
- 1机器人开发--pgv 视觉引导(Position Guided Vision)
- 2台积电稳坐全球晶圆代工第一!
- 3vuecli3代码压缩混淆
- 4san.js源码解读之工具(util)篇——数据校验_js 验证util
- 5在unity中点击三维物体,显示它的名字_unity扫描出物体后出现信息
- 6110道 Elasticsearch面试题及答案(持续更新)_elecsearch面试题
- 7Redis过期回调_error org.springframework.data.redis.listener.redi
- 8poj 3667 线段树-区间的前缀和后缀_在前缀和上的线段树
- 9HashMap和HashSet的区别和分析
- 10TensorFlow、pytorch和python对应的版本关系_pytorch cpu 和gpu版本对应
ClickHouse介绍及安装(含集群方式)和使用_click house
赞
踩
目录
- 1 概述
- 2 架构概述
- 3 ClickHouse 引擎
- 4 数据类型
- 5 安装部署
- 6 客户端工具
- 6.1 clickhouse-client
- 6.2 DBeaver
- 6.3 JDBC
- 6.4 clickhouse-local
- 7 MySQL 及 ClickHouse 的 MySQL 引擎使用
- 8 一个示例
- 9 数据的导入导出
- 10 Movie 数据分析
- 11 ClickHouse-China/ClickhouseMeetup
1 概述
ClickHouse是俄罗斯的Yandex公司(名字来一种说法是源于Yet Another Indexer)于2016年开源的用于联机分析(OLAP)的面向列的数据库管理系统(DBMS),它也是一款 MPP(Massively Parallel Processing) 架构的列式存储数据库,它能够使用SQL查询实时生成分析数据报告。
ClickHouse 的初始设计目标是为自己公司内部的 Yandex.Metrica 产品提供服务支持。这个产品会全方位的对Web进行分析,使用户可以从流量趋势到鼠标移动等做到全面了解用户的在线受众并推动其业务的增长,整个分析类似于 OLAP 分析,在数据采集过程中,每次页面点击 click 都会产生一个事件流,在分析中也就是基于页面的点击事件流用面向数仓进行 OLAP 分析,用英文可以描述为 Click Stream, Data WareHouse,简称为 ClickHouse。
通过 ClickHouse 对数据的处理,可以让用户的思考决策更快:(1) 在相同的时间内运行更多查询;(2) 测试更多的预想;(3) 以更多新方式对;(4) 数据进行切片和切块;(5) 从新角度看待你的数据;(6) 发现新维度。
什么时候使用 ClickHouse呢?当需要分析或清洗结构化的且不可变的事件或日志类数据时可以使用,并且建议将每个此类流放入具有预先连接(pre-joined)维度的单个宽事实表中,因为对 SQL 有较好的支持也非常适合于商业智能领域(BI 领域)。具体到一些可行的应用程序示例如:(1) 网络和应用分析;(2) 广告网络和实时出价;(3) 电信;(4) 电子商务和金融;(5) 信息安全;(6) 监控和遥测;(7) 时间序列;(8) 商业情报;(9) 线上游戏;(10) 物联网。
ClickHouse不适用的场景。ClickHouse虽然是一个非常优秀的 OLAP 数据库,但是也不是所有场景都适用,例如:(1) 事务性工作负载(OLTP);(2) 高请求率的键值访问;(3) Blob或文档存储;(4) 标准化数据;(5) 不擅长按行删除数据,虽然支持。
ClickHouse的特点
- 非常燃的速度(Blazing Fast):ClickHouse的性能超过了目前市场上可对比的面向列的DBMS。每秒钟每台服务器每秒处理数亿至十亿多行和数十千兆字节的数据。ClickHouse会充分利用所有可用的硬件,以尽可能快地处理每个查询。单个查询(解压缩后、仅使用的列)的峰值处理性能超过每秒2 TB。ClickHouse的工作速度比传统方法快100-1000倍。与常见的数据管理方法不同,在常规方法中,大量原始格式的原始数据可作为任何给定查询的“数据湖”(data lake),而ClickHouse在大多数情况下可提供即时结果,处理数据的速度比创建数据的速度更快。
- 线性可扩展(Linearly Scalable):ClickHouse允许公司在必要时将服务器添加到群集中,而无需花费时间或金钱进行任何其他DBMS修改。该系统已成功为Yandex.Metrica提供服务,而其主要生产集群中的服务器数量在两年内已从60台增加到394台,这些服务器位于六个地理分布的数据中心内,ClickHouse可以在垂直和水平方向上很好地缩放。ClickHouse易于调整以在具有数百个节点的群集上,在单个服务器上甚至在小型虚拟机上执行。当前每个节点的安装量超过2万亿行,每个节点的存储量为100Tb。
- 硬件效率高(Hardware Efficient):与具有相同可用 I/O 吞吐量的传统的面向行的系统相比,ClickHouse处理典型的分析查询要快两到三个数量级。系统的列式存储格式允许将更多热数据放入RAM中,从而缩短了响应时间。ClickHouse可以最大程度地减少范围查询的次数,从而提高了使用旋转磁盘驱动器的效率,因为它可以保持连续存储数据的参考位置。由于ClickHouse的矢量化查询执行涉及相关的处理器指令和运行时代码生成,因此它具有CPU效率。通过最大限度地减少大多数查询类型的数据传输,ClickHouse使公司无需使用专门针对高性能计算的专用网络即可管理其数据并创建报告。
- 容错(Fault Tolerant):ClickHouse支持多主机异步复制,并且可以跨多个数据中心进行部署。单个节点或整个数据中心的停机时间不会影响系统的读写可用性。分布式读取将自动与活动副本保持平衡,以避免增加延迟。服务器停机后,复制的数据将自动或半自动同步。
- 功能丰富(Feature Rich):ClickHouse具有用户友好的SQL查询方言,具有许多内置分析功能,例如它包括概率数据结构,用于快速和有效存储基数和分位数的计算。有用于工作日期、时间和时区的功能,以及一些专门的功能,例如寻址URL和IP(IPv4和IPv6)以及更多功能。ClickHouse中可用的数据组织选项,例如数组、数组联接、元组和嵌套数据结构,对于管理非规范化数据非常有效。由于系统支持本地联接和分布式联接,因此使用ClickHouse可以联接分布式数据或位于同一地点的数据。它还提供了使用外部词典(从外部源加载的维度表)进行简单语法无缝连接的机会(例如MySQL)。ClickHouse支持近似查询处理–您可以根据需要快速获得结果,这在处理TB级和PB级数据时必不可少。系统的条件汇总函数,总计和极值的计算,使我们可以通过一次查询获得结果,而不必运行多个查询。
- 高度可靠(Highly Reliable):ClickHouse一直在管理PB级数据,这些数据为俄罗斯领先的搜索提供商,欧洲最大的IT公司之一Yandex的大量高负载大众受众服务提供服务。自2012年以来,ClickHouse一直为公司的网络分析服务,比较电子商务平台,公共电子邮件服务,在线广告平台,商业智能工具和基础架构监视提供强大的数据库管理。ClickHouse可以配置为位于独立节点上的纯分布式系统,而没有任何单点故障。软件和硬件故障或配置错误不会导致数据丢失。ClickHouse不会删除“损坏的”数据,而是将其保存或询问您在启动前该怎么做。每次对磁盘或网络进行读取或写入之前,所有数据均经过校验和。几乎不可能偶然删除数据,因为即使存在人为错误,也有保护措施。ClickHouse提供了对查询复杂性和资源使用情况的灵活限制,可以通过设置对其进行微调。可以同时为多个高优先级低延迟请求和一些具有后台优先级的长时间运行的查询提供服务。
- 简单方便(Simple and Handy):ClickHouse简化了所有数据处理,它易于使用,将所有结构化数据提取到系统中,并可立即用于报告。可以随时轻松将用于新属性或维度的新列添加到系统中,而不会降低系统运行速度。ClickHouse简单易用,开箱即用。除了在数百个节点群集上执行之外,该系统还可以轻松地安装在单个服务器甚至虚拟机上。安装ClickHouse不需要任何开发经验或代码编写技能。
2 架构概述
ClickHouse 是一个真正的列式数据库管理系统(DBMS)。在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。只要有可能,操作都是基于矢量进行分派的,而不是单个的值,这被称为“矢量化查询执行”,它有利于降低实际的数据处理开销。
通常有两种不同的加速查询处理的方法:矢量(向量)化查询执行(vectorized query execution)和运行时代码生成(runtime code generation)。在后者中,动态地为每一类查询生成代码,消除了间接分派和动态分派。这两种方法中,并没有哪一种严格地比另一种好。运行时代码生成可以更好地将多个操作融合在一起,从而充分利用 CPU 执行单元和流水线。矢量化查询执行不是特别实用,因为它涉及必须写到缓存并读回的临时向量。如果 L2 缓存容纳不下临时数据,那么这将成为一个问题。但矢量化查询执行更容易利用 CPU 的 SIMD 功能(Single Instruction Multiple Data,单指令多数据流)。关于将两种方法结合起来的更好选择的研究可以查看论文 Vectorization vs. Compilation in Query Execution。使用了矢量化查询执行,同时初步提供了有限的运行时动态代码生成。
关于ClickHouse架构的了解,需要我们理解如下17个概念:列(Columns)、字段(Field)、Leaky Abstractions、数据类型(Data Types)、块(Block)、块流(Block Streams)、格式(Formats)、I/O、表(Tables)、解析器(Parsers)、解释器(Interpreters)、函数(Functions)、聚合函数(Aggregate Functions)、服务(Server)、分布式查询执行(Distributed Query Execution)、合并树(Merge Tree)、副本(Replication)。关于其详细的解释推荐查看官网引文版文档 Overview of ClickHouse Architecture。
Columns 和 Field 是 ClickHouse 数据最基础的映射单元,ClickHouse 在内存中的一列数据由 Columns 表示,Columns 在源码层面可分为接口和实现向部分。在大多数场合,ClickHouse 都会以整列的方式操作数据,但有时如果需要操作单个具体的数据,此时就需要使用 Field 对象了,Field对象代表一个单值。
ClickHouse 中的数据序列化和反序列化主要由 DataType 负责,在源码中 IDataTypes接口定义了许多正反序列化的方法,涵盖了常用的二进制、文本、JSON、XML、CSV 、Protobuf 等多种格式类型。虽然这里提到 DataType 主要负责数据的序列化相关的工作,但是它并不直接负责数据的读取,数据读取而是转由 Column 或 Field 对象获取的。
在 ClickHouse 中虽然 Columns 和 Field 组成了数据的基本单元,但是对应的实际的操作中还缺少一些必要的信息,比如数据的类型和列名等,因此 ClickHouse 设计了 Block 对象,Block 对象可以看做数据表的子集,本质上其由 数据对象、数据类型和列名组成的三元组,即 Columns、DataType、列名称字符串。这样在操作数据时,Columns 提供了数据的读取能力,DataType告诉操作如何序列化和反序列。
因为 ClickHouse 内部的数据操作是一种流的形式,有了 Block 对象,对 Block Streams 的设计就水到渠成了,在源码层面流的操作由两组顶层接口:IBlockInputStream 和 IBlockOutputStream,前者负责数据的读取和关系运算,后者负责将数据输出到下一环节中。
Table 在 ClickHouse 底层设计时表现为 IStorage 接口,同时又提供了多种的表引擎,IStorage 接口定义了 DDL(ALTER、DROP、RENAME、OPTIMIZE等)、read 和 write 方法,它们分别负责数据的定义、查询和写入。
Parser 和 Interpreter 也是两个非常重要的接口,Parser 分析器负责创建 AST(Abstract Syntax Tree)对象,Interpreter 解释器负责解释 AST,并进一步创建查询的执行管道。它与前面说的 IStorage 接口一起串联起了整个数据查询的过程。
ClickHouse 主要提供了两类函数:普通函数(Functions)、聚合函数(Aggregate Functions)。普通函数有接口 IFunction 定义。聚合函数由接口 IAggregateFunction 定义,相比无状态的普通函数,聚合函数是有状态的。
ClickHouse 集群由分片(Shard)组成,每一个分片式通过副本(Replica)组成。ClickHouse 的一个节点只能拥有一个分片,分片是一个逻辑概念,其物理实现由副本承担。例如我们想实现1个分片1 副本,则就需要连个节点,因为 1 个节点只能实现 1 分片(0 副本)。
3 ClickHouse 引擎
熟悉 MySQL 的同学可能有中熟悉的感觉,在MySQL 中执行 SHOW ENGINES 可以看到当前数据库支持的引擎
mysql> SHOW ENGINES;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.03 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
ClickHouse也有类似的设计,ClickHouse 的引擎包括两部分,库引擎和表引擎。
3.1 库引擎
ClickHouse 的建库语句如下:
CREATE DATABASE IF NOT EXISTS db_name [ENGINE = engine]
- 1
数据库引擎主要分为 5 种:
- Ordinary:默认引擎,使用时无需在建库时刻意声明,在此数据库下的表可以使用任意的类型的表引擎
- Dictionary:字典引擎,此类数据库会自动为所有数据字典创建它们的数据表(加载配置文件中配置的字段表信息和数据)
- Memory:内存引擎,用户存放临时数据,数据只会在内存中,不会涉及任何磁盘操作,当服务重启后数据会清空。
- MySQL: MySQL 引擎,会自动拉取远端 MySQL 中的数据,并在该库下创建 MySQL 表引擎的数据表。
- Lazy:日志引起,在该数据库下只能创建 log 系列引擎的表
3.2 表引擎
ClickHouse 有着多样化的表引擎,它将存储部分进行了抽象,把存储引擎作为一层独立的接口,目前大体上有6 大类接口:合并树、外部存储、内存、日志、接口、其它类型,具体的表引擎如下
-
MergeTree系列
- 基础能力
- MergeTree:合并树家族中最基础的表引擎,提供了数据分区、一级索引、二级索引功能,支持列级别 TTL 和表级别 TTL,支持多路径存储策略。适用于高负载任务的最通用和功能最强大的表引擎。这些引擎的共同特点是可以快速插入数据并进行后续的后台数据处理。
- ReplacingMergeTree:MergeTree 引擎有主键但是没有主键唯一的约束,也就是当写入多行主键一样的数据时也能正常写入,这样会存在重复数据,为解决这个问题,产生了 ReplacingMergeTree 表引擎,它可以在合并分区时删除重复的数据(注意是以分区为单位删除重复数据的)。
- SummingMergeTree:它可以在合并分区时按照预先定义的条件聚合汇总数据,将同一分组(
ORDER BY指定的字段)下的多行数据汇总合并成一行(在汇总字段中执行 SUM ,不在是选取同组内第一行的数据),这样既可以减少数据行,也能降低后期汇总查询的开销。 - AggregatingMergeTree:在合并分区时按照预先定义的条件聚合数据,有点类似于数据立方体的意思,从这里可以看到 AggregatingMergeTree 是 SummingMergeTree 的升级版。它需要借助 AggregateFunction 定义某个的字段的聚合方式及数据类型,
- CollapsingMergeTree:在面对海量数据的大数据领域,一般修改和删除数据的代价都比较大,但某些业务场景下有需要修改和删除某些数据,在 MergeTree 引擎系列中为了高效实现对数据的删除和修改便出现了这个引擎,它通过以增代删的思路支持了行级数据的修改和删除。它通过 sign 标记字段记录数据行的状态,如果 sign=1表示这是一行有效的数据,如果 sign=-1 则表示数据是需要被删除的,当分区合并时,同一数据分区内 sign 标记为 1 和 -1 的一组数据会被相互抵消,这种相互抵消的过程就像折纸一样,可能也是折叠合并树名字的由来。
- VersionedCollapsingMergeTree:从名字看它是在 CollapsingMergeTree 基础上添加了 Versioned(版本)。从介绍上一个引擎中可以看到在合并时其实是由顺序要求的,正常顺序为先有 sign=1 的数据,后有 sign=-1 的状态的数据,但是如果处理的数据量很大,数据的写入通常是多线程执行的,这个时候就不能保证数据写入的顺序,这时 CollapsingMergeTree 引擎就会出现不可预知的问题,未解决这个问题,出现了 VersionedCollapsingMergeTree 引擎,正如其名,解决办法是通过添加版本来保合并分区数据时sign 无序的问题,
VersionedCollapsingMergeTree(sign, version),第二个参数同一行数据可以指定相同的标识来作为版本。
- 副本能力。合并树引擎名字添加
Replicated前缀后,便在原来的基础的拥有了副本(意味着主副本的数据可以备份到其它节点)能力的支持,但想拥有这个能力需要依赖 ZooKeeper 了。- ReplicatedMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedSummingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergeTree
- 基础能力
-
日志类型。当数据量很小(100W一下)又主要是一些简单查询类的场景,并且是一次写入多次频繁查询时,使用日志家族系的引擎是一个不错的选择。
-
外部存储类型
- Kafka:它可以直接与 Kafka 集群对接,并进行数据的订阅,实时接收查询数据。在默认情况下 Kafka 表引擎会每隔 500 毫秒(由 stream_poll_timeout_ms参数决定,默认为 500 )拉取一次数据,
- MySQL:可以与 MySQL 数据库中的数据表建立映射,并通过 SQL 向MySQL 数据库发起远程查询(包括 SELECT、INSERT),目前 MySQL 表引擎不支持任何 UPDATA 和 DELETE 操作,如果有更新方面的需求,可以考虑使用 CollapsingMergeTree 作为视图的表引擎。
- JDBC:相比于 MySQL 表引擎,JDBC 表引擎还可以连接 H2 (in-memory)、SQLite、MySQL、PostgreSQL,但是想使用这个引擎需要依赖于
clickhouse-jdbc-bridge 项目,它主要是为 ClickHouse 提供一个代理访问其它数据库的功能,并自动转换为 ClickHouse 与 JDBC 之间对应的数据格式。下载源码使用 maven 编译mvn clean package之后得到target/jdbc.bridge-1.0.jar的 jar 包,然后启动代理服务,执行这个查看帮助java -jar jdbc.bridge-1.0.jar --help。 - HDFS:
ENGINE = HDFS(URI, format),uri 为 hdfs 的路径,format格式,常见的有 CSV、TSV、JSON等。 - File:File表引擎可以直接读取本地文件的数据,数据保存的路径由 config.xml文件中配置指定。
-
内存类型
- Memory:直接将数据存储到内存中,数据既不会压缩,也不会被格式转换,数据在内存中保存到形态与查询是看到的一样,同时它也不会写出到磁盘,当 ClickHouse 服务重启时,Memory表内的数据会丢失。
- Set:相比于 Memory 表引擎,Set 表引擎拥有自己的物理存储,数据首先会被写入到内存,然后被同步到磁盘文件中,索引当 ClickHouse 服务重启后数据不会丢失,当数据表被重新装载时,磁盘上的文件数据会被全量加载内存,Set 表引擎具有去重的能力,在数据写入过程中,重复的数据将会自动忽略。
- Join:Join表引擎主要是为了 JOIN 查询而生,在 Join 表引擎的底层实现中,它与 Set 表引擎公用了大部分的处理逻辑,所以 Join 和 Set 表引擎拥有很多相似之处。
- Buffer:与 Memory 表引擎类似,Buffer 表引擎也是直接将数据装载到内存中,也不支持将数据持久化到磁盘,ClickHouse 服务重启后数据也会丢失,但是 Buffer 表引擎主要不是面向查询场景而设计的,它的最主要的作用的充当一个缓冲区的角色,例如,现在需要将一批数据写入 MergeTree 引擎的表 A,当并发数很高时,很可能发生 MergeTree 表 A 的合并速度慢于写入的速度,为了缓解这个问题,可以中间引入 Buffer 表做为缓冲区,首先将数据写入 Buffer 表,当满足创建 Buffer 表时预设的条件时会自动将数据写入目标表。
-
接口类型
- Merge:它本身不存储数据,它的主要作用是很冰多个查询的结果集。被代理查询的数据表被要求处于同一个数据库内,且拥有相同的表结构。
- Dictionary:它是数据字典表引擎的一层代理,可以取代字典函数,可以让用户通过数据表的形式查询字典。
- Distributed:Distributed 自身也不存任何数据,它可以为分布式表提供一层透明代理,在集群内部自动进行数据的写入分发以及查询路由工作。
-
其它类型
- Null:与 MySQL 的 BLACKHOLE 引擎类似,用户向 Null 引擎的表写入数据,系统会正确返回但是会被自动忽略掉,永远不会将它保存,如果用户查询这张表,则永远都是一张空表。它有什么用呢?例如当我们使用物化视图时,不需要保留源表的数据,这个源表的数据可以使用 Null 引擎,这样当源表数据被写入新数据时,虽然源表永远为空,但是会同步到物化视图表,查询物化视图可以正常查询到数据。
- URL:类似于 HTTP 客户端,可以通过 HTTP 或 HTTPS 协议,访问 REST 接口服务,当执行 SELECT 时底层会将其转换为 GET 请求接口,当执行 INSERT 操作时,会将其转换为 POST 请求。
4 数据类型
4.1 基础类型
-
有符号整数类型
- Int8 → [-128 : 127]
- Int16 → [-32768 : 32767]
- Int32 → [-2147483648 : 2147483647]
- Int64 → [-9223372036854775808 : 9223372036854775807]
-
无符号整数类型
- UInt8 → [0 : 255]
- UInt16 → [0 : 65535]
- UInt32 → [0 : 4294967295]
- UInt64 → [0 : 18446744073709551615]
-
Boolean。不支持,可以使用UInt8类型,用1或0表示
-
- Float32 → 对应于float
- Float64 → 对应于double
-
- Decimal(P, S) → P :精度,有效范围:[1:38],决定可以有多少个十进制数字(包括分数)。S :规模,有效范围[0:P],决定数字的小数部分中包含的小数位数。
- Decimal32(S) → 等效于p从1到9
- Decimal64(S) → 等效于p从10到18
- Decimal128(S) → 等效于p从19到38
-
字符串类型
- String → 字符串可以任意长度的。它可以包含任意的字节集,包含空字节。ClickHouse 没有编码的概念。字符串可以是任意的字节集,按它们原本的方式进行存储和输出。但为了规范性和可维护性建议在用一套程序中遵循使用同一的的编码。
- FixedString(N) → 固定长度 N 的字符串(N 必须是严格的正自然数)。
- UUID → 专门用于保存UUID类型的值,格式如
00000000-0000-0000-0000-000000000000,Clickhouse自带函数generateUUIDv4()可生成
-
时间类型
- Date → 日期类型(精确到天),用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。允许存储从 Unix 纪元开始到编译阶段定义的上限阈值常量(目前上限是2106年,但最终完全支持的年份为2105)。最小值输出为0000-00-00。日期中没有存储时区信息。
- DateTime → 时间戳类型(精确到秒)。用四个字节(无符号的)存储 Unix 时间戳)。允许存储与日期类型相同的范围内的值。Unix中的值范围为
[1970-01-01 00:00:00, 2105-12-31 23:59:59]。默认情况下,客户端连接到服务的时候会使用服务端时区。您可以通过启用客户端命令行选项--use_client_time_zone来设置使用客户端时间。 - Datetime64 → 时间戳类型(精确到亚秒)。相比于 DateTime 类型增加了精度的设置。
4.2 复合类型
4.3 特殊类型
- Nullable:类似于 Java 8 的 Optional 对象,它表示某个基础数据类型可以为 Null 值。使用是需要注意,①它只能和基础类型搭配使用,不能用于数组和元组这些复合类型,也不能作为索引字段;②慎用 Nullable 类型,使用后可能会使查询和写入的性能变慢。
- Domains:包含两个主要类型 IPv4 和 IPv6,从本质上看他是对整形和字符串的进一步封装,IPv4 类型基于 UInt32 封装,IPv6 基于 FixedString(16)封装。那我为什么不能直接使用字符串存储而要使用这个类型存储呢?第一字符串可以存储任意类型,如果需要存储 IPv4 或者 IPv6 格式的数据则需要进行验证,而使用 IPv4 或者 IPv6 可以减少数据格式校验,如果格式有误,数据会无法写入。第二就是使用 ClickHouse 的 IPv4 或 IPv6 格式有更好的性能,因为例如 IPv4 使用 UInt32 存储,相比于直接使用 String 更加紧凑,占用空间更小,查询性能更快。
5 安装部署
5.1 安装之前
在前面我们知道 ClickHouse通过向量化执行引擎来加速查询,向量化执行可以简单的看作一项消除程序中循环的优化,为了实现向量化需要利用 CPU 的 SIMD (Single Instruction Multiple Data)指令,通过单条指令可以实现操作多条数据。在现代计算机中是通过数据并行来提高性能,其原理就是在 CPU 寄存器层面实现数据的并行操作。ClickHouse 目前通过 SSE 4.2 指令集实现向量化执行的。
因此首先需要保证我们的系统是支持SSE 4.2指令集(x86_64处理器构架的Linux系统为例),可以执行如下命令检查是否支持SSE 4.2,如果返回SSE 4.2 supported表示支持,则可以继续下面的安装。同时终端必须使用UTF-8编码。
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
- 1
同时我们最好再调整一下CentOS系统对打开文件数的限制,在/etc/security/limits.conf、/etc/security/limits.d/*-nproc.conf这2个文件的末尾加入一下内容。
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
# 或者配置 clickhouse 用户的文件句柄数,clickhouse 会以 clickhouse 用户运行
#clickhouse soft nofile 262144
#clickhouse hard nofile 262144
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
修改完毕之后,SSH工具重新连接,再次登录后,执行如下命令查看,如果输出的值是我们设置的则表示已生效。
# 查看
ulimit -n
- 1
- 2
5.2 单节点方式
5.2.1 yum方式安装
如果服务器可以连接网络,则可以直接通过yum方式安装,执行如下命令,如果是普通用户需要有sudo权限。下面的命令会自动下载资源安装稳定版的ClickHouse,如果需要安装最新版,把stable替换为testing。
# CentOS / RedHat
sudo yum install yum-utils
sudo rpm --import https://repo.yandex.ru/clickhouse/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.yandex.ru/clickhouse/rpm/stable/x86_64
sudo yum install clickhouse-server clickhouse-client
- 1
- 2
- 3
- 4
- 5
5.2.2 rpm方式安装
Yandex ClickHouse团队建议我们使用官方预编译的rpm软件包,用于CentOS、RedHat和所有其他基于rpm的Linux发行版。这种方式比较适合无法方位外网的生产环境安装,因此下面将主要采用这种方式安装和部署。ClickHouse的rpm包可以访问Download下载所需版本的安装包,执行如下命令下载资源包并安装。
下载 RPM 包常用的仓库主要有下面两个,可以选择访问其一,下载需要安装的版本进行部署
方式一:https://packagecloud.io/altinity/clickhouse
访问网站 https://packagecloud.io/altinity/clickhouse,选择安装的版本,例如在 CentOS7 系统下,下载如下几个 rpm 包,然后进行安装部署
# 1 下载
wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-server-19.16.3.6-1.el7.x86_64.rpm/download.rpm
wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-client-19.16.3.6-1.el7.x86_64.rpm/download.rpm
wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-common-static-19.16.3.6-1.el7.x86_64.rpm/download.rpm
wget --content-disposition https://packagecloud.io/Altinity/clickhouse/packages/el/7/clickhouse-server-common-19.16.3.6-1.el7.x86_64.rpm/download.rpm
# 2 安装
rpm -ivh clickhouse-*-19.16.3.6-1.el7.x86_64.rpm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
方式二:通过 yandex 提供的镜像
访问网站 https://repo.yandex.ru/clickhouse/rpm/,选择安装的版本,例如在 CentOS7 系统下,下载如下几个 rpm 包,然后进行安装部署
# 1 下载
wget https://repo.yandex.ru/clickhouse/rpm/prestable/x86_64/clickhouse-client-21.2.1.5869-2.noarch.rpm
wget https://repo.yandex.ru/clickhouse/rpm/prestable/x86_64/clickhouse-common-static-21.2.1.5869-2.x86_64.rpm
wget https://repo.yandex.ru/clickhouse/rpm/prestable/x86_64/clickhouse-common-static-dbg-21.2.1.5869-2.x86_64.rpm
wget https://repo.yandex.ru/clickhouse/rpm/prestable/x86_64/clickhouse-server-21.2.1.5869-2.noarch.rpm
# 2 安装
rpm -ivh clickhouse-*.rpm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.2.3 升级
如果需要在原有 ClickHouse 的基础上升级也是非常方便,直接下载新版本的 RPM 包,执行如下命令安装升级(可以不用关闭 ClickHouse 服务),升级的过程中,原有的 config.xml 等配置均会被保留,也可以参考官方资料使用其它方式升级 ClickHouse。
# 查看当前版本
clickhouse-server --version
# 升级。从安装的过程我们也可以看到,新包中的配置以 .rpmnew 后缀,旧的配置文件保留
[root@cdh2 software]# rpm -Uvh clickhouse-*-20.5.4.40-1.el7.x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:clickhouse-server-common-20.5.4.4warning: /etc/clickhouse-server/config.xml created as /etc/clickhouse-server/config.xml.rpmnew
################################# [ 13%]
warning: /etc/clickhouse-server/users.xml created as /etc/clickhouse-server/users.xml.rpmnew
2:clickhouse-common-static-20.5.4.4################################# [ 25%]
3:clickhouse-server-20.5.4.40-1.el7################################# [ 38%]
Create user clickhouse.clickhouse with datadir /var/lib/clickhouse
4:clickhouse-client-20.5.4.40-1.el7################################# [ 50%]
Create user clickhouse.clickhouse with datadir /var/lib/clickhouse
Cleaning up / removing...
5:clickhouse-client-19.16.3.6-1.el7################################# [ 63%]
6:clickhouse-server-19.16.3.6-1.el7################################# [ 75%]
7:clickhouse-server-common-19.16.3.################################# [ 88%]
8:clickhouse-common-static-19.16.3.################################# [100%]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
5.2.4 目录结构
/etc/clickhouse-server:服务端的配置文件目录,包括全局配置 config.xml 和用户配置 users.xml/var/lib/clickhouse:默认的数据存储目录,如果是生产环境可以将其修改到空间较大的磁盘挂载路径。可以通过修改/etc/clickhouse-server/config.xml配置文件中<path>、<tmp_path>和<user_files_path>标签值来设置。/var/log/clickhouse-server:默认的日志保存目录。同样可以通过修改/etc/clickhouse-server/config.xml配置文件中<log>和<errorlog>标签值来设置。/etc/cron.d/clickhouse-server:clickhouse server 的一个定时配置,用于恢复因异常中断的 ClickHouse 服务进程。~/.clickhouse-client-history:client 执行的 sql 历史记录。
5.2.5 服务的启停
ClickHouse Server服务的启停命令如下。我们可以先启动ClickHouse服务。
# 1 启动。
# 可以在/var/log/clickhouse-server/目录中查看日志。
#sudo /etc/init.d/clickhouse-server start
systemctl start clickhouse-server
## 或者基于指定的配置文件启动服务。使用此命令时注意权限
clickhouse-server --config-file=/etc/clickhouse-server/my_config.xml
# 2 查看状态
systemctl status clickhouse-server
# 3 重启
systemctl restart clickhouse-server
# 4 关闭
systemctl stop clickhouse-server
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5.2.6 进入 CLI
启动ClickHouse Client服务,验证是否安装成功,如果可以正常执行,那么我们就可以快速去开始体验ClickHouse了。
# 1 未设置密码时
# --database / -d 登录的数据库
# --help 查看帮助信息
# --host / -h 服务端地址,默认是 localhost,如果修改 config.xml 中的 listen_host 值后可以使用此参数指定访问的 ip
# --multiline / -m 支持SQL多行语句,而不是回车就执行
# --multiquery / -n 允许一次执行多条 SQL 语句
# --password 登录的密码,默认值为空
# --port 服务端的 TCP 端口,默认值为 9000
# --query / -q 指定 SQL 语句
# --time / -t 打印每条 SQL 的执行时间
# --user / -u 登录的用户名,默认值为 default
# --version / -V 查看版本信息
clickhouse-client
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-- 2 执行一个简单的SQL。可以正常解析并执行。
cdh1 :) SELECT 1;
SELECT 1
→ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.)
┌─1─┐
│ 1 │
└───┘
-- 退出
cdh2 :) q;
Bye.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5.3 集群方式
例如现在准备在三个节点(cdh1、cdh2、cdh3)的机器上安装部署ClickHouse,CentOS 7系统的防火墙和SELINUX已经关闭或禁止或端口已开放。集群的方需要依赖ZooKeeper服务,因此先要保证ZooKeeper服务正常启动,剩余的安装方式和单节点差不多,只不过需要添加一个集群形式的配置文件。
先在cdh1、cdh2、cdh3三个节点都通过rpm方式安装ClickHouse服务。先在cdh1节点配置/etc/clickhouse-server/metrika.xml(需要自己创建,默认为 /etc/metrika.xml,自己制定时需要在 config.xml 中指明),这个文件主要将ClickHouse各个服务的host和port、ZooKeeper集群的各个节点配置到文件中。cdh2和cdh3也同样配置,只不过需要将<macros>标签下的<replica>标签中的值改为自己节点的主机名或者ip。
<yandex>
<!-- /etc/clickhouse-server/config.xml 中配置的remote_servers的incl属性值,-->
<clickhouse_remote_servers>
<!-- 定义的集群名 -->
<perftest_3shards_1replicas>
<!-- 数据分片1 -->
<shard>
<internal_replication>true</internal_replication>
<!-- 主副本 -->
<replica>
<host>cdh1</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>cdh2</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片3 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>cdh3</host>
<port>9000</port>
</replica>
</shard>
</perftest_3shards_1replicas>
</clickhouse_remote_servers>
<!--zookeeper相关配置-->
<zookeeper-servers>
<node index="1">
<host>cdh1</host>
<port>2181</port>
</node>
<node index="2">
<host>cdh2</host>
<port>2181</port>
</node>
<node index="3">
<host>cdh3</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<replica>cdh1</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
因为集群之间需要互相方位其它节点的服务,需要开放ClickHouse服务的ip和端口,在cdh1、cdh2、cdh3三个机器上配置/etc/clickhouse-server/config.xml文件,在<yandex>标签下释放 <listen_host>标签(大概在69、70行),配置如下。
<yandex>
<!-- Listen specified host. use :: (wildcard IPv6 address), if you want to accept connections both with IPv4 and IPv6 from everywhere. -->
<listen_host>::</listen_host>
<!-- 设置时区为东八区,大概在第144行附近-->
<timezone>Asia/Shanghai</timezone>
<!-- 设置扩展配置文件的路径,大概在第229行附近-->
<include_from>/etc/clickhouse-server/metrika.xml</include_from>
<!-- 大概在160附近,注释其中配置的用于测试分布式存储的分片配置-->
<!-- Test only shard config for testing distributed storage
<test_shard_localhost>
……
</test_unavailable_shard>
-->
</yandex>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
为了不让ClickHouse裸奔,现在我们配置一下用户认证部分。密码配置有两种方式,一种是明文方式,一种是密文方式(sha256sum的Hash值),官方推荐使用密文作为密码配置,在cdh1、cdh2、cdh3三个机器上配置/etc/clickhouse-server/users.xml文件。用户名和密码的配置主要是在标签中,下面的配置文件中配置了两个用户,一个是默认用户default,就是如果未指明用户时默认使用的用户,其密码配置的为sha256密文方式,第二个用户是ck,为一个只读用户,即只能查看数据,无法建表修改数据等操作,其密码直接采用的明文方式进行配置。
<?xml version="1.0"?>
<yandex>
<!-- Profiles of settings. -->
<profiles>
<!-- Default settings. -->
<default>
<max_memory_usage>10000000000</max_memory_usage>
<use_uncompressed_cache>0</use_uncompressed_cache>
<load_balancing>random</load_balancing>
</default>
<!-- Profile that allows only read queries. -->
<readonly>
<readonly>1</readonly>
</readonly>
</profiles>
<!-- Users and ACL. -->
<users>
<default>
<!--
<password>KavrqeN1</password>
通过如下命令随机执行随机获取一个: PASSWORD=$(base64 < /dev/urandom | head -c8); echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-'
-->
<password_sha256_hex>abb23878df2926d6863ca539f78f4758722966196e8f918cd74d8c11e95dc8ae</password_sha256_hex>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<!-- Settings profile for user. -->
<profile>default</profile>
<!-- Quota for user. -->
<quota>default</quota>
<!-- For testing the table filters -->
<databases>
<test>
<!-- Simple expression filter -->
<filtered_table1>
<filter>a = 1</filter>
</filtered_table1>
<!-- Complex expression filter -->
<filtered_table2>
<filter>a + b < 1 or c - d > 5</filter>
</filtered_table2>
<!-- Filter with ALIAS column -->
<filtered_table3>
<filter>c = 1</filter>
</filtered_table3>
</test>
</databases>
</default>
<ck>
<password>123456</password>
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>readonly</profile>
<quota>default</quota>
</ck>
</users>
<!-- Quotas. -->
<quotas>
<!-- Name of quota. -->
<default>
<!-- Limits for time interval. You could specify many intervals with different limits. -->
<interval>
<!-- Length of interval. -->
<duration>3600</duration>
<!-- No limits. Just calculate resource usage for time interval. -->
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>
</yandex>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
其中生成sha256sum的Hash值可以执行如下命令(第一行),回车后输出两行信息(第二行和第三行),其中第二行是原始密码,第三行是加密的密文,配置文件使用第三行的字符串,客户端登录是使用第二行的密码。
# 随机生成一个 sha256 加密的密码
$ PASSWORD=$(base64 < /dev/urandom | head -c8); echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-'
KavrqeN1
abb23878df2926d6863ca539f78f4758722966196e8f918cd74d8c11e95dc8ae
# 指定生成密码,例如指定密码为 KavrqeN1
$ PASSWORD=KavrqeN1; echo "$PASSWORD"; echo -n "$PASSWORD" | sha256sum | tr -d '-'
KavrqeN1
abb23878df2926d6863ca539f78f4758722966196e8f918cd74d8c11e95dc8ae
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
由于配置了密码,因此需要让集群的每个节点也知道每个节点的密码,因此在上面的/etc/clickhouse-server/metrika.xml配置文件的分片中增加用户名和密码的配置,这里为了方便三个节点的密码配置的一样,也可以每个节点密码不一样。
<!-- 定义的集群名 -->
<perftest_3shards_1replicas>
<shard>
<!-- 在分布式表中的这个 shard 内只选择一个合适的 replica 写入数据。如果为本地表引擎为 ReplicatedMergeTree ,多个副本之间的数据交由引擎自己处理 -->
<internal_replication>true</internal_replication>
<replica>
<host>cdh1</host>
<port>9000</port>
<user>default</user>
<password>KavrqeN1</password>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>cdh2</host>
<port>9000</port>
<user>default</user>
<password>KavrqeN1</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>cdh3</host>
<port>9000</port>
<user>default</user>
<password>KavrqeN1</password>
</replica>
</shard>
</perftest_3shards_1replicas>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
在三个节点的服务器上分别启动ClickHouse服务,执行如下命令。启动时请保证每个节点的9000端口未被占用(lsof -i:9000),如果占用请修改/etc/clickhouse-server/config.xml文件中的端口(<tcp_port>9000</tcp_port>),同时记得/etc/clickhouse-server/metrika.xml中的端口号也要统一。
# 启动服务
systemctl start clickhouse-server
# 查看服务状态。如果Active 显示的为 active,且信息中没有错误,则表示启动成功。
systemctl status clickhouse-server
- 1
- 2
- 3
- 4
- 5
6 客户端工具
6.1 clickhouse-client
# 1 未设置密码时
clickhouse-client
# 2 指定用户名和密码
clickhouse-client -h 127.0.0.1 -u default --password KavrqeN1
clickhouse-client -h 127.0.0.1 --port 9000 -u default --password KavrqeN1 --multiline
# 指定sql命令方式
clickhouse-client -h 127.0.0.1 --port 9000 -u default --password KavrqeN1 --multiline -q "SELECT now()"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-- 查看集群信息
cdh3 :) SELECT * FROM system.clusters;
SELECT *
FROM system.clusters
↙ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.)
┌─cluster─────────────────┬─shard_num─┬─shard_weight─┬─replica_num─┬─host_name─┬─host_address────┬──port─┬─is_local─┬─user────┬─default_database─┬─errors_count─┬─estimated_recovery_time─┐
│ perftest_3shards_1replicas │ 1 │ 1 │ 1 │ cdh1 │ 192.168.33.3 │ 9000 │ 0 │ default │ │ 0 │ 0 │
│ perftest_3shards_1replicas │ 2 │ 1 │ 1 │ cdh2 │ 192.168.33.6 │ 9000 │ 0 │ default │ │ 0 │ 0 │
│ perftest_3shards_1replicas │ 3 │ 1 │ 1 │ cdh3 │ 192.168.33.9 │ 9000 │ 1 │ default │ │ 0 │ 0 │
└────────────────────────────┴───────────┴──────────────┴─────────────┴───────────┴──────────────┴───────┴──────────┴─────────┴──────────────────┴──────────────┴─────────────────────────┘
← Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.) ↖ Progress: 3.00 rows, 360.00 B (1.36 thousand rows/s., 163.76 KB/s.)
3 rows in set. Elapsed: 0.003 sec.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6.2 DBeaver
- 新建连接
- All(或者Analytical),选择ClickHouse,下一步
- 端口默认是8123,主机选择ClickHouse的Server节点(如果是集群,随意一个ClickHouse 服务节点都行)。填写用户认证处设置用户名和密码。
- 测试连接,会提示下载驱动,确认下载即可。
查看ClickHouse集群信息,在DBeaver中执行如下SQL。可以看到集群的分片、分片表示序号、host名字、端口号、用户名等信息。
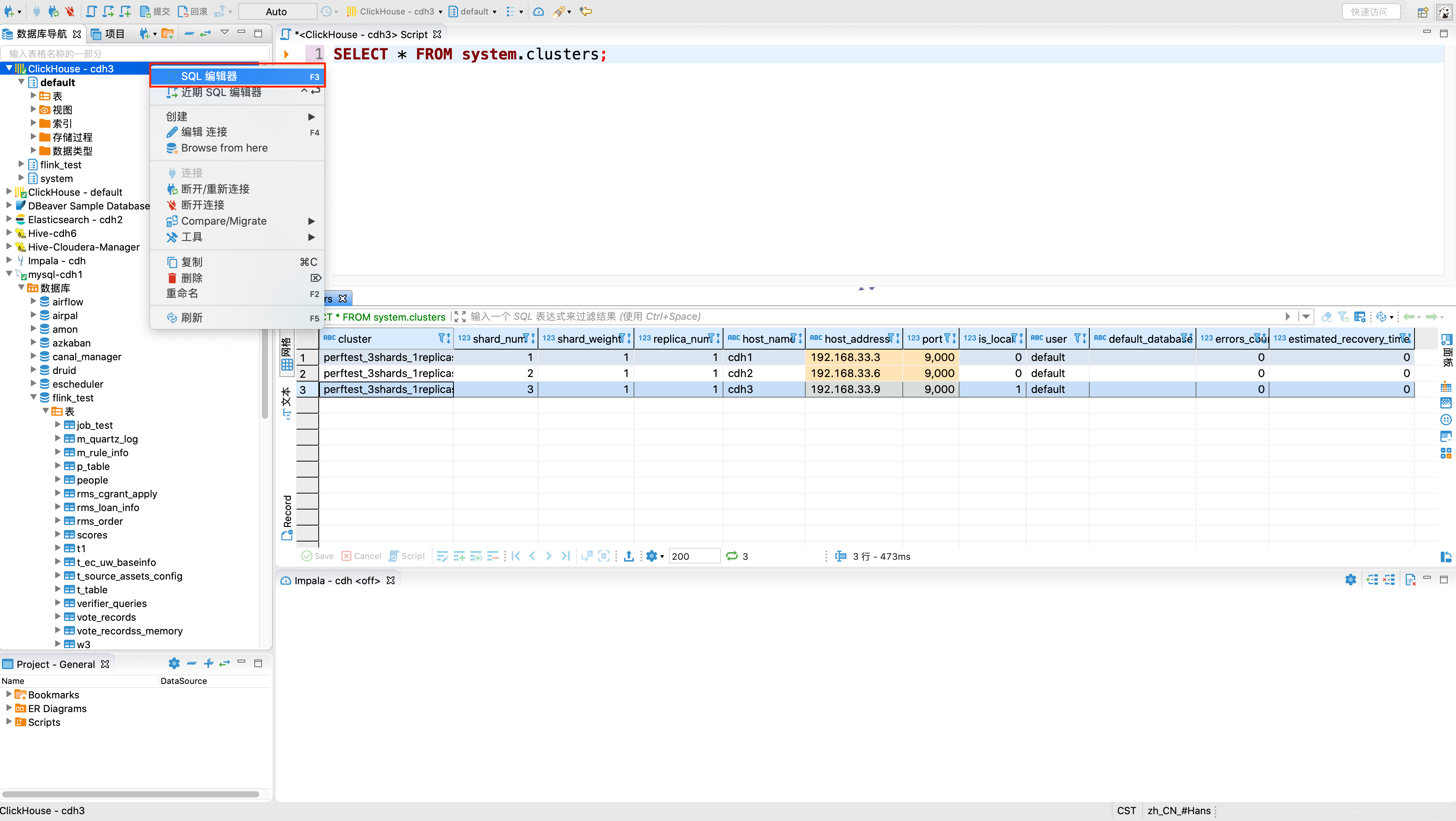
6.3 JDBC
项目中引入依赖
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
Scala代码如下:
package yore
import java.sql.{Connection, DriverManager, ResultSet, ResultSetMetaData, Statement}
/**
* 数据集可以通过执行这个脚本获取:
* https://github.com/Percona-Lab/ontime-airline-performance/blob/master/download.sh
*
* url 支持高可用模式,即 jdbc:clickhouse://<server1>:<port>,<server2>:<port>[,...]/<database>
* 会依次从可用的地址中随机选择其中一个连接访问
*
* 关于客户端访问 ClickHouse 的端口:
* TCP协议的端口为 9000
* HTTP协议的端口为 8123
*
* Created by yore on 2019/11/4 17:25
*/
object JdbcClient {
private val address = "jdbc:clickhouse://cdh3:8123/default"
def main(args: Array[String]): Unit = {
Class.forName("ru.yandex.clickhouse.ClickHouseDriver")
var connection: Connection = null
var statement: Statement = null
var results: ResultSet = null
var sql = "SELECT COUNT(*) FROM part "
sql = "SELECT * FROM lineorder ORDER BY LO_COMMITDATE DESC LIMIT 10"
sql =
"""
|SELECT
| min(Year), max(Year), Carrier, count(*) AS cnt,
| sum(ArrDelayMinutes>30) AS flights_delayed,
| round(sum(ArrDelayMinutes>30)/count(*),2) AS rate
|FROM ontime
|WHERE
| DayOfWeek NOT IN (6,7) AND OriginState NOT IN ('AK', 'HI', 'PR', 'VI')
| AND DestState NOT IN ('AK', 'HI', 'PR', 'VI')
| AND FlightDate < '2010-01-01'
|GROUP by Carrier
|HAVING cnt>100000 and max(Year)>1990
|ORDER by rate DESC
|LIMIT 1000;
""".stripMargin
try{
// 用户名和密码就是前面在/etc/clickhouse-server/users.xml 中配置的
connection = DriverManager.getConnection(address, "ck", "123456")
statement = connection.createStatement
val begin = System.currentTimeMillis
results = statement.executeQuery(sql)
val end = System.currentTimeMillis
val rsmd: ResultSetMetaData = results.getMetaData()
for(i <- 1 to rsmd.getColumnCount){
print(s"${rsmd.getColumnName(i)}\t")
}
println()
while(results.next()){
for(i <- 1 to rsmd.getColumnCount){
print(s"${results.getString(rsmd.getColumnName(i))}\t")
}
println()
}
println(s"${"-"*30}\n执行${sql} 耗时${end-begin} ms")
}catch {
case e: Exception => e.printStackTrace()
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
执行上述查询后控制台输出的结果如下:
min(Year) max(Year) Carrier cnt flights_delayed rate
2003 2009 EV 1454777 237698 0.16
2003 2009 B6 683874 103677 0.15
2003 2009 FL 1082489 158748 0.15
2006 2009 YV 740608 110389 0.15
2006 2009 XE 1016010 152431 0.15
2003 2005 DH 501056 69833 0.14
2001 2009 MQ 3238137 448037 0.14
2003 2006 RU 1007248 126733 0.13
2004 2009 OH 1195868 160071 0.13
1987 2009 UA 9655762 1203503 0.12
2003 2006 TZ 136735 16496 0.12
1987 2009 CO 6092575 681750 0.11
1987 2009 AA 10678564 1189672 0.11
1987 2001 TW 2693587 283362 0.11
1987 2009 AS 1511966 147972 0.1
1987 2009 NW 7648247 729920 0.1
1987 2009 DL 11948844 1163924 0.1
1988 2009 US 10229664 986338 0.1
2007 2009 9E 577244 59440 0.1
2003 2009 OO 2654259 257069 0.1
1987 1991 PA 218938 20497 0.09
2005 2009 F9 307569 28679 0.09
1987 2005 HP 2628455 236633 0.09
1987 2009 WN 12726332 1108072 0.09
------------------------------
执行
SELECT
min(Year), max(Year), Carrier, count(*) AS cnt,
sum(ArrDelayMinutes>30) AS flights_delayed,
round(sum(ArrDelayMinutes>30)/count(*),2) AS rate
FROM ontime
WHERE
DayOfWeek NOT IN (6,7) AND OriginState NOT IN ('AK', 'HI', 'PR', 'VI')
AND DestState NOT IN ('AK', 'HI', 'PR', 'VI')
AND FlightDate < '2010-01-01'
GROUP by Carrier
HAVING cnt>100000 and max(Year)>1990
ORDER by rate DESC
LIMIT 1000;
耗时1801 ms
Process finished with exit code 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
6.4 clickhouse-local
clickhouse-local 可以理解为 是ClickHouse 服务的一个单机微内核版,它不需要依赖任何 ClickHouse 的服务端程序,但是 clickhouse-local 只能够使用 File 表引擎,同时它是于本机 ClickHouse 服务(如果有)的数据完全隔离。
# echo 输出两行逗号分隔的数据作为数据源输入,通过 SQL 创建一个对应结构的表,查询数据,最后删除表
[root@cdh2 ~]# echo -e "1,2\n3,4" | clickhouse-local --query "CREATE TABLE table (a Int64, b Int64) ENGINE = File(CSV, stdin); \
> SELECT a, b FROM table; DROP TABLE table"
1 2
3 4
# 通过 ps 查看系统进程信息,通过管道输出第二行到行尾的所有内容,再通过管道使用 awk 取出第1列(USER)和第4列(MEM)
# 作为数 clickhouse 数据源输入,创建对应的表结构,执行 SQL 查询语句,获取每个用户内存的使用量。
#
# 其中参数说明如下
# --structure /-S 输入数据的表结构
# --input-format / -if 输入数据个格式,默认为 TSV
# --file / -f 输入数据的路径,默认值为标准输入 stdin
# --query / -q 执行的 SQL 语句,多条语句时用分号分割
# --table / -N 表名,用于放置输出数据,默认为 table
# --format / -of 输出数据的格式,默认为 TSV
# --stacktrace whether to dump debug output in case of exception.
# --verbose 查询执行的更详细信息
# -s 禁用 stderr 日志
# --config-file 配置文件的路径,格式与ClickHouse server 配置相同,默认配置为空
# --help clickhouse-local的参数说明
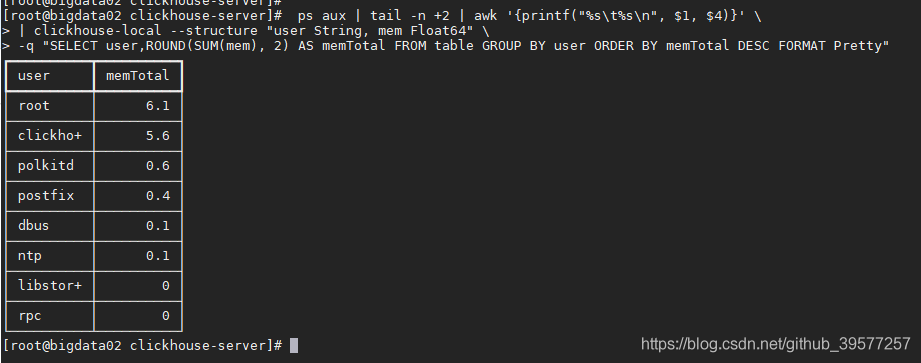
ps aux | tail -n +2 | awk '{ printf("%s\t%s\n", $1, $4) }' \
| clickhouse-local --structure "user String, mem Float64" \
-q "SELECT user, round(sum(mem), 2) as memTotal FROM table GROUP BY user ORDER BY memTotal DESC FORMAT Pretty"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
7 MySQL 及 ClickHouse 的 MySQL 引擎使用
默认情况下,ClickHouse使用自己的数据库引擎,但它同时支持MySQL数据库引擎,这种方式将远程的MySQL服务器中的表映射到ClickHouse中,并允许您对表进行INSERT和SELECT查询,以方便您在ClickHouse与MySQL之间进行数据交换。MySQL数据库引擎会将对其的查询转换为MySQL语法并发送到MySQL服务器中,因此我们可以执行诸如SHOW TABLES或SHOW CREATE TABLE之类的操作。但是通过这种方式不能对数据进行:ATTACH/DETACH、DROP、RENAME、CREATE TABLE、ALTER。
下面我们通过ClickHouse的MySQL数据库引擎来查询MySQL中的一份数据来演示,其中一个表的数据大概有2kw。通过这个演示感受一下ClickHouse的速度。
-- 1 在ClickHouse中创建MySQL类型的数据库,同时与MySQL服务器交换数据:
cdh3 :) CREATE DATABASE IF NOT EXISTS flink_test
:-] ENGINE = MySQL('cdh1:3306', 'flink_test', 'scm', 'scm');
CREATE DATABASE IF NOT EXISTS flink_test
ENGINE = MySQL('cdh1:3306', 'flink_test', 'scm', 'scm')
Ok.
0 rows in set. Elapsed: 0.004 sec.
-- 2 查看库
cdh3 :) SHOW DATABASES;
SHOW DATABASES
→ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.)
┌─name───────┐
│ default │
│ flink_test │
│ system │
└────────────┘
↘ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.) ↓ Progress: 3.00 rows, 290.00 B (528.24 rows/s., 51.06 KB/s.)
3 rows in set. Elapsed: 0.006 sec.
-- 3 查看 flink_test 库中的表。此时在ClickHouse中便可以看到MySQL中的表。其它未用到的表已省略
cdh3 :) SHOW TABLES FROM flink_test;
SHOW TABLES FROM flink_test
↙ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.)
┌─name───────────────────┐
│ vote_recordss_memory │
│ w3 │
└────────────────────────┘
← Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.) ↖ Progress: 17.00 rows, 661.00 B (1.95 thousand rows/s., 75.99 KB/s.)
17 rows in set. Elapsed: 0.009 sec.
-- 4 选择库
cdh3 :) USE flink_test;
USE flink_test
Ok.
0 rows in set. Elapsed: 0.005 sec.
-- 5 插入数据(表名区分大小写)
cdh3 :) INSERT INTO w3 VALUES(3, 'Mercury');
INSERT INTO w3 VALUES
Ok.
1 rows in set. Elapsed: 0.022 sec.
-- 6 查询数据。数据插入后不支持删除和更新。
cdh3 :) SELECT * FROM w3;
SELECT *
FROM w3
← Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.)
┌─id─┬─f1──────┐
│ 3 │ Mercury │
│ 5 │ success │
└────┴─────────┘
↖ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.) ↑ Progress: 2.00 rows, 42.00 B (202.58 rows/s., 4.25 KB/s.)
2 rows in set. Elapsed: 0.010 sec.
-- 7 查看 MySQL 和 ClickHouse 对数据的聚合能力
-- 7.1 MySQL。可以看到在MySQL中统计一张将近2千万数据量的表花费了 29.54 秒
mysql> SELECT COUNT(*) FROM vote_recordss_memory;
+----------+
| COUNT(*) |
+----------+
| 19999998 |
+----------+
1 row in set (29.54 sec)
-- 7.2 ClickHouse 中执行一次COUNT,花费了 9.713 秒
cdh3 :) SELECT COUNT(*) FROM vote_recordss_memory;
SELECT COUNT(*)
FROM vote_recordss_memory
↘ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.) ↓ Progress: 131.07 thousand rows, 131.07 KB (1.14 million rows/s., 1.14 MB/s.) ↙ Progress: 327.68 thousand rows, 327.68 KB (1.52 million rows/s., 1.52 MB/s.) ← Progress: 524.29 thousand rows, 524.29 KB (1.66 millio
┌──COUNT()─┐
│ 19999998 │
└──────────┘
↓ Progress: 19.79 million rows, 19.79 MB (2.04 million rows/s., 2.04 MB/s.) ↙ Progress: 20.00 million rows, 20.00 MB (2.06 million rows/s., 2.06 MB/s.)
1 rows in set. Elapsed: 9.713 sec. Processed 20.00 million rows, 20.00 MB (2.06 million rows/s., 2.06 MB/s.)
-- 7.3 在查询时指定mysql的连接、库名、表名、登录信息,等价于上面的SQL。
cdh3 :) SELECT COUNT(*) FROM mysql('cdh1:3306', 'flink_test', 'vote_recordss_memory', 'root', '123456');
-- 8 使用 ClickHouse 的 MergeTree 表引擎
-- 8.1 切换到 ClickHouse 默认库下
cdh1 :) USE default;
USE default
Ok.
0 rows in set. Elapsed: 0.007 sec.
-- 8.2 创建表并指定 MergeTree 表引擎,将MySQL数据加载进来,同时指定排序规则主键值为准
cdh1 :) CREATE TABLE vote_recordss
:-] ENGINE = MergeTree--(id, create_time)
:-] ORDER BY id AS
:-] SELECT * FROM mysql('cdh1:3306', 'flink_test', 'vote_recordss_memory', 'root', '123456');
CREATE TABLE vote_recordss
ENGINE = MergeTree
ORDER BY id AS
SELECT *
FROM mysql('cdh1:3306', 'flink_test', 'vote_recordss_memory', 'root', '123456')
↖ Progress: 65.54 thousand rows, 3.01 MB (299.97 thousand rows/s., 13.80 MB/s.) ↑ Progress: 131.07 thousand rows, 6.03 MB (411.12 thousand rows/s., 18.91 MB/s.) ↗ Progress: 196.61 thousand rows, 9.04 MB (468.88 thousand rows/s., 21.57 MB/s.) → Progress: 262.14 thousand Ok.
0 rows in set. Elapsed: 27.917 sec. Processed 20.00 million rows, 920.00 MB (716.40 thousand rows/s., 32.95 MB/s.)
-- 8.3 查询。可以看到是count某个值的速度速度约为MySQL的2950倍
cdh1 :) SELECT COUNT(*) FROM vote_recordss;
SELECT COUNT(*)
FROM vote_recordss
↙ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.)
┌──COUNT()─┐
│ 19999998 │
└──────────┘
← Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.) ↖ Progress: 20.00 million rows, 80.00 MB (2.26 billion rows/s., 9.06 GB/s.) 98%
1 rows in set. Elapsed: 0.009 sec. Processed 20.00 million rows, 80.00 MB (2.20 billion rows/s., 8.79 GB/s.)
-- 8.4 去重。可以看到ClickHouse速度约为MySQL的94倍
mysql> SELECT DISTINCT group_id from vote_recordss_memory ;
+----------+
| group_id |
+----------+
| 1 |
| 2 |
| 0 |
+----------+
3 rows in set (12.79 sec)
-- ClickHouse中执行
cdh1 :) SELECT DISTINCT group_id from vote_recordss;
SELECT DISTINCT group_id
FROM vote_recordss
↑ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.)
┌─group_id─┐
│ 0 │
│ 2 │
│ 1 │
└──────────┘
↗ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.) → Progress: 19.04 million rows, 76.17 MB (145.18 million rows/s., 580.70 MB/s.) 94%↘ Progress: 20.00 million rows, 80.00 MB (147.97 million rows/s., 591.87 MB/s.) 98%
3 rows in set. Elapsed: 0.136 sec. Processed 20.00 million rows, 80.00 MB (147.44 million rows/s., 589.76 MB/s.)
-- 8.5 分组统计。可以看到ClickHouse速度约为MySQL的94倍
mysql> SELECT SUM(vote_num),group_id from vote_recordss_memory GROUP BY group_id;
+---------------+----------+
| SUM(vote_num) | group_id |
+---------------+----------+
| 33344339689 | 0 |
| 33315889226 | 1 |
| 33351509121 | 2 |
+---------------+----------+
3 rows in set (16.26 sec)
-- ClickHouse中执行
cdh1 :) SELECT SUM(vote_num),group_id from vote_recordss GROUP BY group_id;
SELECT
SUM(vote_num),
group_id
FROM vote_recordss
GROUP BY group_id
↙ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.) ← Progress: 11.43 million rows, 91.42 MB (101.40 million rows/s., 811.20 MB/s.) 56%
┌─SUM(vote_num)─┬─group_id─┐
│ 33344339689 │ 0 │
│ 33351509121 │ 2 │
│ 33315889226 │ 1 │
└───────────────┴──────────┘
↖ Progress: 11.43 million rows, 91.42 MB (66.08 million rows/s., 528.64 MB/s.) 56%↑ Progress: 20.00 million rows, 160.00 MB (115.61 million rows/s., 924.84 MB/s.) 98%
3 rows in set. Elapsed: 0.173 sec. Processed 20.00 million rows, 160.00 MB (115.56 million rows/s., 924.45 MB/s.)
-- 8.6 排序取TOP 10。可以看到ClickHouse速度约为MySQL的25倍
mysql> SELECT * FROM vote_recordss_memory ORDER BY create_time DESC,vote_num LIMIT 10;
+----------+----------------------+----------+----------+--------+---------------------+
| id | user_id | vote_num | group_id | status | create_time |
+----------+----------------------+----------+----------+--------+---------------------+
| 19999993 | 4u6PJYvsDD4khghreFvm | 2388 | 0 | 1 | 2019-10-15 01:00:20 |
| 19999998 | shTrosZpT5zux3wiKH5a | 4991 | 2 | 1 | 2019-10-15 01:00:20 |
| 19999995 | xRwQuMgQeuBoXvsBusFO | 6737 | 2 | 1 | 2019-10-15 01:00:20 |
| 19999996 | 5QNgMYoQUSsuX7Aqarw8 | 7490 | 2 | 2 | 2019-10-15 01:00:20 |
| 19999997 | eY12Wq9iSm0MH1PUTChk | 7953 | 0 | 2 | 2019-10-15 01:00:20 |
| 19999994 | ZpS0dWRm1TdhzTxTHCSj | 9714 | 0 | 1 | 2019-10-15 01:00:20 |
| 19999946 | kf7FOTUHAICP5Mv2xodI | 32 | 2 | 2 | 2019-10-15 01:00:19 |
| 19999738 | ER90qVc4CJCKH5bxXYTo | 57 | 1 | 2 | 2019-10-15 01:00:19 |
| 19999810 | gJHbBkGf0bJViwy5BB2d | 190 | 1 | 2 | 2019-10-15 01:00:19 |
| 19999977 | Wq7bogXRiHubhFlAHBJH | 208 | 0 | 2 | 2019-10-15 01:00:19 |
+----------+----------------------+----------+----------+--------+---------------------+
10 rows in set (15.31 sec)
-- ClickHouse中执行
cdh1 :) SELECT * FROM vote_recordss ORDER BY create_time DESC,vote_num LIMIT 10;
SELECT *
FROM vote_recordss
ORDER BY
create_time DESC,
vote_num ASC
LIMIT 10
↗ Progress: 0.00 rows, 0.00 B (0.00 rows/s., 0.00 B/s.) → Progress: 2.34 million rows, 107.77 MB (21.21 million rows/s., 975.60 MB/s.) 11%↘ Progress: 5.31 million rows, 244.19 MB (24.97 million rows/s., 1.15 GB/s.) 26%↓ Progress: 8.75 million rows, 402.46 MB (27.97 mi%
┌───────id─┬─user_id──────────────┬─vote_num─┬─group_id─┬─status─┬─────────create_time─┐
│ 19999993 │ 4u6PJYvsDD4khghreFvm │ 2388 │ 0 │ 1 │ 2019-10-15 01:00:20 │
│ 19999998 │ shTrosZpT5zux3wiKH5a │ 4991 │ 2 │ 1 │ 2019-10-15 01:00:20 │
│ 19999995 │ xRwQuMgQeuBoXvsBusFO │ 6737 │ 2 │ 1 │ 2019-10-15 01:00:20 │
│ 19999996 │ 5QNgMYoQUSsuX7Aqarw8 │ 7490 │ 2 │ 2 │ 2019-10-15 01:00:20 │
│ 19999997 │ eY12Wq9iSm0MH1PUTChk │ 7953 │ 0 │ 2 │ 2019-10-15 01:00:20 │
│ 19999994 │ ZpS0dWRm1TdhzTxTHCSj │ 9714 │ 0 │ 1 │ 2019-10-15 01:00:20 │
│ 19999946 │ kf7FOTUHAICP5Mv2xodI │ 32 │ 2 │ 2 │ 2019-10-15 01:00:19 │
│ 19999738 │ ER90qVc4CJCKH5bxXYTo │ 57 │ 1 │ 2 │ 2019-10-15 01:00:19 │
│ 19999810 │ gJHbBkGf0bJViwy5BB2d │ 190 │ 1 │ 2 │ 2019-10-15 01:00:19 │
│ 19999977 │ Wq7bogXRiHubhFlAHBJH │ 208 │ 0 │ 2 │ 2019-10-15 01:00:19 │
└──────────┴──────────────────────┴──────────┴──────────┴────────┴─────────────────────┘
↖ Progress: 16.65 million rows, 766.10 MB (27.46 million rows/s., 1.26 GB/s.) 82%↑ Progress: 20.00 million rows, 920.00 MB (32.98 million rows/s., 1.52 GB/s.) 98%
10 rows in set. Elapsed: 0.607 sec. Processed 20.00 million rows, 920.00 MB (32.93 million rows/s., 1.51 GB/s.)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
在不同的查询查询场景下,ClickHouse都要比MySQL快很多,整个查询ClickHouse均能控制在1秒内,这个给人的印象实在太深刻了,是不是有种,放开MySQL吧~,专业的事情让专业的数据库来做吧
![[计算机网络]--MAC/ARP/DNS协议_mac地址欺骗arp欺骗攻击](https://img-blog.csdnimg.cn/direct/e63669185525402a8917335a49e5a9de.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

