
- 1python 庆余年2收视率数据分析与可视化_庆余年数据分析python
- 2Docker专题系列之一:docker在线安装+使用+常用命令
- 3【Git分布式版本控制系统之二】你还不会Github、Git分支命令?(1)
- 4Pytorch之Base_calcuate(卷积层,池化层,激活函数,全连接层,顺序容器(Sequential))_python torch. sequential全连接层
- 5python excel 饼图 简书_Python实现绘画多个饼图
- 6普通人如何仰望星空_平庸人类的观星方式
- 7Kafka快速入门(Kafka消费者)_kafka创建消费者组
- 8人工智能OCR领域安全应用措施_ocr技术 涉密信息流向控制
- 9web测试常用的用例及知识(全)_web体验测试用例是什么
- 10记录neo4j卸载之路(非教程)
2024年网络安全最新Flink Table API 与 SQL 编程整理(1),2024年最新2024最新网易网络安全面经
赞
踩
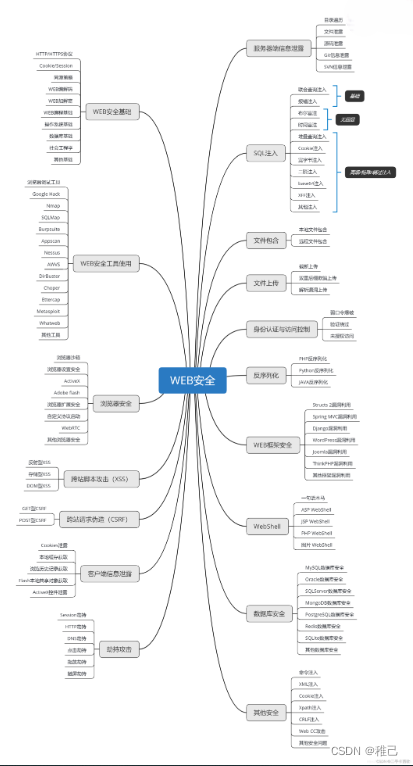
学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
tableEnv.fromDataStream(ecommerceLogDstream,'mid,'uid ......)
- 1
- 2
最后的动态表可以转换为流进行输出,如果不是简单的插入就使用toRetractStream
table.toAppendStream[(String,String)]
- 1
- 2
如何输出一个table
当我们获取到一个结构表的时候(table类型)执行insertInto目标表中:resultTable.insertInto("TargetTable");
【1】Table descriptor: 类似于注入,最终使用Sink进行输出,例如如下输出到targetTable中,主要是最后一段的区别。
tEnv
.connect(new FileSystem().path(path)).withFormat(new OldCsv().field("word", Types.STRING)
.lineDelimiter("\n")).withSchema(new Schema()
.field("word", Types.STRING))
.registerTableSink("targetTable");
- 1
- 2
- 3
- 4
- 5
- 6
【2】自定义一个 Table sink: 输出到自己的 sinkTable2注册进去。
TableSink csvSink = new CsvTableSink(path,new String[]{"word"},new TypeInformation[]{Types.STRING});
tEnv.registerTableSink("sinkTable2", csvSink);
- 1
- 2
- 3
【3】输出一个 DataStream: 例如下面产生一个RetractStream,对应要给Tuple2的联系。Boolean这行记录时add还是delete。如果使用了groupby,table 转化为流的时候只能使用toRetractStream。得到的第一个boolean型字段标识 true就是最新的数据(Insert),false表示过期老数据(Delete)。如果使用的api包括时间窗口,那么窗口的字段必须出现在groupBy中。
// emit the result table to a DataStream
DataStream<Tuple2<Boolean, Row>> stream = tableEnv.toRetractStream(resultTable, Row.class)
stream.filter(_._1).print()
- 1
- 2
- 3
- 4
案例代码:
package com.zzx.flink import java.util.Properties import com.alibaba.fastjson.JSON import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011 import org.apache.flink.table.api.java.Tumble import org.apache.flink.table.api.{StreamTableEnvironment, Table, TableEnvironment} object FlinkTableAndSql { def main(args: Array[String]): Unit = { //执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //设置 时间特定为 EventTime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //读取数据 MyKafkaConsumer 为自定义的 kafka 工具类,并传入 topic val dstream: DataStream[String] = env.addSource(MyKafkaConsumer.getConsumer("FLINKTABLE&SQL")) //将字符串转换为对象 val ecommerceLogDstream:DataStream[SensorReding] = dstream.map{ /\* 引入如下依赖 <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.36</version> </dependency>\*/ //将 String 转换为 SensorReding jsonString => JSON.parseObject(jsonString,classOf[SensorReding]) } //告知 watermark 和 evetTime如何提取 val ecommerceLogWithEventTimeDStream: DataStream[SensorReding] =ecommerceLogDstream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[SensorReding](Time.seconds(0)) { override def extractTimestamp(t: SensorReding): Long = { t.timestamp } }) //设置并行度 ecommerceLogDstream.setParallelism(1) //创建 Table 执行环境 val tableEnv: StreamTableEnvironment = TableEnvironment.getTableEnvironment(env) var ecommerceTable: Table = tableEnv.fromTableSource(ecommerceLogWithEventTimeDStream ,'mid,'uid,'ch,'ts.rowtime) //通过 table api进行操作 //每10秒统计一次各个渠道的个数 table api解决 //groupby window=滚动式窗口 用 eventtime 来确定开窗时间 val resultTalbe: Table = ecommerceTable.window(Tumble over 10000.millis on 'ts as 'tt).groupBy('ch,'tt).select('ch,'ch.count) var ecommerceTalbe: String = "xxx" //通过 SQL 执行 val resultSQLTable: Table = tableEnv.sqlQuery("select ch,count(ch) from "+ ecommerceTalbe +"group by ch,Tumble(ts,interval '10' SECOND") //把 Table 转化成流输出 //val appstoreDStream: DataStream[(String,String,Long)] = appstoreTable.toAppendStream[(String,String,Long)] val resultDStream: DataStream[(Boolean,(String,Long))] = resultSQLTable.toRetractStream[(String,Long)] //过滤 resultDStream.filter(_._1) env.execute() } } object MyKafkaConsumer { def getConsumer(sourceTopic: String): FlinkKafkaConsumer011[String] ={ val bootstrapServers = "hadoop1:9092" // kafkaConsumer 需要的配置参数 val props = new Properties // 定义kakfa 服务的地址,不需要将所有broker指定上 props.put("bootstrap.servers", bootstrapServers) // 制定consumer group props.put("group.id", "test") // 是否自动确认offset props.put("enable.auto.commit", "true") // 自动确认offset的时间间隔 props.put("auto.commit.interval.ms", "1000") // key的序列化类 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") // value的序列化类 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer") //从kafka读取数据,需要实现 SourceFunction 他给我们提供了一个 val consumer = new FlinkKafkaConsumer011[String](sourceTopic, new SimpleStringSchema, props) consumer } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
关于时间窗口
【1】用到时间窗口,必须提前声明时间字段,如果是processTime直接在创建动态表时进行追加就可以。如下的ps.proctime。
val ecommerceLogTable: Table = tableEnv
.fromDataStream( ecommerceLogWithEtDstream,
`mid,`uid,`appid,`area,`os,`ps.proctime )
- 1
- 2
- 3
- 4
【2】如果是EventTime要在创建动态表时声明。如下的ts.rowtime。
val ecommerceLogTable: Table = tableEnv
.fromDataStream( ecommerceLogWithEtDstream,
'mid,'uid,'appid,'area,'os,'ts.rowtime)
- 1
- 2
- 3
- 4
【3】滚动窗口可以使用Tumble over 10000.millis on来表示
val table: Table = ecommerceLogTable.filter("ch = 'appstore'")
.window(Tumble over 10000.millis on 'ts as 'tt)
.groupBy('ch,'tt)
.select("ch,ch.count")
- 1
- 2
- 3
- 4
- 5
如何查询一个 table
为了会有GroupedTable等,为了增加限制,写出正确的API。
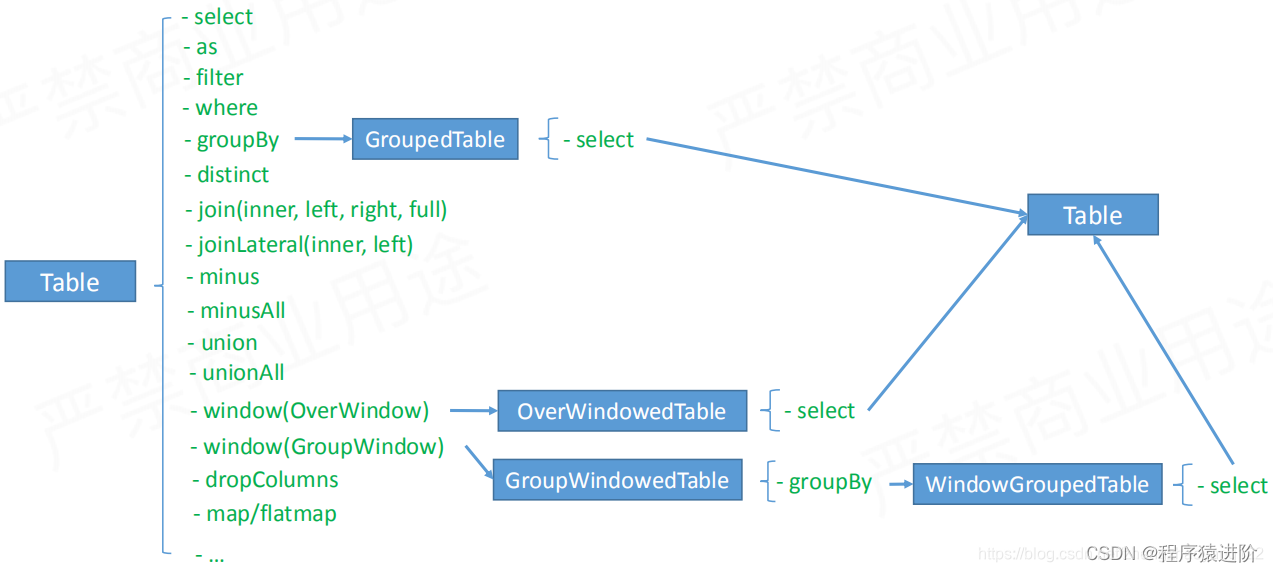
Table API 操作分类
1、与sql对齐的操作,select、as、filter等;
2、提升Table API易用性的操作;
——Columns Operation易用性: 假设有一张100列的表,我们需要去掉一列,需要怎么操作?第三个API可以帮你完成。我们先获取表中的所有Column,然后通过dropColumn去掉不需要的列即可。主要是一个Table上的算子。
| Operators | Examples |
|---|---|
| AddColumns | Table orders = tableEnv.scan(“Orders”); Table result = orders.addColumns(“concat(c,‘sunny’)as desc”); 添加新的列,要求是列名不能重复。 |
| addOrReplaceColumns | Table orders = tableEnv.scan(“Orders”); Table result = order.addOrReplaceColumns(“concat(c,‘sunny’) as desc”);添加列,如果存在则覆盖 |
| DropColumns | Table orders = tableEnv.scan(“Orders”); Table result = orders.dropColumns(“b c”); |
| RenameColumns | Table orders = tableEnv.scan(“Orders”); Table result = orders.RenameColumns("b as b2,c as c2);列重命名 |
——Columns Function易用性: 假设有一张表,我么需要获取第20-80列,该如何获取。类似一个函数,可以用在列选择的任何地方,例如:Table.select(withColumns(a,1 to 10))、GroupBy等等。
| 语法 | 描述 |
|---|---|
| withColumns(…) | 选择你指定的列 |
| withoutColumns(…) | 反选你指定的列 |

列的操作语法(建议): 如下,它们都是上层包含下层的关系。
columnOperation:
withColumns(columnExprs) / withoutColumns(columnExprs) #可以接收多个参数 columnExpr
columnExprs:
columnExpr [, columnExpr]* #可以分为如下三种情况
columnExpr:
columnRef | columnIndex to columnIndex | columnName to columnName #1 cloumn引用 2下标范围操作 3名字的范围操作
columnRef:
columnName(The field name that exists in the table) | columnIndex(a positive integer starting at 1)
Example: withColumns(a, b, 2 to 10, w to z)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Row based operation/Map operation易用性:
//方法签名: 接收一个 scalarFunction 参数,返回一个 Table def map(scalarFunction: Expression): Table class MyMap extends ScalarFunction { var param : String = "" //eval 方法接收一些输入 def eval([user defined inputs]): Row = { val result = new Row(3) // Business processing based on data and parameters // 根据数据和参数进行业务处理,返回最终结果 result } //指定结果对应的类型,例如这里 Row的类型,Row有三列 override def getResultType(signature: Array[Class[_]]): TypeInformation[_] = { Types.ROW(Types.STRING, Types.INT, Types.LONG) } } //使用 fun('e) 得到一个 Row 并定义名称 abc 然后获取 ac列 val res = tab .map(fun('e)).as('a, 'b, 'c) .select('a, 'c) //好处:当你的列很多的时候,并且每一类都需要返回一个结果的时候 table.select(udf1(), udf2(), udf3()….) VS table.map(udf())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Map是输入一条输出一条

FlatMap operation易用性:
//方法签名:出入一个tableFunction def flatMap(tableFunction: Expression): Table #tableFunction 实现的列子,返回一个 User类型,是一个 POJOs类型,Flink能够自动识别类型。 case class User(name: String, age: Int) class MyFlatMap extends TableFunction[User] { def eval([user defined inputs]): Unit = { for(..){ collect(User(name, age)) } } } //使用 val res = tab .flatMap(fun('e,'f)).as('name, 'age) .select('name, 'age) Benefit //好处 table.joinLateral(udtf) VS table.flatMap(udtf())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
FlatMap是输入一行输出多行

FlatAggregate operation功能性:
#方法签名:输入 tableAggregateFunction 与 AggregateFunction 很相似 def flatAggregate(tableAggregateFunction: Expression): FlatAggregateTable **先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7** **深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!** **因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**       **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!** **由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新** **[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)** 存中...(img-iIQ32zz6-1715459091977)] [外链图片转存中...(img-VXhzNem0-1715459091978)] [外链图片转存中...(img-yijkvvI2-1715459091978)] **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!** **由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新** **[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32

