
- 1python基础知识(五):while循环、for循环、continue语句和break语句_while循环n次
- 2VJ runtime error可能的原因_vjudge runtime error
- 3电子技术课程设计—交通灯控制系统设计_555简易交通灯电路设计与装调
- 4[crash分析2]C语言在ARM64中函数调用时,栈是如何变化的?_arm函数调用中的堆栈变化
- 5AI论文精读之CSPNet—— 一种加强CNN模型学习能力的主干网络_cspnet论文
- 6JWT详解、JJWT使用、token 令牌
- 7走进前端 Vscode和插件的安装 如何在Gitee上提交代码_vscode gitee插件
- 8Java---给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中最后一个单词的长度。_给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最
- 9完备的 AI 学习路线,最详细的资源整理!_ai学习路线
- 10mysql学校作业(二)_查询会员表,输出e-mail是qq邮箱的会员的昵称和e-mail
【数据结构与算法】快速排序的优化_快速排序算法优化
赞
踩
中心比较值优化、小规模直接插入排序优化、并行优化
前言
快速排序是一种比较优秀的排序算法,然而从快排的原理下手,我们能够对快速排序进一步优化。可以从中心值的选取、小规模直接插入排序、并行优化处理。
中心值优化:通过在样本(前中后)中选取中间值,来尽可能地选择离中位数最近的基准值。
小规模排序:待排序序列较小时,可以通过转变为例如直接插入排序来进行优化,避免深度递归。
并行优化:依据快速排序特点,子序列进行并行快速排序来优化提速
一、优化思路
1.1 中心值选取优化
快速排序算法的原理,是选取一个中心值,将比它大/小的元素归为一边,一轮即可确定一个元素的位置。最坏情况下,对n个元素分类,可以分为n-1与1,算法复杂度O(n2)。最优情况下,对n个元素分类,可以分为n/2与n/2,或者(n-1)/2与(n-1)/2+1。算法复杂度为O(nlogn)。可见,中心值的选取对于算法的性能提升是非常重要的。
如何寻找到中心值呢?理想情况下中值是最优的中心值——但是需要通过排序来寻找——这就陷入了自证的怪圈中。不过我们并不苛求极致的优化——有时候的苛求优化的操作只会将问题复杂化。通过“随机”选取部分值,在样本中选择最优的中心值,相比于从第一个开始作中心值的做法,已经是有了极大的优化。
1.2 直接插入排序优化
快速排序算法每次能够将序列分化为两部分,递归地进行求解。然而,调用函数本身需要占用空间,也耗费时间。当规模较小时,采用在该情况下更优的排序算法,是一种权衡——总是在各种条件下,用最好的方法——符合贪心的要求。
1.3 并行处理
快速排序最优也是O(nlogn)的复杂度,其他算法例如归并排序也是O(nlogn)的复杂度,快速排序有一个非常重要的特征。每一轮分类,都将数据分为两个部分,这两个部分彼此排序互不影响,因此可以并行地实现。
二、实验结果
实验结果
数据规模为100的排序对比:
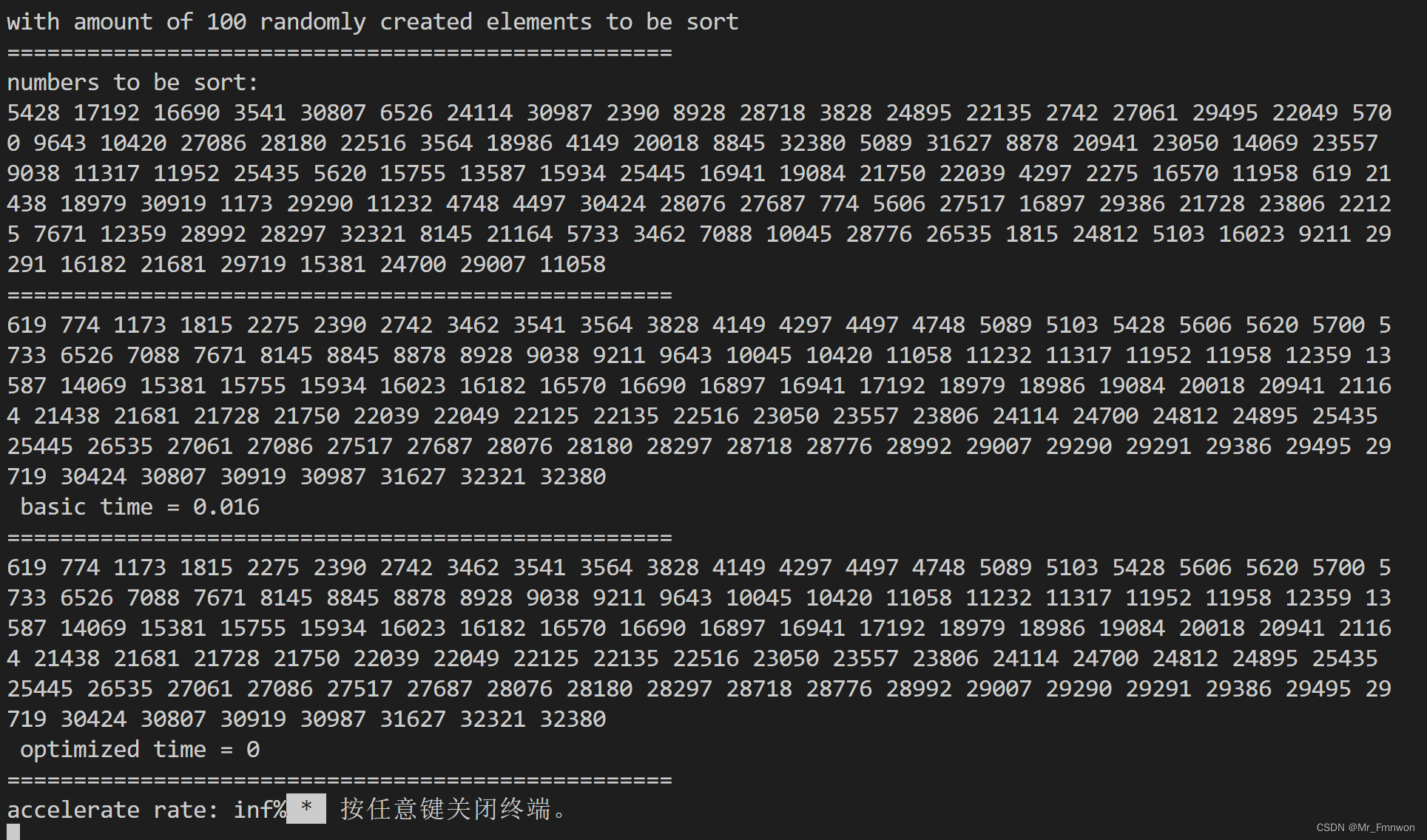
因为优化过后速度过快,时间记录为0,因此效率得到一个无穷大。(/0)
数据规模为10,0000的排序对比:(均显示前100个数)

可以看到,数量级为100000已经非常庞大了,对于计算机而言,使用快速排序算法,速度还是很快的,而且优化效率几乎达到一倍。
数据规模为1,0000,0000的排序对比:(均显示前100个数)
 在面对亿级的数据时,优化过的算法效率提升非常可观。
在面对亿级的数据时,优化过的算法效率提升非常可观。
三、优化源码
中心值选取优化
- // ****************************************************************************************
- // optimized point 1:
- // compare the first, last and middle one, swap the middle value recond with the first location
- int middle=(i+j)/2;
- int index=(A[low]>=A[high] && A[low]<=A[middle])?low:
- ((A[high]>=A[low] && A[high]<=A[middle])?high:middle);
- swap(A[index],A[low]);
- //*****************************************************************************************
采取抽样的方法,前中后选取中间值。离散选取减小了因部分连续片段同时较大或较小而所选中间值偏大或偏小的可能性。
直接插入排序优化
- //****************************************************************************************
- // optimized opint 2:
- // if the size of array to be sorted is small enough,
- // direct-insert-sort is much more efficient than quickSort
- if(high-low<maxLen)
- {
- for(i=low+1; i<=high; ++i)
- {
- temp=A[i];
- j=i-1;
- while(A[j]>temp&&j>=low)
- {
- A[j+1]=A[j];
- j--;
- }
- A[j+1]=temp;
- }
- return;
- }
- //*****************************************************************************************

当数据规模足够小时(<maxLen=10(默认可调)),采用直接插入排序算法,避免了深层的递归,在权衡之下是更优的算法。
并行优化排序
(这部分花了两天,并行在vscode要配置的东西和注意的事项太多了,一不小心就出错;此外,一股脑儿在递归函数里面用多线程,效率嘎嘎降,100000000个数据,不加判断就一个劲儿多线程,可以在80s左右完成。。。是不优化的6/7倍)
- // ****************************************************************************************
- // optimized point 3:
- // via openmp, make it runs parallelly
- //
- // Actually, there are 2 options with different parallelly running structure as follows
- //***********************option 1*********************************/
- // if(depth<=7)
- // {
- // #pragma omp parallel // starts a new team
- // {
- // #pragma omp sections
- // {
- // //{ Work1(); }
- // #pragma omp section
- // { QuickSort_optimized(A, i+1, high, depth+1); }
- // #pragma omp section
- // { QuickSort_optimized(A, low, j-1, depth+1); }
- // }
- // }
- // }
- // else
- // {
- // QuickSort_optimized(A, i+1, high, depth+1);
- // QuickSort_optimized(A, low, j-1, depth+1);
- // }
- //***********************option 2*********************************/
- if(depth<=7)
- {
- #pragma omp parallel num_threads(2)
- {
- #pragma omp single
- {
- #pragma omp task
- QuickSort_optimized(A, i+1, high, depth+1);
- #pragma omp task
- QuickSort_optimized(A, low, j-1, depth+1);
- #pragma omp taskwait
- }
- }
- }
- else
- {
- QuickSort_optimized(A, i+1, high, depth+1);
- QuickSort_optimized(A, low, j-1, depth+1);
- }
- }
- //**************************************************************************************
值得说明的是,如果直接无脑用并行子部分排序,由于快速排序是的递归函数,每一次并行都会产生两个线程。首先就是线程随着递归深度以指数爆炸的方式产生。其次,线程之间处理也随着线程的增多而发生冲突,产生意想不到的拖延“死锁”。再次,众多线程的创建、运维、消除的声明周期,同样占用着大量的时间与资源。因此,这里采用浅层并行,深层串行的方式,着重凸显线程并发的优势,规避其劣势。
总结
除了上述三种优化方法,还有如尾预编译等优化手段,可以查阅其他大牛的博客。
需要基础快排/优化快排源代码的,可以评论区喊我。
一起学习,一起加油!

