- 1揭秘ChatGPT:如何让机器理解并生成自然语言_解码器可以帮助系统理解和生成自然语言文本文本吗
- 2[计算机网络]--MAC/ARP/DNS协议_mac地址欺骗arp欺骗攻击
- 3盘点12个Python数据可视化库,通吃任何领域_python数据可视化项目推荐
- 4Python -----map函数_python map
- 5基于springboot+vue的图书管理系统-计算机毕业设计_springboot+vue的系统架构图
- 6Flutter 与 原生交互(Android),靠着这份900多页的PDF面试整理
- 7transformers 安装_transformer安装
- 8Python可视化-Bokeh库
- 9ThingsBoard3.1项目的安装与编译_thingsboard 手动导入yarn包
- 10kafka的Java客户端-消费者_java kafka consumer
《论文阅读》具有人格自适应注意的个性化对话生成 AAAI 2023
赞
踩
前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~
无抄袭,无复制,纯手工敲击键盘~
今天为大家带来的是《Personalized Dialogue Generation with Persona-Adaptive Attention》

出版:AAAI
时间:2023
类型:个性化对话生成
特点:个性化;多样性;回复生成;个性化适应性注意力
作者:Qiushi Huang
第一作者机构:University of Surrey
简介
生成个性化回复的关键是需要平衡上下文和个性化信息,由此作者提出利用个性化适应的注意力(Persona-Adaptive Attention,PAA)来适应性地调整两者之间的权重,此外一个动态地掩码矩阵用于去除冗余的信息,并进行正则化处理以防过拟合
本文的亮点在于使用 Attention 平衡上下文和个性化信息的权重,上一篇论文 《论文阅读》Learning to Know Myself: A Coarse-to-Fine Persona-Aware Training for Personalized Dialogue Generation 则注重让模型捕获个性化信息,如通过问题生成个性化信息,利用对比学习构造相关但不一致的个性化信息作为负样本,提高模型捕获回复中关键个性化 Token 的能力
挑战与机遇
-
个性化数据集规模普遍较小
【常见解决思路】利用外部数据集进行数据增强,利用复杂的训练过程来提升模型表现
-
权衡上下文和个性化信息的比例
【常见的解决思路】鲜少有人提及
针对上述第二个挑战,作者提出一下几点思路:
1)为了加强 PAA 中的个性化信息,在 decoder 端拼接个性化信息作为提示信息
2)为了平衡上下文和个性化信息的权重,PAA 将 persona-prompted 解码器的两个跨注意力和自我注意结合起来,以计算用于结合上下文和 persona 的潜在表示的权重
3)为了避免信息冗余(即并非所有的信息有用),所以提出两个动态掩码矩阵来去除冗余信息
任务定义

模型架构
模型包含两个 Encoder,分别为上下文编码和个性化信息编码,Encoder 参数随机初始化,Decoder 使用预训练模型 GPT2 为目标语句进行编码
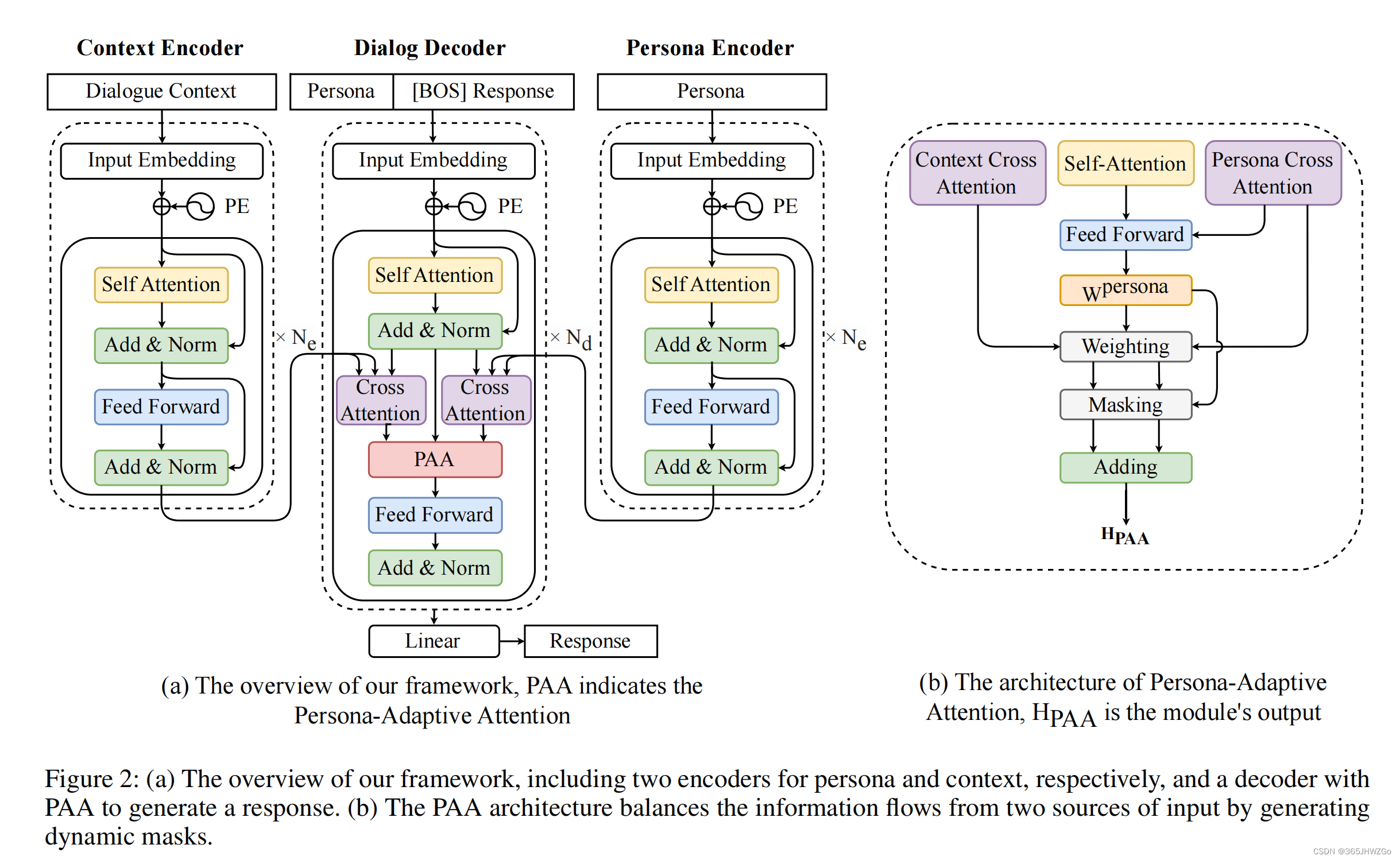
Context Encoder
I U = { t 1 U , t 2 U , . . . , t k U } h U = Encoder ( I U ) (1) I_U=\{t_1^U,t_2^U,..., t_k^U\}\\ h_U = \texttt{Encoder}(I_U)\tag1 IU={t1U,t2U,...,tkU}hU=Encoder(IU)(1)
I U I_U IU 将所有语句拼接起来,组成一个完整的句子
Persona Encoder
I P = { t 1 P , t 2 P , . . . , t l P } h P = Encoder ( I P ) (2) I_P=\{t_1^P,t_2^P,..., t_l^P\}\\ h_P = \texttt{Encoder}(I_P)\tag2 IP={t1P,t2P,...,tlP}hP=Encoder(IP)(2)
I P I_P IP 将所有语句拼接起来,组成一个完整的句子
Dialog Decoder
I R = { I P , [ B O S ] , t 1 y , t 2 y , . . . , t r y } h R = Self-Attention ( I R ) + M R h ^ R = AddNorm ( h R ) (3) I_R=\{I_P,[BOS],t_1^y,t_2^y,...,t_r^y\}\\ h_R=\texttt{Self-Attention}(I_R)+M_R\\ \hat{h}_R=\texttt{AddNorm}(h_R)\tag3 IR={IP,[BOS],t1y,t2y,...,try}hR=Self-Attention(IR)+MRh^R=AddNorm(hR)(3)
在得到上述 hidden states \texttt{hidden states} hidden states 之后,我们可以进行 Cross Attention \texttt{Cross Attention} Cross Attention 的计算,
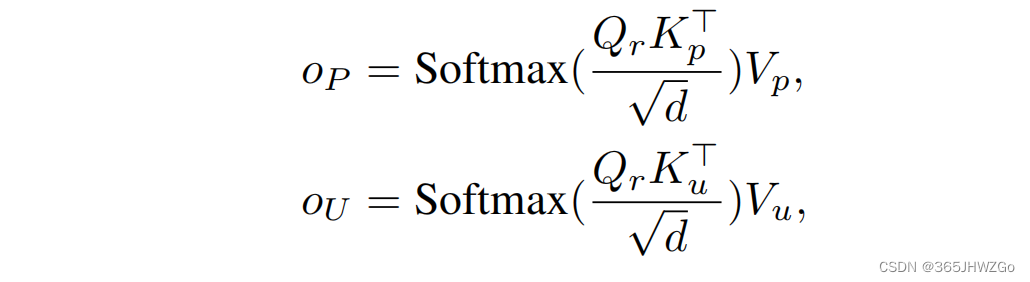
其中 Q r = h ^ R Q_r =\hat{h}_R Qr=h^R, K p , V p = h p K_p,V_p=h_p Kp,Vp=hp , K u , V u = h U K_u,V_u=h_U Ku,Vu=hU
Persona-Adaptive Attention
那么如何将上述获得的结果融合到一起呢?

将 Decoder 端 Self-Attention 的输出 h R h_R hR 拼接上 Cross-Attention 端的输出 o P o_P oP,然后获取最初 Persona weighting,这样做可以使模型能够考虑角色和回复之间的关联,包括在自注意力和跨注意力两种方式中考虑角色和响应之间的关系
然后在将该权重应用于两个交叉注意力后的结果,使其之间相互互补

我们之前提及本文的另一个创新点是利用 MASK 矩阵去除冗余信息,下面我们将介绍 MASK 矩阵的获取

如果上下文长度超过了角色长度, τ \tau τ 可以用于控制 mask 的强度的, τ = ∣ I U ∣ / ( ∣ I U ∣ + ∣ I P ∣ ) \tau=|I_U|/(|I_U|+|I_P|) τ=∣IU∣/(∣IU∣+∣IP∣), ∣ ∣ || ∣∣ 表示输入长度

然后将 MASK 矩阵分别乘以对应的输出,得到最终的 Decoder 输出
损失函数

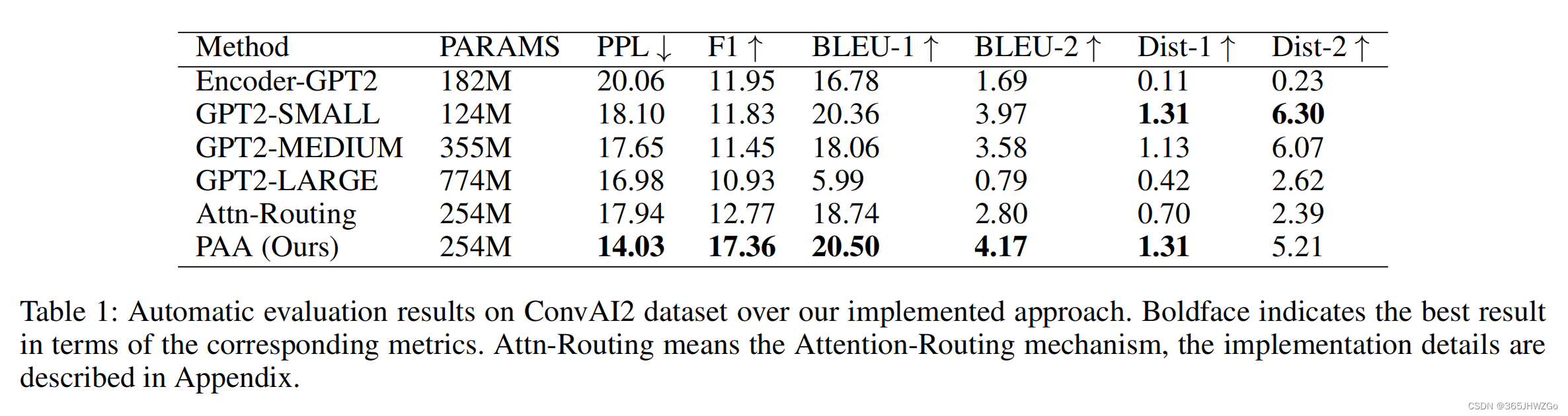
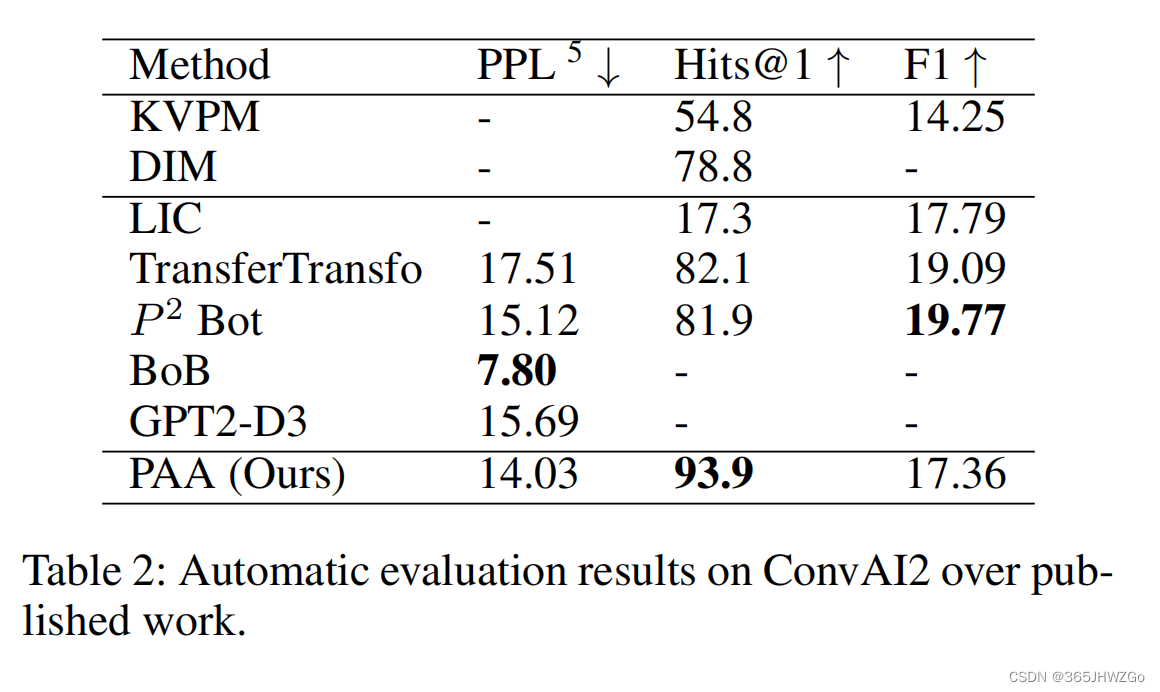
实验结果