- 1会Python的大学生,毕业后有多赚?_只会python大学毕业
- 2Vue - 实现文件导出&文件保存下载_vue 下载文件流
- 3【C++】文件IO流_c++ 文件io
- 4PIVOT函数与UNPIVOT函数的运用
- 5ubuntu_qtcreator安装_qtcreater安装 源
- 6关系型数据库, NoSQL 数据库, NewSQL 数据库权威整理_对比分析关系数据库,newsql数据库,nosql数据库的联系
- 7算法与数据结构-堆的基本操作C语言实现_堆及其操作 c语言
- 8开源协议的对比和商业上的安全使用_sspl特点
- 9香橙派Kunpeng Pro开箱测评:入门体验使用与基础测试_香橙派 面试
- 101+x_大数据应用开发(python)职业技能(中级)_1+x证书泰迪大数据应用开发(python)职业技能等级证书考什么
轴承故障诊断 (12)基于交叉注意力特征融合的VMD+CNN-BiLSTM-CrossAttention故障识别模型_vmd cnn bilstm
赞
踩
目录
3 基于VMD+CNN-BiLSTM-CrossAttention的轴承故障诊断分类
3.1 定义VMD+CNN-BiLSTM-CrossAttention分类网络模型

创新点:利用交叉注意力机制融合模型!
往期精彩内容:
Python-凯斯西储大学(CWRU)轴承数据解读与分类处理
Python轴承故障诊断 (二)连续小波变换CWT_pyts 小波变换 故障-CSDN博客
Python轴承故障诊断 (三)经验模态分解EMD_轴承诊断 pytorch-CSDN博客
Pytorch-LSTM轴承故障一维信号分类(一)_cwru数据集pytorch训练-CSDN博客
Pytorch-CNN轴承故障一维信号分类(二)-CSDN博客
Pytorch-Transformer轴承故障一维信号分类(三)-CSDN博客
Python轴承故障诊断 (四)基于EMD-CNN的故障分类-CSDN博客
Python轴承故障诊断 (五)基于EMD-LSTM的故障分类-CSDN博客
Python轴承故障诊断 (六)基于EMD-Transformer的故障分类-CSDN博客
Python轴承故障诊断 (七)基于EMD-CNN-LSTM的故障分类-CSDN博客
Python轴承故障诊断 (八)基于EMD-CNN-GRU并行模型的故障分类-CSDN博客
基于FFT + CNN - BiGRU-Attention 时域、频域特征注意力融合的轴承故障识别模型-CSDN博客
基于FFT + CNN - Transformer 时域、频域特征融合的轴承故障识别模型-CSDN博客
大甩卖-(CWRU)轴承故障诊数据集和代码全家桶-CSDN博客
Python轴承故障诊断 (九)基于VMD+CNN-BiLSTM的故障分类-CSDN博客
Python轴承故障诊断 (十)基于VMD+CNN-Transfromer的故障分类-CSDN博客
Python轴承故障诊断 (11)基于VMD+CNN-BiGRU-Attenion的故障分类-CSDN博客
交叉注意力融合时域、频域特征的FFT + CNN -BiLSTM-CrossAttention轴承故障识别模型-CSDN博客
交叉注意力融合时域、频域特征的FFT + CNN-Transformer-CrossAttention轴承故障识别模型-CSDN博客
前言
本文基于凯斯西储大学(CWRU)轴承数据,进行变分模态分解VMD的介绍与数据预处理,最后通过Python实现基于交叉注意力CNN-BiLSTM-CrossAttention的时空特征融合模型对故障数据的分类。凯斯西储大学轴承数据的详细介绍可以参考下文:
Python-凯斯西储大学(CWRU)轴承数据解读与分类处理_cwru数据集时域图-CSDN博客
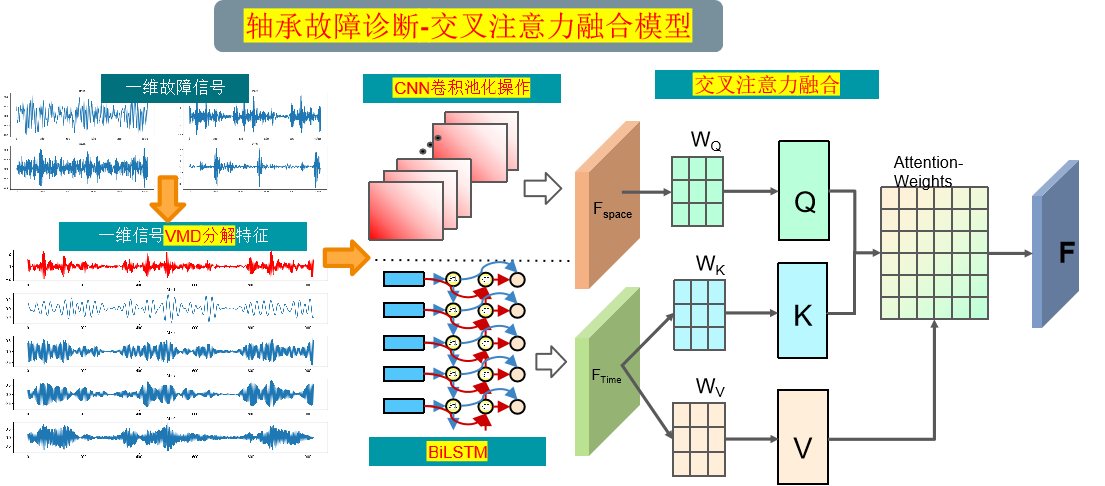
模型整体结构
模型整体结构如下所示:
-
VMD 分解:
-
输入:轴承振动信号
-
操作:通过VMD技术将原始信号分解成多个本征模态函数(IMF)
-
输出:每个IMF表示不同频率范围内的振动成分
-
CNN 空间特征提取:
-
输入:VMD分解得到的IMFs
-
操作:对每个IMF进行卷积和池化操作,提取空间特征
-
输出:卷积池化后的特征表示,用于捕获不同频率下的振动空间特征
-
BiLSTM 时序特征提取:
-
输入:VMD分解得到的IMFs
-
操作:双向LSTM网络学习序列信息,关注重要的时序特征
-
输出:经BiLSTM处理后的时序特征表示,具有更好的故障信号时序建模能力
-
交叉注意力机制特征融合:
-
输入:CNN提取的空间特征,BiLSTM提取的时序特征
-
交叉注意力机制:使用交叉注意力机制融合时域和频域的特征。可以通过计算注意力权重,使得模型更关注重要的特征,提高模型性能和泛化能力
1 变分模态分解VMD的Python示例
第一步,Python 中 VMD包的下载安装:
- # 下载
- pip install vmdpy
-
- # 导入
- from vmdpy import VMD
第二步,导入相关包进行分解
- import numpy as np
- import matplotlib.pyplot as plt
- from vmdpy import VMD
-
- # -----测试信号及其参数--start-------------
- t = np.linspace(0, 1, 1000)
- signal = np.sin(2 * np.pi * 5 * t) + np.sin(2 * np.pi * 20 * t)
-
- T = len(signal)
- fs = 1/T
- t = np.arange(1,T+1)/T
-
- # alpha 惩罚系数;带宽限制经验取值为抽样点长度1.5-2.0倍.
- # 惩罚系数越小,各IMF分量的带宽越大,过大的带宽会使得某些分量包含其他分量言号;
- alpha = 2000
-
- #噪声容限,一般取 0, 即允许重构后的信号与原始信号有差别。
- tau = 0
- #模态数量 分解模态(IMF)个数
- K = 5
-
- #DC 合成信号若无常量,取值为 0;若含常量,则其取值为 1
- # DC 若为0则让第一个IMF为直流分量/趋势向量
- DC = 0
-
- #初始化ω值,当初始化为 1 时,均匀分布产生的随机数
- # init 指每个IMF的中心频率进行初始化。当初始化为1时,进行均匀初始化。
- init = 1
-
- #控制误差大小常量,决定精度与迭代次数
- tol = 1e-7
- # -----测试信号及其参数--end----------
-
- # Apply VMD
- # 输出U是各个IMF分量,u_hat是各IMF的频谱,omega为各IMF的中心频率
- u, u_hat, omega= VMD(signal, alpha, tau, K, DC, init, tol)
-
- #得到中心频率的数值
- print(omega[-1])
-
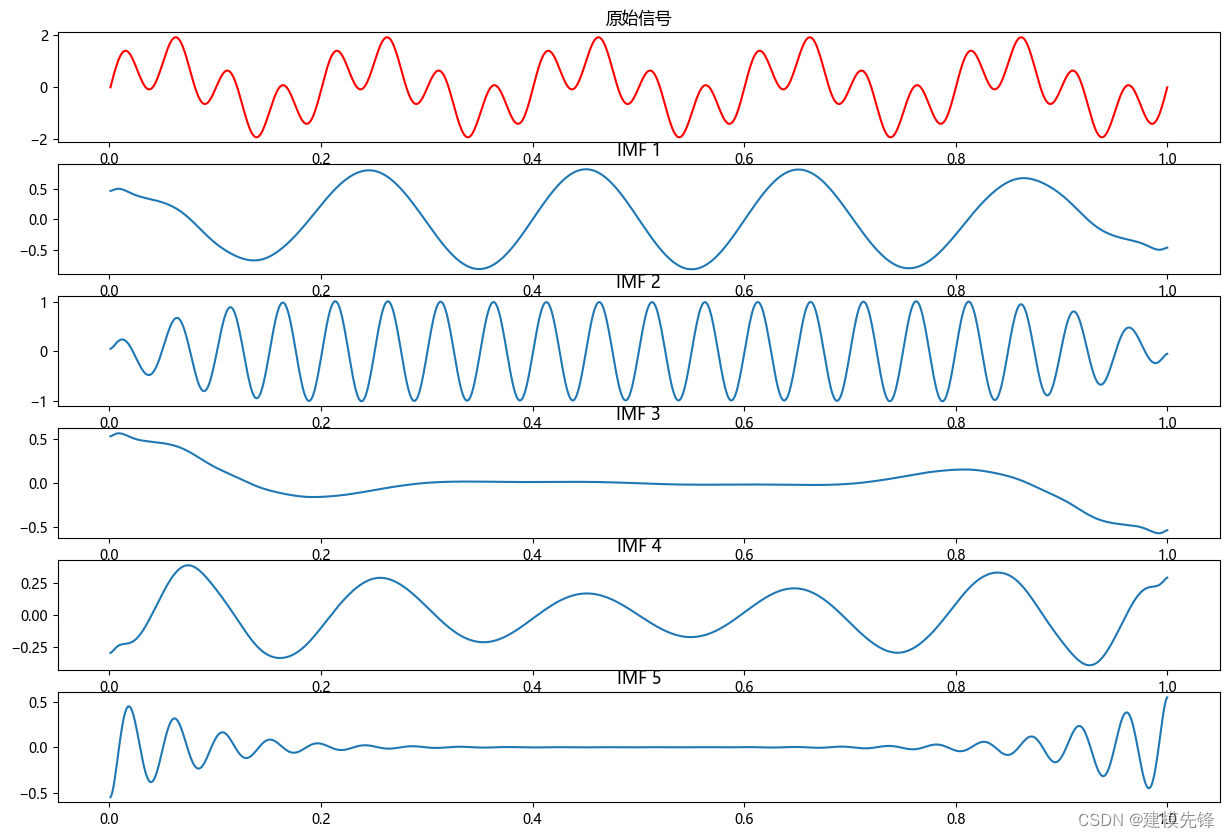
- # Plot the original signal and decomposed modes
- plt.figure(figsize=(15,10))
- plt.subplot(K+1, 1, 1)
- plt.plot(t, signal, 'r')
- plt.title("原始信号")
-
- for num in range(K):
- plt.subplot(K+1, 1, num+2)
- plt.plot(t, u[num,:])
- plt.title("IMF "+str(num+1))
-
- plt.show()

2 轴承故障数据的预处理
2.1 导入数据
参考之前的文章,进行故障10分类的预处理,凯斯西储大学轴承数据10分类数据集:
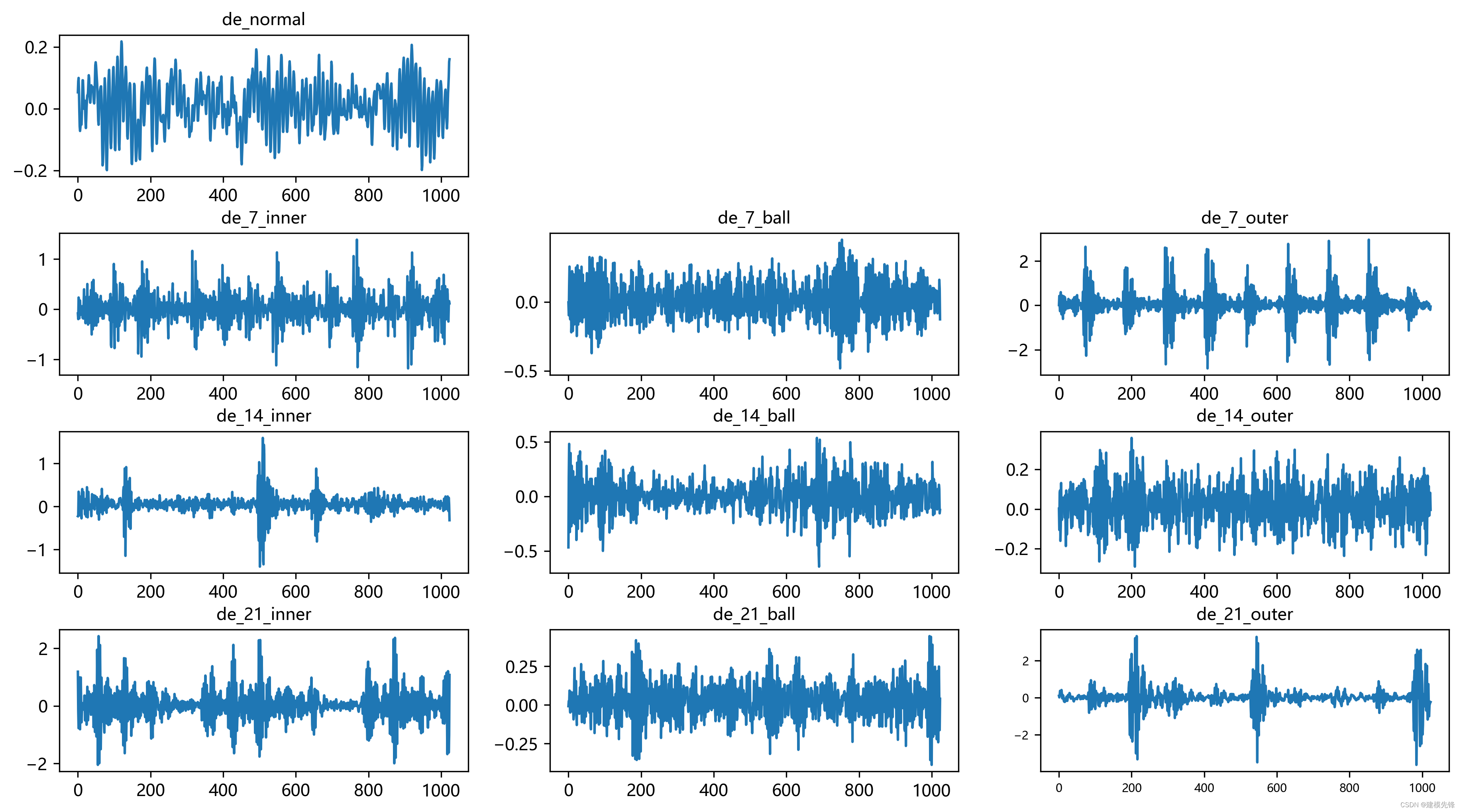
train_set、val_set、test_set 均为按照7:2:1划分训练集、验证集、测试集,最后保存数据
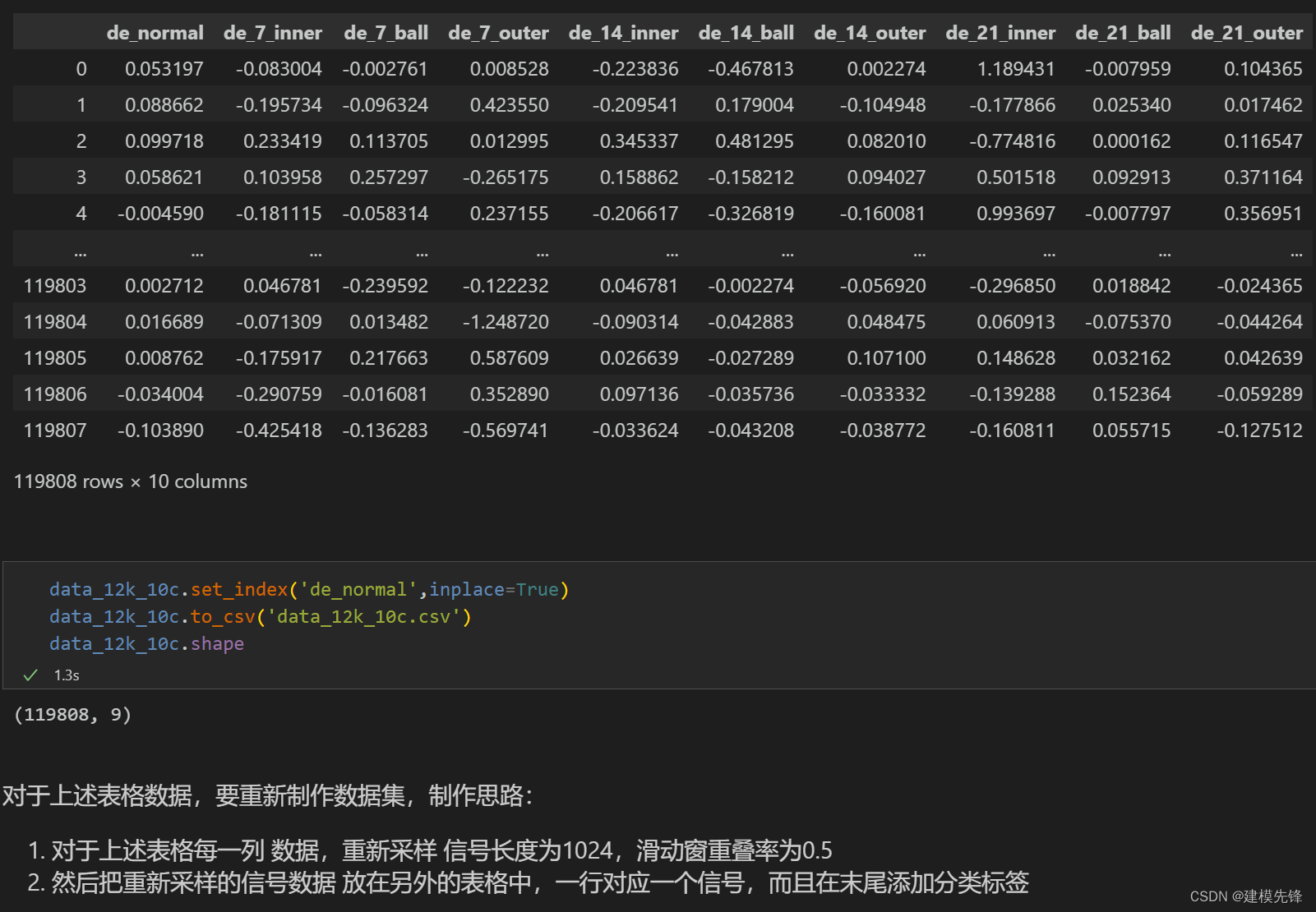
上图是数据的读取形式以及预处理思路
2.2 故障VMD分解可视化
第一步, 模态选取
根据不同K值条件下, 观察中心频率,选定K值;从K=4开始出现中心频率相近的模态,出现过分解,故模态数 K 选为4。
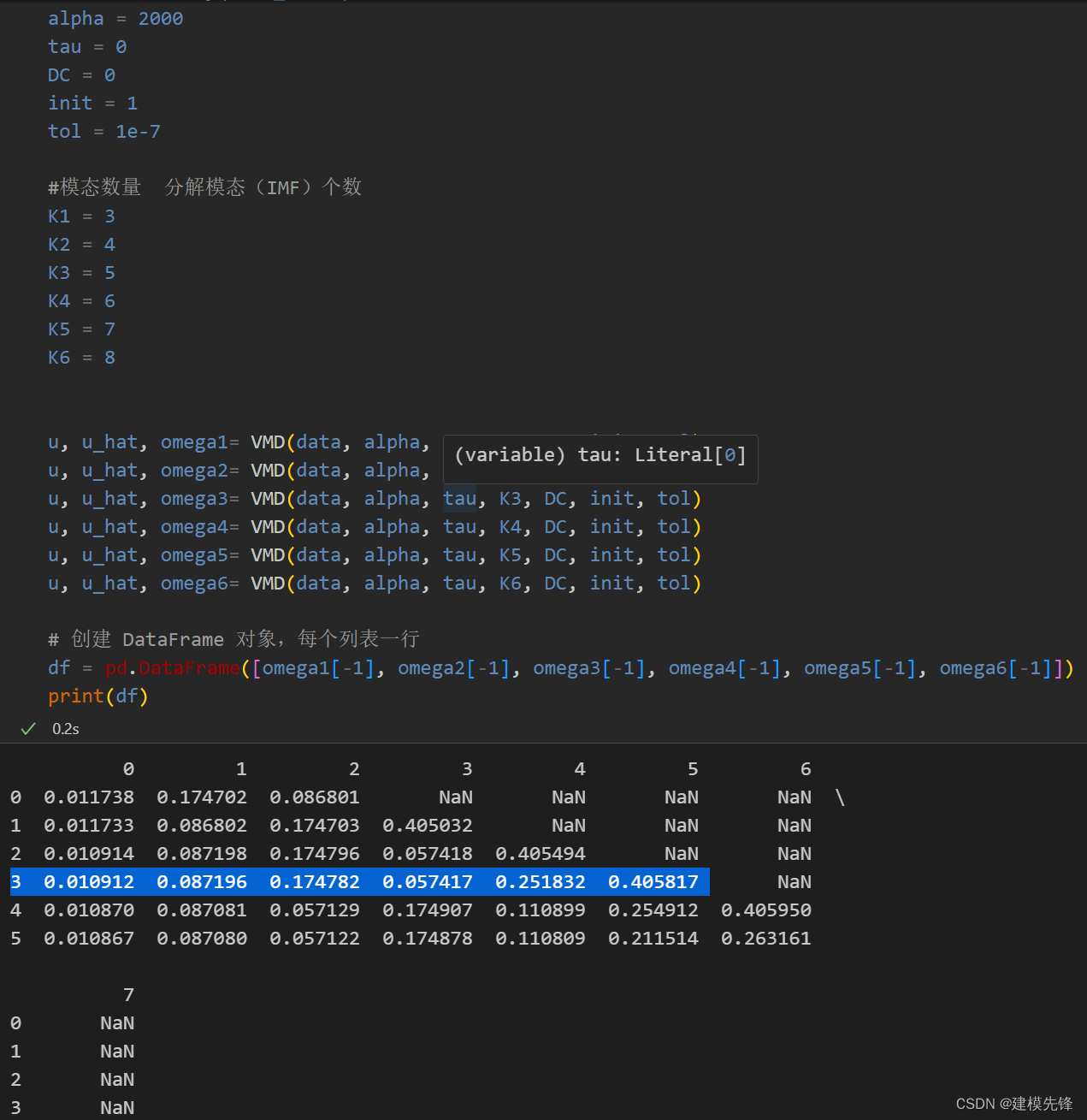
第二步,故障VMD分解可视化
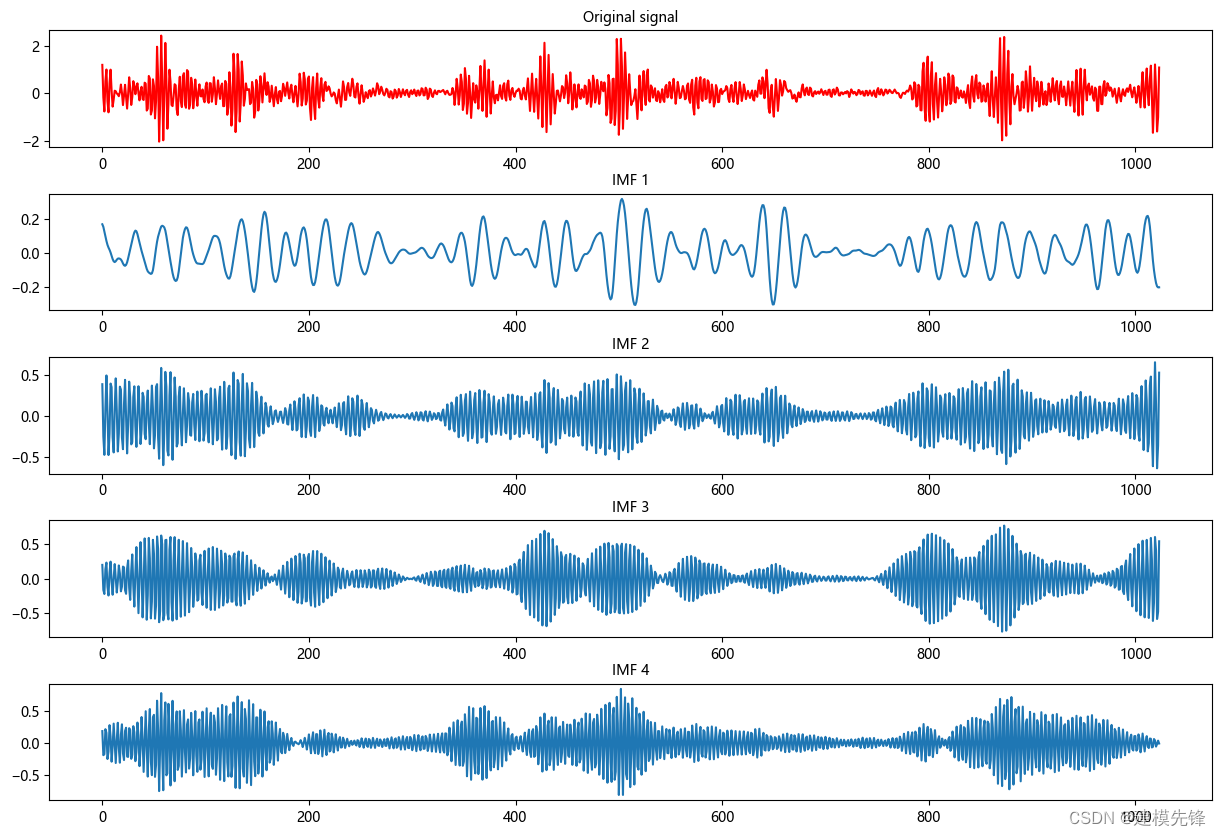
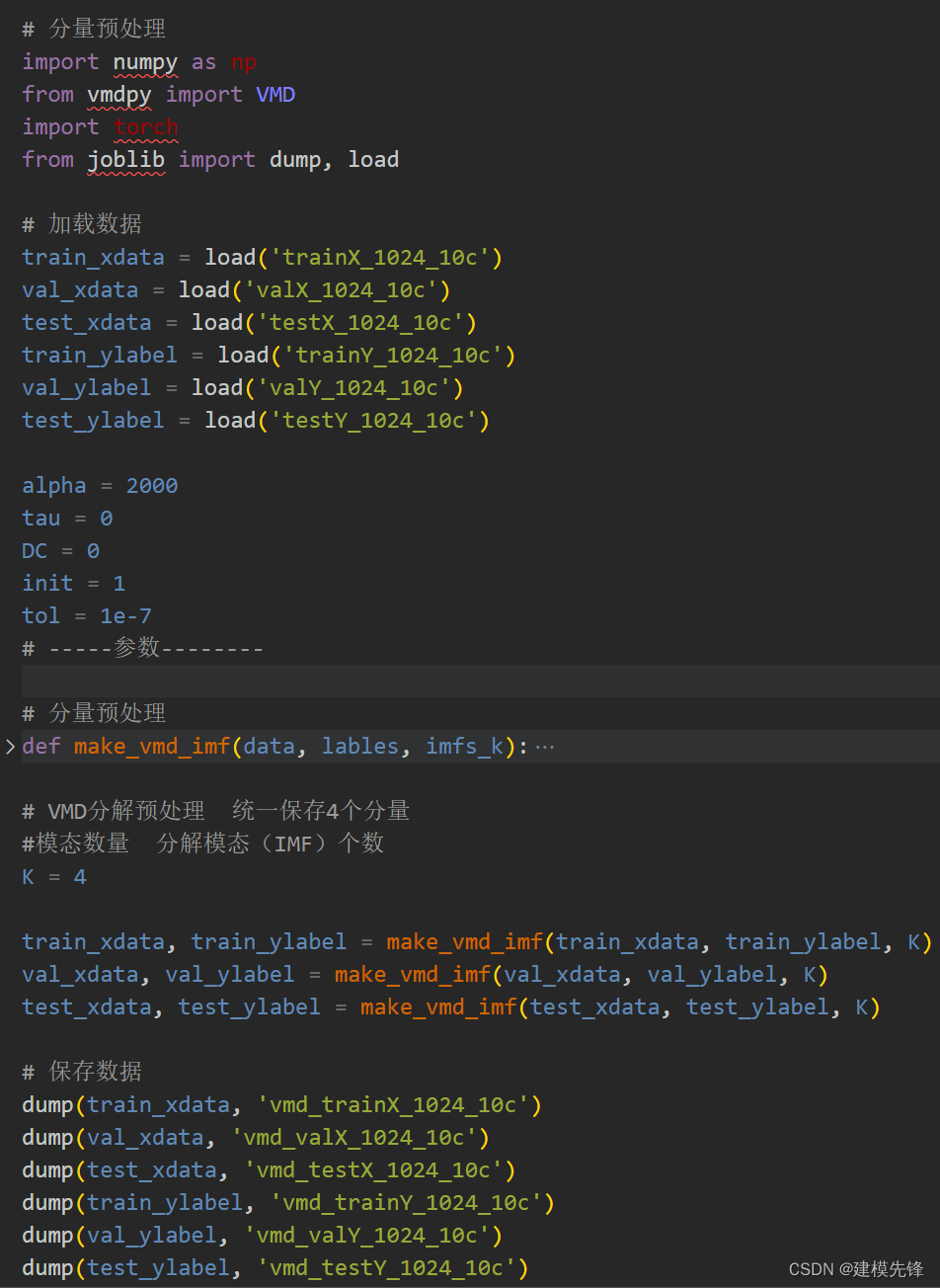
2.3 故障数据的VMD分解预处理
3 交叉注意力机制
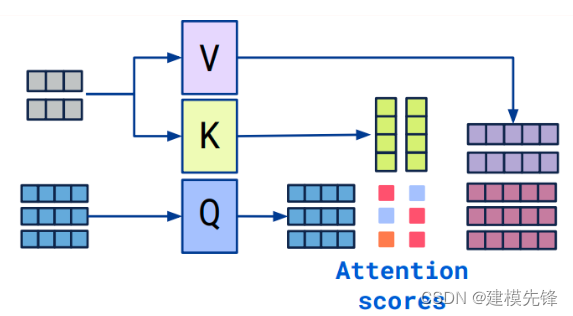
3.1 Cross attention概念
-
Transformer架构中混合两种不同嵌入序列的注意机制
-
两个序列必须具有相同的维度
-
两个序列可以是不同的模式形态(如:文本、声音、图像)
-
一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的K&V
3.2 Cross-attention算法
-
拥有两个序列S1、S2
-
计算S1的K、V
-
计算S2的Q
-
根据K和Q计算注意力矩阵
-
将V应用于注意力矩阵
-
输出的序列长度与S2一致
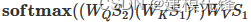
在融合过程中,我们将经过CNN卷积池化操作的空间特征作为查询序列,BiLSTM输出的时序特征作为键值对序列。通过计算查询序列与键值对序列之间的注意力权重,我们可以对不同特征之间的关联程度进行建模。
3 基于VMD+CNN-BiLSTM-CrossAttention的轴承故障诊断分类
下面基于VMD分解后的轴承故障数据,先把分解的分量通过CNN进行卷积池化操作提取信号的空间特征,然后同时把分量送入BiLSTM层提取时序特征,使用交叉注意力机制融合时域和频域的特征, 对特征进行增强,实现CNN-BiLSTM-CrossAttention信号的分类方法。
3.1 定义VMD+CNN-BiLSTM-CrossAttention分类网络模型
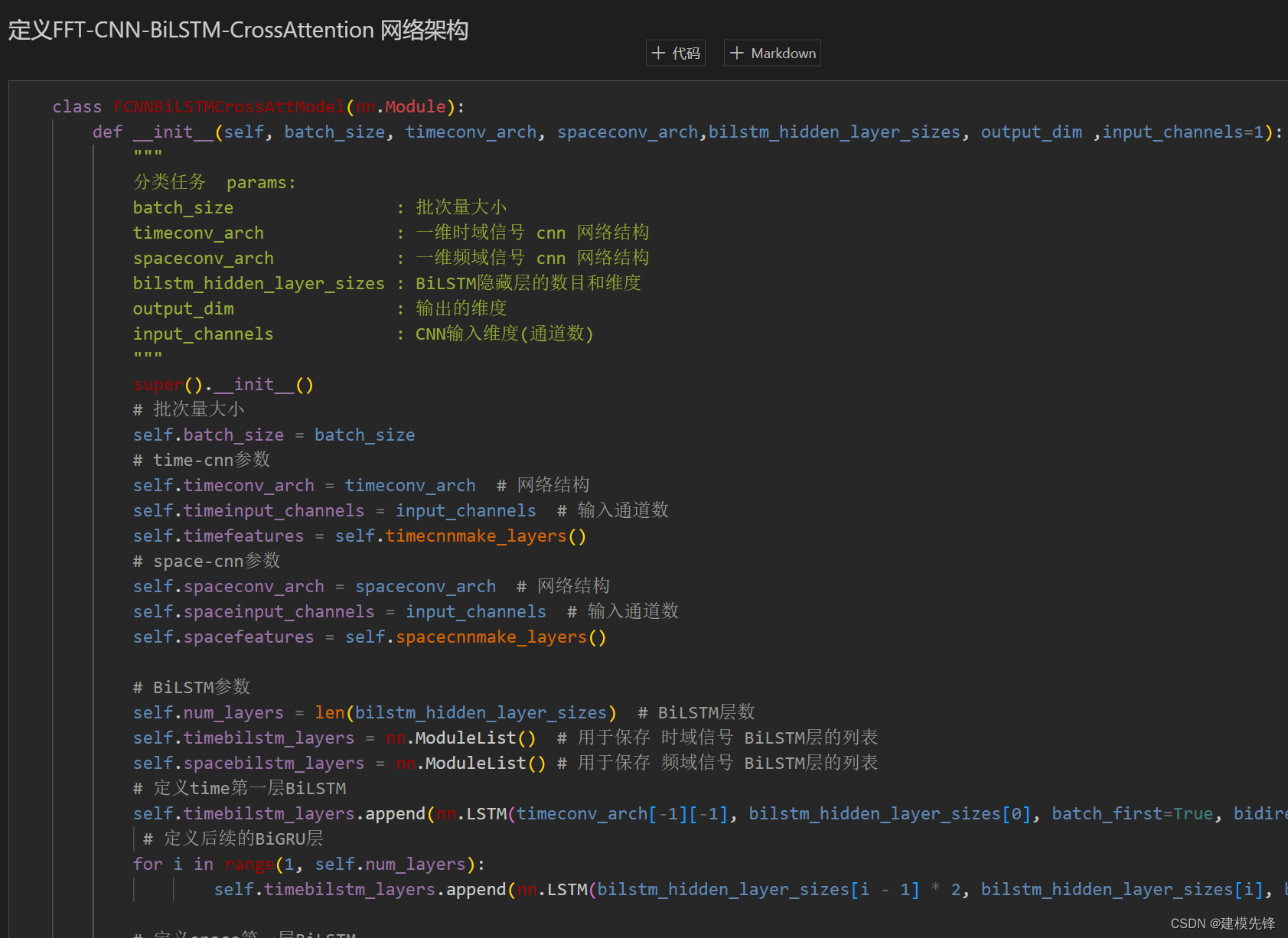
3.2 设置参数,训练模型
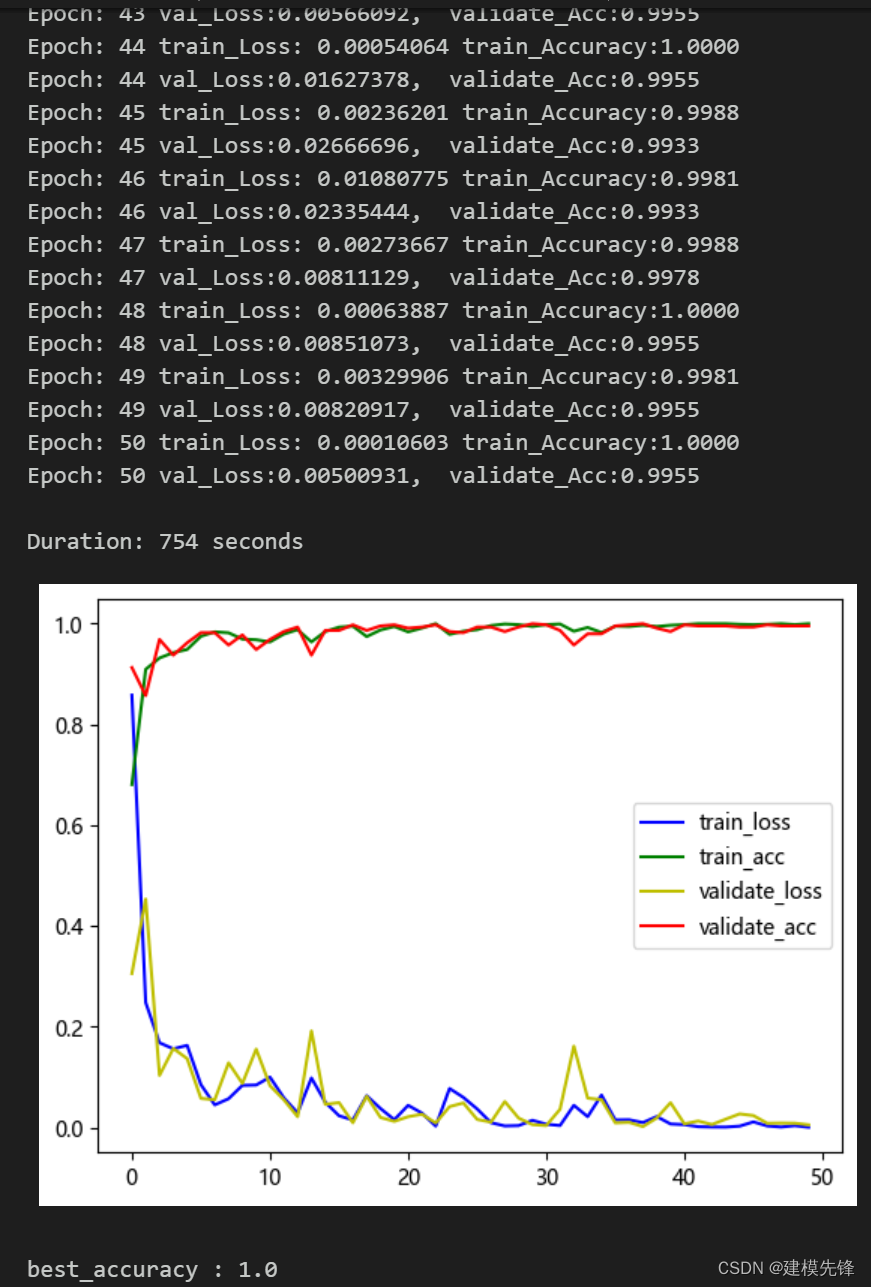
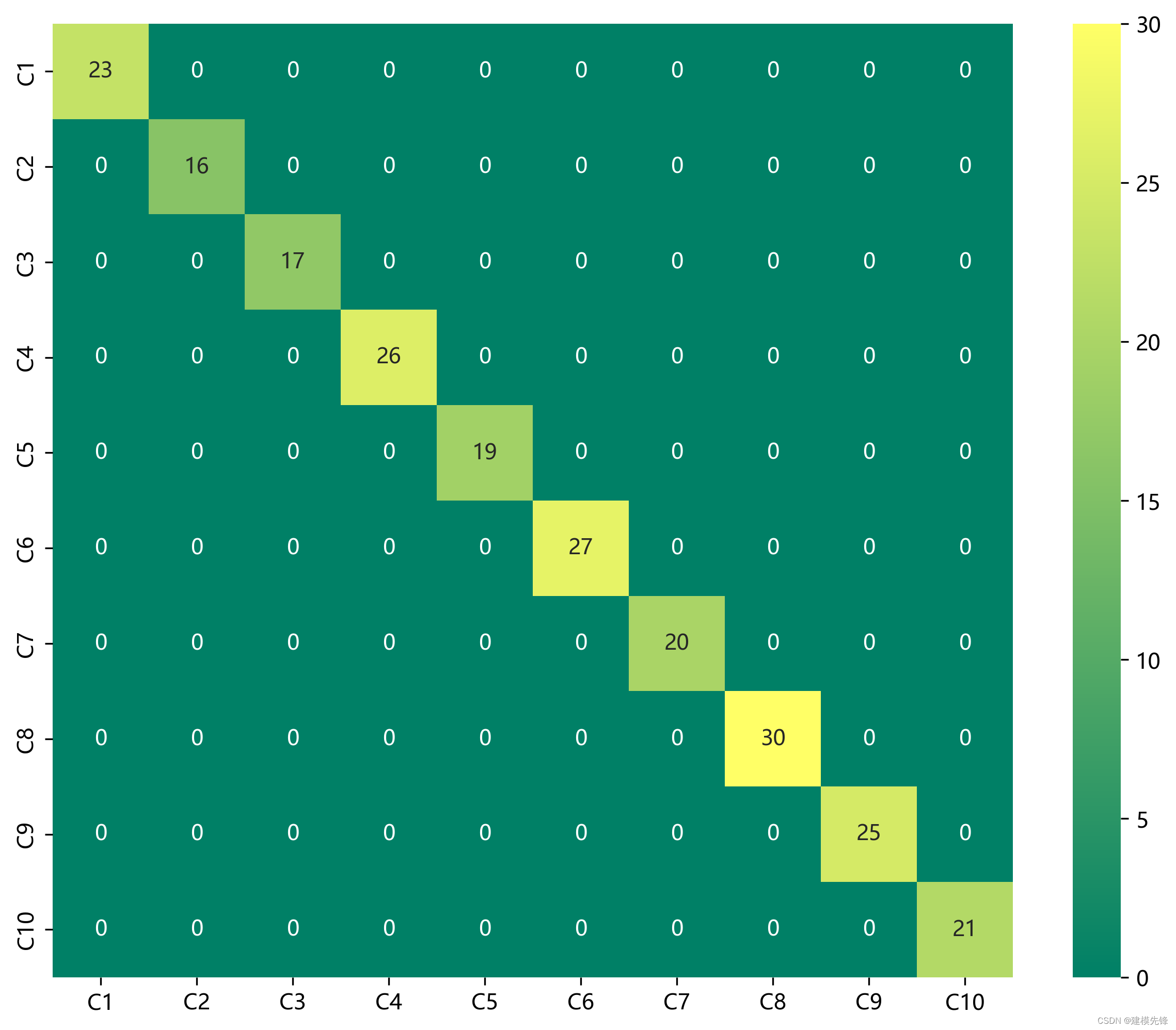
50个epoch,准确率将近98%,用VMD+CNN-BiLSTM-CrossAttention网络分类效果显著,模型能够充分提取轴承故障信号的空间和时序特征,收敛速度快,性能优越,精度高,交叉注意力机制能够对不同特征之间的关联程度进行建模,从故障信号频域、时域特征中属于提取出对模型识别重要的特征,效果明显,继续调参可以进一步提高分类准确率。
注意调整参数:
-
可以适当增加CNN层数和隐藏层的维度,微调学习率;
-
调整BiLSTM层数和维度数,增加更多的 epoch (注意防止过拟合)
-
可以改变一维信号堆叠的形状(设置合适的长度和维度)
3.3 模型评估
准确率、精确率、召回率、F1 Score

故障十分类混淆矩阵:
代码、数据如下:
对数据集和代码感兴趣的,可以关注最后一行
- # 加载数据
- import torch
- from joblib import dump, load
- import torch.utils.data as Data
- import numpy as np
- import pandas as pd
- import torch
- import torch.nn as nn
- # 参数与配置
- torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
- #代码和数据集:https://mbd.pub/o/bread/ZZqXmp9x