, (逗号)
column2 (标识符)
FROM (关键字)
table_name (标识符)
WHERE (关键字)
column3 (标识符)
= (等号)
10 (常量)
; (分号)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 语法分析(Syntax Analysis):
语法分析器根据预定义的语法规则将词法单元序列转换为抽象语法树(AST)。在这个例子中,语法树的节点表示查询的不同部分:
SELECT
/ \
column1 column2
\ /
FROM
|
table_name
|
WHERE
/ \
column3 =
|
10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在上述语法树中,每个节点代表查询语句的一部分。例如,根节点是 SELECT 关键字,它有两个子节点分别代表 column1 和 column2。FROM 子句也是根节点的子节点,它有一个子节点代表表名 table_name。WHERE 子句是 FROM 子句的子节点,它有两个子节点分别代表 column3 和等号操作符,以及一个子节点代表常量 10。
- 分析树(Parse Tree)生成:
在语法分析过程中,语法分析器构建了抽象语法树。该语法树称为分析树(Parse Tree),它是表示查询语句结构的一种层次结构。每个节点都表示查询语句的一个组成部分,并且具有与之相关的语义信息。分析树将用于后续的查询优化和执行。
值得注意的是,语法分析器在生成分析树时可能会对输入进行验证,例如检查语法错误和语义错误。如果存在错误,语法分析器将报告错误并终止解析过程。
语义分析
语义分析(Semantic Analysis)是编译器或解释器中的一个重要阶段,用于对源代码进行深层次的语义检查和解释。它的主要作用是确保程序在语义上是合法的,并进行语义转换和语义解释,以便进行后续的优化和执行。
语义分析的目的是检查程序的语义正确性,即确定程序是否符合编程语言的语义规则和约束。它涉及对语句、表达式、类型、作用域、符号引用等进行分析和验证。具体来说,语义分析会执行以下任务:
- 类型检查:验证表达式和操作符之间的类型兼容性,确保不会出现类型错误,例如将字符串与数字相加。
- 符号表管理:建立符号表并管理标识符的声明和引用。检查变量、函数、类等标识符的作用域、可见性和重复定义等问题。
- 语义约束检查:检查语法规则以外的语义约束,例如数组索引必须是整数、函数调用的参数数量与声明的参数数量匹配等。
- 类型推导:在一些语言中,根据上下文推导出表达式的类型,以减少显式类型注释的需求。
- 常量折叠:对于常量表达式,进行计算和简化,以便在编译时进行优化。
通过进行语义分析,编译器或解释器能够检测和报告源代码中的潜在错误,并确保程序在语义上是一致和合法的。它为后续的代码优化、代码生成和程序执行提供了准确的基础。
exec_simple_query 在从词法和语法分析模块获取了parsetree_list之后,会对其中每一棵分析树调用pg_analyze_and_rewrite进行语义分析和查询重写,而在其中负责语义分析的则是analyze. c文件中的parse_analyze 函数。parse_analyze 会根据分析树生成一个对应的查询树,而查询重写模块则继续对这一查询树进行修改,并且有可能会将这个查询树改写成一个包含多棵查询树的链表。因此,pg_analyze_and_rewrite最终返回给exec_simple_query的将是一个查询树链表。
parse_analyze的源码如下:
/*
* parse_analyze
* Analyze a raw parse tree and transform it to Query form.
* 对原始解析树进行分析并转换为查询表单。
*
* Optionally, information about $n parameter types can be supplied.
* References to $n indexes not defined by paramTypes[] are disallowed.
*
* The result is a Query node. Optimizable statements require considerable
* transformation, while utility-type statements are simply hung off
* a dummy CMD_UTILITY Query node.
* 结果是一个 Query 节点。
* 可优化的语句需要进行相当大的转换,
* 而实用程序类型的语句只需挂在一个虚拟的 CMD_UTILITY Query 节点上。
*/
Query *
parse_analyze(RawStmt *parseTree, const char *sourceText,
Oid *paramTypes, int numParams,
QueryEnvironment *queryEnv)
{
/* 创建一个解析状态结构体 */
ParseState *pstate = make_parsestate(NULL);
Query *query;
/* 检查源文本是否为空(从8.4版本开始是必需的) */
Assert(sourceText != NULL);
/* 将源文本保存到解析状态结构体中 */
pstate->p_sourcetext = sourceText;
/* 如果提供了参数类型信息,则将参数设置为解析状态结构体中 */
if (numParams > 0)
parse_fixed_parameters(pstate, paramTypes, numParams);
/* 设置查询环境 */
pstate->p_queryEnv = queryEnv;
/* 转换原始解析树为查询树 */
query = transformTopLevelStmt(pstate, parseTree);
/* 如果有后解析分析钩子函数,则在此调用 */
if (post_parse_analyze_hook)
(*post_parse_analyze_hook) (pstate, query);
/* 释放解析状态结构体的内存 */
free_parsestate(pstate);
/* 返回转换后的查询树 */
return query;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
在parse_analyze函数中,将根据命令类型分七种情况处理(参考函数transformStmt),如图5-15所示。经过语义分析之后,会生成查询树(Query 结构,见数据结构5.6)。其中SELECT/INSERDELETE/UPDATE这四种情况所生成的查询树会经由查询重写和查询优化作进一步处理。
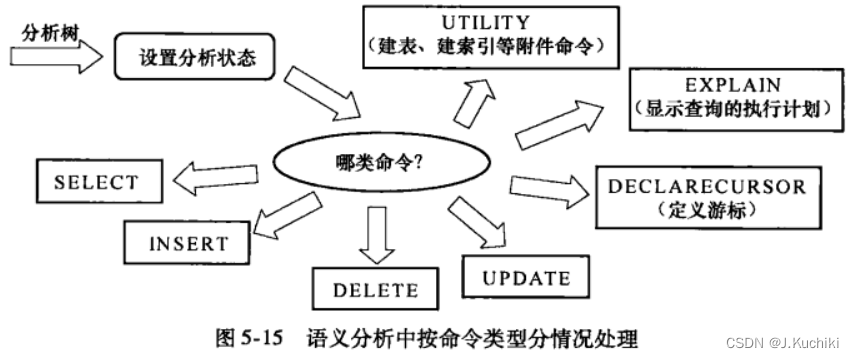
该过程涉及两个重要的结构体:Query 和 ParseState。Query (用于存储查询树)是查询分析的最终输出结果,其中许多字段可以在分析树的相关结构体中找到对应项,其详细介绍参考先前的代码结构。ParseState结构则用于记录语义分析的中间信息。
ParseState源码如下:
struct ParseState
{
struct ParseState *parentParseState; /* stack link */
const char *p_sourcetext; /* source text, or NULL if not available */
List *p_rtable; /* range table so far */
List *p_joinexprs; /* JoinExprs for RTE_JOIN p_rtable entries */
List *p_joinlist; /* join items so far (will become FromExpr
* node's fromlist) */
List *p_namespace; /* currently-referenceable RTEs (List of
* ParseNamespaceItem) */
bool p_lateral_active; /* p_lateral_only items visible? */
List *p_ctenamespace; /* current namespace for common table exprs */
List *p_future_ctes; /* common table exprs not yet in namespace */
CommonTableExpr *p_parent_cte; /* this query's containing CTE */
Relation p_target_relation; /* INSERT/UPDATE/DELETE target rel */
RangeTblEntry *p_target_rangetblentry; /* target rel's RTE */
bool p_is_insert; /* process assignment like INSERT not UPDATE */
List *p_windowdefs; /* raw representations of window clauses */
ParseExprKind p_expr_kind; /* what kind of expression we're parsing */
int p_next_resno; /* next targetlist resno to assign */
List *p_multiassign_exprs; /* junk tlist entries for multiassign */
List *p_locking_clause; /* raw FOR UPDATE/FOR SHARE info */
bool p_locked_from_parent; /* parent has marked this subquery
* with FOR UPDATE/FOR SHARE */
bool p_resolve_unknowns; /* resolve unknown-type SELECT outputs as
* type text */
QueryEnvironment *p_queryEnv; /* curr env, incl refs to enclosing env */
/* Flags telling about things found in the query: */
bool p_hasAggs;
bool p_hasWindowFuncs;
bool p_hasTargetSRFs;
bool p_hasSubLinks;
bool p_hasModifyingCTE;
Node *p_last_srf; /* most recent set-returning func/op found */
/*
* Optional hook functions for parser callbacks. These are null unless
* set up by the caller of make_parsestate.
*/
PreParseColumnRefHook p_pre_columnref_hook;
PostParseColumnRefHook p_post_columnref_hook;
ParseParamRefHook p_paramref_hook;
CoerceParamHook p_coerce_param_hook;
void *p_ref_hook_state; /* common passthrough link for above */
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48


函数parse_analyze首先将生成一个ParseState结构用于记录语义分析的状态,然后通过调用函数transformStmt 来完成语义分析过程。函数transformStmt 会根据不同的查询类型调用相应的函数进行处理。从词法和语法分析中介绍的数据结构可以看到,PostgreSQL 中几乎每一个数据结构的第一个字段都是NodeTag类型的 type。在 PostgreSQL为了传递参数方便,把很多数据节点的指针都通过指针类型转换成Node结构的指针,Node结构中只有一个类型为NodeTag名为type的字段,通过这样一种方式PostgreSQL把大多数要传递的数据结构都包装成了称为“Node”(节点〉的统一形式,从而通过一套统一的操作函数进行处理。为了能够确定接收到的数据结构到底是哪一种,Post-greSQL中把 NodeTag设计成了一个枚举类型,每一种数据结构都在其中对应–个值,这些值的名称都由“T_”及其数据类型名称组成,例如SelectStmt数据结构对应的NodeTag值就是“T_SelectStmt”。
transformStmt函数只有两个参数,一个是ParseState,另一个就是要处理的包装成节点的分析树。通过节点type字段,transformStmt可以处理七种分析树,相应的处理函数见表5-9。