
- 1ComfyUI本地Windows环境部署
- 2实现一个简单的顺序表(Java代码)_用java设计一个有序顺序表(元素已排序,递增或递减)
- 3uniapp使用腾讯im 无ui集成方案写法_腾讯im uniapp
- 4【Linux—进程间通信】共享内存的原理、创建及使用
- 5centos7 安装mysql ,已经填坑_宝塔unable to locate package bt-mysql57
- 6@Param注解
- 7vue element UI常遇到的bug_elementui表单的bug
- 8计算机毕业论文选题 - 毕设选题推荐_计算机毕设选题推荐
- 9Mac基于Docker-ubuntu构建c/c++编译环境
- 10Gitee + PicGo搭建markdown图床_本地搭建git显示markdown_gitee picgo
基于深度学习的自然场景文字识别系统研究 faster-RCNN + CRNN (二)_fasterrcnn文字检测
赞
踩
上文链接 https://blog.csdn.net/dzcera/article/details/122955738
4实验结果及设置
4.1数据集
本文采用ICDAR2013,ICDAR2015数据集并将ICDAR2013,ICDAR2015 dataset 转化为 PASCAL_VOC dataset 格式对于模型进行训练和验证。其中ICDAR2013数据集样本多为自然场景水平字符,同时包含字符图片和单词图片,训练集共有3567张裁剪后的图片,测试集共有1439张裁剪后的图片。ICDAR2015数据集样本多为复杂自然场景中倾斜模糊等受背景影响较大的图片。
4.2本文实验环境
本文实验开发环境为Intel i7-9750h,GPU为NVIDIA GTX1050
lmdb0.97
numpy1.17.2
Pillow6.1.0
six1.12.0
torch1.2.0
torchvision0.4.0
4.3实验结果及分析
根据Faster R-CNN中的“image-centric”采样策略,RPN通过反向传播(BP,back-propagation)和随机梯度下降(SGD,stochastic gradient descent)进行端到端(end-to-end)的网络训练。依照RPN和Faster R-CNN两者之间的特征共享技术,两个网络共享一个相同的卷积层,构成一个统一的网络。Faster R-CNN模型分别用转化为PASCAL_VOC dataset格式后的ICDAR2013和ICDAR2015中的自然图像进行训练。同时VGG16 是基于大量真实图像的 ImageNet 图像库预训练的网络,本项目训练时将学习好的 VGG16 的权重迁移到Faster R-CNN上作为网络的初始权重,通过迁移学习的方式提高了训练速度。本文训练的模型经过多次训练后的文字检测方法识别准确率为90.91%,检测精度高。
为了测试本项目的性能,实验模型测试采用多张自然场景,不同干扰因素的文字图片。以其中的三个样本为例,首先我们选取三个样本中场景干扰因素较小,文字较为清晰的图片进行测试。可以看到训练好的模型可以准确的检测识别出文字的内容,遮挡部分文字的干扰因素并没有对识别结果造成严重的影响。检测结果逐词分割,有较高的识别率。其次选取一张常见的自然场景文字图片,以自然环境为场景文字识别图片的主体,文字所占图片中的空间占比较小且较为分散,由不同颜色的文字组成,并有类似文字的告示牌图样干扰。可以看到训练后的网络可以准确识别该类文字,基本不受自然场景干扰因素的影响。最后一个样本中,训练模型选择了场景内容较为复杂的自然场景图片,该图片中自然场景较为复杂,有人为建筑和人群等干扰因素。图中有多处文字片段,且文字的颜色、样式、倾斜程度和文字所处光照条件均不相同,占据图片中的空间比例极小。训练后的模型在检测这张图片的时候仅能检测识别到一处图片占比空间较大的文字。而将图片裁剪后,所有文字内容均可识别检测出,这也是目前需要进一步改进的地方。


图 1场景干扰因素较小,文字较为清晰的文字图片

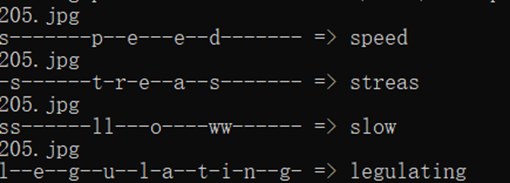
图 2场景干扰因素较大,文字较为清晰的文字图片


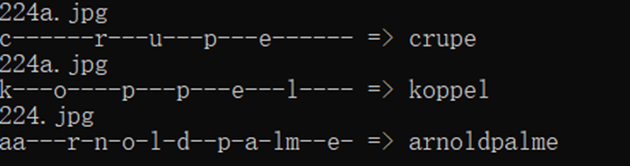
图 3场景干扰因素较大,文字较为模糊的文字图片
文字检测识别是一种通用识别技术,特别是自然场景的检测与识别近些年已成为深度学习计算机视觉方向的研究热点。如今传统的文字识别技术已经相对成熟,但自然场景文字识别准确率较低,至今还未能达到实用的程度。本文实验尝试从不同于现有方法的角度,利用Faster R-CNN和CRNN结合的方法提高了检测精度。通过考虑文字特征实现文本检测定位,利用卷积神经网络检测自然场景中的英文文本,操作步骤简单,可行度高。实验测试图片来自已公开的训练集和网络,包括背景干扰、倾斜弯曲、低分辨率、模糊等极端场景,实验结果证明本文采用的方法适应性强,在复杂场景下鲁棒性能好,在场景干扰情况,也能保证文字的准确检测和识别。本文未能实现多语言的混合文本识别,相关问题还需要进一步的研究。

