- 1不歧视双非的计算机院校,这30所重点院校不歧视“双非”,公平竞争录取,爱了爱了!...
- 2nltk中文分句_利用NLTK进行分句分词
- 3CMake构建_cmake构建工程
- 4pandas - read_csv报错:‘utf-8‘/‘gbk‘ codec can‘t decode byte 0xb1 in position 0:invalid start byte_utf-8' codec can't decode byte 0xb1 in position 0:
- 5【云原生之Docker实战】使用docker部署个人导航页webstack_docker部署一个个人网站
- 6保护通信的双重安全:消息认证与身份认证
- 7MQ的消费模式-消息是推还是拉_rocketmq消息采用push还是pull
- 8零基础学习Transformer:multi-head self-attention layer and multi-head attention layer_transformer中单头与多头的区别
- 9NLP自然语言处理中英文分词工具集锦与基本使用介绍_英语分词软件
- 10c语言之动态链表
C语言中自定义类型讲解_c语言中如何定义的类型简写
赞
踩
- 前言:C语言中拥有三种自定义类型,这三种自定义类型是怎么运用呢?在内存中又是怎么存储的呢?通过这篇文章我们来逐个讲解讲解。
三种类型分别是:
1.结构体 – 通俗的来讲就是可以把不同类型的变量放在一个集合中
2.枚举 – 可以理解成把所有事情全部列举出来
3.联合体 – 通俗的理解成,成员公用一块空间的结构体
结构体
结构体的声明:
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}; //分号不能丢
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们在声明结构体的时候,也可以选择匿名(通俗的讲就是这个结构体我们只会用一次)
匿名结构体类型:
//匿名结构体类型
struct
{
int a;
char b;
float c;
}x;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在这之前我们学过,“循环”,“判断语句”,这些都是可以嵌套使用的,在结构体当中,我们是否也可以嵌套使用结构体呢?就是在结构体中在引用结构体。
结构体的自引用:
struct Node
{
int data;
struct Node* next;
};
- 1
- 2
- 3
- 4
- 5
我们可以发现,我们通过结构体指针的方式,在结构体中引用结构体的方式,可以来实现结构体的自引用。
结构体的定义与初始化:
struct Point { int x; int y; }p1; //声明类型的同时定义变量p1 struct Point p2; //定义结构体变量p2 //初始化:定义变量的同时赋初值。 struct Point p3 = {x, y}; struct Stu //类型声明 { char name[15];//名字 int age; //年龄 }; struct Stu s = {"zhangsan", 20};//初始化 struct Node { int data; struct Point p; struct Node* next; }n1 = {10, {4,5}, NULL}; //结构体嵌套初始化 struct Node n2 = {20, {5, 6}, NULL};//结构体嵌套初始化

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
结构体在内存中的存储方式
要了解结构体的存储方式,首先我们来看一看它是否和我们平常想象的方式一样在内存中存储。
例题:
struct S1
{
char c1;
int i;
char c2;
};
int main()
{
printf("%d\n", sizeof(struct S1));
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
分析:
按照我们平常的逻辑,
char c1占1个字节,int i占4个字节,char c2占一个字节,总的加一起应供占6个字节,我们来看看运行的结果是不是六个字节呢?
运行结果:
因此我们可以知道,实际上他并不是像我们想象的方式在内存中存储的,那是怎么存储的呢?

首先得掌握结构体的对齐规则:
- 第一个成员在与结构体变量偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
VS中默认的值为8 - 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整
体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
这段话又是什么意思呢?我们接着上面的代码继续分析
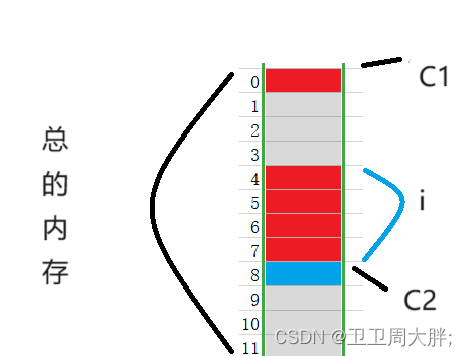
我们把下图比作内存条:第一个成员在与结构体变量偏移量为0的地址处(故名思意就是代码的起始处)。如图所示的C1就是所放的位置,其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数与该成员大小的较小值,因为int类型的的大小是4与VScode下的默认对齐数8相比较小,因此int i必须放在内存位置4个倍数的位置,如下图中所放的位置,同理C2也是如此,可是最后的结果如图加起来应该是9,为什么结果是12呢?我们看 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。因为此结构体中最大对齐数是4,因此我们的内存总大小是12,和我们刚刚所对的运行结果刚刚好一样,因此我们可以通过这个结构体的对齐规则来掌握结构体在内存中的存储。
为什么存在内存对齐?
平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
我们也可修改默认对齐数,来控制结构体中内存的存储。
#pragma pack(8)//设置默认对齐数为8
struct S1
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
通过这个例子我们知道了通过 pragma来控制默认对齐数,那么我们来一道例题。
#include <stdio.h> #pragma pack(8) struct S1 { char c1; int i; char c2; }; #pragma pack() #pragma pack(1)//设置默认对齐数为1 struct S2 { char c1; int i; char c2; }; #pragma pack()//取消设置的默认对齐数,还原为默认 int main() { //输出的结果是什么? printf("%d\n", sizeof(struct S1)); printf("%d\n", sizeof(struct S2)); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
如图所示:
S1和上个例题相同就不再过多讲解,在S2中我们的默认对齐数是1可知C1放在起始处,后面可以根据依次连接的方式对齐。因此结果是12、6
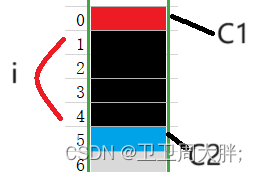

因此我们可以知道:结构在对齐方式不合适的时候,我么可以自己更改默认对齐数。
结构体传参:
我们直接看代码:
struct S { int data[1000]; int num; }; struct S s = {{1,2,3,4}, 1000}; //结构体传参 void print1(struct S s) { printf("%d\n", s.num); } //结构体地址传参 void print2(struct S* ps) { printf("%d\n", ps->num); } int main() { print1(s); //传结构体 print2(&s); //传地址 return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
请问:上面的 print1 和 print2 函数哪个好些?
答案是:首选print2函数。
原因:
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。在print1中是将整个结构体传过去,而print2中是传的地址,因此print2会大幅度提高性能
位段
- 位段的成员可以是 int (unsigned int) (signed int) 或者是 char (属于整形家族)类型。
- 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
- 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
- 位段的声明和结构是类似的,但是位段的成员名后边有一个冒号和一个数字。
例如:
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
}s1;
int main()
{
printf("%d\n", sizeof(struct A));
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
代码分析:
因为位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
- 声明类型是int类型的,所以一开始开辟了4个整型的空间即32bit
- _a用掉了2bit,还剩下30bit
- _b用掉了5bit,还剩下25bit
- _c用掉了10bit,还剩下15bit
- _d需要30bit,可是我们所剩下的空间只有15bit,又因为_d是int类型,因此在开辟一个整型的空间即32bit位将_d所需要的30bit位全部放进去,因此我们可以知道,一共开辟了8个字节的空间。
运行结果:
位段的跨平台问题
- int 位段被当成有符号数还是无符号数是不确定的。
- 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机
器会出问题。 - 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
- 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
枚举
枚举顾名思义就是一一列举。
把可能的取值一一列举。
比如我们现实生活中:
一周的星期一到星期日是有限的7天,可以一一列举。
看代码:
enum Day//星期 { Mon, Tues, Wed, Thur, Fri, Sat, Sun }; enum Sex//性别 { MALE, FEMALE, SECRET }; enum Color//颜色 { RED, GREEN, BLUE };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
当然这些可能取值都是有值的,默认从0开始,一次递增1,当然在定义的时候也可以赋初值。
我们来看一道题目带你懂枚举的值:
enum ENUM_A
{
X1,
Y1,
Z1 = 255,
A1,
B1,
};
int main()
{
enum ENUM_A enumA = Y1;
enum ENUM_A enumB = B1;
printf("%d %d\n", enumA, enumB);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
代码分析:
我们刚刚讲过默认从0开始,一次递增1,当然在定义的时候也可以赋初值。那么这题的答案是多少?我们不难看出
X1是从0开始故而Y1是1,然而Z1我们给它赋了初始值255,那B1是多少?是在255的基础上加2还是接着前面的0,1开始呢?看运行结果:
显然我们可以在知道,B1的值是在接着我们所赋的值来继续加1,因此我们也了解了枚举的作用。

枚举的优点
- 增加代码的可读性和可维护性
- 和#define定义的标识符比较枚举有类型检查,更加严谨。
- 防止了命名污染(封装)
- 便于调试
- 使用方便,一次可以定义多个常量
联合(共用体)
定义:联合也是一种特殊的自定义类型
这种类型定义的变量也包含一系列的成员,特征是这些成员公用同一块空间(所以联合也叫共用体)。
口头的文字肯定不如代码的效果明显,所以我们直接上代码:
//联合类型的声明
union Un
{
char c;
int i;
};
//联合变量的定义
union Un un;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
联合体在内存中的存储
- 联合的大小至少是最大成员的大小。
- 当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。
例题:
union Un
{
int i;
char c;
};
union Un un;
int main()
{
// 下面输出的结果是一样的吗?
printf("%d\n", &(un.i));
printf("%d\n", &(un.c));
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
前面我们说过,特征是这些成员公用同一块空间(所以联合也叫共用体)。
因此我们可以知道题目是公用一块空间。

联合大小的计算
例题:
union Un1 { char c[5]; int i; }; union Un2 { short c[7]; int i; }; int main() { //下面输出的结果是什么? printf("%d\n", sizeof(union Un1)); printf("%d\n", sizeof(union Un2)); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
代码分析:
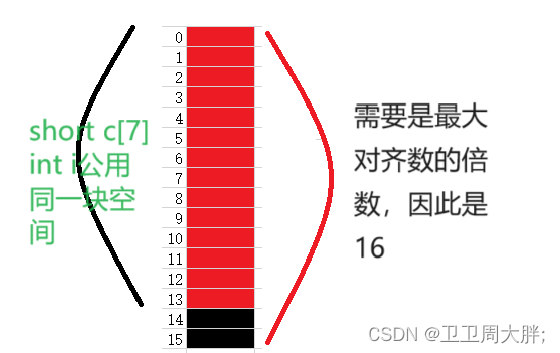
Un1的分析:占8个字节
Un2的分析:占16个字节
好了,今天的讲解就到这里了,如果有讲的不好的地方希望各位多多指出。