
热门标签
热门文章
- 1秘密-安恒明御防火墙-入门信息安全教学
- 2任意文件读取和上传_文件上传结合任意文件读取
- 3VTK_3D坐标系(vtkAxesActor/vtkCubeAxesActor)_vtk绘制背景刻度
- 4使用1panel部署Ollama WebUI(dcoekr版)浅谈_1panel ollama
- 5生成中文词向量和句向量的Word2Vec和Doc2Vec实现_中文生成词向量工具
- 6学生选课管理系统——用例图_用例模型图学生选课管理系统
- 7FPGA原理与结构(0)——目录与传送门_fpga原理和结构天野英晴pdf 百度网盘
- 8推荐项目:ngCordova - AngularJS与Cordova的完美结合
- 9ollama 使用,以及指定模型下载地址_ollama 下载
- 10什么是会话固定攻击?Spring Boot 中要如何防御会话固定攻击?
当前位置: article > 正文
大语言模型-阿里云研发的通义千问-72B_阿里的通义千问72b
作者:繁依Fanyi0 | 2024-06-12 02:09:09
赞
踩
阿里的通义千问72b

通义千问-72B(Qwen-72B)是阿里云研发的通义千问大模型系列的720亿参数规模的模型。Qwen-72B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。
主要有以下特点:
- 大规模高质量训练语料:使用超过3万亿tokens的数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。通过大量对比实验对预训练语料分布进行了优化。
- 强大的性能:Qwen-72B在多个中英文下游评测任务上(涵盖常识推理、代码、数学、翻译等),效果显著超越现有的开源模型。具体评测结果请详见下文。
- 覆盖更全面的词表:相比目前以中英词表为主的开源模型,Qwen-72B使用了约15万大小的词表。该词表对多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强和扩展。
- 较长的上下文支持:Qwen-72B支持32k的上下文长度。
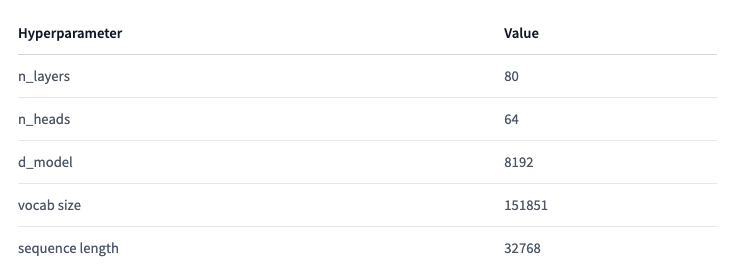
模型参数
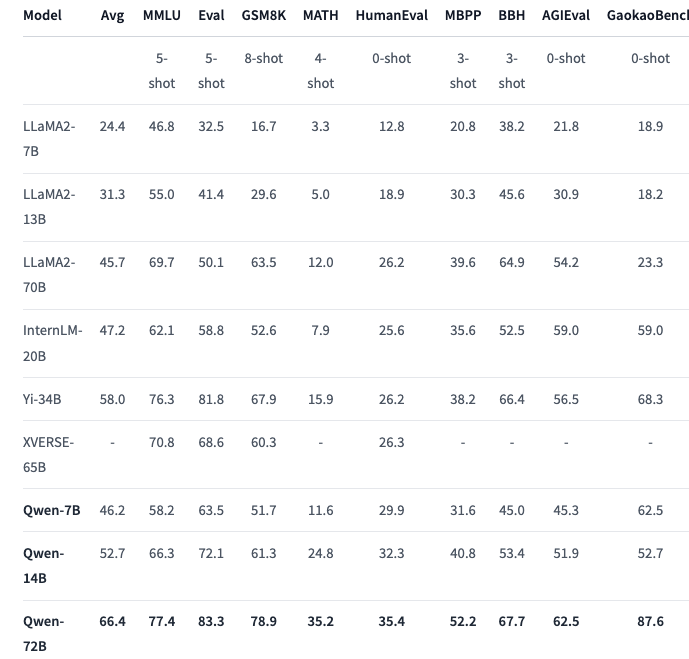
评测效果
我们选取了MMLU,C-Eval,GSM8K, MATH, HumanEval, MBPP, BBH, CMMLU等目前较流行的benchmark,对模型的中英知识能力、翻译、数学推理、代码等能力进行综合评测。Qwen-72B模型在所有benchmark上均取得了开源模型中的最优表现。
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

