
- 12024秋招阿里产品面试,学习编程的5大支柱,京东健康java面试
- 2等保二级和等保三级怎么做_等保二级 nextjs
- 3ECAI 2024投稿指南_ecai2024
- 4Android Studio导入项目非常慢——卡在Building '项目名' Gradle project info_importing"项目名"gradle project
- 5vue中list、String一些常用方法(自己总结,不断更新)_vue3 事件解析list
- 6使用Arduino和Proteus仿真实例-DS3232高精度实时时钟驱动仿真物联网_proteus ds3232不走
- 7【算法-LeetCode】129. 求根节点到叶节点数字之和(递归;回溯)_leetc129
- 8UTS iOS插件
- 9【LLM系列之LLaMA】LLaMA: Open and Efficient Foundation Language Models_llama西班牙语语料库
- 10【0005】 详聊PostgreSQL中 GROUP BY(分组)的使用_pgsql group by
Hadoop(一)Hadoop概述
赞
踩
1.Hadoop基本结构
Hadoop是一个分布式系统基础架构,主要解决海量数据的存储和海量数据的分析计算问题。
Hadoop组成:
- Hadoop Common(辅助工具): The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (数据存储): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN(资源调度): A framework for job scheduling and cluster resource management.
- Hadoop MapReduce(数据处理与计算): A YARN-based system for parallel processing of large data sets.
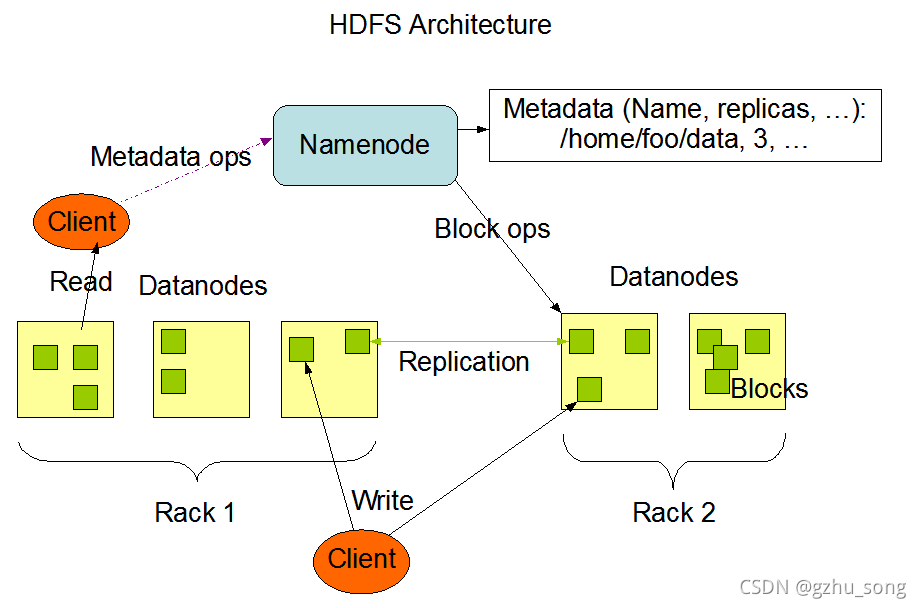
1.1 HDFS架构
NameNode 指明每个文件块存在哪个节点上 DataNode存储实实在在的数据
1、NameNode是一个中心服务器,单一节点(简化系统的设计和实现,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问
2、文件操作,Namenode是负责文件元数据的操作,它知道数据的存放位置(例如NN知道数据块1存在001、006、008三台机器)。这些信息不是长久固定的,每次启动系统后需要重新从数据节点获取这些信息。Datanode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过Namenode,只询问它跟哪个DataNode联系,否则Namenode会成为系统的瓶颈
3、 副本存放在哪些Datanode上由Namenode来控制,根据全局情况作出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低读取网络开销和读取延时。HDFS分布式文件系统的内部有一个副本存放策略:以默认的副本数=3为例:①第一个副本块存本机(若客户端在集群中,不在的话随机选择一个较近的机器)②第二个副本在另一个机架的随机节点③第三个副本在第二个副本所处机架的随机节点
4、Namenode全权管理数据库的复制,它周期性的从集群中的每Datanode接收心跳信合和状态报告,接收到心跳信号意味着DataNode节点工作正常,块状态报告包含了一个该DataNode上所有的数据列表
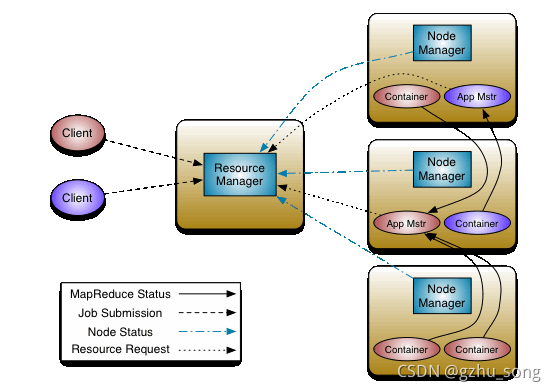
1.2 YARN架构
- Resource Manager:整个集群资源的统一管理者
- Node Manager:单个节点服务器的资源管理者
- App Mstr:单个任务运行的管理者
- Container:相当于一台独立服务器,里面有任务运行所需要的资源,比如CPU、磁盘、网络等
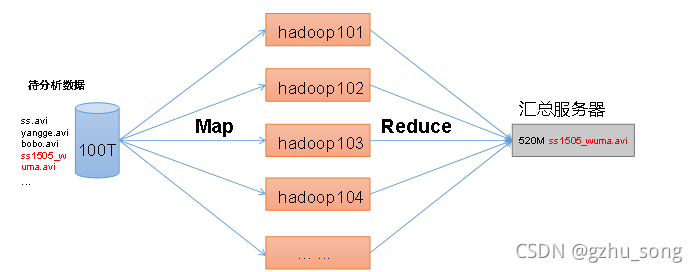
1.3 MapReduce架构
MapReduce将计算过程分为两个阶段:Map和Reduce
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
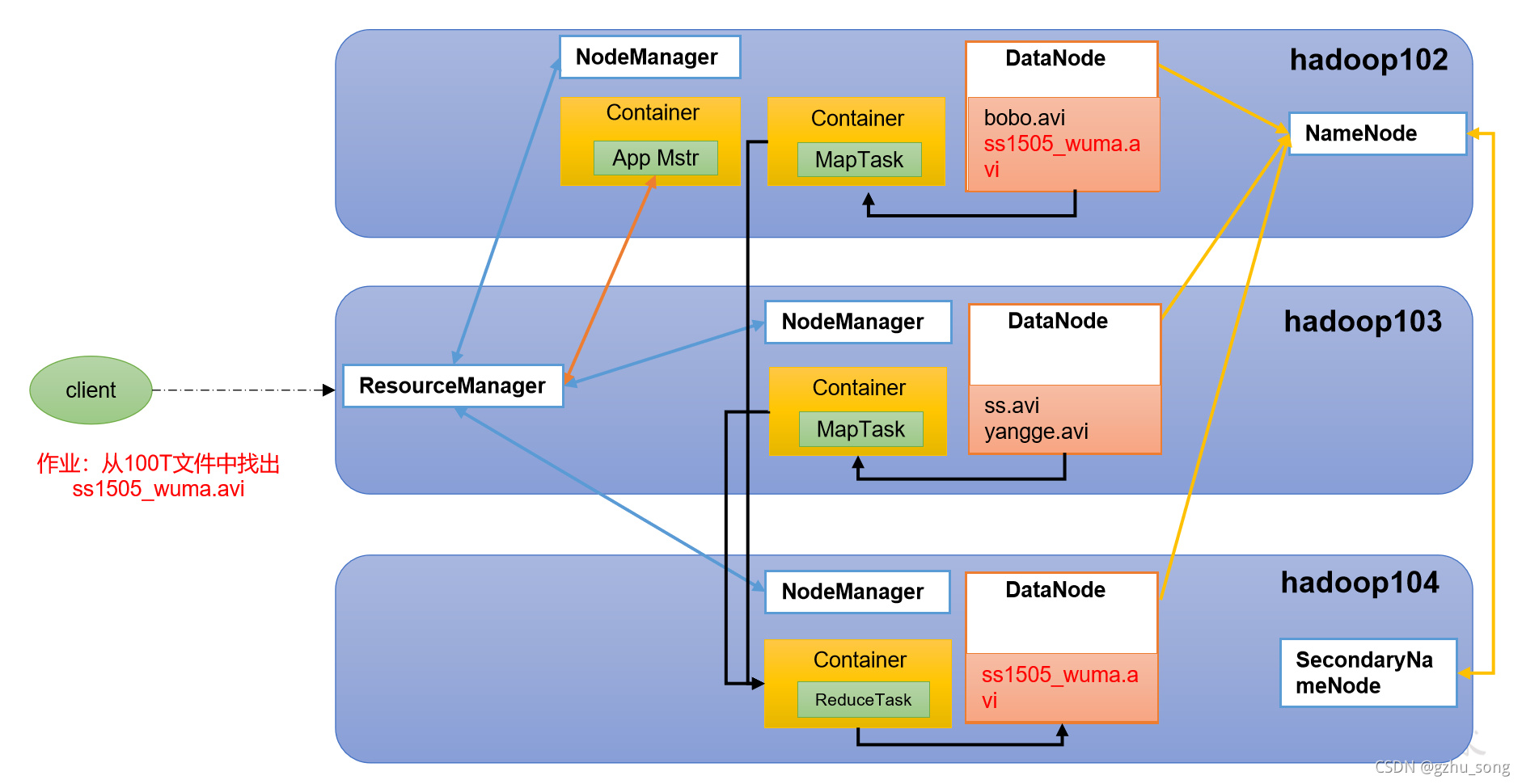
1.4 HDFS、YARN、MapReduce三者关系
工作过程概述:
1.用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
2.ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序ApplicationMaster
3.ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7
4.ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源
5.一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务
6.NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务MapTask
7.各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态
8.最后经过ReduceTask将结果返回写到磁盘,HDFS做相应的存储
9.应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己
关于SecondaryNameNode:
链接: https://blog.csdn.net/xh16319/article/details/31375197
2.Hadoop优势
- 高可用性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算节点出现故障,也不会导致数据丢失

- 高扩展性:在集群间分配任务数据,可以方便的扩展数以千计的节点
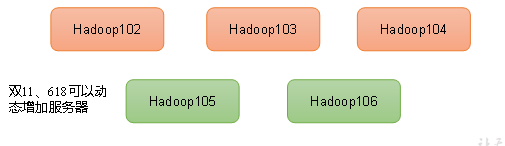
- 高效性:Hadoop是并行处理数据的

- 高容错性:能够用自动将失败的任务重新分配

3.安装JDK与Hadoop
相关压缩包在文章末尾
3.1 安装JDK
1、卸载现有JDK
注意:安装JDK前,一定确保提前删除了虚拟机自带的JDK
2、用XShell传输工具将JDK导入到opt目录下面的software文件夹下面
3、在Linux系统下的opt目录中查看软件包是否导入成功
[gzhu@hadoop102 ~]$ ls /opt/software/
- 1
4、解压JDK到/opt/module目录下
[gzhu@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
- 1
5、配置JDK环境变量
①新建/etc/profile.d/my_env.sh文件
[gzhu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
- 1
添加如下内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
- 1
- 2
- 3
②保存后退出 :wq
③source一下/etc/profile文件,让新的环境变量PATH生效
[gzhu@hadoop102 ~]$ source /etc/profile
- 1
6、测试JDK是否安装成功
[gzhu@hadoop102 ~]$ java -version
- 1
如果能看到以下结果,则代表Java安装成功。
java version “1.8.0_212”
注意:重启(如果java -version可以用就不用重启)
[gzhu@hadoop102 ~]$ sudo reboot
- 1
3.2 安装Hadoop
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
1、用XShell文件传输工具将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面
2、进入到Hadoop安装包路径下
[gzhu@hadoop102 ~]$ cd /opt/software/
- 1
3、解压安装文件到/opt/module下面
[gzhu@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
- 1
4、查看是否解压成功
[gzhu@hadoop102 software]$ ls /opt/module/
- 1
显示hadoop-3.1.3即成功
5、将Hadoop添加到环境变量
①获取Hadoop安装路径
[gzhu@hadoop102 hadoop-3.1.3]$ pwd /opt/module/hadoop-3.1.3
- 1
②打开/etc/profile.d/my_env.sh文件
[gzhu@hadoop102 hadoop-3.1.3]$ sudo vim /etc/profile.d/my_env.sh
- 1
在my_env.sh文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 1
- 2
- 3
- 4
保存并退出: :wq
③让修改后的文件生效
[gzhu@hadoop102 hadoop-3.1.3]$ source /etc/profile
- 1
6、测试是否安装成功
[gzhu@hadoop102 hadoop-3.1.3]$ hadoop version
- 1
7、重启(如果Hadoop命令不能用再重启虚拟机)
[gzhu@hadoop102 hadoop-3.1.3]$ sudo reboot
- 1

