
热门标签
热门文章
- 1kafka java api示例_kafka生产者和消费者的javaAPI的示例代码
- 2彻底弄懂ES6中的Map和Set
- 3论文浅尝 | 基于表示学习的大规模知识库规则挖掘
- 4监控MySQL的工具_mysql enterprise monitor
- 5Redis面试题24道
- 6ModuleNotFoundError: No module named ‘mysql‘解决方案_modulenotfounderror: no module named 'mysql
- 7Linux Mysql表名默认区分大小写【已解决】_mysql-5.7.18 linux版本的配置文件区分大小写
- 8正排索引 vs 倒排索引 - 搜索引擎具体原理_正排索引和倒排索引
- 9MAC OS X 系统镜像各版本下载_macos下载
- 10git 下载特定分支_git 下载分支
当前位置: article > 正文
论文浅尝 | 基于表示学习的大规模知识库规则挖掘
作者:繁依Fanyi0 | 2024-05-17 07:57:19
赞
踩
scalable rule learning via learning representation论文研读
 链接:www.ict.griffith.edu.au/zhe/pub/OmranWW18.pdf
链接:www.ict.griffith.edu.au/zhe/pub/OmranWW18.pdf
动机
传统的规则挖掘算法因计算量过大等原因无法应用在大规模KG上。为了解决这个问题,本文提出了一种新的规则挖掘模型RLvLR(Rule Learning via LearningRepresentation),通过利用表示学习的embedding和一种新的子图采样方法来解决之前工作不能在大规模KG上scalable的问题。
亮点
文章的亮点主要包括:
(1)采样只与对应规则相关的子图,在保存了必要信息的前提下极大减少了算法的搜索空间和计算量;
(2)提出了argument embedding,将规则表示为predicate sequence;
概念
1. closed-pathrule,LHS记为body(r),RHS记为head(r)
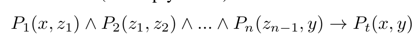
2. supportdegree of r
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/582647
推荐阅读
相关标签

