
- 1github actions实现Android持续集成_- name: grant execute permission for gradlew run:
- 2ADB interface 驱动下载,以及使用,Because an app is obscuring a permission request settings can’t verify your_android composite adb interface下载
- 3英雄为何失败--看 汉武大帝 中的李广与程不识_程不识和李广
- 4C/C++热门精品资料地址集(110个)(转)
- 5多旋翼无人机的飞行特点
- 6django轻院图书馆座位预约管理系统(程序+开题报告)
- 7Ubuntu的apt、apt-get和apt-cache命令_ubuntu apt
- 8字节腾讯三轮社招面经(附个人回答)_字节社招面经
- 9C语言程序设计100个经典例子_c语言经典程序100例
- 10git清空添加到暂存区的所有文件_git清空暂存区全部文件
解决Pytorch的cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
赞
踩
1. 问题报错
在使用GPU加速模型训练的过程中经常会遇到这样的错误:
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
- 1
这个错误通常表示cuDNN库未能正确初始化。
2. 可能原因
2.1 GPU内存不足
在终端输入nvidia-smi查看GPU占用情况,如下图中的GPU 0几乎跑满,如果再使用该GPU运行其他占用内存较大的程序可能会报错。
>>> nvidia-smi
- 1

2.2 缓存问题
有时,cuDNN错误可能是由于缓存问题引起的。尝试清除缓存,然后重新运行代码。可以在Python代码中使用以下代码来清除缓存:
import torch
torch.cuda.empty_cache()
- 1
- 2
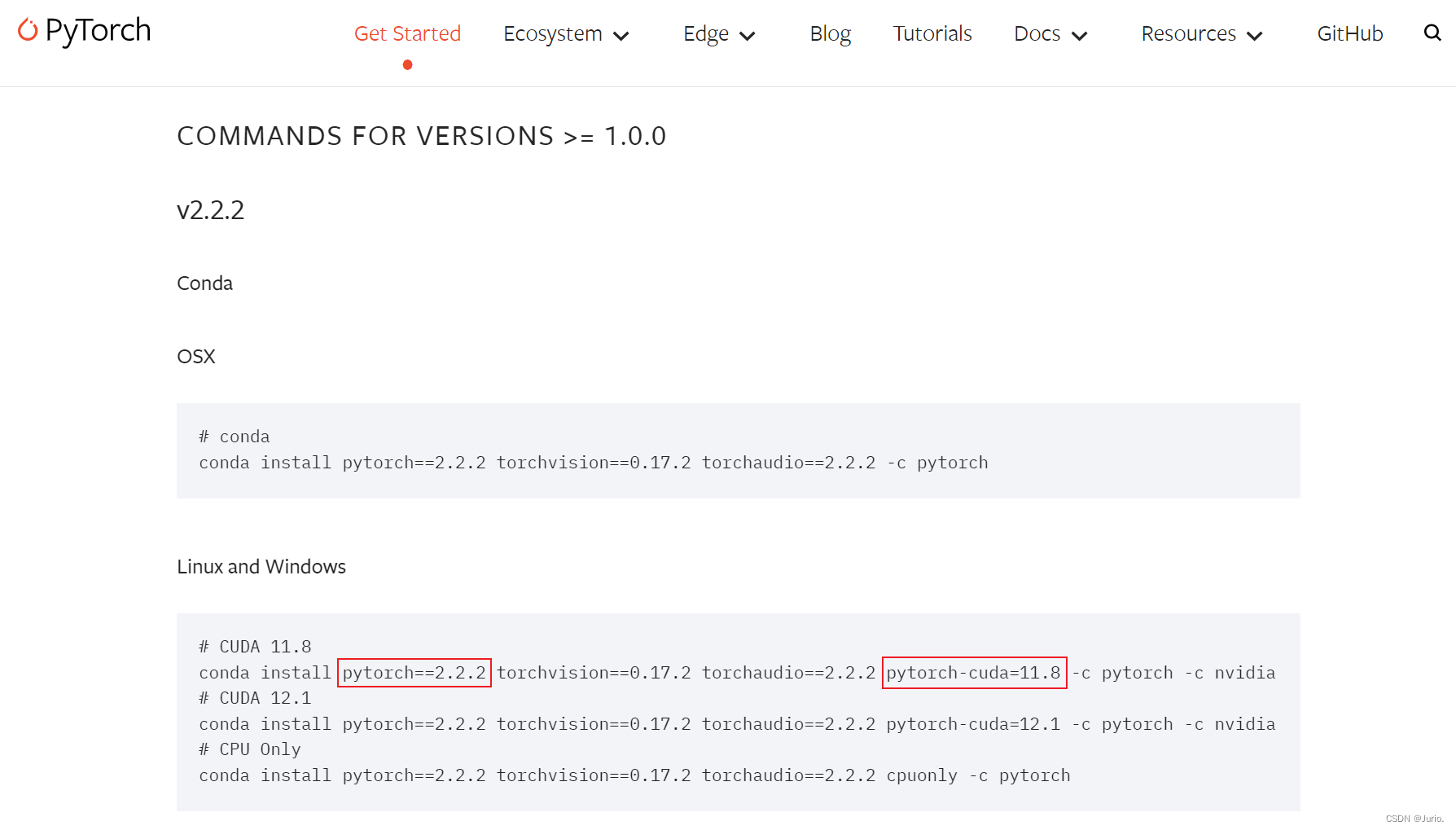
2.3 CUDA和Pytorch版本不兼容
不同版本的深度学习框架对CUDA和Pytorch的要求可能有所不同。在使用特定版本的框架时,查阅其文档或要求,了解所需的CUDA和Pytorch版本,并确保安装了正确的版本。
前往Pytorch官网查看版本对应关系:https://pytorch.org/get-started/previous-versions/,如果版本不匹配则需要重新安装Pytorch或者更新CUDA版本。注意同一Pytorch版本适配多个CUDA版本,具体还需要考虑cuDNN的版本,详情见下一节。
显卡的CUDA版本同样可以通过nvidia-smi进行查看:

2.4 CUDA和cuDNN版本不兼容
确保你使用的CUDA版本与cuDNN版本兼容,验证CUDA和cuDNN是否正确安装并配置。
cuDNN官网下载地址提供了二者版本对应关系:https://developer.nvidia.com/rdp/cudnn-archive
如果需要重新下载CUDA,可以前往官网下载:https://developer.nvidia.com/cuda-toolkit-archive
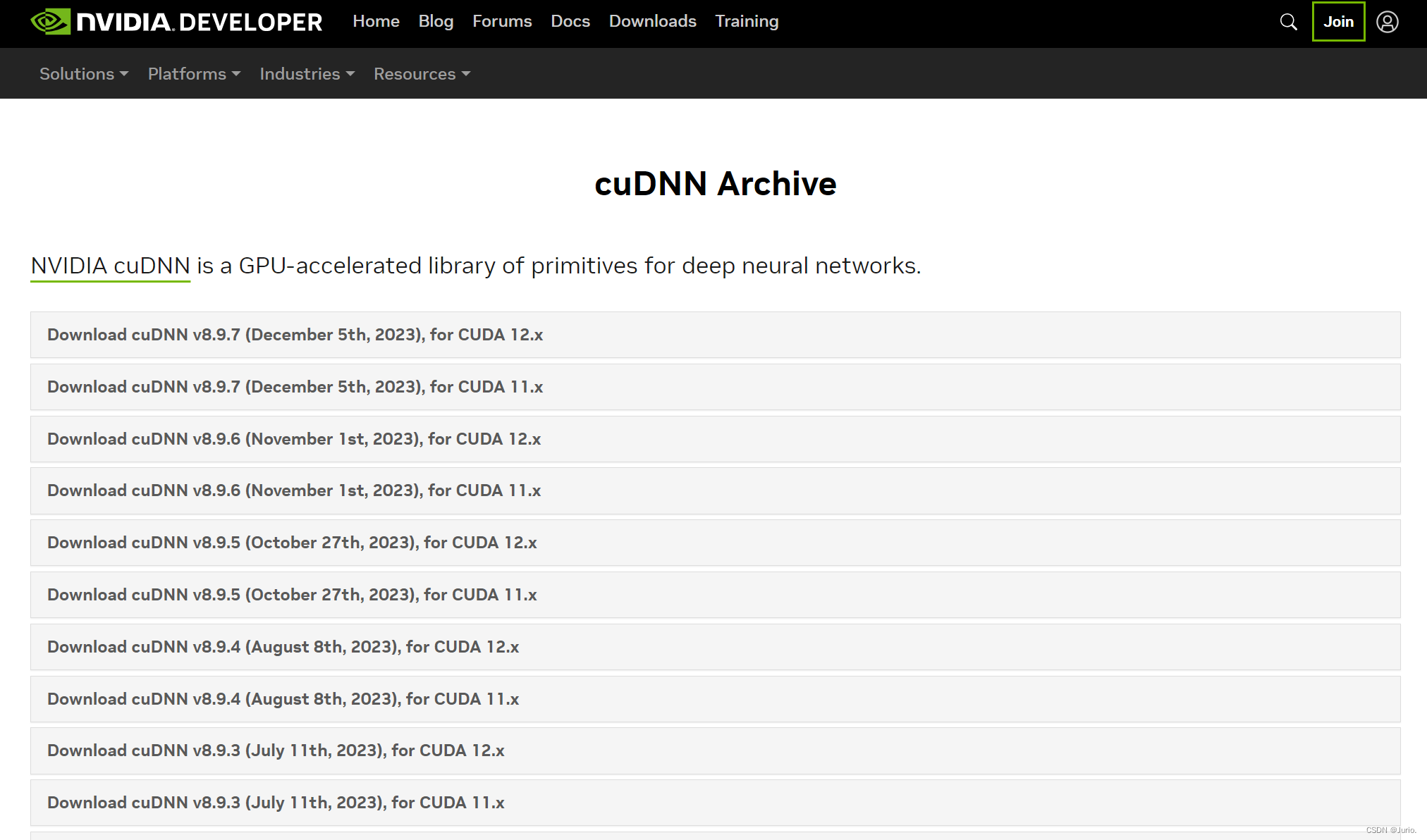
这篇博客记录了部分CUDA Toolkit 和cuDNN的版本对应关系:https://blog.csdn.net/tangjiahao10/article/details/125225786
3. 验证CUDA是否可用
查看CUDA是否可用命令如下:
import torch
print(torch.cuda.is_available())
- 1
- 2
返回True即可用。

