
- 12023年10月国产数据库大事记-墨天轮_达梦数据库上市
- 2gitee项目部署步骤及克隆或提交仓库用户名密码错误解决_git修改克隆密码
- 3unity到小游戏instantGame(流程演示,非内容制作 亲测可用)
- 4内核交叉编译配置定制和编译(2)_安卓8.1 交叉编译 配置
- 5阿里云 OSS桶对象存储攻防
- 6Hive的部署_hive部署
- 7java.lang.IncompatibleClassChangeError:异常原因及解决方法
- 8新版IDEA中Git的使用(三)_新版idea的git
- 9GBDT、XGBoost、LightGBM汇_gbdt xgboost lightgbm
- 10STM32——高级定时器输出指定个数PWM波原理及实战_stm32输出固定数量的脉冲
使用OpenCV+Python进行图像处理的初学者指南
赞
踩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达介绍
我们都知道一句话:“每张照片都可以告诉我们一个故事”。图像中可能隐藏着很多信息,我们可以用不同的方式和视角来解释它。那么,什么是图像,如何处理图像?
简而言之,我们可以说图像是事物的视觉表示,可以使用计算机视觉轻松处理(从机器学习的角度来看)。视频呢?视频可以描述为一组移动图像或连续帧的记录。
你们中的一些人现在可能已经知道计算机视觉,可以选择跳过这一段,但是对于那些不了解它的人,可以这么说,计算机视觉主要以缩写形式“CV”而闻名,可以说是一个从数字图像、视频等中提取有用信息的人工智能领域。
“CV”的几乎所有领域都有很多实际应用,包括医疗领域、汽车、制造、农业等领域。

图 1
作为目前正在阅读这篇文章的人,你将能够区分图像中存在的事物或元素。但是,机器呢?他们能不能自己看到并思考来区分它?不?那么让我们让你的机器做到这一点。
在本博客中,你将熟悉使用 Python 的计算机视觉基础知识。
我相信你已经安装了 Python Shell / Jupyter Notebook / PyCharm 或 Visual Studio Code(仅举几例)来使用 Python 进行编程。
让我们安装广泛使用的包 (OpenCV) 开始,我们将在 Jupyter Notebook 的每个单元格中运行代码。
为图像预处理安装 OpenCV 包
OpenCV 是一个预构建的、开源的库(包),广泛用于计算机视觉、机器学习和图像处理应用程序。它支持多种编程语言,包括 Python。
使用以下命令安装 OpenCV 包:
pip install opencv-python或者
pip install opencv-contrib-python在你的终端上运行这些命令中的任何一个,或者如果你使用的是 Anaconda Navigator – Jupyter Notebook,你可以使用“conda”命令替换“pip”。
导入包
Python中的包是什么?Python 中的包是包含预先编写的脚本的模块的集合。这些包帮助我们完全或单独导入模块。我们可以通过调用“cv2”模块来导入包,如下所示:
import cv2读取图像
数字图像可分为;彩色图像、灰度图像、二值图像和多光谱图像。
彩色图像包括每个像素的颜色信息。以灰色阴影作为唯一颜色的图像是灰度图像,而二值图像正好有两种颜色,主要是黑色和白色像素。多光谱图像是在某些特定波长内捕获跨越电磁光谱的图像数据的图像。
让我们回到编码部分,读取一张图片,例如图片如下所示:

这是山魈的图像。我目前正在从本地目录中读取图像。
# cv2.imread(path_to_image_with_file_extension, flag)使用代码如下所示:
img = cv2.imread("mandrill.jpg", 1)这里我们使用的是cv2包的“imread”方法来读取图片,第一个参数对应图片的路径及其文件名和扩展名,第二个是可以设置的标志,它告诉我们,如何读取图像。如果你愿意,可以在此处替换图像的绝对路径,然后尝试从本地计算机甚至从 Internet 读取它!如果图像存在于你当前的工作目录中,你只需指定图像名称及其扩展类型。
第二个参数,如果你把它当作灰度图像来读取,你可以将参数指定为0;
-1表示读取图像不变(如果有则将图像读取为alpha或透明通道)
默认情况下,它是 1,作为彩色图像。你还可以尝试此链接中的其他参数:
https://docs.opencv.org/4.5.2/d8/d6a/group__imgcodecs__flags.html#ga61d9b0126a3e57d9277ac48327799c80
图像的属性
形状:
每个图像都有一个形状。图片展示的边界长度可以称为形状,即高度和宽度。现在你知道如何读取图像,我们来检查图像的形状如何?
print(img.shape)是打印图像形状的基本方法,但我们可以使用以下方法提取形状:
- h, w, c = img.shape
- print("Dimensions of the image is:nnHeight:", h, "pixelsnWidth:", w, "pixelsnNumber of Channels:", c)
以获得更好的理解。
对于颜色和不变模式,它将返回 3 个值,包括图像中存在的高度、宽度和通道数。如果你使用了灰度模式,则形状将为 2,这将返回图像的高度和宽度,但是你只需要使用 h 和 w 变量(不包括使用“c”),否则你可能会得到一个值错误说“没有足够的值来解包(预期 3,得到 2)”。
类型:
我们可以使用“type”方法知道图像的类型。使用这种方法可以帮助我们了解图像数据是如何表示的。运行代码如下:
print(type(img))结果可能是这样的:
作为图像类型。它是相同类型和大小的物品的多维容器。你可以在以下链接中更多地参考 N 维数组:
https://numpy.org/doc/stable/reference/arrays.ndarray.html
你刚刚读取的图像的数据类型:
由于图像是一个N维数组,我们可以检查图像的数据类型:
print(img.dtype)图像像素值:
我们可以将图像视为一组小样本。这些样本称为像素。为了更好地理解,请尝试尽可能放大图像。我们可以看到相同的分为不同的方块。这些是像素,当它们组合在一起时,它们就形成了一个图像。
表示图像的一种简单方法是以矩阵的形式。我们甚至可以使用矩阵创建图像并保存它!将在本文后面向你展示如何操作。看看下面这张图:
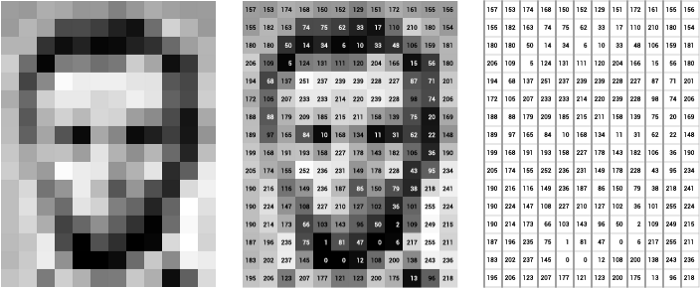
图 2
这张图片是图像的矩阵表示形式的一个例子。左边是林肯的图像,中间是像素值标有 0 到 255 的数字,表示它们的强度或亮度,右边是矩阵中的数字本身。
矩阵中的每个值对应一个像素,它是图像中存在的最小信息元素。只需打印加载图像的变量即可查看图像像素值!
print(img)图像分辨率
图像分辨率可以定义为图像中存在的像素数。当像素数量增加时,图像质量会提高。我们之前已经看到,图像的形状给出了行数和列数。这可以说是该图像的分辨率。几乎所有人都知道的一些标准分辨率是 320 x 240 像素(最适合小屏幕设备)、1024 x 768 像素(适合标准计算机显示器)、720 x 576 像素(适合标准清晰度电视 )、1280 x 720 像素(用于在宽屏显示器上查看)、1280 x 1024 像素(适合在宽高比为 5:4 的 LCD 显示器上以全屏尺寸查看)、1920 x 1080 像素(用于在高清电视上观看)现在我们甚至拥有 3840 x 2160 像素的 4K、5K 和 8K 分辨率,
当我们乘以列数和行数时,我们可以获得图像中存在的像素总数。例如,在 320 x 240 图像中,其中存在的像素总数为 76,800 像素。
查看图像
让我们看看如何在窗口中显示图像。为此,我们必须创建一个 GUI 窗口来在屏幕上显示图像。第一个参数必须是 GUI 窗口屏幕的标题,以字符串格式指定。我们可以使用 cv2.imshow() 方法在弹出窗口中显示图像。
但是,当你尝试关闭它时,你可能会觉得被它的窗口卡住了。所以为了解决这个问题,我们可以使用一个简单的“waitKey”方法。在新的单元格中尝试此代码部分:
- cv2.imshow('Mandrill', img)
- k = cv2.waitKey(0)
- if k == 27 or k == ord('q'):
- cv2.destroyAllWindows()
在这里,我们在“waitKey”中指定了参数“0”,以保持窗口打开直到我们关闭它。(你也可以以毫秒为单位给出时间,而不是 0,指定应该打开多长时间。)
之后,我们可以分配变量('q') 以在按下“ESC”键或键时关闭窗口。cv2.destroAllWindows() 方法用于关闭或删除屏幕/内存中的 GUI 窗口。
保存图像
在保存图像之前,如何将图像转换为灰度然后保存?使用以下方法将图像转换为灰度:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)现在我们可以保存图像:
cv2.imwrite('Mandrill_grey.jpg', gray)并检查当前工作目录中保存的图像。第一个参数对应于要保存图像的文件的名称,第二个参数是包含图像(像素信息)的变量。
提取图像位平面并重建它们
我们可以将图像划分为不同级别的位平面。例如,将图像划分为 8 位 (0-7) 平面,其中最后几个平面包含图像的大部分信息。
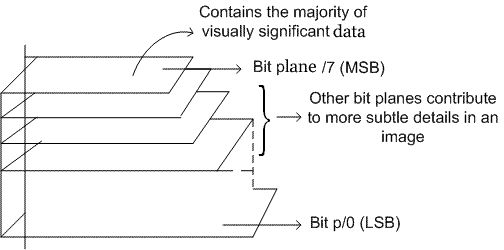
图 3
为此,我们可以再导入两个包:
- import matplotlib.pyplot as plt
- import numpy as np
如果你在导入任何软件包时遇到错误,你可以使用以下命令安装它们:
- conda install -c conda-forge matplotlib
- conda install -c anaconda numpy
现在我们正在定义一个函数来提取图像的 8 级位平面中的每一个。
- def extract_bit_plane(cd):
- # extracting all bit one by one
- # from 1st to 8th in variable
- # from c1 to c8 respectively
- c1 = np.mod(cd, 2)
- c2 = np.mod(np.floor(cd/2), 2)
- c3 = np.mod(np.floor(cd/4), 2)
- c4 = np.mod(np.floor(cd/8), 2)
- c5 = np.mod(np.floor(cd/16), 2)
- c6 = np.mod(np.floor(cd/32), 2)
- c7 = np.mod(np.floor(cd/64), 2)
- c8 = np.mod(np.floor(cd/128), 2)
- # combining image again to form equivalent to original grayscale image
- cc = 2 * (2 * (2 * c8 + c7) + c6) # reconstructing image with 3 most significant bit planes
- to_plot = [cd, c1, c2, c3, c4, c5, c6, c7, c8, cc]
- fig, axes = plt.subplots(nrows=2, ncols=5,figsize=(10, 8), subplot_kw={'xticks': [], 'yticks': []})
- fig.subplots_adjust(hspace=0.05, wspace=0.05)
- for ax, i in zip(axes.flat, to_plot):
- ax.imshow(i, cmap='gray')
- plt.tight_layout()
- plt.show()
- return cc

现在我们已准备好调用该函数。
reconstructed_image = extract_bit_plane(gray)我们已经使用最后三个位平面(即第六、第七和第八个平面)重建了图像(几乎相似)。结果如下所示:

我们自己构建一个小图像怎么样?现在就来试试吧!
构建一个小的合成图像
我们可以尝试生成一个合成图像,其中包含四个具有四个不同像素强度值的同心正方形,40、80、160 和 220。
- con_img = np.zeros([256, 256])
- con_img[0:32, :] = 40 # upper row
- con_img[:, :32] = 40 #left column
- con_img[:, 224:256] = 40 # right column
- con_img[224:, :] = 40 # lower row
- con_img[32:64, 32:224] = 80 # upper row
- con_img[64:224, 32:64] = 80 # left column
- con_img[64:224, 192:224] = 80 # right column
- con_img[192:224, 32:224] = 80 # lower row
- con_img[64:96, 64:192] = 160 # upper row
- con_img[96:192, 64:96] = 160 # left column
- con_img[96:192, 160:192] = 160 # right column
- con_img[160:192, 64:192] = 160 # lower row
- con_img[96:160, 96:160] = 220
- plt.imshow(con_img)
生成的图像将如下所示:

本文中提到的 Jupyter Notebook 中完整的 Python 编程代码可在这个 Github 存储库中找到:
https://github.com/jissdeodates/Beginner-s-Guide-to-Computer-Vision
参考:
图 1 – https://seevisionc.blogspot.com/2013/09/computer-vision-is-everywhere.html
图 2 - https://towardsdatascience.com/everything-you-ever-wanted-to-know-about-computer-vision-heres-a-look-why-it-s-so-awesome-e8a58dfb641e
图 3 - https://nptel.ac.in/content/storage2/courses/117104069/chapter_8/8_13.html
好消息!
小白学视觉知识星球
开始面向外开放啦
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/571548
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

