
- 1RabbitMQ异步与重试机制_rabbitmq 重试机制测试
- 2四种经典限流算法的实现思路以及各自的优缺点_java的限流实现的各种优缺点
- 3Flink 实践教程-入门(10):Python作业的使用_flink python
- 4C语言学生选课系统实现_学生选修课程系统设计c语言代码
- 5边缘计算加持下的智慧社区_智慧社区边缘计算
- 6Anaconda环境下安装 opencv_annocoda opencv
- 7思科实验9.网络层:PPP协议配置_思科ppp协议
- 8论文Word问题02:EndNoteX9_插入引用参考文献_endnotex9怎么引用参考文献
- 9zookeeper总结
- 10Mobile ALOHA 的模仿学习算法和协同训练--翻译斯坦福机器人项目1_mobile-aloha联合训练
NLP竞赛全球亚军,我的科研经验分享
赞
踩

去年五一,我正在洛阳旅行,本已收到了腾讯公司的offer,准备假期过后去实习。这时候导师突然来了电话,让我6月份回实验室做科研。
一瞬间我觉得自己好悲惨,大厂实习泡汤了,研究生最后一段自由时光也成了泡影。
科研的主题是Text2SQL,就是把一句话翻译成对应的SQL语句。这是我毕业的开题方向,当初对NLP这个朝阳领域很感兴趣,有几个不错的idea。可我也就止步于此,没尝试过代码实现,看的论文不到10篇,处境很尴尬。
放弃了实习的念头,我在6月底重回实验室后,经历半年多我终于对Text2SQL领域有了清晰的认识。完成毕业论文的同时,产出了paper和专利,并在10月份获得了耶鲁大学Text2SQL比赛的全球第二名。
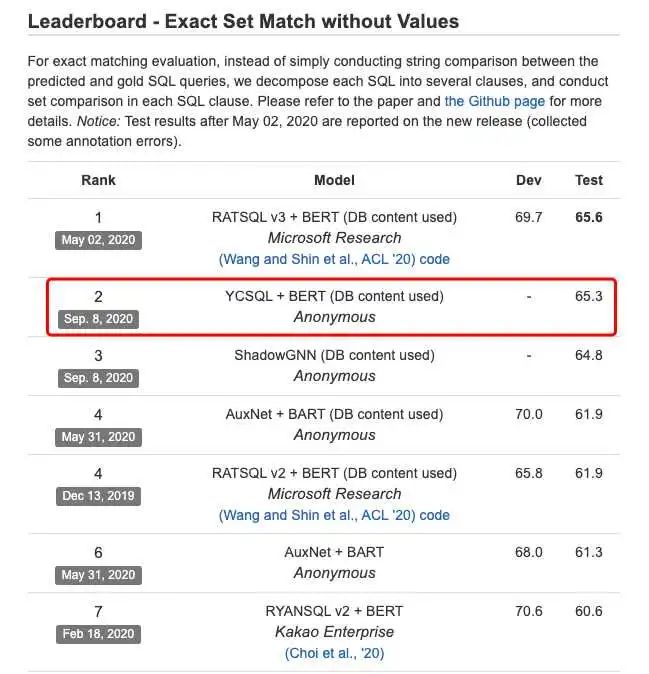
从开始的懵懂、工程能力不足到最终收获了还不错的结果,我对这半年多经历用了3个方面来概括:
1.阅读领域内近3-5年顶会论文
2.站在巨人的肩膀上,强化工程能力
3.充分利用学校和实验室资源
一、阅读领域内近3-5年顶会论文
阅读已有工作是开展科研的必经之路,既是为了站在一个制高点饱览研究领域这块蛋糕,也是为了提升学术嗅觉与idea能力。同时,可以避免想出了一个很好的idea立即开始复现,结果提交论文时才发现,这个点早就被别人做掉了的极端现象。
高效收集paper的4个途径:
1)在研究领域的公开赛事或榜单上学习Top名次的解决方案(一般都有相应的论文链接)。比如Text2SQL领域有:WikiSQL、TableQA、Spider、CoSQL等比赛,里边有大量值得学习的paper。
2)收集2-3篇综述论文。一篇好的综述概括了该领域的整体进展、已有工作以及潜在的研究方向等等,能够给予我们启发,事半功倍。
3)在谷歌学术上通过关键词搜索相关论文。论文质量可以根据引用数量、会议等级来衡量。
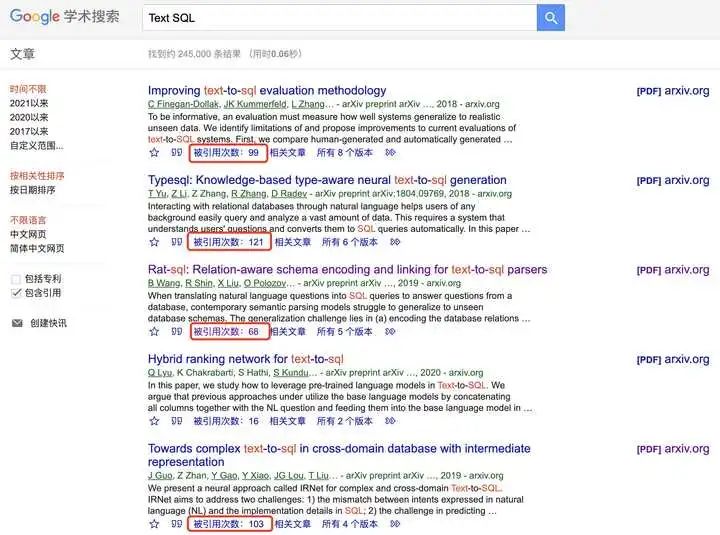
点击某一篇文章的“被引用次数”链接,可以跳转进入引用了这篇论文的界面,继续寻找有价值的论文。很多论文其实没有精读的必要,我们在收集了一批论文后,不妨先读读摘要、实验、结论部分,再确定是否需要通篇精读,以提高效率。

当然一些经典的paper是一定要看的,比如做NLP肯定不能错过Transformer、BERT等等。
4)在Github上搜索资源整合项目。如果这个领域比较热门或者正处于上升期,一般都会有热心用户分享自己整理的资料。例如,关于Text2SQL我已经整理好了一份大礼包,包含了背景、论文、数据集、解决方案、应用案例等内容,帮助感兴趣的小伙伴们节省时间:
https://github.com/yechens/NL2SQL
二、站在巨人的肩膀上,强化工程能力
有了学术积累和idea后,就需要快速复现idea。刚开始我有一个误区:科研一定要从0做到1。
后来导师告诉我大可不必这样。聪明的人会先参考别人的解决方案(特别是SOTA),在学习过程中强化工程和coding水平,形成更优雅的代码风格。这就像站在巨人的肩膀上,我可以基于他们的工作实现自己的想法,取其精华,去其糟粕。
还是以Text2SQL为例。这个任务的数据处理部分特别繁琐,需要同时考虑文本和数据库信息,仅预处理就包含了上千行代码。我参考了Spider上的Top方案后,发现大家在这部分有很多思路是共通的,完全可以借鉴。这样一来,我可以把更多精力放在模型结构设计和后处理上,这两者对最终结果有关键影响。
有的同学表示说,“自己之前没有太多接触神经网络,现在要改实验代码,觉得好难”,这就涉及基本功问题了。我们每天需要额外挤时间来补漏洞,提升自己的coding能力。
如果喜欢看书,我推荐Keras之父的《Python深度学习》和李沐老师的《动手学深度学习》。两本书我都认真看过,非常经典和通俗易懂。
三、充分利用学校和实验室资源
最后一个关键是学会充分利用现有资源,这个资源包括学术资源、人力资源、硬件资源。
学术资源
最直接的学术资源就是实验室的师兄师姐们,还有大Boss——导师。
师兄中肯定有人发过paper,无论是写作还是关于编程和技巧,和他们聊过之后都给我带来了启发。导师是我研究领域中的权威人物,可以帮助我把关idea是否work、是否有足够的竞争力,甚至在没有任何思路的时候点醒我,提供有价值的idea。
人力资源
导师精力有限,往往神龙见首不见尾,不可能顾及所有人,所以带领学弟学妹们的工作一般留给了高年级同学。如果研究的方向他们也感兴趣,大家完全可以一起合作。例如让coding能力强的师弟帮忙做一些实验,coding弱些的同学分析数据和badcase,便于我迭代模型。不仅让他们有所收获,也帮助我分担了很多工作量,一举多得。
如果能带学弟学妹们投中论文,我想他们一定会从心里发出感激的,没准也更愿意在今后的工作中加上我的名字。
硬件资源
俗话说巧妇难为无米之炊,做科研有了idea和coding能力,没有机器也还是白搭。所以无论是在实验室还是公司,要善于利用资源。
我在实验室时,老板很慷慨的采购了服务器,还有Tesla V100显卡让我们做实验。实验室24h可以进出,提供免费饮用水和咖啡。如果做出了成绩(比如会议中稿,比赛拿下SOTA)会有丰厚的物质奖励。
如果实验室没有这些硬件资源,应该主动和老板沟通,请他帮忙协助解决。
总结
路漫漫其修远兮,吾将上下而求索。
做科研是一条艰辛的路,特别是从0到1的过程。但是通向光明之路,从来没有一帆风顺的选择。
为了避免拖延症和摸鱼,我会给自己罗列各个阶段的deadline,然后从学术调研、coding实验、多次迭代方面进行攻坚。如果真的感觉很累,我会停下来离开实验室,去球场和朋友打球;或者跑跑步,呼吸新鲜空气,让自己清醒放松。
最后推荐几个深度学习方向科研工作的神器吧,希望能为同学们的科研道路提供帮助:
arxiv:论文收录网站(防止自己的idea被剽窃,完成论文后可以先挂上去,证明原创性);
PaperwithCode:论文和代码的结合工具,包含了很多NLP、CV方向的SOTA论文和模型实现;
dblp:计算机英文资料收集网站,支持各种字段搜索(会议、作者、时间等);
Connected Paper:论文引用信息可视化工具,分析出文献的前世今生;
NLPIndex:NLP学术搜索神器,同时链接了paper、code、graph,是上述上个神器的综合体;
Deepl:翻译神器,特点是地道,更接近真人翻译(略胜于谷歌翻译)
diagrams:画图好帮手,制作高大上的流程图、模型图必备,可以在线导出为pdf高清矢量图(放大后图片细节不失真)
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)

- END -



2021年机器学习什么风向?谷歌大神Quoc Le:把注意力放在MLP上






