
- 1Gitea 的简单介绍
- 2面向对象设计原则详解:迪米特法则_迪米特原则 菜鸟
- 3flask服务中如何request获取请求的headers信息
- 4云计算时代改变了什么?_大数据、云计算改变了什么的结果
- 5Q-learning算法理论及应用_q-learning算法中的状态值是怎么表达的
- 6android genymotion模拟器怎么使用以及和google提供的模拟器性能对比
- 7深入了解PyTorch的文本摘要和文本生成技术
- 8字节跳动面试分享,android内存优化面试题
- 9git分支回滚之后,无法合并的问题及解决方式_git回退版本以后重新合并
- 10稀疏卷积Submanifold Sparse Convolutional Networks
Hive3.1.3版本安装部署_hive 3.1.3安装
赞
踩
前言
Hive作为大数据生态中的一员,曾经也是一个热门的组件,特别是在数据仓库类的项目中,扮演着一个重要的角色,比如版本管理、历史数据追溯等,今年来随着实时要求的增多,该组件的热度也随之降低,但它作为一种离线数据分析的工具,还是比较成熟稳定的。
提示:下面案例仅供参考
一、安装准备
1.下载安装介质
登录hive官网地址https://hive.apache.org/general/downloads/,选择版本下载安装包,推荐下载3.x版本,虽然目前最新的版本是4.0,但该版本处于beta状态,对于一些历史项目或多或少会有一些兼容性的问题,本篇以hive3.1.3版本为例.
2.上传服务器并解压
使用ftp工具(xshell、putty、termius等等)上传安装包至服务器,并执行tar -zxvf apache-hive-3.1.3-bin.tar.gz命令解压安装包,由于名称过长,我这边将名称改成hive-3.1.3(执行mv apache-hive-3.1.3-bin hive-3.1.3命令)
二、安装配置
1.配置环境变量
上篇安装hadoop的文章中提到了具体的环境变量配置细节,这里就不再重复赘述,执行 vim(或者vi ) /etc/profile.d/my_env.sh,输入以下内容:
export HIVE_HOME=/application/soft/hive-3.1.3
export HIVE_CONF_DIR=/application/soft/hive-3.1.3/conf
export PATH=$PATH:$HIVE_HOME/bin
- 1
- 2
- 3
保存后,执行source /etc/profile使环境变量生效。
2.解决日志jar包冲突
执行以下命令,避免输出日志时报冲突错误
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.17.1.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.17.1.bak
- 1
3.初始元数据
1、hive本身自带的元数据存储时derby数据库,进入hive安装目录,执行bin/schematool -dbType -initSchema命令,在结尾输出"initialization script completed"字样,则表示初始化成功,输入hive命令,即可进入hive中使用。由于derby是一个轻量级的数据库,项目中一般会将derby数据库替换成mysql来存储hive元数据。
2、执行cp mysql-connector-java-8.0.17.jar $HIVE_HOME/lib命令,将mysql复制到hive安装路径下的lib目录
3、执行vim $HIVE_HOME/conf/hive-site.xml命令,在hive安装路径conf目录下创建hive-site.xml,然后复制以下内容到文件中
提示:jdbc连接信息根据自身环境不同,可自行调整
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- jdbc连接的url--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://cdp1:3306/metastore?useSSL=false</value> </property> <!-- jdbc连接的Driver--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <!-- jdbc连接的username--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- jdbc连接的password--> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>******</value> </property> <!-- Hive元数据存储版本的验证 --> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!-- 元数据存储授权--> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!-- Hive默认在HDFS的工作目录--> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <!-- 指定存储元数据要连接的地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://cdp1:9083</value> </property> <!-- 指定hiveserver2连接的host--> <property> <name>hive.server2.thrift.bind.host</name> <value>cdp1</value> </property> <!-- 指定hiveserver2连接的端口号--> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <!-- 打印表头信息--> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <!-- 打印当前数据库信息--> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <property> <name>datanucleus.schema.autoCreateAll</name> <value>true</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
4、进入hive安装目录,执行bin/schematool -dbType mysql -initSchema --verbose命令,在结尾输出"initialization script completed"字样,则表示初始化成功
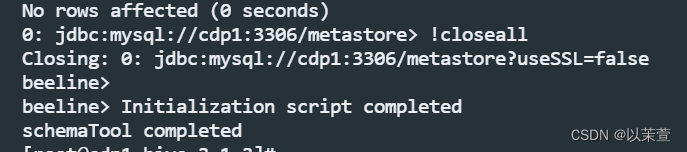
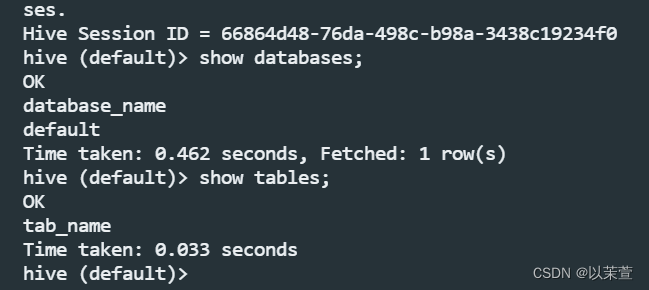
4.启动并进入hive
执行hive命令,进入hive客户端,可以执行一些基本命令:show databases;show tables查看是否正常。
6.开启metastore服务
metastore服务是hive的元数据功能,里面记录了hdfs存储路径,已经创建的hive表名等,可以连接到上述配置文件中的mysql地址,查看具体的存储信息,常用的表名有:DBS、TBLS等。先创建一个日志存放的目录,比如$HIVE_HOME/logs,然后执行以下命令开启metastore服务。
nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log
- 1
7.开启hiveserver2服务
hiveserver2功能开启后,可以通过jdbc远程连接的方式访问hive中的数据,例如在编写spark程序时,经常会遇到访问hive的场景,执行以下命令开启hiveserver2服务
nohup hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log
- 1
metastore服务在hiveserver2前面启动,两者开启后,可通过客户端工具(dbeaver、datagrip等)访问连接,连接地址是jdbc:hive2://cdp1:10000
也可以先在服务器上测试是否能够连接,执行beeline -u jdbc:hive2://cdp1:1000以连接到hiveserver2服务。
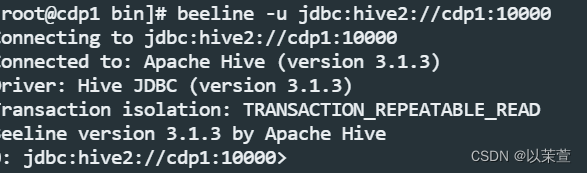
总结
至此hive组件就已经安装完成了,相对于hadoop集群部署来说还是比较简单的,需要配置的地方也没那么多,但目前hive底层运行的执行引擎还是mapreduce,如果想要hive运行的更加高效,可以开启多个hiveserver2或者切换到hive on spark来加速任务的执行速度,由于篇幅有限,这里就不继续讨论了,后续再接着讨论其他组件的功能。

