
热门标签
热门文章
- 1使用easypoi完成word模板内容替换_easypoi替换word通配符
- 2wcf 基础连接已经关闭: 连接被意外关闭
- 3Android闹钟设置的解决方案_android 开启闹钟
- 4【建议收藏】数据库 SQL 入门——数据库与表操作(内附演示)_sql使用表
- 5FIFO原理_fifosize
- 6使用ESP8266连接阿里云并实现数据的收发(完整版)(不涉及单片机仅为连接单片机前的调试工作)_esp8266 怎么接收数据
- 7NoSQL非关系型数据库概述根据发展时间详细介绍_非关系型nosql数据库
- 8【Linux】深入解析动静态库:原理、制作、使用与动态链接机制
- 9课后答案︻︼─一大收集_清华数字电路与逻辑设计第二版答案
- 10git拉取和提交代码具体操作流程_使用git开发时在开发完一个功能后是先拉取代码吗
当前位置: article > 正文
【大数据基础实践】(六)数据仓库Hive的基本操作_熟悉hive的基本操作_hive数仓数据执行
作者:繁依Fanyi0 | 2024-06-07 16:05:33
赞
踩
hive数仓数据执行
2.3 生态系统
- Hive依赖于HDFS 存储数据、
- Hive依赖于MapReduce 处理数据
- 在某些场景下Pig可以作为Hive的替代工具
- HBase 提供数据的实时访问
- Pig主要用于数据仓库的ETL环节
- Hive主要用于数据仓库海量数据的批处理分析

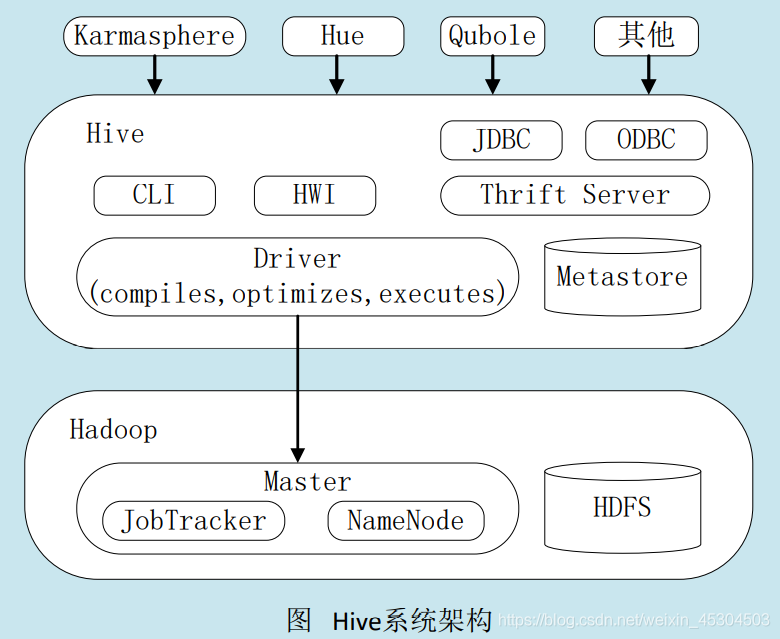
3. Hive系统架构
- 用户接口模块。包括CLI、HWI、JDBC、ODBC、Thrift Server
- 驱动模块(Driver)。包括编译器、优化器、执行器等,负责把HiveQL语句转换成一系列MapReduce作业
- 元数据存储模块(Metastore)。是一个独立的关系型数据库(自带derby数据库,或MySQL数据库)
4. HQL转成MapReduce作业的原理
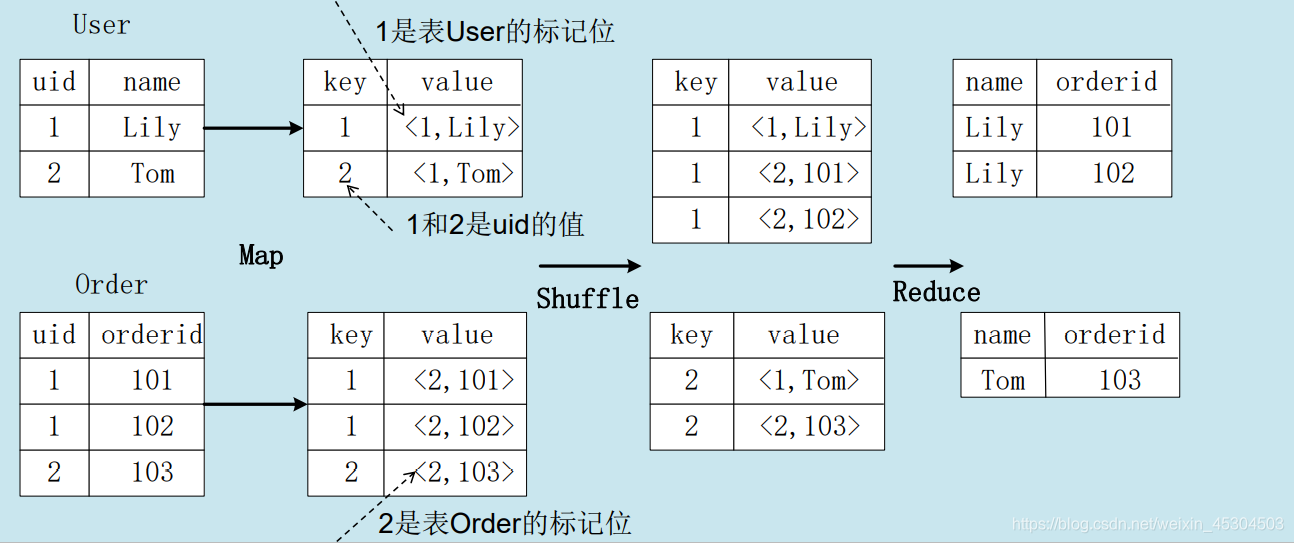
4.1 join的实现原理
select name, orderid from user join order on user.uid=order.uid;
- 1
- 2
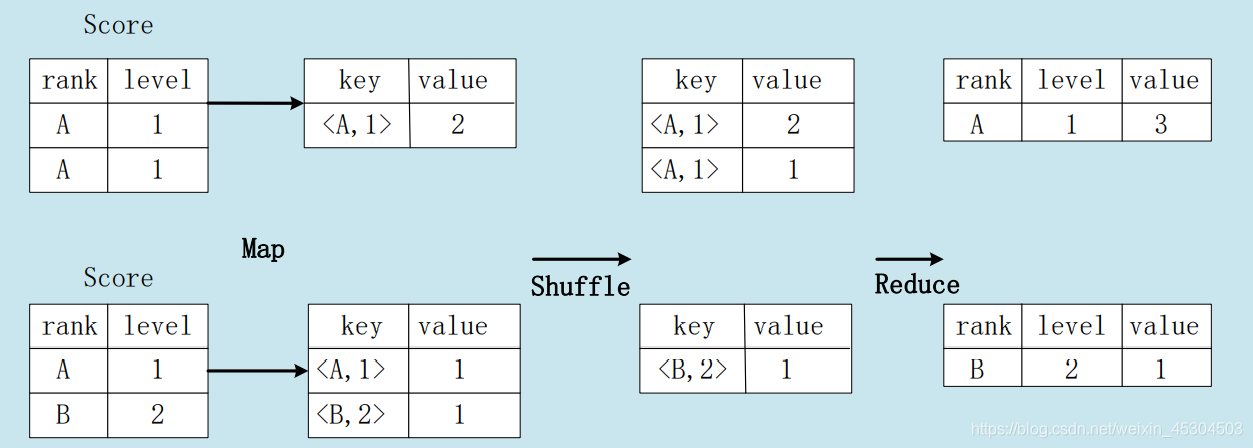
4.2 group by的实现原理
存在一个分组(Group By)操作,其功能是把表Score的不同片段按照rank和level的组合值进行合并,计算不同rank和level的组合值分别有几条记录:
select rank, level ,count(\*) as value from score group by rank, level
- 1
- 2
5. 实验练习
5.1 环境配置
5.1.1 HIVE
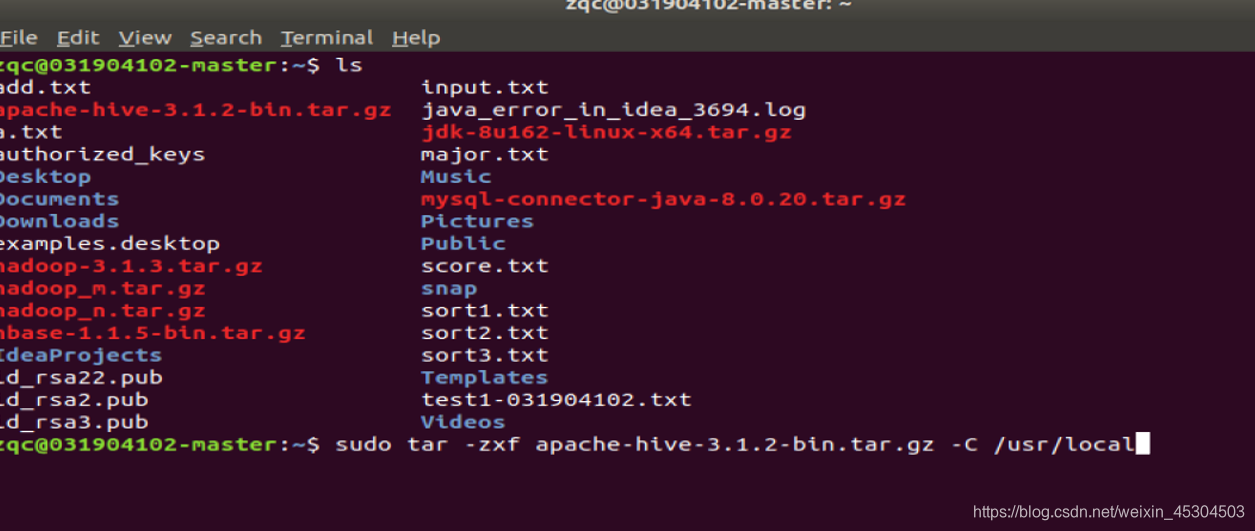
将Hive解压到/usr/local中

更改名字

更改hive目录所有者和所在用户组

环境配置

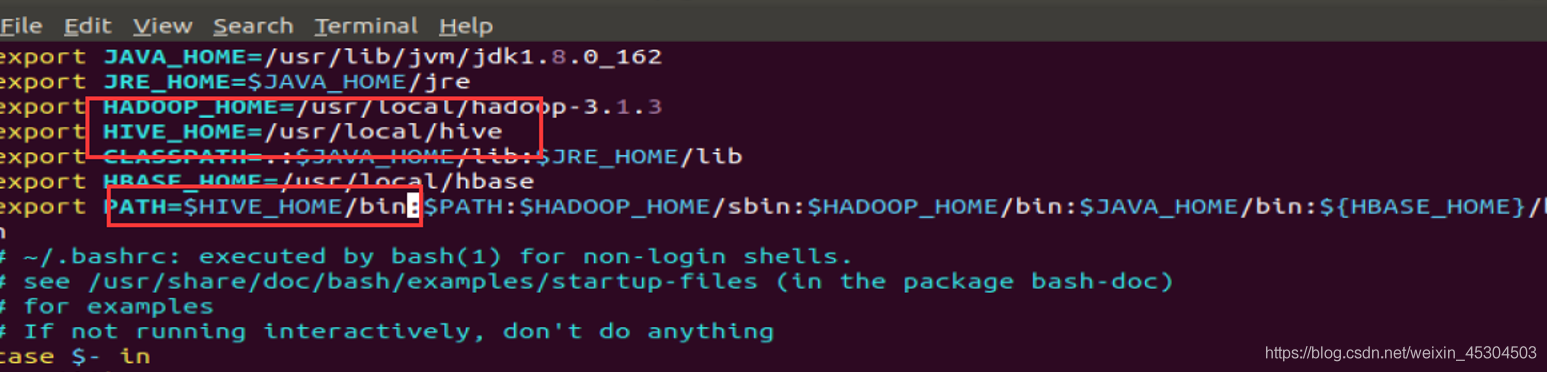
使环境生效

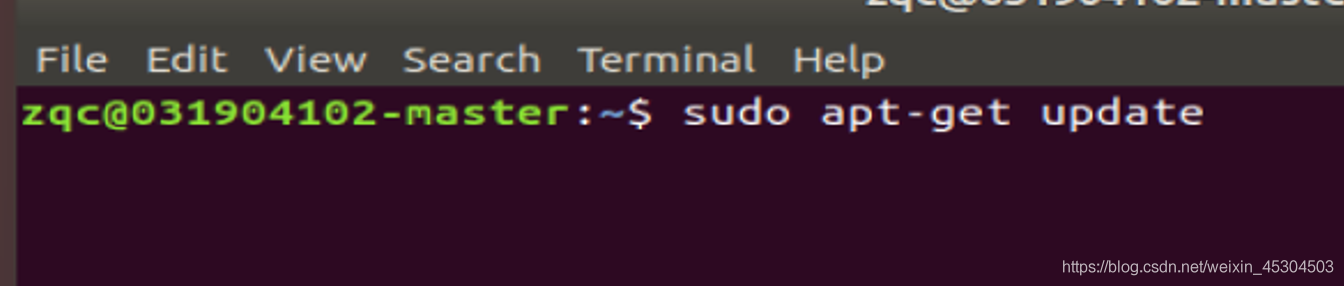
5.1.2 MYSQL
更新软件源
推荐阅读
相关标签

