
- 1网络编程-TCP并发服务器-多点通信-域套接字
- 2华为交换机端口隔离看这一篇文章就行了
- 3算力单位的解释_100p算力是多少
- 4计算机的CPU和GPU的区别,GPU与CPU的区别
- 5Android安卓进程保活(一)1像素且透明Activity,吃透这份Android高级工程师面试497题解析_android 1像素透明activity
- 6PySpark:DataFrame及其常用列操作_pyspark dataframe
- 7app保活面试题,最新手淘Android高级面试题及答案_app产品工程师面试题
- 8一文读懂Stable Diffusion 论文原理+代码超详细解读_stable diffusion论文
- 9FPGA实现调幅_fpga调幅
- 10Hadoop重启失败问题集合_hadoop重启命令不起作用
推荐系统中常用的embedding方法_大语言模型embedding步骤
赞
踩
简单来说,Embedding就是用一个低维的向量表示一个物体,可以是一个词,或是一个商品,或是一个电影等等。
在传统机器学习模型构建过程中,经常使用one hot encoding对离散特征,特别是ID类特征进行编码,但由于one hot encoding的维度等于特征的总数,比如阿里的商品one hot encoding的维度就至少是千万量级的,而且有的特征还会增量更新,所以这样的编码方式得到的特征向量是非常稀疏的,甚至用multi hot encoding对ID特征编码也会是一个非常稀疏的向量。
如果深度学习模型输入大量的稀疏特征,高维稀疏特征易引发“维度灾难”,使空间距离很难有效衡量,另外高维经常使参数数量变得非常多,计算复杂度增加,也容易导致过拟合;稀疏容易造成梯度消失,导致无法有效完成参数学习。因此通过Embedding将低维向量对物体进行编码喂给DNN很好的解决了前面的问题。
Embedding特点:
表达能力丰富
-
- 相似的特征,embedding相似度也高
- embedding数学运算,woman + king - man = queen
应用方便
-
- 相比于高维稀疏特征,embedding参数数量少,节约存储、计算更快
- 预训练的Embedding向量,与其他特征向量拼接,一同输入模型
- 通过annoy/faiss等框架,便于实现新的召回策略,I2I,U2I等
1 矩阵分解
矩阵分解,直观上来说就是把原来的�×�大矩阵,近似分解成�×�和�×�的两个小矩阵,在实际推荐时使用两个小矩阵进行计算。基于矩阵分解的推荐算法的核心假设是用隐语义(隐变量)来表达用户和物品,他们的乘积关系就成为了原始的元素。隐因子数量 k 的选取要远远低于用户和电影的数量,大矩阵分解成两个小矩阵实际上是用户和电影在 k 维隐因子空间上的映射,这个方法其实是也是一种 “降维”过程,同时将用户和电影的表示转化为在这个 k 维空间上的分布位置,电影和用户的距离越接近表示用户越有可能喜欢这部电影

从机器学习的角度,电影评分预测实际上是一个矩阵补全的过程,原来的大矩阵必然是稀疏的,即有一部分有评分,有一部分是没有评过分的,所以整个预测模型的最终目的是得到两个小矩阵,然后通过这两个小矩阵的乘积来补全大矩阵中没有评分的位置。所以对于机器学习模型来说,问题转化成了如何获得两个最优的小矩阵。因为大矩阵有一部分是有评分的,那么只要保证大矩阵有评分的位置(实际值)与两个小矩阵相乘得到的相应位置的评分(预测值)之间的误差最小即可,目标函数可以是均方误差等。
2 word2vec
word2vec是浅层神经网络模型,有两种网络结构,分别为CBOW和skip-gram。

CBOW 的目标是根据上线文出现的词语来预测当前词生成的概率,而skip-gram是根据当前词来预测上下文词语的生成概率。两者都可以表示成由输入层、映射层、输出层组成的神经网络。
输入层每个词由one-hot编码表示,词汇表中有N个单词,每个词为一个N维向量,单词出现的位置为1,其余位置为0。
映射层包含K个节点,映射层取值可以由N维输入向量和输入与映射层间的�∗�维的权重计算得到,CBOW中还需要将各个输入向量经权重计算出的映射层数值求和。
输出层向量也是N维的,可以由映射层以及映射层与输出层之间的�∗�维矩阵计算得到,输出层向量应用softmax函数可以计算出每个单词生成的概率。
�(�=��|�)=���∑�=1����
通过方向传播算法训练神经网络权重从而使得语料库所有word的整体生成概率最大化。
但是softmax存在归一化项的缘故,需要对词汇表的所有单词进行遍历,迭代过程比较缓慢,后续有hierarchical softmax和negative sampling改进方法。
输入向量和输入与映射层间的�∗�维的矩阵、映射层与输出层之间的�∗�维矩阵存储的就是每个word的embedding。
3 Item2Vec
相比于Word2vec利用“词序列”生成词Embedding。Item2vec利用“物品序列”构造物品Embedding。 其中物品序列是由指定用户的浏览购买等行为产生的历史行为序列。

其中�代表总item个数,�代表item向量的维度,即隐层神经元个数.
Item2vec和Word2vec的唯一不同在于,Item2vec没有使用时间窗口的概念,认为一个序列中任意两个物品都相关。
item2vec是为了得到item embedding 和 user embedding,然后利用用户向量和物品向量的相似性,在召回层快速得到候选集合。
- item embedding: 收集用户行为序列,采用word2vec思想,生成每个item的Embedding
- user embedding: 由历史item embedding AVG pooling、 SUM pooling 或聚类得到。
4 双塔
4.1 DSSM
通过query和document的点击曝光日志,用DNN把query和document表达为低维语义向量,并通过余弦相识度来计算两个语义向量的距离,最终训练出语义相识度模型。

该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低维语义Embedding向量。可用于做I2I的召回。
4.2 YouTube 双塔
YouTube双塔模型分别用MLP网络对用户特征和视频特征分别进行了Embedding,在最后的softmax层前,用户特征和视频特征之间没有任何交互,这就形成了两个独立的塔。

用户塔和视频塔通过接受用户侧/视频侧相关的特征向量,经过MLP内的多层神经网络生成一个多维的稠密向量,这个稠密向量其实就是用户/视频的Embedding向量。
线上用户部分embedding实时计算,线下计算好item的embedding,灌入到annoy或者faiss,直接检索就可以获取结果,常用作U2I召回。
4.3 Capsule 胶囊网络
胶囊网络通过“vector in vector out”的传递方案来代替传统神经网络的“scalar in scalar out”(简单来说,神经元的标量输入替换为向量输入,此时这个神经元就是胶囊 。)
天猫的mind召回基于capsule routing机制设计了一个multi-interest extractor layer,用于聚类历史行为和抽取多样化兴趣。Youtube DNN只使用一个vector来表示一个用户,而MIND使用多个vectors,自适应地将用户历史行为聚合成K个用户表示向量来表示用户的多样化的兴趣。

MIND模型的输入为用户相关的特征,输出是多个用户表征向量,主要用于召回阶段使用。输入的特征主要包括三部分,即用户自身相关特征(user,age...)、用户行为特征(如浏览过的商品id)和target item特征。所有的id类特征都经过Embedding层,其中对于用户行为特征对应的Embedding向量进行average pooling操作,然后将用户行为Embedidng向量传递给Multi-Interest Extract layer(生成interest capsules),将生成的interest capsules与用户本身的Embedding concate起来经过几层全连接网络,就得到了多个用户表征向量,在模型的最后有一个label-aware attention层。在线上使用的时候同样应该采用类似向量化召回的思路,选取TopN。
5 Graph
Graph Embedding也是一种特征表示学习方式,借鉴了Word2Vec的思路。在Graph中随机游走生成顶点序列,构成训练集,然后采用Skip-gram算法,训练出低维稠密向量来表示顶点。图模型生成的节点Embedding向量一般包含图的结构信息及附近节点的局部相似性信息。
5.1 DeepWalk
主要思想是在由物品组成的图结构上进行随机游走,产生大量物品序列,然后将这些物品序列作为训练样本输入Word2Vec进行训练,得到物品的Embedding

步骤如下:
- 收集用户行为序列
- 基于这些用户行为序列构建了物品关系图。
- 图中的边是由用户行为产生的,比如为用户M先后购买了物品A和物品B,会产生了一条有向边由A指向B。其他的有向边也是同样的道理,如果有多个有A指向B的有向边,那么该条边的权重被加强。通过这样的方法将所有用户行为序列都转换成物品相关图中的边后,就得到全局的物品相关图。
- 采用随机游走的方式随机选择起始点,重新产生物品序列。
- 物品序列作为训练样本输入Word2Vec进行训练
5.2 Node2Vec
通过调整随机游走权重的方法使Graph Embedding的结果更倾向于体现网络的同质性或结构性。

同质性指距离相近节点的Embedding应尽量近似,例如�与�1,�2,�3,�4。为了使Graph Embedding的结果能够表达网络的“结构性”,在随机游走过程中,需要让游走的过程更倾向于BFS,因为BFS会更多地在当前节点的邻域中游走遍历,相当于对当前节点周边的网络结构进行一次“微观扫描”。当前节点是“局部中心节点”,还是“边缘节点”,或是“连接性节点”,其生成的序列包含的节点数量和顺序必然是不同的,从而让最终的Embedding抓取到更多结构性信息。
结构性指的是结构上相似的节点Embedding应尽量近似,例如�与�6。为了表达“同质性”,需要让随机游走的过程更倾向于DFS,因为DFS更有可能通过多次跳转,游走到远方的节点上,但无论怎样,DFS的游走更大概率会在一个大的集团内部进行,这就使得一个集团或者社区内部的节点的Embedding更为相似,从而更多地表达网络的“同质性”。
node2vec算法通过节点间的跳转概率控制BFS和DFS的倾向性

改进的随机游走有两个参数�,�。假设刚游走完边(�,�),现在在节点�要根据转移概率���选择下一个节点�。
���=���(�,�)∗������(�,�)={1������=01�����=11������=2
其中,���指的是节点�到节点�的距离,只有3种情况,如果又回到顶点t,那么为0;如果x和t直接相邻,那么为1;其他情况为2。参数�和�共同控制着随机游走的倾向性。参数�被称为返回参数,�越小,随机游走回节点t的可能性越大,node2vec就更注重表达网络的同质性,参数�被称为进出参数,�越小,则随机游走到远方节点的可能性越大,node2vec更注重表达网络的结构性,反之,当前节点更可能在附近节点游走。
node2vec所体现的网络的同质性和结构性在推荐系统中可以被很直观的解释。同质性相同的物品很可能是同品类、同属性,或者经常被一同购买的商品,而结构性相同的物品则是各品类的爆款、各品类的最佳凑单商品等拥有类似趋势或者结构性属性的商品。毫无疑问,二者在推荐系统中都是非常重要的特征表达。由于node2vec的这种灵活性,以及发掘不同图特征的能力,甚至可以把不同node2vec生成的偏向“结构性”的Embedding结果和偏向“同质性”的Embedding结果共同输入后续的深度学习网络,以保留物品的不同图特征信息。
5.3 EGES
EGES利用DeepWalk生成的graph embedding思想,收集用户的点击历史,将两个连续的 Item 用一个有向边连接.同时为了解决冷启动问题,引入了更多补充信息(shop ID, category ID, ...),从而使没有历史行为记录的商品获得Embedding。
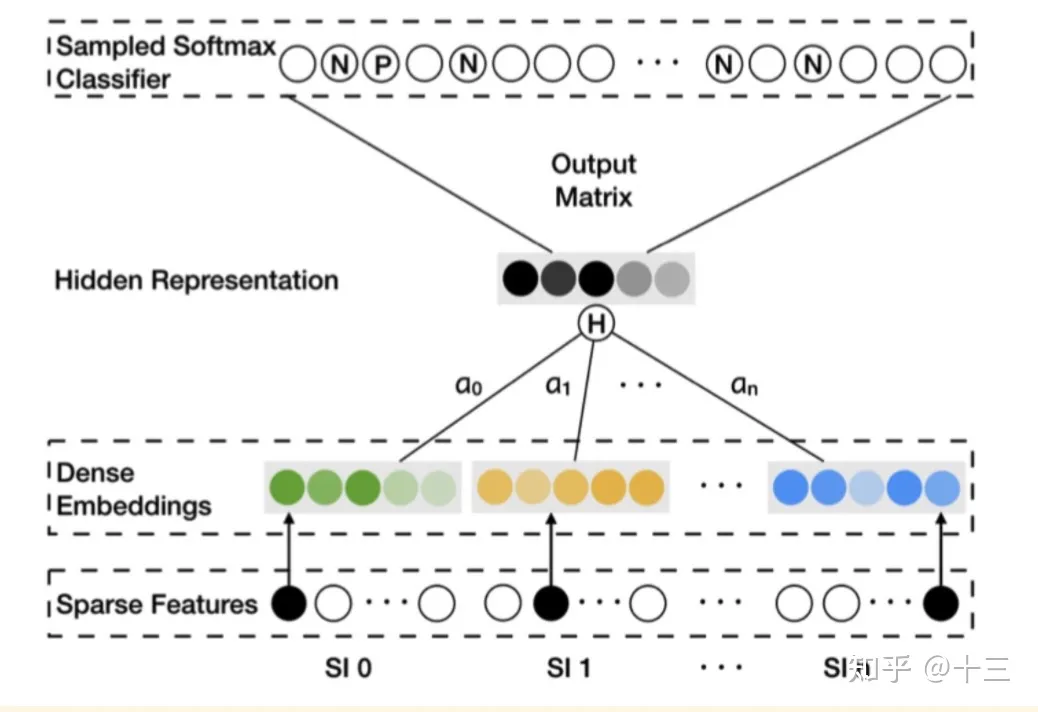
在生成物品 Embedding 的过程中,考虑到不同种类的 Side Information 对 Embedding 的贡献是不同的,为了表示不同类型的 Side Information 在被聚合时会具有不同的贡献,引入了attention机制,对每个Side Information embedding加上了权重。图中的Hidden Representation层就是对不同Embedding进行加权平均操作的层,得到加权平均后的Embedding向量后,再直接输入softmax层。
5.4 Pinsage
pinsage是GCN在推荐领域的成功应用,PinSage模型使用了随机游走和图卷积,捕获到了图结构的特征以及节点的特征,以生成节点的嵌入表示。

PinSage算法,通过采样节点的邻居并动态地从采样邻居构建计算图,实现了有效的局部的卷积。这些动态形成的计算图说明了如何围绕一个节点进行局部的卷积,并且在训练时不需要在整张图上进行操作。
论文中涉及到的数据为20亿图片(pins),10亿画板(boards),180亿边(pins与boards连接关系)。如作者所言,PinSage是“random-walk-based GCN”。论文目的是通过PinSage算法学习节点的高效表达(embedding),并以此为基础,后续利用K临近等方法进行推荐。
参考
- 推荐算法之矩阵分解
- 深度学习中不得不学的Graph Embedding方法
- EGES:阿里在图嵌入领域中的探索
- 《Graph Convolutional Neural Networks for Web-Scale Recommender Systems》

