
- 1Xilinx DDR3 IP核使用问题汇总(持续更新)和感悟
- 2已解决Command “python setup.py egg_info“ failed with error code 1 in /tmp/pip-build-23ykqx51/pynacl/_创建egg项目报错code1
- 3循环神经网络(RNN)_rnn循环神经网络
- 4【头歌-Python】Python第九章作业(初级)第 1、2、4 关_附件中是某月每天的最高温度和最低温度数据,请绘制本月的高温曲线(红色、圆点标记
- 5Linux 中 Docker 启动服务时报错 driver failed programming external connectivity on endpoint: xxxx
- 6揭露通信培训套路—打着招聘旗号贷款培训的招转培,你中招了吗?_培训机构招聘套路
- 7OpenHarmony集成OCR三方库实现文字提取
- 8关于Vite打包项目后图片丢失的解决方法_打包的时候 svg图片不显示
- 9VUE学习中的一些JS知识点_vue charat
- 10elementui表单规则校验_elementui表单校验规则
BP神经网络理解原理——用Python编程实现识别手写数字(翻译英文文献)_bp算法实验 mnist手写数字图像集 python
赞
踩
BP神经网络理解原理——用Python编程实现识别手写数字
备注,这里可以用这个方法在csdn中编辑公式: https://www.zybuluo.com/codeep/note/163962
一、前言
本文主要根据一片英文书籍进行学习,并且尝试着在 PyCharm 环境下用Python软件进行编程验证效果,书的名字叫:Using neural nets to recognize handwritten digits
其中书的链接为: http://neuralnetworksanddeeplearning.com/chap1.html
这里讲解了BP神经网络和构成还有如何通过神经网络训练识别手写数字,用了Python作为实践的例子。
前期准备
我这里是按照这个链接弄的:https://m.jb51.net/article/166781.htm
这里需要用到 PyCharm 环境用Python进行验证,需要用到的Python库为 Numpy,这里使用的python开发环境为 JupyterLab 和 PyCharm 下。其中安装库的方法是在DOS窗口键入:
pip install PackageName以scipy为例子,键入以后等着下载就行,如图所示:
但是存在一个问题,下载速度太慢,我们只需要加一个参数 -i ,速度就可以提升10倍数,举个例子:
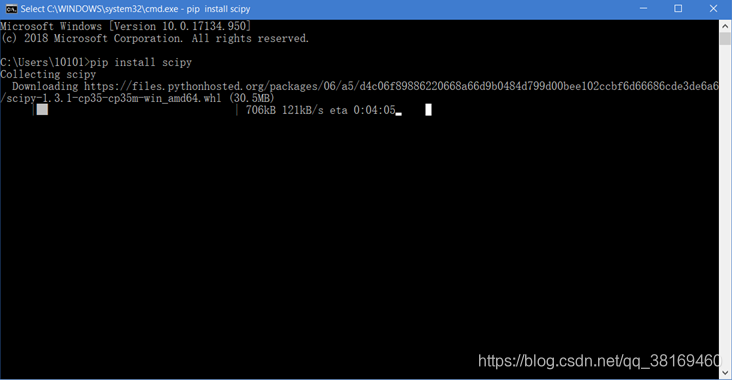
pip install PyQt5 -i https://pypi.tuna.tsinghua.edu.cn/simple
网址可以为:
清华
https://pypi.tuna.tsinghua.edu.cn/simple/
中科大
https://pypi.mirrors.ustc.edu.cn/simple/
阿里云
https://mirrors.aliyun.com/pypi/simple/
豆瓣
http://pypi.douban.com/simple/- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这样就下载安装好库了,这些都是题外话,不过是很有用的方法,接下来开始正式学习。
前期准备——补充
因为导入数据不成功,所以网上找了许多方法,这里所有学习链接:
这里程序的理解,一部分是按照自己学习python以后的基础进行学习,一部分是按照这个这个链接进行理解: https://www.cnblogs.com/jsxyhelu/p/8719131.html 还有这个链接用来加载数据: https://www.cnblogs.com/jsxyhelu/p/8719196.html 然后导入失败,我就按照本章博客的方法,使用 CoCalc 网络环境进行下载数据集,其中 CoCalc 的使用和下载链接为: https://cocalc.com 其中 CoCalc 的英文使用教程和中文使用教程为: https://doc.cocalc.com/getting-started.html 英文使用教程 https://www.jianshu.com/p/e009997ab5d8 这里面有博主的中文教程 在JupyterLab中导入库: https://blog.csdn.net/chenpe32cp/article/details/80350409 从tensorflow中导入手写数字集: https://www.cnblogs.com/eczhou/p/7860508.html

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
因为在下文中学习中,遇到一个很大的问题,下载的数据难以导入python开发环境中,难以进行,自己在网络上找了许多方法,这里不再选择 PyCharm 作为开发环境,选择使用 JupyterLab 作为开发环境。其中导入数据采用的方法是从作者的 github 上直接下载,然后也可以使用 tensorflow 的库在 PyCharm 上就行下载学习,因此需要安装 tensorflow 的库,还有 keras 的库。这里使用 JupyterLab 中进行安装,其中安装的网站为:
https://jupyter.org/然后在 JupyterLab 中安装库,在命令行中输入并执行:
!pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install keras -i https://pypi.tuna.tsinghua.edu.cn/simple- 1
然后就可以在 JupyterLab 中执行程序,并且进行神经网络的训练。
还有一种方法导入数据的方法是,这里使用的Python环境为 PyCharm ,如果在你的根目录下有MINIST_data,则直接加载,如果没有,会从tensorflow 中载入,使用方式根据这个链接进行导入数据:
https://www.cnblogs.com/eczhou/p/7860508.html二、理论部分——神经网络的基础概念学习
我这里学习是根据上面的链接进行学习的,而我接下来的任务主要就是理解和翻译这篇文章,这篇文章对神经网络的原理,还有它的构成部分 感知器的选择, S型函数, 等梯度下降法 等等都有详细的推导和解释,对我们了解BP神经网路的原理,还有接下来的其他类型神经网络学习都有着很大的帮助,最后它还用Python编程验证了想法,进行了实践,它也在github上给出了源码还有训练数据和测试数据,通过这个短短74行代码,就可以实现识别手写数字正确率达到96%,这让我们有极大的兴趣了解它,从而可以极大的帮助我们理解BP神经网络。 下面开始正式学习。
1.第一部分——引入
对于下面这串数字:
我们都可以很轻松的识别出这串数字是:504192,但是这种轻松是很具有欺骗性的。在我们大脑的每个半球,都有一个主要的视觉皮层,也被称为V1,在V1层包含了1.4亿多个神经元,它们之间有数百亿个连接。然而,人类的视觉涉及到的不止有V1层,整个系列的视觉皮层 V2,V3,V4 和 V5 - 正在逐步进行更复杂的图像处理,随着层的增加,处理的越来越抽象,更有助于我们发散性记忆或其他应用。而随着数百万年来的进化,我们人类特别适应来基于视觉理解世界。因此,识别手写的数字并不简单,相反,我们人类是惊人的,非常善于理解我们的眼睛向我们展示的东西。 但几乎所有这些工作都是在无意识中完成的。如果尝试编写计算机程序来识别上述数字,那么视觉模式识别的难度就会变得很明显。 当我们自己做的时候看起来很容易变得非常困难。 关于我们如何识别形状的简单直觉 - “a 9在顶部有一个循环,在右下角有一个垂直笔划” - 结果并不是那么简单的算法表达。 当你试图使这些规则变得精确时,你很快就变得没有精力继续下去。
用神经网络以不同的方式解决问题。 这个想法是采取大量的手写数字,,作为训练样本,比如这样的训练样本:
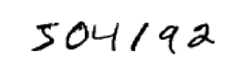
神经网络相当于开发一个可以从这些训练样例中学习的系统。 换句话说,神经网络使用样本来自动推断用于识别手写数字的规则。 此外,通过增加训练样本的数量,网络可以更多地了解手写数字的规则,从而提高其准确性。 因此,虽然我上面只显示了100个训练数字,但也许我们可以通过使用数千甚至数百万或数十亿的训练样例来构建更好的手写识别器。
在这里,将编写一个计算机程序,实现一个学习识别手写数字的神经网络。 该程序只有74行,并没有使用特殊的神经网络库。 但是这个简短的程序可以识别精度超过96%的数字,无需人工干预。 此外,在后面的章节中,我们将开发出可以将准确度提高到99%以上的想法。 实际上,最好的商业神经网络现在非常好,银行可以使用它们来处理支票,并通过邮局来识别地址。
本博文采用识别手写数字作为例子,因为它是一般学习神经网络的优秀原型问题。 作为原型,它有一个最佳点:它具有挑战性 - 识别手写数字并不是一件小事 - 但要求极其复杂的解决方案或巨大的计算能力并不困难。 此外,它是开发更高级技术的好方法,例如深度学习。 因此,在整本书中,我们将反复回到手写识别问题。 在本书的后面,我们将讨论如何将这些想法应用于计算机视觉中的其他问题,以及语音,自然语言处理和其他领域。
当然,如果本章的目的只是编写一个识别手写数字的计算机程序,那么这一章就会短得多! 但在此过程中,我们将开发许多关于神经网络的关键思想,包括两种重要类型的人工神经元**(感知器和sigmoid神经),以及神经网络的标准学习算法,称为随机梯度下降**。 在整个过程中,我专注于解释为什么事情按照它们的方式完成,以及建立你的神经网络直觉。 这需要更长时间的讨论,而不是我刚刚介绍了正在发生的事情的基本机制,但是对于你将获得更深刻的理解是值得的。 在收益中,到本章结尾,我们将能够理解深度学习是什么,以及它为何重要。

2.第二部分——神经网络的构造
a11、理论部分1——感知器(Sigmoid神经的基础)
什么是神经网络? 首先,我将解释一种称为感知器的人工神经元。 感知器是由科学家Frank Rosenblatt在20世纪50年代和60年代开发的,受到Warren McCulloch和Walter Pitts早期工作的启发。今天,使用其他模型的人工神经元更为常见 - 在本书中,在神经网络的许多现代工作中,使用的主要神经元模型是一个称为S形神经元的模型(Sigmoid 神经)。 我们很快就会得到sigmoid神经元。 但要理解为什么sigmoid神经元的定义方式,它们值得花时间先了解感知器。
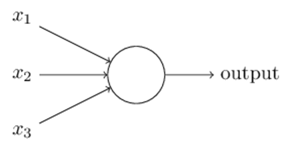
那么感知器如何工作呢? 感知器需要几个二进制输入:x1,x2,…,并产生一个二进制输出:
在所示的示例中,感知器具有三个输入,x1,x2,x3。 通常,它可以有更多或更少的输入。Rosenblatt 提出了一个计算输出的简单规则。 他引入了权重w1,w2,…,表示相应输入对输出的重要性的实数。 神经元的输出0或1由加权和
∑
j
ω
j
x
j
\sum_{j}\omega_j\ x_j
j∑ωj xj 是否小于或大于某个阈值确定。就像权重一样,阈值是一个实数,它是神经元的参数。 用更精确的代数术语来表达它:
这就是感知器的工作方式。
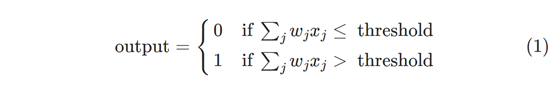
a12、例子部分1——感知器(Sigmoid神经的基础)
上面的理论部分讲的是基本的数学模型。 您可以考虑感知器的一种方式是,它是一种通过权衡证据来做出决策的方法。
让我举个例子:假设周末即将到来,你已经听说你所在城市将举办奶酪节。你喜欢奶酪,并试图决定是否去参加奶酪节。 您可以通过权衡三个因素来做出决定:
1.天气好吗?
2.你的男朋友或女朋友想陪你吗?
3.在奶酪节举办地点有交通站点吗?(假设你没有车)。
我们可以通过相应变量x1,x2,x3来表示这三个因素。例如,如果天气好的话,我们有x1 = 1,如果天气不好,我们有x1 = 0。同样,如果你的男朋友或女朋友想去,x2 = 1,如果不想去,x2 = 0。 同样交通便利性也适用于x3。
假设你非常喜欢奶酪,以至于即使你的男朋友或女朋友不感兴趣 你也想去参加。但也许你真的厌恶恶劣的天气,如果天气不好,就没有办法去参加电影节。 您可以使用感知器来模拟这种决策。 一种方法是为天气选择权重w1 = 6,对于其他条件选择w2 = 2和w3 = 2。 较大的w1值表明天气对你很重要,远远超过你的男朋友或女朋友是否加入你,或者公共交通的近处。 最后,假设您为感知器选择了5的阈值。 通过这些选择,感知器实现了所需的决策模型,每当天气好时输出1,并在天气恶劣时输出0。 无论你的男朋友或女朋友想去,或公共交通是否在附近,输出都没有区别。
通过改变权重和阈值,我们可以得到不同的决策模型。 例如,假设我们选择了一个阈值3。然后感知器会决定你应该在天气好的时候去节日,或者当节日都在公共交通附近,而你的男朋友或女朋友愿意加入你时 你就愿意参加节日。 换句话说,它是一个不同的决策模型。 降低门槛意味着你更愿意去参加奶酪节。
显然,感知器并不是人类决策的完整模型!但是,这个例子说明了感知器如何权衡不同类型的证据以便做出决策。 一个复杂的感知器网络可以做出非常微妙的决定,这似乎是合理的:
在这个网络中,第一列感知器 - 我们称之为第一层感知器 - 通过权衡输入证据做出三个非常简单的决定。 第二层的感知器怎么样? 每个感知者都通过权衡第一层决策的结果来做出决定。 通过这种方式,第二层中的感知器可以在比第一层中的感知器更复杂和更抽象的水平上做出决定。 而第三层中的感知器可以做出更复杂的决策。 通过这种方式,感知器的多层网络可以参与复杂的决策制定。
顺便说一下,当我定义感知器时,我说感知器只有一个输出。 在上面的网络中,感知器看起来像有多个输出。事实上,它们仍然是单一输出。 多个输出箭头仅仅是指示感知器的输出被用作若干其他感知器的输入。

a21、理论部分2——感知器(Sigmoid神经的基础)
让我们简化描述感知器的方式.重新改写一下,b = -threshold(阈值),然后
ω
.
x
=
∑
j
ω
j
x
j
\omega.x = \sum_{j}\omega_j\ x_j
ω.x=j∑ωj xj
这里w.x为权重向量和输入向量的点积,下面这个式子是基于上面的式子(1)改写的,本质是一样的。式子如下:
您可以将偏差视为衡量感知器输出1的容易程度的衡量标准。或者说,偏差为可以衡量感知器触发的容易程度。 对于具有非常大偏差的感知器,感知器输出11非常容易。但如果偏差非常负,那么感知器难以输出1.显然,引入偏差只是一个很小的变化。 我们如何描述感知器,但我们稍后会看到它会导致进一步的符号简化。 因此,在本书的其余部分我们将不会使用阈值,我们将始终使用偏差(bias)。
我已经将感知器描述为权衡证据以做出决策的方法。 可以使用感知器的另一种方式是计算我们通常认为是基础计算的基本逻辑函数,诸如AND,OR和NAND之类的函数。 下面的不是讲述重点,具体的可以自己阅读英文文献,感知器可以通过设定 bias 和 权重,就可以把感知器当作一个与非门,通过多个与非门的连接,可以实现多种门的功能。
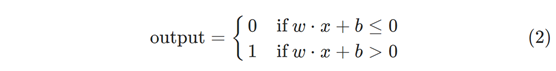
a22、例子部分2——感知器(Sigmoid神经的基础)
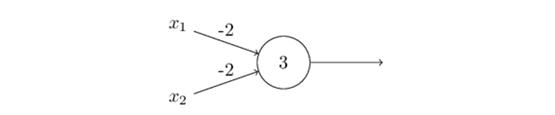
例如,假设我们有一个感知器有两个输入,每个输入的权重为-2,-2,总偏差(bias)为3.这是我们的感知器:
然后我们看到输入00产生输出1,因为(-2)* 0 +( - 2)* 0 + 3 = 3是正的。 在这里,我引入了乘法符号来使乘法显式化。 类似的计算表明输入01和10产生输出1.但是输入11产生输出0,因为(-2)* 1 +( - 2)* 1 + 3 = -1(-2)* 1 +( - 2 )* 1 + 3 = -1为负。所以感知器实现了一个与非门!
b、理论部分——Sigmoid神经元
学习算法听起来很棒。但是我们如何为神经网络设计这样的算法呢? 假设我们有一个感知器网络,我们想用它来学习解决一些问题。例如,网络的输入可能是来自扫描的手写数字图像的原始像素数据。 我们希望网络学习权重和偏差,以便网络输出正确地对数字进行分类。 要了解学习如何发挥作用,假设我们对网络中的某些权重(或偏见)进行了微小的改变。 我们所希望的是,这种小的重量变化只会导致网络输出的相应变化很小。 正如我们稍后将看到的,这个属性将使学习成为可能。 原理上,这就是我们想要的(显然这个网络太简单了,无法进行手写识别!):
如果权重(或偏差)的微小变化确实导致输出的变化很小,那么我们可以微微的调整权重和偏差,那样我们就可以实现网络的学习。 例如,假设当网络应该是“9”时,网络错误地将图像分类为“8”。网络自己开始慢慢的纠正,然后对权重和偏差进行微小的改变,使网络更接近地将图像分类为“9”。就这样网络一遍又一遍地改变权重和偏差,以产生更好的输出,这就是是网络的自我学习。
但是存在一个问题,当我们的网络包含感知器时,一点一点的自我纠正就不会成功地实现的。 实际上,网络中任何单个感知器的权重或偏差的微小变化有时会导致该感知器的输出完全翻转,例如从0到1。因此,翻转可能导致网络其余部分也发生更大的偏差,从而余下网络变成更复杂的形式。 以上面的例子,虽然您的“9”现在可能被正确分类,但网络在所有其他图像上的行为可能会以某种难以控制的方式完全改变。 这使得很难看到如何逐渐修改权重和偏差,以使网络更接近期望的行为。 也许有一些聪明的方法可以解决这个问题。 但是,我们如何才能获得感知器网络才能学习,这并不是显而易见的。
因为感知器上面说的缺点,因此我们可以通过引入一种称为S形神经元的新型人工神经元来解决这个问题。 Sigmoid神经元与感知器类似,但经过修改,因此其权重和偏差的微小变化让输出也产生微小的变化。 这是sigmoid 神经元网络学习的重要一点,接下来,描述一下Sigmoid神经元:
就像感知器一样,S形神经元有输入x1,x2,… 但是,这些输入不仅仅是0或1,可以为0到1之间的任何值。因此,例如,0.638 … 等等都是是S形神经元的有效输入。 同样就像感知器一样,S形神经元对每个输入都有权重,w1,w2,… 和整体偏差 b。 但是输出不是0或1.相反,它是
δ
(
ω
x
+
b
)
\delta(\omega x + b)
δ(ωx+b) 其中 σ 称为sigmoid函数,顺便说一下,σ有时被称为逻辑函数,这个新一类神经元称为逻辑神经元。 记住这个术语是有用的,因为这些术语被很多使用神经网络的人使用。 但是,我们将坚持使用sigmoid术语。并且定义为:
更明确地说,输入x1,x2,… ,权重w1,w2,…和偏差b的sigmoid神经元的输出是:
乍一看,Sigmoid神经元看起来与感知器非常不同。 如果你还不熟悉它,那么sigmoid函数的代数形式可能看起来很让人迷惑。事实上,感知器和Sigmoid神经元之间存在许多相似之处,而S形函数的代数形式更多地是技术细节,而不是理解的真正障碍。
为了理解他们的相似性,下面我们对Sigmoid神经进行分析,z = wx + b,趋近于正无穷时,输出为 1 ,如果 z = wx + b 趋近于负无穷时,输出为 0 .当 z 在一个合适的尺度范围内,就可以基本近似于感知器模型。
σ的代数形式怎么样?我们怎么能理解这个?事实上,σ的确切形式并不那么重要 - 真正重要的是函数所体现的性质。这是形状:
如果 σ 函数来模拟来阶跃,则 Sigmoid 神经元将是感知器,因为输出将是1或0,这取决于w⋅x+b 为大的正数还是负数。严格来说,我们需要修改该点的阶跃函数。但是你明白了,通过使用实际的σ函数,我们得到了一个平滑的感知器,正如上面已经所说的那样。实际上,σ 函数的平滑性是重要性质。σ的平滑度意味着权重中的小变化 Δwj 和偏差中的 Δb 将在神经元的输出中产生小的变化 Δoutput。实际上,通过微积分可以得出Δoutput近似于:

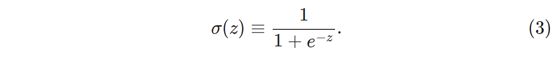
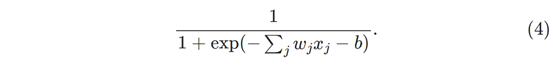

其中上式为全微分的表达式。虽然上面的表达看起来很复杂,但是表达式不重要,但是有一个特别好的特点:Δoutput 是权重 Δw 和偏差 Δb 的线性函数。 这种线性关系可以实现权重和偏差的微小的变化,以实现输出中任何所需的微小变化。通过上面的讨论, Sigmoid 神经元具有与感知器相同的定性行为,但是 Sigmoid 神经元可以更容易实现改微小的改变重量和偏差从而微小的改变输出。
如果σ的形状真正重要,而不是它的确切形式,那么为什么要使用公式(3)中用于 σ 的特定形式?事实上,在本书后面我们考虑f(w⋅x+ b)为某些其他激活函数f(⋅)。当我们使用不同的激活函数时,主要的变化是等式(5)中的偏导数值的改变。事实证明,当我们稍后计算这些偏导数时,使用σ将简化代数运算,因为指数具有微分不变性。一般来说, σ 函数在神经网络中一般作为激活函数。
我们应该如何解释Sigmoid神经的的输出?显然,感知器和Sigmoid神经元之间的一个重要区别是:S形神经元不仅输出0或1,而且它可以在0和1之间输出任何实数,所以0.173 … 0.173 …和0.689 … 0.689 …之类的值是合法的产出。例如,如果我们想要使用输出值来表示输入到神经网络的图像中的像素的平均强度,这可能是有用的,但是有时候这样使用不是那么方便。假设我们希望网络输出指示“输入图像是9”或“输入图像不是9”。显然,如果输出结果为0或者1,这样就很容易辨别。但是对于连续的Sigmoid函数,我们可以设置一个约定来解决这个问题,例如,通过决定将至少0.5的任何输出当作为表示“9”,并将任何小于0.5的当作解释为“不是“9”。
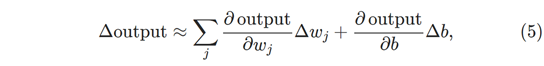
c、理论部分——神经网络的结构
在下一节中,我将介绍一个神经网络,它可以很好地分类手写数字。 为下面学习做准别,我们解释一些术语,这些术语可以让我们为网络的不同部分命名。 假设我们有网络:
如前所述,该网络中最左层称为输入层,层内的神经元称为输入神经元。 最右边或输出层包含输出神经元,或者在这种情况下,包含单个输出神经元。中间层称为隐藏层,因为该层中的神经元既不是输入也不是输出。上面的网络只有一个隐藏层,但有些网络有多个隐藏层。
网络中输入和输出层的设计通常很简单。 例如,假设我们试图确定手写图像是否描绘为“9”。 设计网络的一种自然方式是将图像像素的强度编码到输入神经元中。 如果图像是64×64灰度图像,那么我们将有4,096 = 64×64 个输入神经元,强度在0和1之间适当缩放。输出层将只包含一个神经元,输出小于0.5的值表示“输入图像不是9”,大于0.5的值表示“输入图像是9”。
虽然神经网络的输入和输出层的设计通常是很直接的,但隐藏层的设计可能是相当有意义的。 特别是,用一些简单的经验法则来概括隐藏层的设计过程是不可能的。 相反,神经网络研究人员已经为隐藏层开发了许多设计启发式方法,这有助于人们从他们的网中获得他们想要的行为。例如,这种启发式方法可用于帮助确定如何根据训练网络所需的时间权衡隐藏层的数量。 我们将在本书后面讨论几种这样的设计启发式方法。
到目前为止,我们一直在讨论神经网络,其中一层的输出用作下一层的输入。这种网络称为前馈神经网络(BP神经网络)。 这意味着网络中没有环路 - 信息总是向前馈送,从不反馈。 如果我们确实有循环,我们最终会遇到σ函数的输入取决于输出的情况。这很难理解,所以我们不允许这样的循环。
然而,还有其他模型的人工神经网络,其中反馈回路是可能的。这些模型称为递归神经网络。这些模型中的想法是让神经元在变为静止之前在一段有限的时间内激发。 这种激发可以刺激其他神经元,这些神经元可能会在一段时间内发射,也可以持续一段时间。 这导致更多的神经元发射,因此随着时间的推移,我们会得到一连串的神经元的激发。闭环以后不会在这样的模型中引起问题,因为神经元的输出仅在稍后的某个时间影响其输入,而不是瞬间。
递归神经网络比前馈网络影响力小,部分原因是循环网络的学习算法(至少到目前为止)功能较弱。 但经常性的网络仍然非常有趣。 与前馈网络相比,他们在实际中更接近我们的大脑。 并且循环网络可以解决重要问题,这些问题只能通过前馈网络很难解决。 但是,在本书中我们只专注于更广泛使用的前馈网络。

d、用简单网络分类手写数字
定义了神经网络的结构以后,让我们回到手写识别。我们可以将识别手写数字的问题分成两个子问题。首先,我们想要一种将包含许多数字的图像分成一系列单个数字图像的方法。例如,我们分割这个图像:
把它分割为:
我们人类很容易解决这个分割问题,但计算机程序正确分解图像是一项挑战。 一旦图像被分割,程序就可以对每个数字进行分类。例如,我们希望我们的程序能够识别出上面的第一个数字5。
我们将专注于编写程序来解决第二个问题,即对个别数字进行分类。我们这样做是因为事实证明,**一旦你有一个很好的方法来分类个别数字,分割问题就不那么难解决了。**有许多方法可以解决分割问题。**一种方法是尝试许多不同的分割图像的方法,使用单个数字分类器对每个试验分割进行评分。**如果单个数字分类器对所有片段中的分类充满信心,则试验分段效果好;如果分类器在一个或多个片段中具有很多麻烦,则分段效果不理想。这个想法可以用于很好地解决分割问题。因此,我们不用担心数字分割的问题,而是专注于开发一个神经网络来识别单个手写数字。
要识别个别数字,我们会使用三层神经网络:
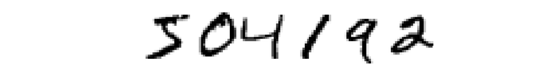

网络的输入层包含编码输入像素值的神经元。如下一节所述,我们的网络训练数据将由扫描的手写数字的28×28像素图像组成,因此输入层包含784 = 28×28 个神经元。为简单起见,省略了上图中的大多数784输入神经元。输入像素是灰度,值为0.0表示白色,值1.0表示黑色,在0到1之间灰度由浅变深。
网络的第二层是隐藏层。我们用n表示这个隐藏层中的神经元数量,我们将试验n的不同值,其中n = 15。
网络的输出层包含10个神经元。 如果第一个神经元激活,即输出 ≈ 1,那么这将表明网络认为该数字是0.如果第二个神经元激活,则表明网络认为该数字是1,等等。更准确地说,我们将输出神经元从0到9编号,并找出哪个神经元来匹配数字的最大激活值。 如果该神经元是神经元编号6,那么我们的网络将猜测输入数字是6.依此类推其他输出神经元。
这里没有采用四个输出神经元的原因,在原文中有解释,这个不讲述。因为如果为四个输出,用二进制方式表示也可以满足要求,比如0000代表数字0,0001代表数字1,等等。因为2^4 = 16,还有6种可能会导致其他错误,而且,只要某一个输出出问题,会导致结果偏差特别大,因此不选择这样的输出方式。
现在,尽管如此,这只是一种启发式方法。 没有什么说三层神经网络必须以我描述的方式运行,隐藏的神经元检测简单的组件形状。 也许一个聪明的学习算法会找到一些权重分配,让我们只使用4个输出神经元。 但作为一种启发式方法,我所描述的思维方式非常有效,并且可以为您设计良好的神经网络架构节省大量时间。

e1、理论部分——等梯度下降法
现在我们有了神经网络的设计,它如何学会识别数字呢? 我们需要的第一件事是要学习的数据集 - 一个所谓的训练数据集。 我们将使用MNIST数据集,其中包含数万个手写数字的扫描图像以及正确的分类。 MNIST的名字来源于它是由美国国家标准与技术研究所NIST收集的两个数据集的修改子集。 这是来自MNIST的一些图片:
MNIST数据分为两部分。第一部分包含60,000张图像用作训练数据。 这些图像是来自250人的扫描手写样本,其中一半是美国人口普查局的雇员,其中一半是高中生。图像为灰度,尺寸为28 x 28像素。 MNIST数据集的第二部分是10,000个图像,用作测试数据。 同样,这些是28乘28的灰度图像。 我们将使用测试数据来评估我们的神经网络学会识别数字的程度。 为了对性能进行良好测试,测试数据来自与原始培训数据不同的250人(虽然仍然是人口普查局员工和高中生之间的一组)。 这有助于让我们相信我们的系统可以识别在培训期间没有看到的人写的数字。
我们将使用符号x来表示训练输入。将每个训练输入x视为28×28 = 784维向量。向量中的每个元素表示图像中单个像素的灰度值。 我们将通过y = y(x)表示相应的期望输出,其中y是10维向量。 例如,如果特定的训练图像xx描绘了6,那么 y(x)= (0,0,0,0,0,0,1,0,0,0)’,是网络的期望输出。 注意,这里的 ‘ 是转置操作,将行向量转换为普通(列)向量。
我们想要的是一种算法,它允许我们找到权重和偏差,以便网络的输出近似于所有训练输入x的y(x) 。为了量化我们实现这一目标的程度,我们定义了成本函数,有时称为损失或目标函数。 我们在本书中使用术语成本函数,但您应该注意其他术语,因为它经常用于研究论文和神经网络的其他讨论:

这里,w表示网络中所有权重的集合,b表示所有偏差的集合,n是训练输入的总数,a是输入x时网络输出的向量,总和超过所有训练输入,x。当然,输出a取决于x,w和b,但为了保持符号简单,我没有明确表示这种依赖性。符号∥v∥仅表示矢量v的范数。我们称C为二次成本函数,它有时也被称为均方误差或只是MSE。分析二次代价函数的形式,我们看到C(w,b)是非负的。此外,成本C(w,b)变小,即C(w,b)≈0,正好当y(x)近似相等时输出a。所以我们的训练算法如果能找到权重和偏差那么做得很好,那么C(w,b)≈0。相比之下,当C(w,b)很大时,它表现不佳 - 这意味着对于大量输入x下,y(x)接近输出a。因此,我们的训练算法的目的是最小化成本C(w,b)作为权重和偏差的函数。换句话说,我们希望找到一组权重和偏差,使成本尽可能小。我们将使用称为梯度下降的算法来做到这一点。
为什么要引入二次成本函数呢?毕竟,我们重点不是对数字的正确分类吗? 为什么不尝试直接最大化的接近正确分类那个数字,而不是像二次成本函数这样的中间过程?主要原因是在于正确分类的图像数量不是网络中权重和偏差的平滑函数。在大多数情况下,对权重和偏差进行小的改变不会导致正确分类的训练图像的数量发生任何变化。 这使得很难弄清楚如何改变权重和偏差以获得改进的性能。 如果我们改为使用像二次成本那样的平滑成本函数,那么很容易对权重和偏差进行微小的改变以便提高成本。 这就是我们首先关注最小化二次成本的原因,然后我们才会检查分类精度。
回归正题,我们训练神经网络的目标是找到权重和偏差,使二次成本函数C(w,b)C(w,b)最小化。这是一个很好的问题,但它有很多分散注意力的结构 - 正如目前所提出的那样 - 将w和b解释为权重和偏差,也需要通过σ函数,网络架构的选择,MNIST等等。 事实证明,我们可以通过忽略大部分结构来理解大量数据,而只关注一小部分。 所以现在我们将忘记所有关于成本函数的特定形式,与神经网络的连接等等。 相反,我们会想象我们只是被赋予了许多变量的函数,我们希望最小化该函数。 我们将开发一种称为梯度下降的技术,可用于解决这种最小化问题。 然后我们将回到我们想要最小化神经网络的特定函数。
让我们假设我们试图最小化一些函数C(v)。 这可以是许多变量的任何实值函数,v = v1,v2,… 请注意,我已经用v替换了w和b符号,以强调这可能是任何函数 - 我们不再专注于神经网络环境。 为了最小化C(v),有助于将C想象为仅仅两个变量的函数,我们将其称为 v1 和 v2 :
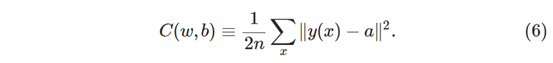
我们想要的是找到C达到其全局最小值的地方。当然,对于上面绘制的函数,我们可以观察图形并找到最小值。但是一般函数C可能是许多变量的复杂函数,并且通常不可能仅仅通过眼睛来找到最小值,而且计算机也不可能就以这样简单的方式实现。
解决问题的一种方法是使用微积分来试图找到最小的分析。我们可以计算导数,然后尝试使用它们来找到C是极值的位置。 如果C只是一个或几个变量的函数,这样可能有用。 但是当我们有更多的变量时,这样的方法变得不可行。 而对于神经网络,我们通常需要更多的变量 - 最大的神经网络具有成本函数,这些函数依赖于数十亿的权重和极其复杂的偏差。使用微积分来最小化那个就行不通!
好的,所以微积分不起作用。 幸运的是,在实际生活中我们遇到的现象,它提出了一种运行良好的算法。我们首先将我们的成本函数视为一种山谷。我们想象一个球从山谷的斜坡上滚下来。 我们的日常经验告诉我们,球最终会滚到山谷的底部。 也许我们可以用这个想法来找到函数的最小值?我们随机选择(假想的)球的起点,然后模拟球滚动到山谷底部时的运动。 我们可以简单地通过计算C的衍生物(也许是一些二阶导数)来进行这种模拟 - 这些衍生物会告诉我们关于山谷的局部“形状”我们需要知道的一切,以及我们的球应该如何滚动。
根据我刚刚写的内容,你可能会认为我们会考虑摩擦和重力的影响等来写下牛顿的球运动方程。实际上,我们不会非常认真地对待滚球的现象 - 我们正在设计一种算法来最小化C,而不是开发出物理定律的精确模拟!以这样的视角旨在激发我们的想象力,而不是限制我们的思维。 因此,不要深入了解物理学的所有细节,让我们简单地问自己:如果我们被宣布为上帝一天,并且可以制定我们自己的物理定律,指挥它应该如何滚动,有什么定律。我们可以选择运动,这样球会一直滚到山谷的底部吗?
为了使这个问题更精确,让我们考虑当我们在v1方向上移动球少量Δv1和在v2方向上移动少量Δv2时会发生什么。 微积分告诉我们C变化如下:
我们将找到一种选择Δv1和Δv2的方法,以使ΔC为负; 也就是说,这样球就会滚落到山谷中。 为了弄清楚如何做出这样的选择,有助于将Δv定义为v变化的矢量,Δv ≡ (Δv1,Δv2)’ 。我们还将C的梯度定义为偏导数的矢量,(∂C/∂v1,∂C/∂v2)’。 我们用∇C表示梯度向量,即:
稍后我们将根据Δv和梯度∇C重写变化ΔC。然而,在谈到这一点之前,我想澄清一些有时会让大家感觉困难的问题。当我们第一次遇到∇C符号时,我们有时会想到他们应该如何思考∇符号。 竟是什么意思? 事实上,将∇C视为一个单一的数学对象 - 上面定义的向量 - 恰好用两个符号编写就完全没问题了。 从这个角度来看,∇只是一段挥动的标志性旗帜,告诉你“嘿,∇C是一个渐变矢量”。 有更高级的观点,其中∇可以被视为一个独立的数学实体(例如,作为微分算子),但我们不需要这样的观点。
利用这些定义,ΔC的表达式(7)可以被重写为:

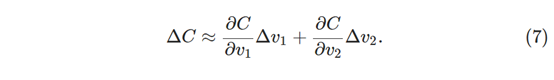
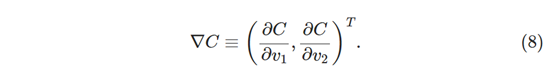
这个等式有助于解释为什么∇C被称为梯度向量:∇C将v的变化与C的变化联系起来。但是这个等式真正令人兴奋的是它让我们看到如何选择Δv以使ΔC为负。 特别是,假设我们选择:
其中η是一个非常小的正数(称为学习率)。然后等式(9)告诉我们:
所以如果我们根据(10)中等式改变v,这保证了ΔC≤0,这样就能保证C一直在减小。因此,我们将采用等式(10)来定义我们的梯度下降算法中的球的“运动定律”。 也就是说,我们将使用等式(10)来计算Δv的值,然后将球的位置v移动该量:
然后我们将再次使用此更新规则,来进行另一项操作。 如果我们一直这样做,我们将继续减少C,知道达到最低点——即最小值。
总之,梯度下降算法的工作方式是重复计算梯度∇C,然后沿相反方向移动,“下降”山谷的斜率,我们可以像这样想象它:
请注意,使用此规则,梯度下降不会再现真实的物理运动。 在现实生活中,球具有动量,并且该动量可以允许它在斜坡上滚动,或者甚至(暂时)滚动上坡。 只有在确定摩擦力的影响之后,球才能保证滚入山谷。 相比之下,我们选择Δv的规则只是说“现在下去”。找到最低限度仍然是一个很好的规则!
为了使梯度下降正常工作,我们需要选择学习率η足够小,使得等式(9)是一个很好的近似。如果我们不这样做,我们最终可能会得到ΔC>0,这显然不会很好! 同时,我们不希望η太小,因为这将使变化Δv变小,因此梯度下降算法将非常缓慢地工作。 在实际实现中,η经常变化,因此等式(9)仍然是良好的近似,但算法不是太慢。我们稍后会看到它是如何工作的。
当C是两个变量的函数时,我已经解释了梯度下降。**但是,实际上,即使C是更多变量的函数,一切也能正常工作。**特别假设C是m变量v1,…,vm的函数。 然后通过小的变化Δv =(Δv1,…,Δvm)’ ,产生的C中的变化ΔC是:
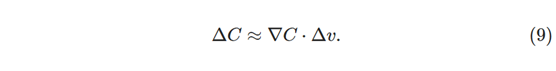
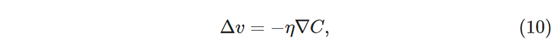
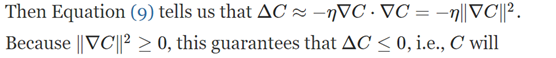
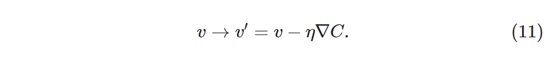

其中梯度∇C是向量:
正如两个变量的情况一样,我们可以选择:
并且我们保证ΔC的(近似)表达式(12)将为负。通过重复应用更新规则,这为我们提供了一种将梯度跟踪到最小的方法,即使C是许多变量的函数:
您可以将此更新规则视为定义梯度下降算法。它为我们提供了一种重复改变位置v的方法,以便找到函数C的最小值。规则并不总是有效 - 有些事情可能出错并且防止梯度下降找到C的全局最小值,我们将在后面的章节中回顾这一点。 但是,在实践中,梯度下降通常效果非常好,而在神经网络中,我们会发现它是一种最小化成本函数的有效方法,因此有助于网络学习。
实际上,甚至有一种感觉,即梯度下降是寻找最小值的最佳策略。让我们假设我们试图在位置上移动Δv,以便尽可能地减少C。这相当于最小化 ΔC ≈ ∇C⋅Δv。我们将约束移动的大小,使得对于一些小的固定ε>0,∥Δv∥=ε 。换句话说,我们希望移动是固定大小的一步,我们试图找到尽可能减少C的移动方向。可以证明,最小化∇C⋅Δv 的Δv的选择是 Δv=-η∇C,其中 η=ε/∥∇C∥ 是由尺寸约束确定∥Δv∥=ε。因此,梯度下降可以被视为在最大程度上立即减少C的方向上采取步骤的方式。
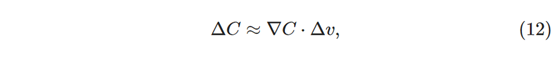
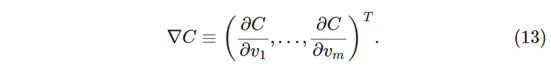
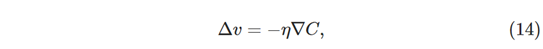
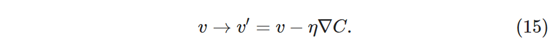
e2、实践部分——等梯度下降法
证明最后一段的断言。 提示:如果您还不熟悉Cauchy-Schwarz不等式,您可能会发现熟悉它很有帮助。
当C是两个变量的函数时,我解释了梯度下降,当它是两个以上变量的函数时。当C只是一个变量的函数时会发生什么?您能否提供梯度下降在一维情况下所做的几何解释?在本书中,我们将使用梯度下降(和变化)作为我们在神经网络中学习的主要方法。
我们如何应用梯度下降来学习神经网络? 我们的想法是使用梯度下降来找到权重wk和偏差bl,从而最小化等式(6)中的成本函数。 为了了解这是如何工作的,让我们重新说明梯度下降更新规则,权重和偏差代替变量vj。 换句话说,我们现在具有分量wk和bl,并且梯度向量∇C具有相应的分量∂C/∂wk和∂C/∂bl。根据组件写出梯度下降更新规则,我们有:
通过重复应用此更新规则,希望找到最低成本函数。 换句话说,这是一个可用于在神经网络中学习的规则。
应用梯度下降规则存在许多挑战。我们将在后面的章节中深入研究这些内容。 但是现在我只想提一个问题。 为了理解问题所在,让我们回顾一下方程(6)中的二次成本。这里有:
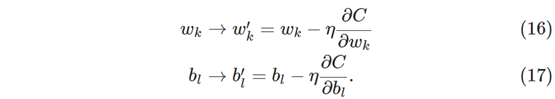
随机梯度下降的概念可用于加速学习。我们的想法是通过计算随机选择的训练输入的小样本的∇Cx来估计梯度∇C。通过对这个小样本进行平均,我们可以快速得到真实梯度∇C的良好估计,这有助于加速梯度下降,从而加速学习。
为了使这些想法更加精确,随机梯度下降通过随机挑选少量m随机选择的训练输入来工作。 我们将标记那些随机训练输入X1,X2,…,Xm,并将它们称为小样本。 如果样本量m足够大,我们预计∇CXj的平均值将大致等于所有∇Cx的平均值,即:
最左面与最右面相等时:
这样我们可以通过计算随机选择的小样本的梯度来估计总梯度。
为了将其明确地连接到神经网络中的学习,假设wk和bl表示我们的神经网络中的权重和偏差。 然后随机梯度下降通过挑选随机选择的一小批训练输入,并进行训练:
其中总和超过当前小批量中的所有训练样例Xj。然后我们选择另一个随机选择的小批量和训练,等等,直到我们用完所有数据,就说完成了一个训练,那时我们重新开始一个新的训练。
顺便提一下,值得注意的是,约定不同于成本函数的缩放以及权重和偏差的小批量更新。在等式(6)中,我们将总成本函数缩放了1/n因子。人们有时会省略1/n,总结单个训练样本的成本而不是平均值。**当事先不知道训练样本的总数时,这尤其有用。例如,如果实时生成更多训练数据,则会发生这种情况。**并且,以类似的方式,小批量更新规则(20)和(21)有时省略总和前面的1/m项。从概念上讲,这几乎没有什么区别,因为它相当于重新调整学习率η。但是在对不同的工作进行详细比较时,值得关注。
我们可以认为随机梯度下降就像政治民意调查一样:使用等梯度下降对小批量采应用比整批更容易,就像进行民意调查比完全选举更容易一样。例如,如果我们有一个大小为n = 60,000的训练集,如在MNIST中,并选择一个小批量大小(比方说)m = 10,这意味着我们将获得6的因子,在估算梯度时小批量为6,000!当然,**估计不会是完美的 - 会有统计波动 - 但它并不需要是完美的:我们真正关心的是朝着有助于减少C的大方向前进,这意味着我们不要需要精确计算梯度。**在实践中,随机梯度下降是在神经网络中学习的常用且强大的技术,并且它是我们将在本书中开发的大多数学习技术的基础。
梯度下降的极端方法是是使用仅为1的小批量大小。即,给定训练输入x,我们根据规则更新我们的权重和偏差:

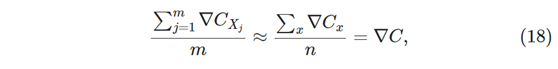
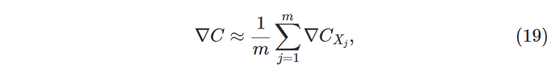
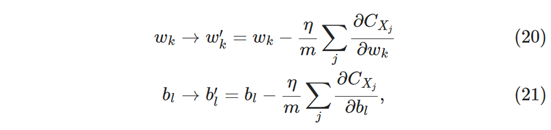
然后我们选择另一个训练输入,并再次更新权重和偏差。此过程称为增量学习。增量学习中,神经网络一次只从一个训练输入中学习(就像人类一样)。与具有小批量的随机梯度下降相比,列出增量学习的一个优点和一个缺点。
让我讨论一个有时会让人们对梯度下降感到厌烦的观点来结束本节。在神经网络中,成本C当然是许多变量的函数 - 所有的权重和偏差 - 因此在某种意义上定义了一个非常高维空间的表面。有些人开始思考:“嘿,我必须能够想象出这些维度的情况”。他们可能会开始担心:“我无法从四维以的空间进行思考,更不用说五个(或五百万)”。他们缺少一些特殊能力,“真正的”超级数学家有哪些能力?当然,答案是否定的。即使是大多数专业数学家也无法将四个维度可视化,如果有的话。相反,他们使用的技巧是开发其他方式来表示无法想象的事。这正是我们上面所做的:我们使用ΔC的代数(而不是视觉)表示来计算如何移动以减少C。;我们的代数技巧只是一个例子,这些技术可能没有我们在三维可视化时所习惯的简单性,但是一旦你建立了这样的概念,你就可以很好地思考高维度。我不会在这里详细介绍,但如果您感兴趣,那么您可能会喜欢阅读这些关于专业数学家在高维度上使用的一些技术的讨论。虽然所讨论的一些技术非常复杂,但大多数最好的内容都是直观且易于访问的,并且可以被任何人掌握。
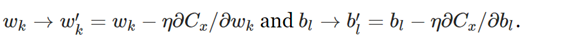
f、应用网络来分类数字
好吧,让我们编写一个程序,学习如何识别手写数字,使用随机梯度下降和MNIST训练数据。 我们将使用一个简短的Python(2.7)程序,只需74行代码! 我们需要的第一件事是获取MNIST数据。 如果你是一个git用户,那么你可以通过克隆本书的代码库来获取数据:
git clone https://github.com/mnielsen/neural-networks-and-deep-learning.git 顺便提一下,当我之前描述过MNIST数据时,我说它被分成了60,000个训练图像和10,000个测试图像。这是官方的MNIST描述。实际上,我们将以稍微不同的方式分割数据。我们将按原样保留测试图像,但将60,000图像MNIST训练集分成两部分:一组50,000个图像,我们将用它来训练我们的神经网络,以及一个单独的10,000图像验证集。我们不会在本章中使用验证数据,但是在本书的后面我们会发现它有助于确定如何设置神经网络的某些超参数 - 例如学习速率等等,这些都不是我们的学习算法直接选择。尽管验证数据不是原始MNIST规范的一部分,但许多人以这种方式使用MNIST,并且验证数据的使用在神经网络中很常见。当我从现在开始参考“MNIST训练数据”时,我将指的是我们的50,000图像数据集,而不是原始的60,000图像数据集。
使用python之前,请安装numpy的库,按照博客最前面的方法安装。
在下面给出完整列表之前,让我解释一下神经网络代码的核心功能。核心是一个网络类,我们用它来代表一个神经网络。 这是我们用来初始化Network对象的代码:
class Network(object):
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]- 1
- 2
- 3
- 4
- 5
- 6
- 7
在此代码中,列表大小包含各个层中的神经元数量。 因此,例如,如果我们想创建一个Network对象,第一层有2个神经元,第二层有3个神经元,最后一层有1个神经元,我们用代码创建:
net = Network([2, 3, 1]) 网络对象中的偏差和权重都是随机初始化的,使用 Numpy 中 np.random.randn 函数生成平均值为0和标准差为1的高斯分布。这种随机初始化为我们的随机梯度下降算法提供了一个起点。在后面的章节中,我们将找到更好的方法来初始化权重和偏差,但现在这样做。 请注意,网络初始化代码假定第一层神经元是输入层,并且省略为这些神经元设置任何偏差,因为偏差仅用于计算后面层的输出。
另请注意,偏差和权重存储为 Numpy 矩阵列表。 因此,例如 net.weights[1] 是一个 Numpy 矩阵,存储连接第二层和第三层神经元的权重。 (这不是第一层和第二层,因为Python的列表索引从0开始。)因为net.weights [1]相当冗长,所以我们只是表示矩阵w。它是一个矩阵,使得 wjk 是第二层中第k个神经元与第三层中第j个神经元之间连接的权重。 j和k下标的这种排序可能看起来很奇怪 - 肯定交换j和k指数更有意义吗? 使用这种排序的最大好处是它意味着第三层神经元的激活矢量是:
在这个等式中含有的较多的信息,所以我们对各个字母代表的元素进行分析。a是第二层神经元激活的载体。为了获得’a’,我们将a乘以权重矩阵w,并添加偏差的向量b。然后,我们将元素σ元素应用于向量wa + b 中的每个向量的元素。(这称为矢量化函数σ)很容易验证方程(2)给出与我们早先的规则(方程(4))相同的结果,用于计算S形神经元的输出。
以分量形式写出方程(22),并验证它给出与用于计算S形神经元输出的规则(4)相同的结果。考虑到所有这些,编写计算网络实例输出的代码很容易,我们首先定义Sigmoid函数:
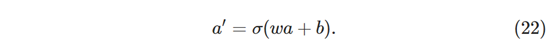
def sigmoid(z):
return 1.0/(1.0+np.exp(-z))- 1
注意,当输入 z 是向量或 Numpy 数组时,Numpy 会自动应用元素 sigmoid ,即以矢量化形式。
然后我们向Network类添加一个前馈方法,给定网络的输入a,返回相应的输出。所有的方法都应用于等式(22)的每一层:
def feedforward(self, a):
"""Return the output of the network if "a" is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a- 1
- 2
- 3
- 4
当然,我们希望网络对象做的主要事情是学习。为此,我们将为他们提供一种实现随机梯度下降的SGD方法。 这是代码:
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None): """Train the neural network using mini-batch stochastic gradient descent. The "training_data" is a list of tuples "(x, y)" representing the training inputs and the desired outputs. The other non-optional parameters are self-explanatory. If "test_data" is provided then the network will be evaluated against the test data after each epoch, and partial progress printed out. This is useful for tracking progress, but slows things down substantially.""" if test_data: n_test = len(test_data) n = len(training_data) for j in xrange(epochs): random.shuffle(training_data) mini_batches = [ training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)] for mini_batch in mini_batches: self.update_mini_batch(mini_batch, eta) if test_data: print "Epoch {0}: {1} / {2}".format( j, self.evaluate(test_data), n_test) else: print "Epoch {0} complete".format(j)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
training_data是表示训练输入和相应的期望**输出的元组(x,y)**的列表。变量epochs和mini_batch_size是 - 要训练的周期数的大小,以及采样时使用的小样本的大小。 eta是学习率,η。 如果提供了可选参数test_data,则程序将在每个训练时期后评估网络,并打印出部分进度。 这对于跟踪进度很有用,但会大大减慢速度。
代码的工作原理如下。在每个训练大周期下,它通过随机改选定训练数据组开始,然后将其划分为适当大小的小样本。这是从训练数据中随机抽样的简便方法。然后,对于每个mini_batch,我们使用等梯度下降法进行训练。这是通过代码self.update_mini_batch(mini_batch,eta)完成的,它仅使用mini_batch中的训练数据,根据梯度下降的单次迭代更新网络权重和偏差。 这是update_mini_batch方法的代码:
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The "mini_batch" is a list of tuples "(x, y)", and "eta"
is the learning rate."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
大部分工作都是由这句代码完成的:
delta_nabla_b, delta_nabla_w = self.backprop(x, y) 这个算法称为反向传播算法,这是一种计算成本函数梯度的快速方法。因此,update_mini_batch只需通过为mini_batch中的每个训练示例计算权重和偏差的微小变化量,然后适当地更新self.weights和self.biases。
我现在不打算展示self.backprop的代码。我们将在下一章研究反向传播的工作原理,包括self.backprop的代码。现在,假设它的行为与声明的一样,返回与训练示例x相关的适当梯度。
让我们看一下完整的程序,包括我在上面省略的文档字符串。除了self.backprop之外,程序是不言自明的 - 所有繁重的工作都是在self.SGD和self.update_mini_batch中完成的,这些我们已经讨论过了。**self.backprop利用一些额外的函数来帮助计算梯度,即sigmoid_prime,它计算σ函数的导数,**以及self.cost_derivative,我在这里不再赘述。您可以通过查看代码和文档字符串来获取这些(以及可能的细节)的要点。我们将在下一章详细介绍它们。请注意,虽然程序看起来很冗长,但很多代码都是文档字符串,旨在使代码易于理解。 实际上,该程序只包含74行非空格,非注释代码。 所有代码都可以在GitHub上找到。
链接为:https://github.com/mnielsen/neural-networks-and-deep-learning/blob/master/src/network.py
""" network.py ~~~~~~~~~~ A module to implement the stochastic gradient descent learning algorithm for a feedforward neural network. Gradients are calculated using backpropagation. Note that I have focused on making the code simple, easily readable, and easily modifiable. It is not optimized, and omits many desirable features. """ #### Libraries # Standard library import random # Third-party libraries import numpy as np class Network(object): def __init__(self, sizes): """The list ``sizes`` contains the number of neurons in the respective layers of the network. For example, if the list was [2, 3, 1] then it would be a three-layer network, with the first layer containing 2 neurons, the second layer 3 neurons, and the third layer 1 neuron. The biases and weights for the network are initialized randomly, using a Gaussian distribution with mean 0, and variance 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers.""" self.num_layers = len(sizes) self.sizes = sizes self.biases = [np.random.randn(y, 1) for y in sizes[1:]] self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])] def feedforward(self, a): """Return the output of the network if ``a`` is input.""" for b, w in zip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b) return a def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None): """Train the neural network using mini-batch stochastic gradient descent. The ``training_data`` is a list of tuples ``(x, y)`` representing the training inputs and the desired outputs. The other non-optional parameters are self-explanatory. If ``test_data`` is provided then the network will be evaluated against the test data after each epoch, and partial progress printed out. This is useful for tracking progress, but slows things down substantially.""" if test_data: n_test = len(test_data) n = len(training_data) for j in xrange(epochs): random.shuffle(training_data) mini_batches = [ training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)] for mini_batch in mini_batches: self.update_mini_batch(mini_batch, eta) if test_data: print "Epoch {0}: {1} / {2}".format( j, self.evaluate(test_data), n_test) else: print "Epoch {0} complete".format(j) def update_mini_batch(self, mini_batch, eta): """Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch. The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta`` is the learning rate.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)] def backprop(self, x, y): """Return a tuple ``(nabla_b, nabla_w)`` representing the gradient for the cost function C_x. ``nabla_b`` and ``nabla_w`` are layer-by-layer lists of numpy arrays, similar to ``self.biases`` and ``self.weights``.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w in zip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass delta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. for l in xrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w) def evaluate(self, test_data): """Return the number of test inputs for which the neural network outputs the correct result. Note that the neural network's output is assumed to be the index of whichever neuron in the final layer has the highest activation.""" test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data] return sum(int(x == y) for (x, y) in test_results) def cost_derivative(self, output_activations, y): """Return the vector of partial derivatives \partial C_x / \partial a for the output activations.""" return (output_activations-y) #### Miscellaneous functions def sigmoid(z): """The sigmoid function.""" return 1.0/(1.0+np.exp(-z)) def sigmoid_prime(z): """Derivative of the sigmoid function.""" return sigmoid(z)*(1-sigmoid(z))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
程序识别手写数字的程度如何?好吧,让我们首先加载 MNIST 数据。我将使用python的Module doc执行程序mnist_loader.py。 我们在Python shell中执行以下命令:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()- 1
- 2
当然,这也可以在一个单独的Python程序中完成,但如果你跟着它,它可能最容易在Python shell中完成。
加载MNIST数据后,我们将建立一个有30个隐含层的神经元网络。我们在导入上面列出的Python程序之后执行此操作:
>>> import network
>>> net = network.Network([784, 30, 10])- 1
最后,我们将使用随机梯度下降来学习超过30个周期 MNIST 中training_data,其中小样本大小为10,学习率为 η = 3.0:
>>> net.SGD(training_data, 30, 10, 3.0, test_data=test_data)请注意,如果您在阅读时运行代码,则需要一些时间来执行 - **对于典型的计算机(截至2015年),可能需要几分钟才能运行。我建议你设置运行,继续阅读,并定期检查代码的输出。如果您匆忙,可以通过减少周期数量,减少隐藏神经元的数量或仅使用部分训练数据来加快速度。**请注意,这些Python脚本旨在帮助您了解神经网络的工作方式,而不是高性能代码!当然,一旦我们训练了网络,它几乎可以在任何计算平台上快速运行。例如,一旦我们为网络学习了一组好的权重和偏差,就可以轻松地将其移植到在Web浏览器中的 Javascript 中运行,或者作为移动设备上的本机应用程序运行。在任何情况下,这里是神经网络的一次训练运行的输出的部分抄本。下面显示了每个训练周期后神经网络正确识别的测试图像的数量。正如你所看到的,在仅仅一个周期之后,这已经达到了10,000个中的9,129个,并且数量继续增长:
Epoch 0: 9129 / 10000
Epoch 1: 9295 / 10000
Epoch 2: 9348 / 10000
...
Epoch 27: 9528 / 10000
Epoch 28: 9542 / 10000
Epoch 29: 9534 / 10000- 1
- 2
- 3
- 4
- 5
- 6
也就是说,训练有素的网络给我们的分类率约为95% - 峰值时为95.42%(“Epoch 28”)! 作为第一次尝试,这是非常令人鼓舞的。 但是,我应告诉您,如果您运行代码,那么您的结果不一定与我的结果完全相同,因为我们将使用(不同的)随机权重和偏差初始化我们的网络。 为了在本章中产生结果,我已经进行了最好的三次运行。
让我们重新运行上面的实验,将隐藏神经元的数量更改为100.如前所述,如果您在阅读时运行代码,则应警告您需要花费一段时间才能执行(在我的机器上每个训练周期的实验需要几十秒钟,因此在代码执行时继续并行读取是明智的)。
>>> net = network.Network([784, 100, 10])
>>> net.SGD(training_data, 30, 10, 3.0, test_data=test_data)- 1
果然,这将结果提高到96.59%。至少在这种情况下,使用更多隐藏的神经元有助于我们获得更好的结果。
当然,为了获得这些准确性,我必须对训练周期的数量,小样本大小和学习率η做出具体选择。 如上所述,这些被称为神经网络的特别的参数,以便将它们与我们的学习算法所学习的参数(权重和偏差)区分开来。 如果我们选择我们的特别的参数参数很差,我们就会得到不好的结果。 例如,假设我们选择学习率为 η=0.1。
>>> net = network.Network([784, 100, 10])
>>> net.SGD(training_data, 30, 10, 0.1, test_data=test_data)- 1
结果不是那么好:
Epoch 0: 1139 / 10000
Epoch 1: 1136 / 10000
Epoch 2: 1135 / 10000
...
Epoch 27: 2101 / 10000
Epoch 28: 2123 / 10000
Epoch 29: 2142 / 10000- 1
- 2
- 3
- 4
- 5
- 6
但是,您可以看到网络性能随着时间的推移逐渐变慢。表明提高学习率,比如说η= 0.01。 如果我们这样做,我们会得到更好的结果,这表明再次提高学习率,可以让训练效果更好。如果我们多次这样做,我们最终会得到类似 η=1.0(也许可以微调到3.0)的学习率, 这与我们之前的实验很接近。 因此,尽管我们最初选择的参数很差,但我们至少得到了足够的信息来帮助我们改进特别参数的选择。
通常,调试神经网络可能具有挑战性。当重要参数的初始选择产生的结果不比随机噪声好时,尤其如此。当学习率改为η=100.0:
>>> net = network.Network([784, 30, 10])
>>> net.SGD(training_data, 30, 10, 100.0, test_data=test_data)- 1
如果学习率太高,会出现这样的结果:
Epoch 0: 1009 / 10000
Epoch 1: 1009 / 10000
Epoch 2: 1009 / 10000
Epoch 3: 1009 / 10000
...
Epoch 27: 982 / 10000
Epoch 28: 982 / 10000
Epoch 29: 982 / 10000- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在想象我们第一次遇到这个问题。当然,我们从早期的实验中知道,正确的做法是降低学习率。但是,如果我们第一次遇到这个问题,那么输出中没有太多东西可以指导我们做什么。我们不仅可能担心学习率,还会担心神经网络的其他方面。我们可能想知道我们是否以一种让网络难以学习的方式初始化权重和偏差?或者我们可能没有足够的培训数据来获得有意义的学习?也许我们还没有足够的周期?或者,具有这种架构的神经网络可能无法学会识别手写数字?也许学习率太低了?或者,也许,学习率太高了?当你第一次遇到问题时,你并不总是确定。
从中汲取的教训是,调试神经网络并非易事,而且,正如普通编程一样,它还有一门艺术。您需要学习调试的艺术,以便从神经网络中获得良好的结果。更一般地说,我们需要开发启发式选择良好的特别的参数和良好的架构。我们将通过本书详细讨论所有这些内容,包括我如何选择上面的特别的参数。
尝试创建一个只有两层的网络 - 输入和输出层,没有隐藏层 - 分别有784和10个神经元。 使用随机梯度下降训练网络。 您分类可以达到什么样的准确度呢?
之前,我跳过了有关如何加载 MNIST 数据的详细信息。 这很简单。为了完整性,这是代码。用于存储 MNIST 数据的数据结构在文档字符串中描述 - 它是简单的东西,元组和 Numpy ndarray 对象列表(如果你不熟悉 ndarrays ,可以将它们想象为向量):
""" mnist_loader ~~~~~~~~~~~~ A library to load the MNIST image data. For details of the data structures that are returned, see the doc strings for ``load_data`` and ``load_data_wrapper``. In practice, ``load_data_wrapper`` is the function usually called by our neural network code. """ #### Libraries # Standard library import cPickle import gzip # Third-party libraries import numpy as np def load_data(): """Return the MNIST data as a tuple containing the training data, the validation data, and the test data. The ``training_data`` is returned as a tuple with two entries. The first entry contains the actual training images. This is a numpy ndarray with 50,000 entries. Each entry is, in turn, a numpy ndarray with 784 values, representing the 28 * 28 = 784 pixels in a single MNIST image. The second entry in the ``training_data`` tuple is a numpy ndarray containing 50,000 entries. Those entries are just the digit values (0...9) for the corresponding images contained in the first entry of the tuple. The ``validation_data`` and ``test_data`` are similar, except each contains only 10,000 images. This is a nice data format, but for use in neural networks it's helpful to modify the format of the ``training_data`` a little. That's done in the wrapper function ``load_data_wrapper()``, see below. """ f = gzip.open('../data/mnist.pkl.gz', 'rb') training_data, validation_data, test_data = cPickle.load(f) f.close() return (training_data, validation_data, test_data) def load_data_wrapper(): """Return a tuple containing ``(training_data, validation_data, test_data)``. Based on ``load_data``, but the format is more convenient for use in our implementation of neural networks. In particular, ``training_data`` is a list containing 50,000 2-tuples ``(x, y)``. ``x`` is a 784-dimensional numpy.ndarray containing the input image. ``y`` is a 10-dimensional numpy.ndarray representing the unit vector corresponding to the correct digit for ``x``. ``validation_data`` and ``test_data`` are lists containing 10,000 2-tuples ``(x, y)``. In each case, ``x`` is a 784-dimensional numpy.ndarry containing the input image, and ``y`` is the corresponding classification, i.e., the digit values (integers) corresponding to ``x``. Obviously, this means we're using slightly different formats for the training data and the validation / test data. These formats turn out to be the most convenient for use in our neural network code.""" tr_d, va_d, te_d = load_data() training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]] training_results = [vectorized_result(y) for y in tr_d[1]] training_data = zip(training_inputs, training_results) validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]] validation_data = zip(validation_inputs, va_d[1]) test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]] test_data = zip(test_inputs, te_d[1]) return (training_data, validation_data, test_data) def vectorized_result(j): """Return a 10-dimensional unit vector with a 1.0 in the jth position and zeroes elsewhere. This is used to convert a digit (0...9) into a corresponding desired output from the neural network.""" e = np.zeros((10, 1)) e[j] = 1.0 return e
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
我上面说过我们的程序得到了很好的结果。那是什么意思?一些简单的(非神经网络)基线测试进行比较,了解其表现良好意义,这是有益的。当然,最简单的基线是随机猜测数字。大约百分之十的准确率。神经网络比这个做的更好!
让我们尝试一个非常简单的想法:我们将看看图像的暗度。 例如,2的图像通常比1的图像暗很多,只是因为更多的像素被黑化,如下面的例子所示:
这表明使用训练数据计算每个数字的平均灰度,0,1,2,…,9。当呈现新图像时,我们计算图像的灰度,然后猜测它是具有最接近的平均黑暗的数字。 这是一个简单的过程,并且易于编码,因此我不会明确地编写代码 - 如果您对GitHub存储库感兴趣的话。但它比随机猜测有了很大改进,使10,000个测试图像中的2,225个正确,即准确率为22.25%。
要找到在20到50%范围内达到准确度的其他想法并不难。如果你工作稍微努力,你可以涨到50%以上。 但是为了获得更高的精度,它有助于使用已建立的机器学习算法。让我们尝试使用最著名的算法之一,支持向量机或SVM。如果您不熟悉SVM,不用担心,我们不需要了解SVM如何工作的细节。 相反,我们将使用一个名为scikit-learn的Python库,它为一个快速的基于C的库(称为LIBSVM)提供了一个简单的Python接口。
如果我们使用默认设置运行scikit-learn的 SVM 分类器,那么它将获得9,435个10,000个测试图像。
这是代码链接:
https://github.com/mnielsen/neural-networks-and-deep-learning/blob/master/src/mnist_svm.py
这比我们根据它有多暗对图像进行分类的方法有了很大的改进。 实际上,这意味着SVM的表现与我们的神经网络大致相同,只是稍微差一点。 在后面的章节中,我们将介绍一些新技术,使我们能够改进我们的神经网络,使它们比SVM表现得更好。
然而,这不是故事的结局。10,000个结果中的9,435是scikit-learn的SVM默认设置。SVM具有许多可调参数,并且可以搜索可以改善这种开箱即用性能的参数。我不会明确地进行此搜索,但如果您想了解更多信息,请参阅Andreas Mueller的博客文章。Mueller表示,通过优化SVM参数的一些工作,可以使性能提高98.5%以上。这非常好!神经网络可以做得更好吗?
事实上,他们可以。目前,精心设计的神经网络优于其他解决MNIST的技术,包括SVM。目前(2013年)的记录正确地对10,000张图像中的9,979个进行了分类。这是由Li Wan,Matthew Zeiler,Sixin Zhang,Yann LeCun和Rob Fergus完成的。我们将看到他们在本书后面使用的大多数技术。在那个级别上,性能接近于人类等效,并且可以说是更好的,因为即使人类有信心地识别出相当多的MNIST图像,例如:
我相信你会认为这些数字很难分类!对于MNIST数据集中的这些图像,神奇网络可以准确地对10,000个测试图像中的21个进行分类,这是非常了不起的。 通常,在编程时我们认为解决像识别MNIST数字这样的复杂问题需要复杂的算法。 但是,即使刚刚提到的Wan等人论文中的神经网络也涉及非常简单的算法,我们在本章中看到的算法的变化。 从训练数据中自动学习所有复杂性。 从某种意义上说,我们的结果和更复杂的论文的观点是,对于某些问题:



g、走向深度学习
虽然我们的神经网络提供了令人印象深刻的性能,但这种自动探索网络中的权重和偏差。这意味着我们不会立即解释网络如何做它的功能。 我们能找到一些方法来理解我们的网络对手写数字进行分类的原则吗?而且,鉴于这些原则,我们能做得更好吗?
为了更加明确地提出这些问题,假设几十年后神经网络导致了人工智能(AI)。我们能理解这些智能网络的工作原理吗?也许网络对我们来说是不透明的,我们不了解权重和偏差,因为它们是自动学习的。在人工智能研究的早期阶段,人们希望建立人工智能的努力也有助于我们理解智能背后的原理,也许还有人类大脑的功能。但结果可能是我们最终既不了解大脑,也不了解人工智能是如何工作的!
为了解决这些问题,让我们回想一下我在本章开头给出的人工神经元的解释,作为衡量证据的一种手段。 假设我们想要确定图像是否显示人脸:
我们可以像攻破手写识别一样解决这个问题 - 通过使用图像中的像素作为神经网络的输入,网络输出一个神经元指示“是,它是一张脸”或“不,它是不是一张脸“。
我们假设我们这样做,但我们没有使用学习算法。相反,我们将尝试手动设计网络,选择适当的权重和偏差。我们怎么可能去做呢?暂时忘记神经网络,我们可以使用的启发式方法是将问题分解为子问题:图像是否在左上方有一个眼睛?它右上角有没有眼睛?中间有鼻子吗?底部中间有一个嘴巴吗?顶上有头发吗?等等。
如果其中几个问题的答案是“是”,或者甚至只是“可能是”,那么我们可以得出结论,图像很可能是一张脸。相反,如果大多数问题的答案都是“否”,那么图像可能不是一张脸。
当然,这只是一种粗略的启发式方法,并且存在许多不足之处。也许这个人是秃头,所以他们没有头发。也许我们只能看到脸部的一部分,或者脸部是一个角度,所以一些面部特征会被遮挡。尽管如此,启发式表明,如果我们能够使用神经网络解决子问题,那么也许我们可以通过组合子问题的网络来构建用于面部检测的神经网络。这是一种可能的架构,矩形表示子网络。请注意,这不是解决面部检测问题的现实方法;相反,它是为了帮助我们建立关于网络如何运作的直觉。这是架构:
子网还可也可以进行分解。假设我们正在考虑这个问题:“左上角是否有眼睛?” 这可以分解成如下问题:“有眉毛吗?”; “有睫毛吗?”; “有虹膜吗?”; 等等。 当然,这些问题应该包括位置信息 - “眉毛在左上方,在虹膜上方吗?”,这类事情 - 但让我们选择是或者否的提问。网络回答“左上角有没有眼睛?”的问题,现在可以分解为:


这些问题也可以通过多个层次进一步细分,最终,我们将可以回答这个问题。例如,这些问题可能是关于图像中某些地方是否存在非常简单的形状。这些问题可以通过连接到图像中的原始像素的单个神经元来回答。
最终结果是一个网络解决了一个非常复杂的问题 - 这个图像是否表现出一个面孔 - 这样最终把问题变成一个非常简单的问题。它通过多个隐含层来实现这一点,早期的网络层回答了关于输入图像的非常简单和具体的问题,后来的网络层构建了更复杂和抽象概念的层次结构。具有这种多层结构的网络 - 两个或多个隐藏层 - 被称为深度神经网络。
当然,我还没有说过如何将这种递归分解成子网络。手工设计网络中的权重和偏差当然是不切实际的。相反,我们希望使用学习算法,以便网络可以从训练数据中自动学习权重和偏差 - 从而学习概念的层次结构。 20世纪80年代和90年代的研究人员尝试使用随机梯度下降和反向传播来训练深度网络。虽然网络会学习,但速度非常慢,而导致无法使用。
自2006年以来,已经开发出一套相对成熟的方法,可以在深层神经网络中进行学习。这些深度学习技术基于随机梯度下降和反向传播,但也引入了新的思路。这些技术使得更深(更大)的网络得以训练 - 人们现在经常训练具有5到10个隐藏层的网络。并且,事实证明,这些问题在许多问题上比浅层神经网络(即仅具有单个隐藏层的网络)表现得更好。当然,原因在于深度神经网络能够建立复杂的概念层次。这有点像传统编程语言使用模块化设计和抽象概念来创建复杂的计算机程序。将深层网络与浅层网络进行比较有点像将编程语言与使用精简语言进行函数调用而无法进行此类调用的能力进行比较。抽象在神经网络中采用与传统编程不同的形式,但它同样重要。

三、实践部分——按照书中描述理解并且实现结果
这里使用的环境为 JupyterLab ,然后按照上面的方式导入数据,然后引用这篇博客的学习方式,链接:
https://www.cnblogs.com/jsxyhelu/p/8719196.html然后导入数据的 Python 步骤为,其中这里为安装 keras 库:
!pip install keras -i https://pypi.tuna.tsinghua.edu.cn/simple运行结果为:
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting keras
dDownloading https://pypi.tuna.tsinghua.edu.cn/packages/f8/ba/2d058dcf1b85b9c212cc58264c98a4a7dd92c989b798823cc5690d062bb2/Keras-2.2.5-py2.py3-none-any.whl (336kB)
Requirement already satisfied: h5py in d:\anaconda\lib\site-packages (from keras) (2.9.0)
Requirement already satisfied: keras-applications>=1.0.8 in d:\anaconda\lib\site-packages (from keras) (1.0.8)
Requirement already satisfied: numpy>=1.9.1 in d:\anaconda\lib\site-packages (from keras) (1.16.4)
Requirement already satisfied: six>=1.9.0 in d:\anaconda\lib\site-packages (from keras) (1.12.0)
Requirement already satisfied: scipy>=0.14 in d:\anaconda\lib\site-packages (from keras) (1.2.1)
Requirement already satisfied: keras-preprocessing>=1.1.0 in d:\anaconda\lib\site-packages (from keras) (1.1.0)
Requirement already satisfied: pyyaml in d:\anaconda\lib\site-packages (from keras) (5.1.1)
Installing collected packages: keras
Successfully installed keras-2.2.5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
下载和加载数据:
from keras.utils.data_utils import get_file
path='mnist.npz'
path = get_file(path,origin='https://s3.amazonaws.com/img-datasets/mnist.npz',file_hash='8a61469f7ea1b51cbae51d4f78837e45')
print(path)
#打开Mnist数据
def load_data():
path='mnist2.pkl.gz'
path = get_file(path,origin='https://github.com/mnielsen/neural-networks-and-deep-learning/raw/master/data/mnist.pkl.gz')
print(path)
f = gzip.open(path, 'rb')
training_data, validation_data, test_data = pickle.load(f, encoding="latin1")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行结果为:
Using TensorFlow backend.
C:\Users\10101\.keras\datasets\mnist.npz- 1
网络生成及其相关函数定义:
# %load D:/dl4cv/GoNetwork/GoNetwork.py # %load network.py """ network.py ~~~~~~~~~~ IT WORKS A module to implement the stochastic gradient descent learning algorithm for a feedforward neural network. Gradients are calculated using backpropagation. Note that I have focused on making the code simple, easily readable, and easily modifiable. It is not optimized, and omits many desirable features. jsxyhelu添加了适当的中文注释 """ #### Libraries # Standard library import random # Third-party libraries import numpy as np class GoNetwork(object): def __init__(self, sizes): """size代表的是网络的分层结构,比如[2, 3, 1] The list ``sizes`` contains the number of neurons in the respective layers of the network. For example, if the list was [2, 3, 1] then it would be a three-layer network, with the first layer containing 2 neurons, the second layer 3 neurons, and the third layer 1 neuron. The biases and weights for the network are initialized randomly, using a Gaussian distribution with mean 0, and variance 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers.""" self.num_layers = len(sizes) #层数 self.sizes = sizes #每层size self.biases = [np.random.randn(y, 1) for y in sizes[1:]] #随机生成子节点 # net.weights[1] 是⼀个存储着连接第⼆层和第三层神经元权重的 Numpy 矩阵。 self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])] #前向网络,主要用于测试当前网络 def feedforward(self, a): """Return the output of the network if ``a`` is input.""" for b, w in zip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b) return a #随机梯度下降算法 def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None): """Train the neural network using mini-batch stochastic gradient descent. The ``training_data`` is a list of tuples ``(x, y)`` representing the training inputs and the desired outputs. The other non-optional parameters are self-explanatory. If ``test_data`` is provided then the network will be evaluated against the test data after each epoch, and partial progress printed out. This is useful for tracking progress, but slows things down substantially.""" training_data = list(training_data) n = len(training_data) if test_data: test_data = list(test_data) n_test = len(test_data) #⾸先随机地将训练数据打乱 for j in range(epochs): random.shuffle(training_data) #再将它分成多个适当⼤⼩的⼩批量数据 mini_batches = [ training_data[k:k+mini_batch_size] for k in range(0, n, mini_batch_size)] #最主要的一行代码 for mini_batch in mini_batches: self.update_mini_batch(mini_batch, eta) if test_data: print("Epoch {} : {} / {}".format(j,self.evaluate(test_data),n_test)) else: print("Epoch {} complete".format(j)) #根据单次梯度下降的迭代更新⽹络的权重和偏置 def update_mini_batch(self, mini_batch, eta): """Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch. The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta`` is the learning rate.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)] #反向传播就是一种快速计算代价函数梯度的方法,也就是计算delta的一种方法 def backprop(self, x, y): """Return a tuple ``(nabla_b, nabla_w)`` representing the gradient for the cost function C_x. ``nabla_b`` and ``nabla_w`` are layer-by-layer lists of numpy arrays, similar to ``self.biases`` and ``self.weights``.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w in zip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass delta = self.cost_derivative(activations[-1], y) * sigmoid_prime(zs[-1]) #bp1 nabla_b[-1] = delta #bp3 nabla_w[-1] = np.dot(delta, activations[-2].transpose()) #bp4 # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. for l in range(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp #bp2,注意这里的+1,其实是计算了下一层了 nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w) #evaluate评价函数 def evaluate(self, test_data): """Return the number of test inputs for which the neural network outputs the correct result. Note that the neural network's output is assumed to be the index of whichever neuron in the final layer has the highest activation.""" test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data] return sum(int(x == y) for (x, y) in test_results) #cost代价函数 def cost_derivative(self, output_activations, y): """Return the vector of partial derivatives \partial C_x / \partial a for the output activations.""" return (output_activations-y) #########helper函数######## #计算sigmoid,这个函数来自定义 def sigmoid(z): """The sigmoid function.""" return 1.0/(1.0+np.exp(-z)) #计算sigmoid的导数,这个函数可以被证明 def sigmoid_prime(z): """Derivative of the sigmoid function.""" return sigmoid(z)*(1-sigmoid(z))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
然后导入数据和对数据进行处理的代码:
''' GoDateSets: GreenOpen 系列 引入数据集 by:jsxyhelu 2018/3/31 ''' import pickle import gzip import numpy as np from keras.utils.data_utils import get_file #打开Mnist数据 def load_data(): path='mnist2.pkl.gz' path = get_file(path,origin='https://github.com/mnielsen/neural-networks-and-deep-learning/raw/master/data/mnist.pkl.gz') print(path) f = gzip.open(path, 'rb') training_data, validation_data, test_data = pickle.load(f, encoding="latin1") f.close() return (training_data, validation_data, test_data) #对读取的数据进行重新封装 def load_data_wrapper(): tr_d, va_d, te_d = load_data() training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]] training_results = [vectorized_result(y) for y in tr_d[1]] training_data = zip(training_inputs, training_results) validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]] validation_data = zip(validation_inputs, va_d[1]) test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]] test_data = zip(test_inputs, te_d[1]) return (training_data, validation_data, test_data) #返回OneHot图 def vectorized_result(j): e = np.zeros((10, 1)) e[j] = 1.0 return e
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
在以上都准备完成的条件下,接下来执行下面的语句,就可以训练神经网络:
import numpy as np
import random
training_data, validation_data, test_data = load_data_wrapper()
training_data = list(training_data)
net = GoNetwork([784, 30, 10])
net.SGD(training_data, 30, 10, 3.0, test_data=test_data)- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后出现这样的运行结果:
Downloading data from https://github.com/mnielsen/neural-networks-and-deep-learning/raw/master/data/mnist.pkl.gz 17055744/17051982 [==============================] - 6s 0us/step C:\Users\10101\.keras\datasets\mnist2.pkl.gz Epoch 0 : 9087 / 10000 Epoch 1 : 9235 / 10000 Epoch 2 : 9325 / 10000 Epoch 3 : 9306 / 10000 Epoch 4 : 9388 / 10000 Epoch 5 : 9409 / 10000 Epoch 6 : 9441 / 10000 Epoch 7 : 9418 / 10000 Epoch 8 : 9432 / 10000 Epoch 9 : 9449 / 10000 Epoch 10 : 9456 / 10000 Epoch 11 : 9460 / 10000 Epoch 12 : 9467 / 10000 Epoch 13 : 9450 / 10000 Epoch 14 : 9458 / 10000 Epoch 15 : 9456 / 10000 Epoch 16 : 9501 / 10000 Epoch 17 : 9460 / 10000 Epoch 18 : 9497 / 10000 Epoch 19 : 9512 / 10000 Epoch 20 : 9482 / 10000 Epoch 21 : 9501 / 10000 Epoch 22 : 9489 / 10000 Epoch 23 : 9490 / 10000 Epoch 24 : 9524 / 10000 Epoch 25 : 9520 / 10000 Epoch 26 : 9508 / 10000 Epoch 27 : 9513 / 10000 Epoch 28 : 9495 / 10000 Epoch 29 : 9498 / 10000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这样,通过对原文的理解和通过网络上学习别人的理解,了解了BP神经网络的构成及其原理,并对程序进行了理解。

