
热门标签
热门文章
- 1建议收藏,详解Python实现进阶版人脸识别_python 人脸识别
- 2xlabel()函数,设置x坐标轴的数值显示范围_xlabel yy mm date
- 3python len函数源码_Python通过len函数返回对象长度
- 4AndroidStudio报错:Entry name ‘META-INF/androidx.legacy_legacy-support-core-utils.version‘ collided
- 5spring boot 2.7 -> 3.0升级指南_springboot2.7升级3
- 6uni-app组件生命周期_uniapp 组件生命
- 7如何在Git中更改文件名的大小写_git 大小写
- 8go的反射和断言
- 9mysql行号_mysql改变当前行号
- 10架构学习资料精选
当前位置: article > 正文
知识增强的NLP预训练模型【将知识图谱中的三元组向量引入到预训练模型中】_预训练模型信息增强
作者:繁依Fanyi0 | 2024-06-08 08:57:00
赞
踩
预训练模型信息增强
将知识引入到依靠数据驱动的人工智能模型中是实现人机混合智能的一种重要途径。
当前以Bert为代表的预训练模型在自然语言处理领域取得了显著的成功,但是由于预训练模型大多是在大规模非结构化的语料数据上训练出来的,因此可以通过引入外部知识在一定程度上弥补其在确定性和可解释性上的缺陷。
该文针对预训练词嵌入和预训练上下文编码器两个预训练模型的发展阶段,分析了它们的特点和缺陷,阐述了知识增强的相关概念。
提出了预训练词嵌入知识增强的分类方法,将其分为四类:
- 词嵌入改造
- 层次化编解码过程
- 优化注意力
- 引入知识记忆
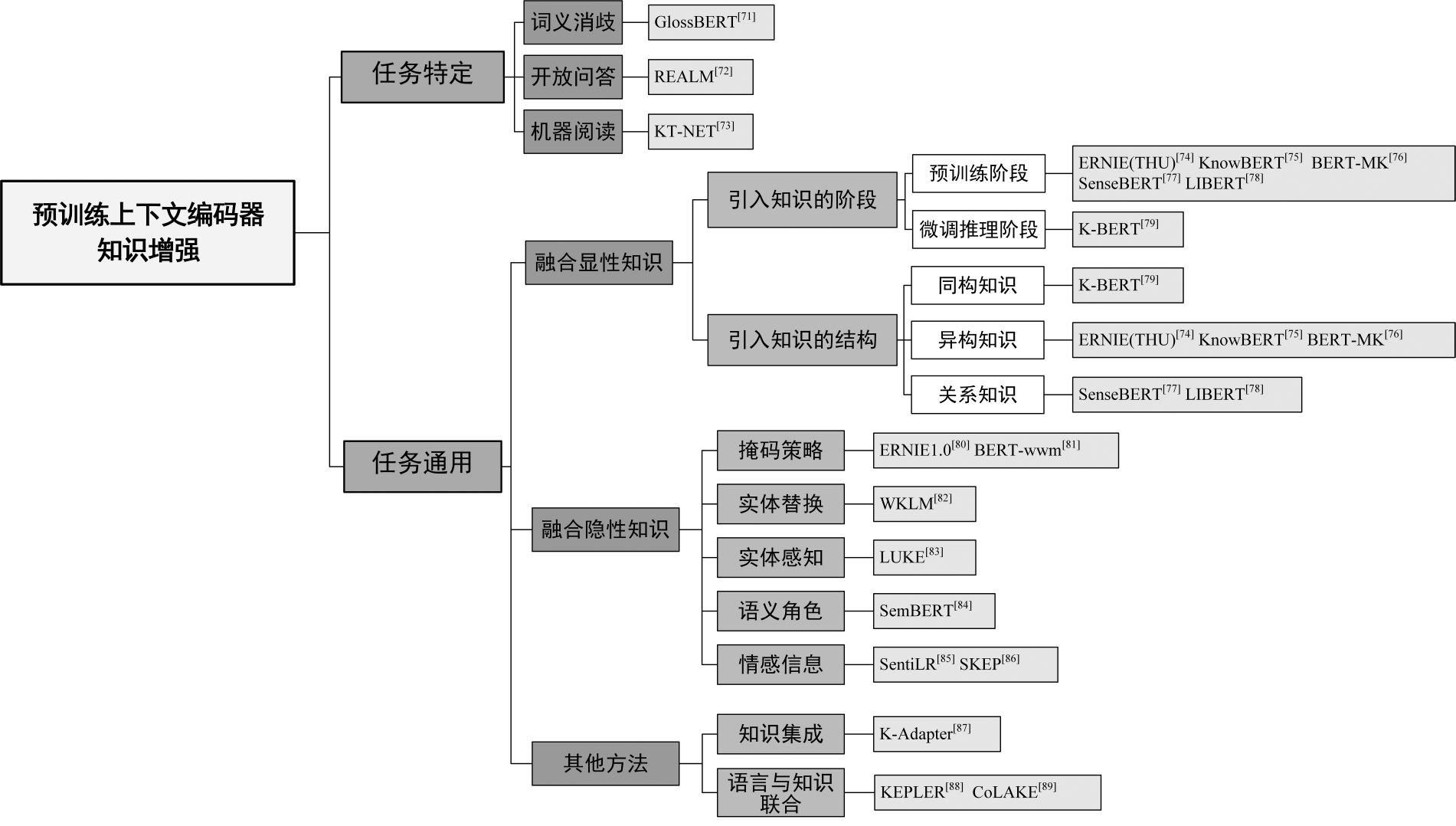
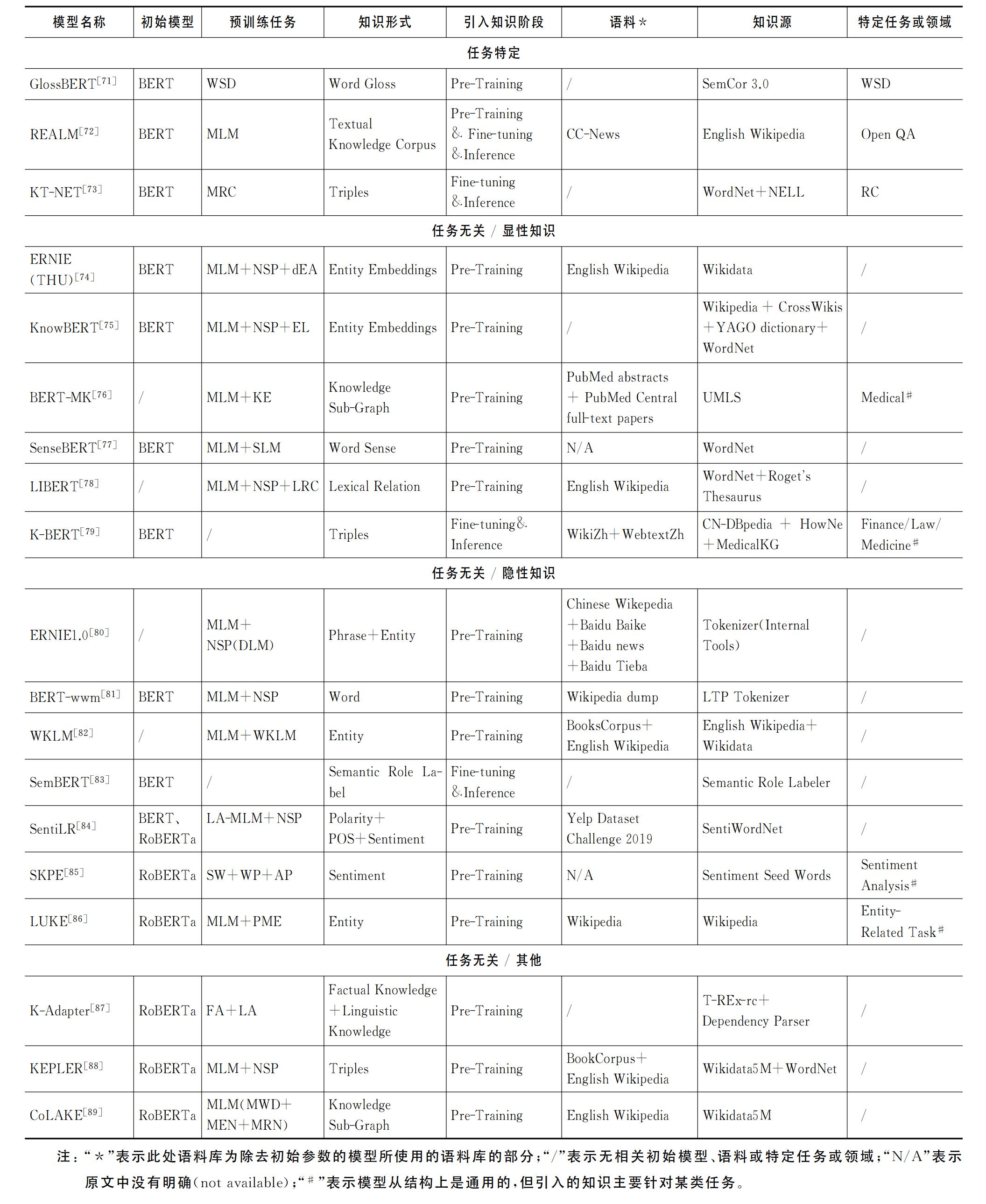
将预训练上下文编码器的知识增强方法分为两大类:
- 任务特定
- 任务通用
并根据引入知识的显隐性对其中任务通用的知识增强方法进行了进一步的细分。
该文通过分析预训练模型知识增强方法的类型和特点,为实现人机混合的人工智能提供了模式和算法上的参考依据。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/689194
推荐阅读
相关标签

