
- 1《ClickHouse入门、实战与进阶》的创作之路_clickhouse入门实战与进阶 pdf
- 2别当工具人了,手把手教会你 Jenkins_jenkins text publisher
- 3KAFKA学习_kafka多个消费者消费一个topic
- 4使用easypoi模板方法导出excel_easypoi导出excel模板
- 5Python & 机器学习之项目实践_正态化数据之后再评估算法还是
- 61.入门matlab数理统计随机数的产生(matlab程序)_生成二项分布随机数的命令
- 7Docker安装kkfileview_基于ubuntu构建kkfileview的dockerfile
- 8Linux Mysql5.7版本安装以及配置 (图文详细)_linux 安装mysql5.7
- 9【原】android模拟器 adb不能正常使用 报错:ADB server didn't ACK * failed to start daemon *...
- 10GPT每日面试题-Typescript中type和interface的区别
USP技术提升大语言模型的零样本学习能力
赞
踩
大语言模型(LLMs)在零样本和少样本学习能力上取得了显著进展,这通常通过上下文学习(in-context learning, ICL)和提示(prompting)来实现。然而,零样本性能通常较弱,因为缺乏指导和难以应用现有的自动提示设计方法。论文提出了一种名为Universal Self-Adaptive Prompting(USP)的自动提示设计方法,旨在提升大语言模型(LLMs)在零样本学习(zero-shot learning)任务中的表现。USP通过使用少量未标记数据和仅推理的LLM生成伪示例(pseudo-demonstrations),从而在零样本设置中实现强大的性能提升。
自动提示设计方法是一种用于提高大语言模型(LLMs)在特定任务上性能的技术。这种方法特别适用于零样本(zero-shot)和少样本(few-shot)学习场景,其中模型需要在没有或只有很少的标注数据的情况下学习执行任务。自动提示设计通过生成或选择有效的提示(prompts),帮助模型更好地理解任务并生成适当的输出。

下面是USP方法的关键特点和步骤:
-
任务类型分类:USP首先将可能的自然语言处理(NLP)任务归类为三种类型之一:分类(CLS)、短文生成(SFG)和长文生成(LFG)。
- CLS (Classification):分类任务,涉及从有限的选项中选择正确答案。
- SFG (Short-form Generation):短文生成任务,通常涉及问答或补全任务,其中正确答案可能有多个。
- LFG (Long-form Generation):长文生成任务,如摘要生成,涉及生成较长的文本。
-
伪示例生成:在零样本设置中,USP使用未标记数据和推理-only的LLM生成伪示例。这些伪示例是从模型的输出中选择的,旨在模拟真实示例,帮助模型更好地学习任务。
-
自适应选择器:USP根据不同的任务类型使用相应的选择器来挑选最合适的查询和模型生成的响应作为伪示例。选择器通过评分函数来量化模型对每个候选伪示例的置信度。
-
两阶段过程:
- 第一阶段:LLM在零样本方式下被提示生成一组候选响应。
- 第二阶段:将选定的伪示例作为上下文信息,与测试查询拼接,然后再次提示LLM以获得最终预测。
-
评分函数设计:USP为每种任务类型设计了不同的评分函数,以选择高质量的伪示例。例如:
- 分类任务:使用负熵作为评分函数,以量化模型对分类标签的置信度。
- 短文生成任务:使用归一化熵和多样性指标来评估模型生成的响应的置信度。
- 长文生成任务:使用响应之间的平均成对ROUGE分数来衡量置信度。

-
成本分析:USP在计算上是高效的,因为它只需要少量的额外LLM查询。
除了USP,还有其它一些自动提示设计方法,如AutoCoT和Z-ICL,它们也使用模型生成的输出作为伪示例,但在选择过程和适用性方面存在差异。这些方法通常需要更多的LLM查询,并且可能需要对特定任务类型进行特定的设计。
在论文中,作者们设计了一系列实验来验证Universal Self-Adaptive Prompting (USP) 方法的有效性。这些实验在以下模型上进行:
- PaLM-540B:一个具有540亿参数的大型语言模型。
- PaLM-62B:一个具有62亿参数的大型语言模型。
- PaLM 2-M:PaLM 2模型的一个变种,该模型在多语言和推理任务上具有更强的能力。
实验涉及的任务类型包括:
- CLS (Classification)、SFG (Short-form Generation)、LFG (Long-form Generation)。
在这些任务上,USP与以下几种基线方法进行了比较:
- 标准零样本提示:传统零样本学习方法,没有使用任何示例。
- AutoCoT:一种自动化的提示设计方法,使用聚类来选择伪示例。
- 随机示例:随机选择示例的方法,作为USP方法的一种简化版本进行比较。
- 标准少样本提示:使用少量标注数据进行学习的少样本学习方法。
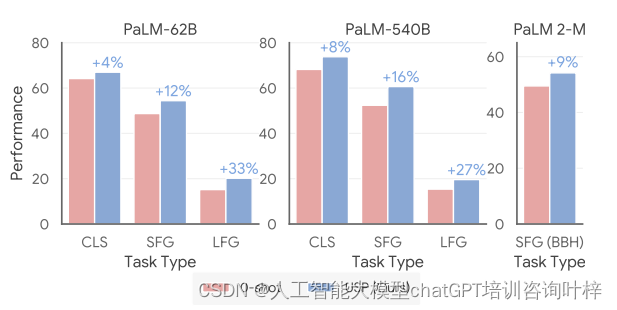
实验结果表明,USP在多个任务上都取得了显著的性能提升。具体来说:
- USP在生成任务(SFG和LFG)上的性能提升尤为显著,这可能是因为生成任务通常具有更大的行动空间,因此更依赖于示例提供的指导。
- 在更大或更先进的模型(如PaLM 2-M)中,USP的性能提升也更为明显,这表明模型的规模和训练技术的进步使得它们能够更好地利用高质量的示例进行学习。
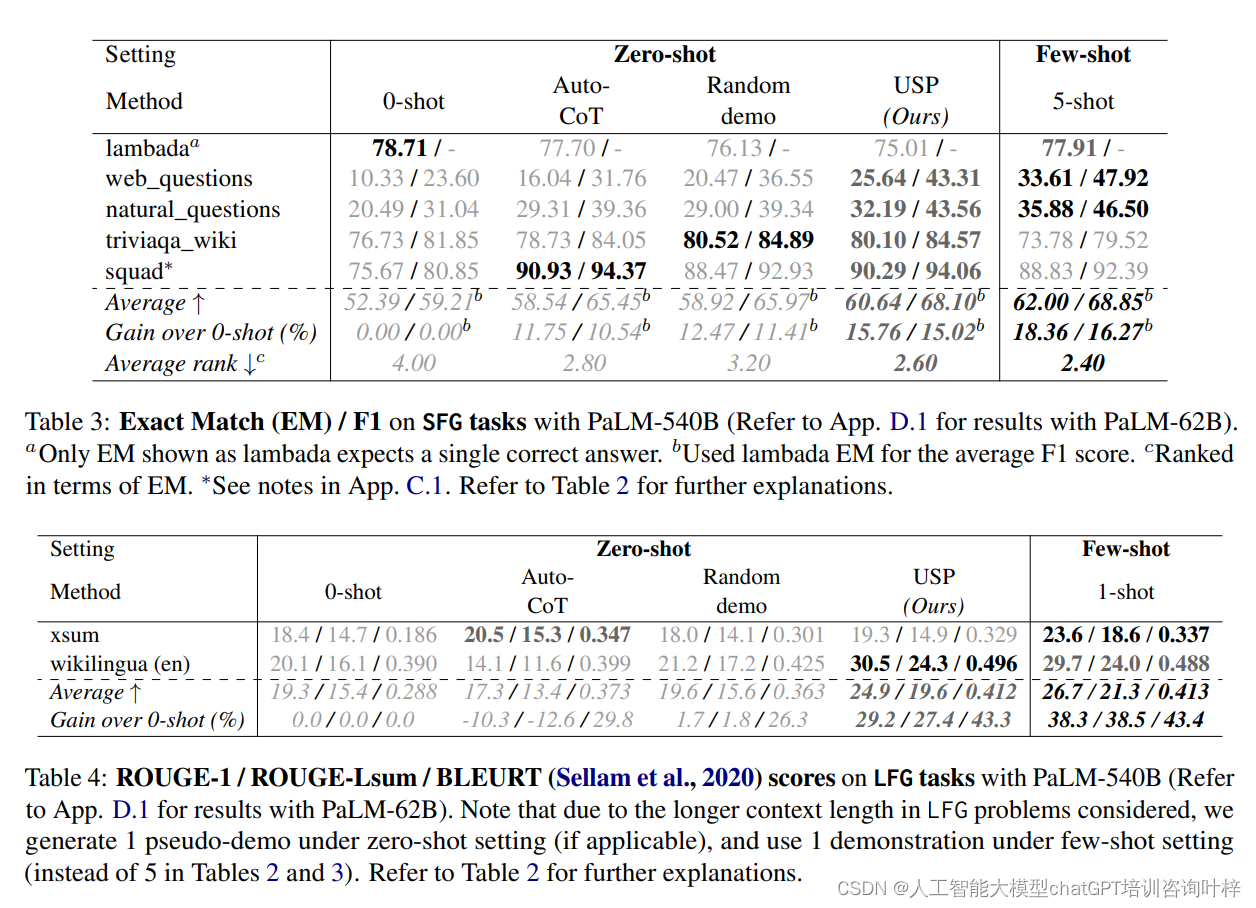
此外,作者们还测试了USP的少样本变体(USPfs),这是在只有少量标注数据可用的情况下使用USP的一个变种。在PaLM 2-M模型上,USPfs在BBH (BIG-bench Hard) 任务上也展现了良好的性能。BBH任务是一组设计来挑战模型推理和逻辑能力的复杂任务。USPfs通过生成额外的伪示例来增强标注数据,从而在这些任务上取得了性能提升。
这些实验结果证明了USP方法在零样本和少样本学习场景下的有效性,特别是在处理复杂的NLP任务时,USP能够显著提高模型的性能。


