
- 1Windows常用的38个DOS命令_windows dos指令
- 2Windows GUI自动化控制工具之python uiAutomation
- 3adb 常用好用的几个命令_adb 常用命令
- 4mysql5.7主从全备恢复_MySQL主从数据备份恢复
- 5人工智能的常用十种算法
- 6Python版本与opencv版本的对应关系_opencv-python对应版本
- 7【git】上手git_git reset --hard origin
- 8Vivado快捷创建Vitis工程 (无需创建Platform Project)_vitis怎么打开已有工程
- 9Unity 和 OpenCV:结合计算机视觉和游戏开发_unity opencv
- 10【redis】redix在Linux下的环境配置和redis的全局命令
让MySQL和Redis数据保持一致的4种策略_redis和mysql数据一致性怎么保证
赞
踩
1 前言
先阐明一下 MySQL 和 Redis 的关系:MySQL 是数据库,用来持久化数据,一定程度上保证数据的可靠性;Redis 是用来当缓存,用来提升数据访问的性能。
关于如何保证 MySQL 和 Redis 中的数据一致(即缓存一致性问题),这是一个非常经典的问题。
使用过缓存的人都应该知道,在实际应用场景中,要想实时刻保证缓存和数据库中的数据一样,很难做到。
基本上都是尽可能让他们的数据在绝大部分时间内保持一致,并保证最终是一致的。
1.1 缓存不一致是如何产生的
如果数据一直没有变更,那么就不会出现缓存不一致的问题。
通常缓存不一致是发生在数据有变更的时候。因为每次数据变更你需要同时操作数据库和缓存,而他们又属于不同的系统,无法做到同时操作成功或失败,总会有一个时间差。在并发读写的时候可能就会出现缓存不一致的问题(理论上通过分布式事务可以保证这一点,不过实际上基本上很少有人这么做)。
虽然没办法在数据有变更时,保证缓存和数据库强一致,但对缓存的更新还是有一定设计方法的,遵循这些设计方法,能够让这个不一致的影响时间和影响范围最小化。
1.2 缓存更新的几种设计
缓存更新的设计方法大概有以下四种:
-
先删除缓存,再更新数据库(这种方法在并发下最容易出现长时间的脏数据,不可取)
-
先更新数据库,删除缓存(Cache Aside Pattern)
-
只更新缓存,由缓存自己同步更新数据库(Read/Write Through Pattern)
-
只更新缓存,由缓存自己异步更新数据库(Write Behind Cache Pattern)
接下来详细介绍一些这四种设计方法
2 设计方法一:先删除缓存,再更新数据库
这种方法在并发读写的情况下容易出现缓存不一致的问题
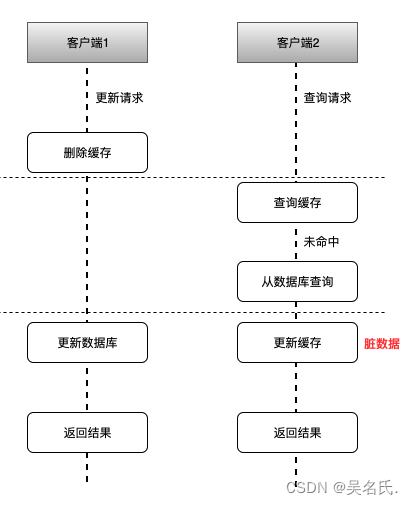
如上图所示,其可能的执行流程顺序为:
- 客户端1 触发更新数据A的逻辑
- 客户端2 触发查询数据A的逻辑
- 客户端1 删除缓存中数据A
- 客户端2 查询缓存中数据A,未命中
- 客户端2 从数据库查询数据A,并更新到缓存中
- 客户端1 更新数据库中数据A
可见,最后缓存中的数据 A 跟数据库中的数据 A 是不一致的,缓存中的数据A是旧的脏数据。
因此一般不建议使用这种方式。
3 设计方法二:先更新数据库,再让缓存失效
这种方法在并发读写的情况下,也可能会出现短暂缓存不一致的问题
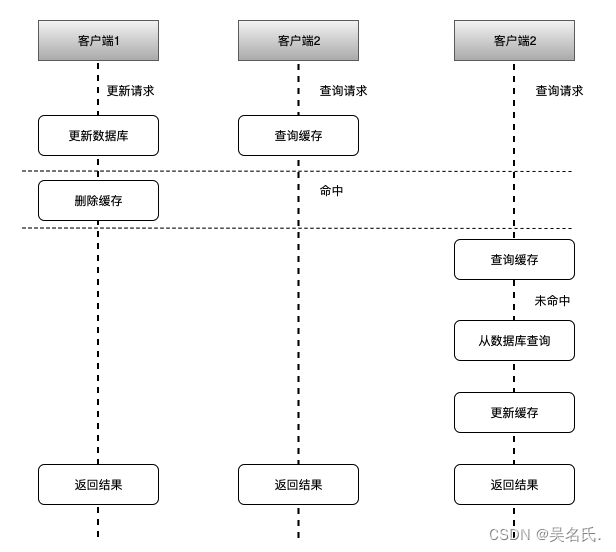
如上图所示,其可能执行的流程顺序为:
- 客户端1 触发更新数据A的逻辑
- 客户端2 触发查询数据A的逻辑
- 客户端3 触发查询数据A的逻辑
- 客户端1 更新数据库中数据A
- 客户端2 查询缓存中数据A,命中返回(旧数据)
- 客户端1 让缓存中数据A失效
- 客户端3 查询缓存中数据A,未命中
- 客户端3 查询数据库中数据A,并更新到缓存中
可见,最后缓存中的数据A和数据库中的数据 A 是一致的,理论上可能会出现一小段时间数据不一致,不过这种概率也比较低,大部分的业务也不会有太大的问题。
4 设计方法三:只更新缓存,由缓存自己同步更新数据库(Read/Write Through Pattern)
只更新缓存,由缓存自己同步更新数据库(Read/Write Through Pattern)
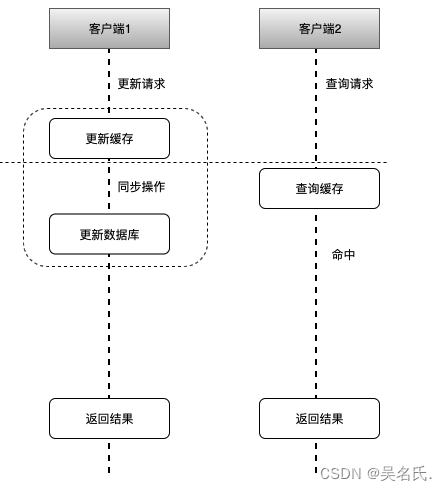
如上图所示,其可能执行的流程顺序为:
- 客户端1 触发更新数据 A 的逻辑
- 客户端2 触发查询数据 A 的逻辑
- 客户端1 更新缓存中数据 A,缓存同步更新数据库中数据 A,再返回结果
- 客户端2 查询缓存中数据 A,命中返回
Read Through 和 WriteThrough 的流程类似,只是在客户端查询数据A时,如果缓存中数据A失效了(过期或被驱逐淘汰),则缓存会同步去数据库中查询数据A,并缓存起来,再返回给客户端。
这种方式缓存不一致的概率极低,只不过需要对缓存进行专门的改造。
5 只更新缓存,由缓存自己异步更新数据库(Write Behind Cache Pattern)
这种方式性详单于是业务只操作更新缓存,再由缓存异步去更新数据库,例如:
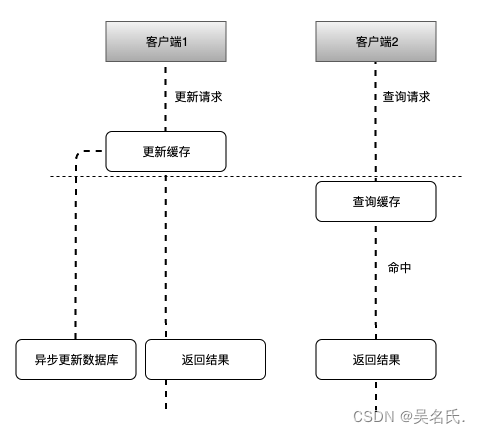
如上图所示,其可能的执行流程顺序为:
- 客户端1 触发更新数据 A 的逻辑
- 客户端2 触发查询数据 A 的逻辑
- 客户端1 更新缓存中的数据 A,返回
- 客户端2 查询缓存中的数据 A,命中返回
- 缓存异步更新数据 A 到数据库中
这种方式的优势是读写的性能都非常好,基本上只要操作完内存后就返回给客户端了,但是其是非强一致性,存在丢失数据的情况。
如果在缓存异步将数据更新到数据库中时,缓存服务挂了,此时未更新到数据库中的数据就丢失了。
6 小结
上面讲到的几种缓存更新的设计方式,都是前人总结出来的经验,这些方式或多或少都有一些弊端,并不完美,实际上也很难有完美的设计。大家在做系统设计的时候,也不要去追求完美,要有一些取舍,找到一种最适合自己业务场景的方式就行。


