
热门标签
热门文章
- 1大模型部署手记(3)通义千问+Windows GPU_通义千问 win11部署
- 2软件无线电安全之GNU Radio基础 -上
- 3【备战秋招】每日一题:2023.05-B卷-华为OD机试 - 宜居星球改造计划
- 4【oracle数据库安装篇一】Linux5.6基于LVM安装oracle10gR2单机_oracle10g r2
- 5记录一次操作git 的愚蠢行为(本地代码只 git add 过,没有 commit ,push 过,然后版本回退 导致本地代码丢失)_git在回退版本后本地代码没了
- 6Flink学习(二) job 执行流程
- 7前端小白入门区块链系列04
- 8计算机大数据毕设选题推荐Hadoop项目,Spark,Hive,Flink_基于hadoop的项目
- 9PHP定时任务框架taskPHP3.0学习记录4宝塔面板bash定时任务(轮询指定json文件字段后确定是否执行、环境部署、执行日志、文件权限)
- 10SpringBoot 解决跨域问题的 5 种方案!_springboot解决跨域
当前位置: article > 正文
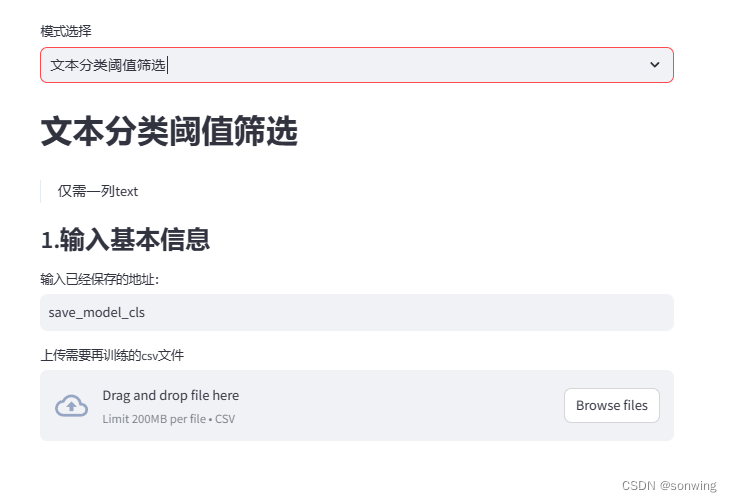
学术垃圾-文本分类
作者:繁依Fanyi0 | 2024-04-25 19:10:52
赞
踩
学术垃圾-文本分类
文本分类的训练、推理
基于transformers包,huggingface的社区,streamlit的界面。简单记录当前的内容。
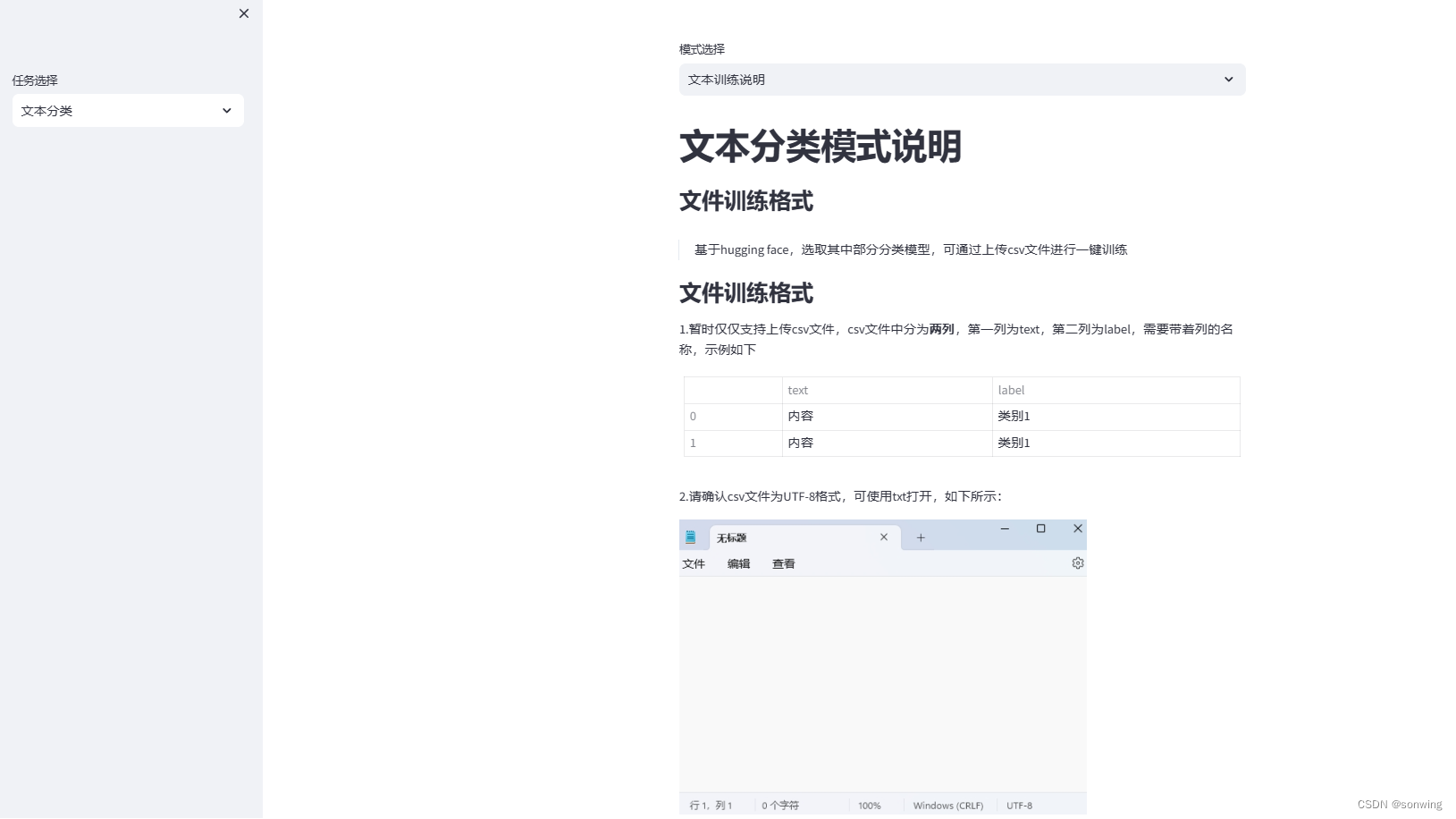
文本分类训练的说明
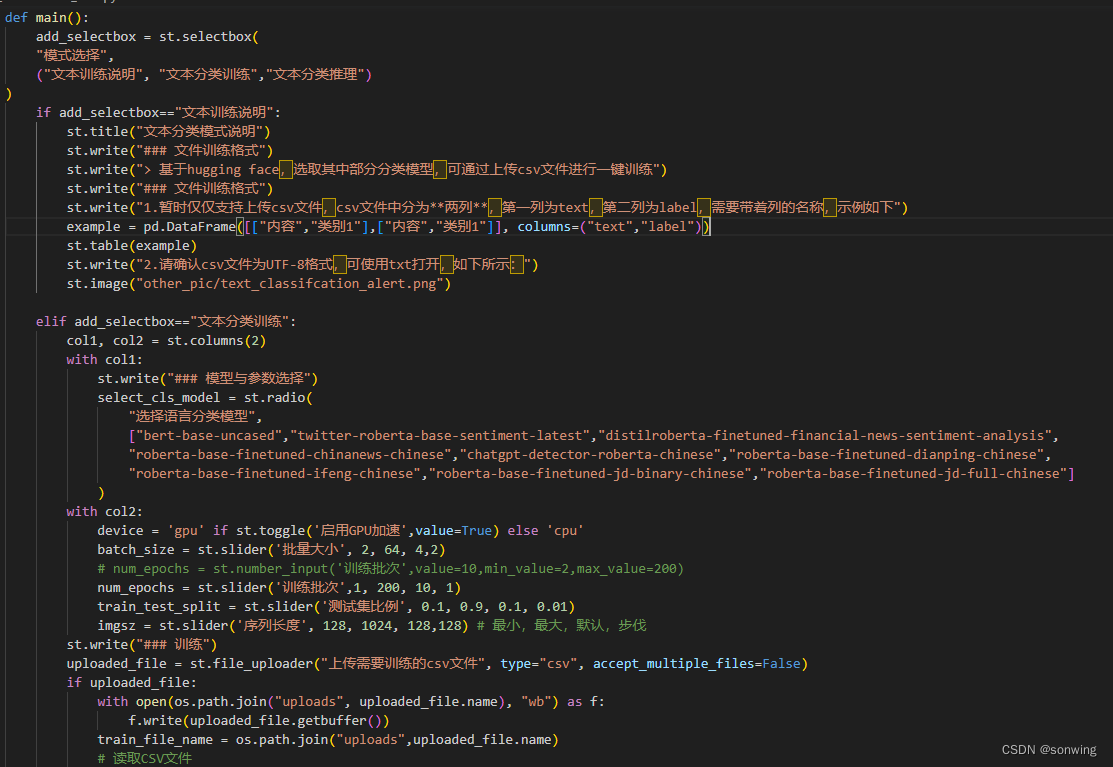
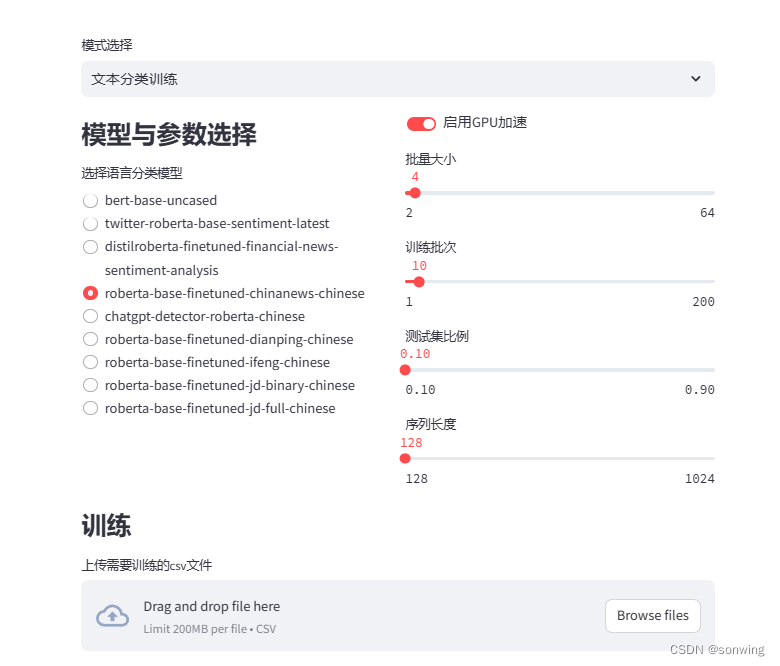
文本分类训练
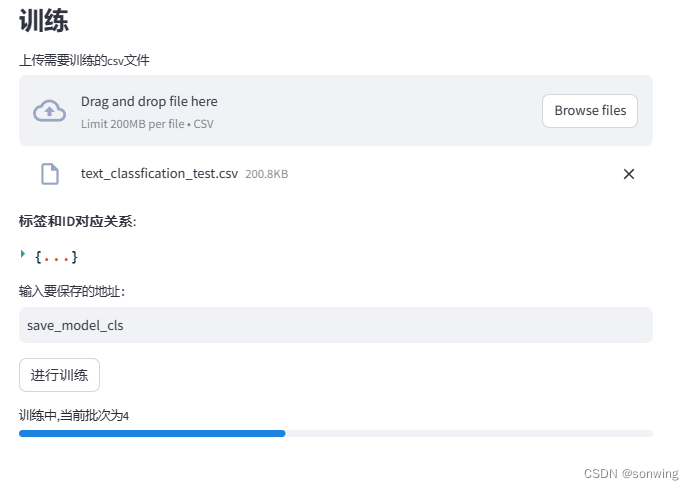
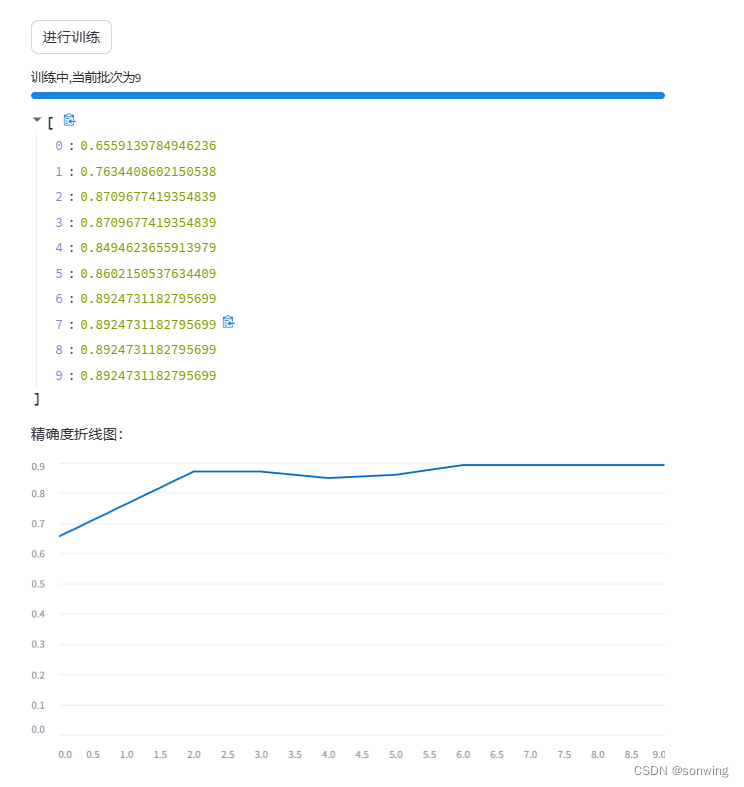
训练标签与ID的对应关系和训练进度条的展示,保存最佳模型,用于后续的推理。
精度折线图和精度
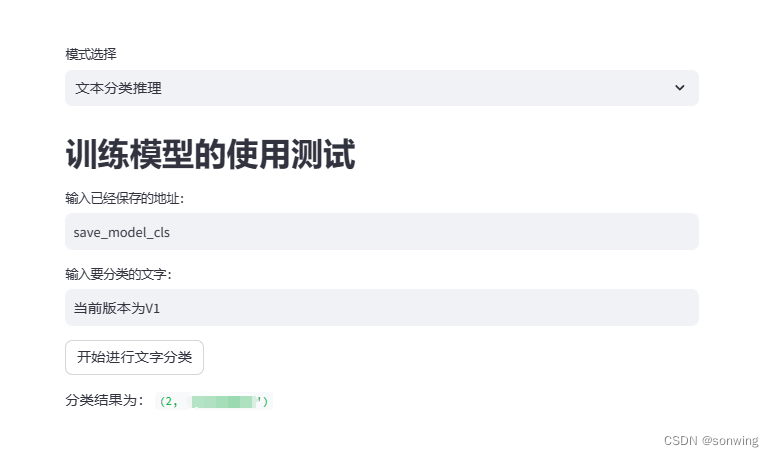
文本分类推理
输出分类结果类别以及名称
PLAN迭代训练
- 使用小量数据训练模型,得到初始模型A
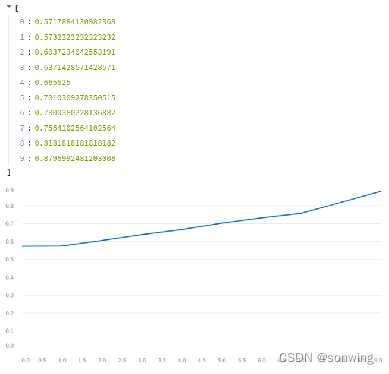
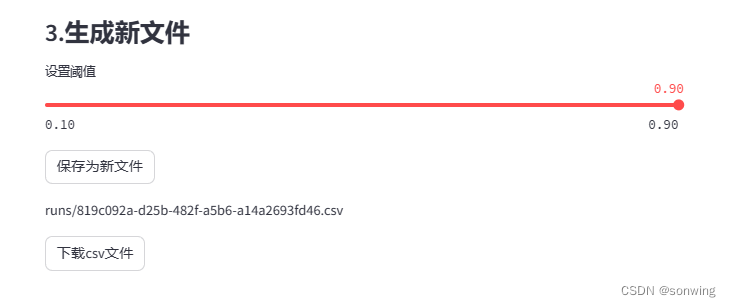
- 使用模型A,对数据进行标注,标注时使用阈值筛选分数较大的部分,这部分简单做了个实验,简单证明了一下可行性。阈值从0到0.9的效果,一个是分数一个是数量。
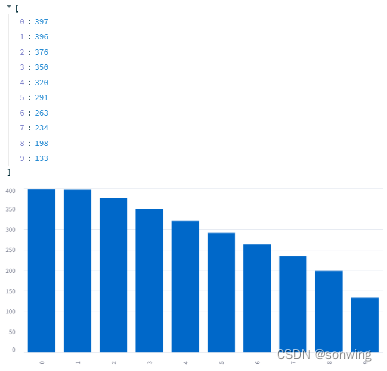
- 对新数据进行筛选与数据标注,使用模型A,设置阈值进行标注,整体基于前面保存的模型地址。
- 重新对模型A训练,方式待定(得学一下半监督学习了),得到模型B。
- 使用模型B再反复进行以上的操作
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/486810
推荐阅读
相关标签

