
- 1ubuntu 分区 方案_ubuntu分区
- 2网络协议与攻击模拟_01winshark工具简介
- 3SOC课程——④——Verilog程序(Testbench的编写)_verilog testbench end
- 4大一python上机题库及答案,大一python期末简答题_、在python中运算符+不仅可以实现数值的 相加、字符串连接,还可以实现列表
- 5Python数据可视化之Wordcloud_spyder安装wordcloud
- 6低功耗蓝牙透传芯片KT6368A的详细说明,平均电流50uA_kt6368a数据手册
- 7Flutter 莫名其妙系列 -- 混合开发集成Flutter出现Failed to apply plugin class ‘FlutterPlugin‘_could not create task ':generatelockfiles'.
- 8hadoop搭建常见错误及解决方案_hadoop运行后出现许多at
- 9Mac连接虚拟机(Linux系统)_怎么用mac终端连接虚拟机
- 10【解决IDEA控制台中文乱码,亲测有效,分析全面】_idea控制台输出中文乱码怎么解决
爱因斯坦霉霉同框只需15秒,最新可控AI一玩停不下来,在线试玩已出丨开源
赞
踩
白交 发自 凹非寺
量子位 | 公众号 QbitAI
现在,AI绘画完全可以做到指哪打哪了!
这边哈士奇,那边牧羊犬,背景在下雪天。
啪叽!一幅画就这么完成了。

这个最新MultiDiffusion模型,不管选的区域位置有多离谱,它都能给你画出指定的东西来。
比如,你能看到大象和奶牛同时握草??

而且在线可试,亲测大概15秒就能出,你甚至可以看到泰勒与爱因斯坦跨时空同框。
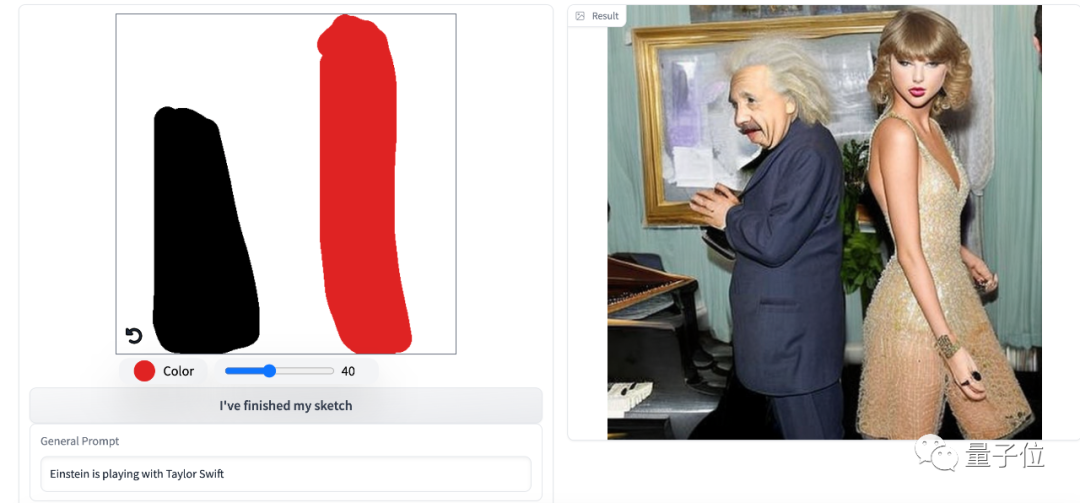
要知道以前AI绘画最大的一个bug就是不可控,但现在人类拥有了更多的控制权。
总之就是,想画什么就画什么,想往哪画就往哪画!
有网友赶紧上手试了试:Not Bad!
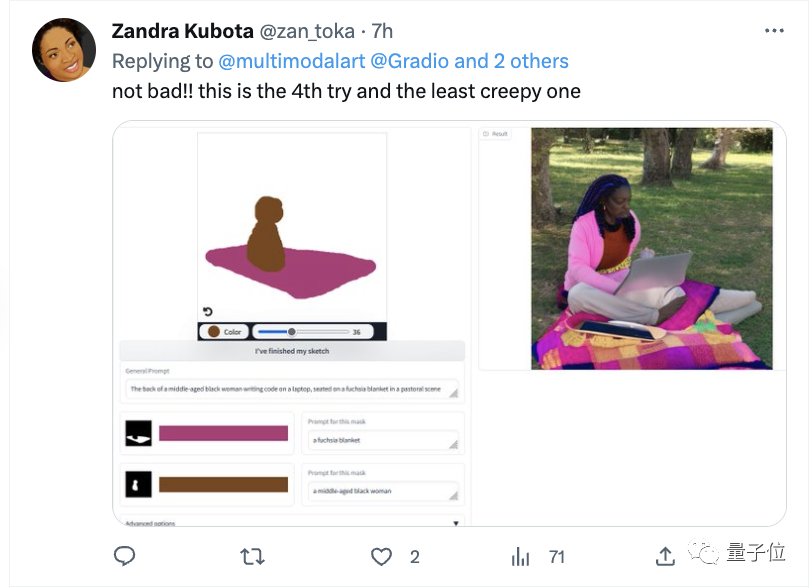
想往哪画就往哪画
从效果来看,主要有三个方面的应用。
文本到高分辨率全景生成;
精确区域生成;
任意长宽比粗略区域生成。
首先,只需要一句话,就可以生成512*4609分辨率的全景图。
一张有滑雪者的雪山顶峰的照片。

摄影师也不用爬楼了,直接获得城市夜景图。

当然更为主体功能,那就是给特定区域单独提示,然后AI绘画就来指哪画哪。
比如在黑色部分是一个明亮的盥洗室,红色区域是一面镜子、蓝色部分是花瓶、黄色部分是白色的水槽。

就这么随手一个拼图画,结果就生成了真实场景。

不过也有一些bug,像一些超现实的,他就有点太天马行空了。
比如三体人在宇宙中大战人类。
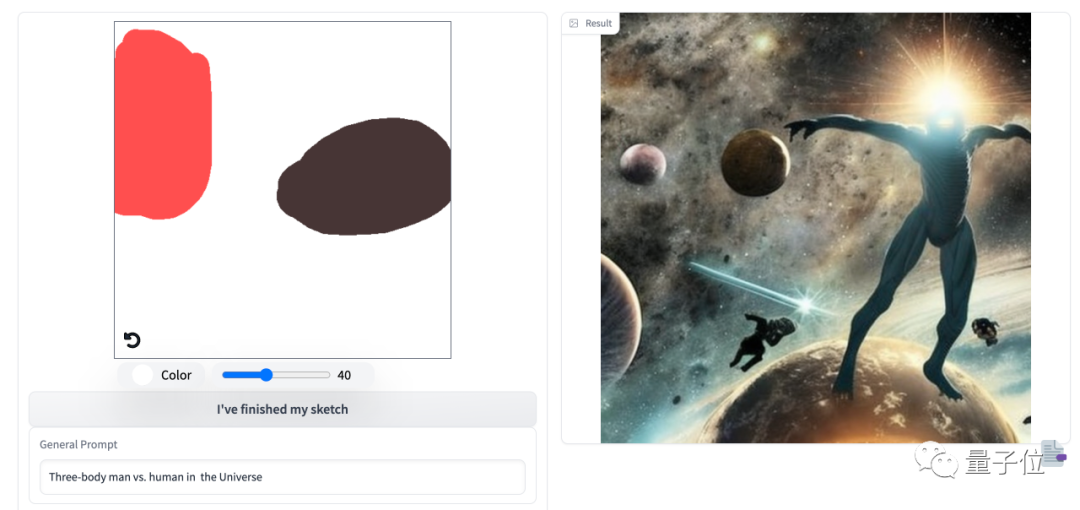
当然也可以无需那么精确,只需标个大致位置,还支持任意长宽比的图像。

蓝色部分是埃菲尔铁塔、红色是粉色的云、绿色是热气球 。

关键是各种构图都十分地合理、场景效果以及实际物体相对大小也都十分精准。
图像生成可控
背后的这个模型叫做MultiDiffusion,这是一个统一的框架,能实现多功能和可控的图像生成。
以往即便Diffusion模型给图像生成带来变革性影响,但用户对生成图像的可控性、以对新任务的快速适应仍是不小的挑战。
研究人员主要是通过重新训练、微调,或者另外开发工具等方式来解决。前不久爆火插件ControlNet正是解决了图像生成的可控性,
而MultiDiffusion无需进一步训练或微调,就可一次实现对生成内容的多种灵活控制,包括期望的长宽比、空间引导信号等。

简单来说,MultiDiffusion的关键在于,在预先训练好的扩散模型上定义一个全新的生成过程。从噪声图像开始,在每个生成步骤中,解决一个优化任务。
然后再将多个扩散生成过程与一组共享的参数或约束结合起来,目标是将每个部分都尽可能去接近去噪版本。
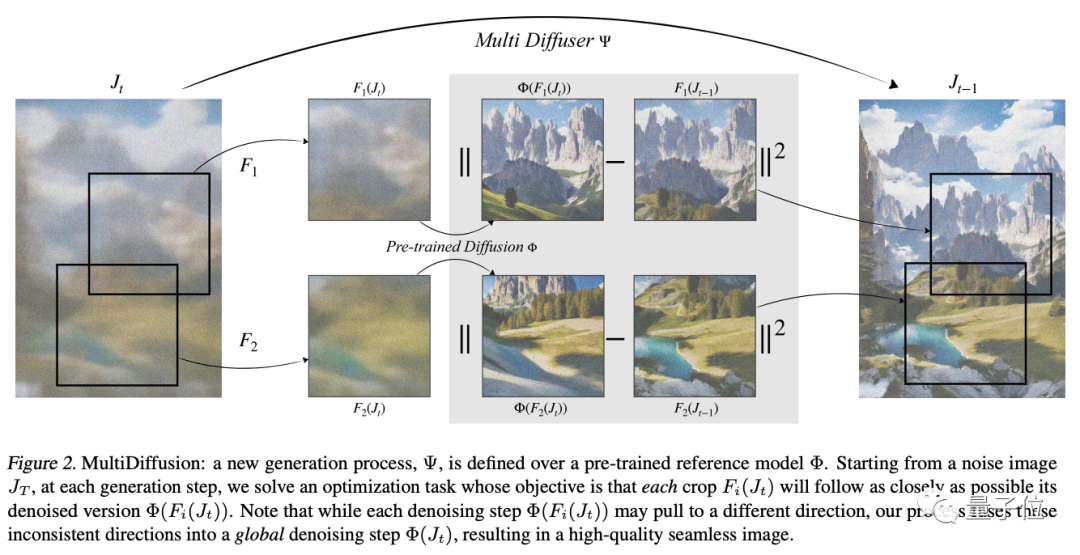
即便有时候每个步骤都可能会将图像拉向不同的方向,但最终融合到一个全局去噪步骤当中,得到一个无缝图像。

来自魏茨曼科学研究所
这篇论文主要来自位于以色列雷霍沃特的魏茨曼科学研究所。

两位共同一作Omer Bar-Tal、Lior Yariv分别是魏兹曼科学研究院计算机科学和应用数学系的研究生和博士生,后两位分别是他们的导师。

△左:Omer Bar-Tal;右:Lior Yariv
好了,感兴趣的旁友可戳下方试一试哦!
https://huggingface.co/spaces/weizmannscience/MultiDiffusion
主页链接:
https://multidiffusion.github.io/
论文链接:
https://arxiv.org/abs/2302.08113
— 完 —
3月29日「中国AIGC产业峰会」
抢票开启
「中国AIGC产业峰会」定档3月29日,线下会场抢票开启!
百度袁佛玉、智源林咏华、澜舟科技周明、小冰徐元春、科大讯飞高建清、启元世界袁泉、云舶科技梅嵩、特赞王喆、微软关玮雅、源码资本黄云刚、元语智能朱雷、无界Ai马千里、Tiamat青柑、峰瑞资本陈石等来自产学研界大咖嘉宾,还有重磅嘉宾陆续确认中。
扫描下方二维码,报名峰会线下会场啦~

点这里声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

