
- 1这些年遇到的RocketMQ消息消费超时/消费异常重试机制导致的重复消费问题(并发消费和顺序消费)源码分析_rocketmq 消费超时
- 2云计算存储虚拟化技术-openstack-cinder_云计算建volume
- 3yolo-inference多后端+多任务+多算法+多精度模型 框架开发记录(cpp版)
- 4【附源码】基于的校园跑腿系统的设计与实现ntdh99计算机毕设SSM
- 5分治法的关键特征_算法系列之常用算法之一----分治算法
- 6PAT (Basic Level) Practice (中文)1059 C语言竞赛(C语言)_.有什么c语言比赛的网站
- 7RAG:如何从0到1搭建一个RAG应用
- 8黑盒测试——场景测试_黑盒测试不可行场景问题
- 9FISCO BCOS从零实战(详细)(一)
- 10论文浅尝 | 异构图 Transformer
AI预测-一文解析AI预测数据工程_ai预测模型
赞
踩
AI预测相关目录
AI预测流程,包括ETL、算法策略、算法模型、模型评估、可视化等相关内容
最好有基础的python算法预测经验
- EEMD策略及踩坑
- VMD-CNN-LSTM时序预测
- 对双向LSTM等模型添加自注意力机制
- K折叠交叉验证
- optuna超参数优化框架
- 多任务学习-模型融合策略
- Transformer模型及Paddle实现
- 迁移学习在预测任务上的tensoflow2.0实现
- holt提取时序序列特征
- TCN时序预测及tf实现
- 注意力机制/多头注意力机制及其tensorflow实现
- 一文解析AI预测数据工程
一、特征工程概述

数据工程包括异常处理、数据单项分析、数据关联分析、数据编码处理、数据特征工程等方面,对AI预测可以起到决定性作用。
二、数据异常处理
见文章:
https://blog.csdn.net/qq_43128256/article/details/136768729?spm=1001.2014.3001.5502
三、数据单项分析
3.1 可视化分析
例如,对温度时间序列数据进行分析时,可通过可视化相近日期的温度数据,观测每日的温度趋势是否符合常识、是否走势大致相同…
3.2 统计特征
例如,分析某一字段数值时,计算其数值均值、方差、中位数…观测其数据项分布是否符合常识、波动是否合理…
四、数据关联分析
4.1 可视化分析
例如,对温度时间序列数据和气压时间序列数据进行分析时,可通过可视化的手段观测两条曲线的趋势与相关性是否整常。
4.2 热度图
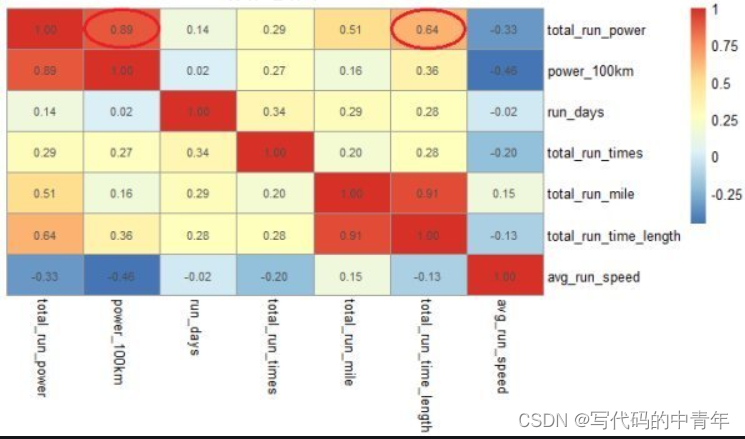
如图所示,所谓热度图本质是对相关性系数矩阵的可视化。
相关性强弱看其系数绝对值大小,正数表示正相关,负数表示负相关。
自身与自身的相关性为1。
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# 创建一个随机的二维数组
data = np.random.rand(10, 12)
# 创建一个热度图
heatmap = sns.heatmap(data)
# 显示图形
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
五、数据编码处理
预测时数据集中往往遇到以文本形式存在的数值,对于这种类型的字段,有必要利用数据编码技术实现文本的数字化,使其变为可以用于算法计算的数值类型数据。
数据编码处理是机器学习、自然语言处理等领域中非常重要的步骤,其主要目的是将原始数据转换为算法能够理解和处理的格式。以下是朴素编码、独热编码(One-Hot Encoding)和词向量的详细介绍:
5.1 朴素编码(Naive Encoding)
朴素编码是一种简单的数据编码方法,它通常用于将分类数据转换为数值形式。对于每个分类变量,朴素编码会为其分配一个唯一的整数值。例如,对于颜色分类变量(红色、蓝色、绿色),朴素编码可能会将红色编码为1,蓝色编码为2,绿色编码为3。然而,这种编码方法存在一个潜在问题,即它假设了编码的数值之间存在某种顺序或距离关系,这在很多情况下并不成立。因此,朴素编码在处理没有自然顺序的分类变量时可能会导致误导性的结果。
5.2 独热编码(One-Hot Encoding)
独热编码是一种解决朴素编码中数值顺序问题的方法。它将分类变量转换为一个二进制向量,其中向量的长度等于分类变量的可能取值数量。对于每个分类变量的取值,独热编码会在向量中对应的位置设置为1,其他位置设置为0。例如,对于颜色分类变量(红色、蓝色、绿色),独热编码会将红色表示为[1, 0, 0],蓝色表示为[0, 1, 0],绿色表示为[0, 0, 1]。这样,每个分类变量的取值都被表示为一个独立的维度,从而消除了数值之间的序关系问题。独热编码特别适用于那些没有自然顺序的分类变量,如颜色、国家、产品类别等。
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# 假设我们有一个包含几个分类特征的数组
categorical_features = np.array([['cat1', 'dog', 'fish'], ['dog', 'cat1', 'cat2']]).reshape(-1, 1)
# 初始化 OneHotEncoder
encoder = OneHotEncoder(sparse=False)
# 使用 fit_transform 方法对数据进行编码
onehot_encoded = encoder.fit_transform(categorical_features)
print(onehot_encoded)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
5.3 词向量(Word Embedding)
词向量是自然语言处理中用于表示词汇的一种方法。与传统的基于规则或统计的自然语义处理方法不同,词向量将单词映射到一个低维实数向量空间中,使得具有相似含义或上下文的单词在向量空间中具有相近的位置。这种表示方法有助于捕捉词汇之间的语义关系,并使得机器学习算法能够更好地处理文本数据。词向量的生成通常基于大规模的语料库和深度学习技术,如Word2Vec、GloVe等。词向量在自然语言处理任务中取得了显著的效果提升,特别是在文本分类、情感分析、机器翻译等领域。
from gensim.models import Word2Vec from nltk.tokenize import word_tokenize import nltk # 下载 nltk 的punkt分词器模型,如果你还没有下载的话 nltk.download('punkt') # 假设我们有一些文本数据 sentences = [word_tokenize("I love natural language processing".split()), word_tokenize("NLP is awesome".split()), word_tokenize("Machine learning is fun".split())] # 初始化并训练 Word2Vec 模型 model = Word2Vec(sentences, min_count=1) # 获取一个词的向量表示 vector = model.wv['love'] # 查找最相似的词 similar_words = model.wv.most_similar('love') print(similar_words)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
5.4 其他具有设计性的编码
如对季节进行1-2-3-4编码,对月份进行1-2-3-…-11-12编码,对工作日、周六、周日进行1-1-1-1-1-2-3的编码等等。
六、数据编码处理
数据特征构建和数据集划分属于AI基础,略。
6.1 数据特征提取
聚类
如K-SSE配合K均值聚类,先确定聚类数目,再对数据进行聚类,根据聚类结果给数据打上类别标签,如此,聚类算法实际上提取了蕴含在数据中的隐含信息,不同类别间的数据具有一定区分度。
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import make_blobs # 生成模拟数据 n_samples = 300 n_features = 2 centers = 4 # 假设真实聚类数目为4 X, y_true = make_blobs(n_samples=n_samples, n_features=n_features, centers=centers, cluster_std=0.60, random_state=0) # 定义K值范围 k_range = range(1, 10) # 存储每个K值的SSE sse = [] # 遍历K值范围,进行K均值聚类并计算SSE for k in k_range: kmeans = KMeans(n_clusters=k, init='k-means++', max_iter=300, n_init=10, random_state=0) kmeans.fit(X) sse.append(kmeans.inertia_) # inertia_属性即SSE # 绘制K-SSE曲线 plt.plot(k_range, sse, marker='o') plt.xlabel('Number of clusters K') plt.ylabel('SSE') plt.title('K-SSE Curve') plt.show() # 根据K-SSE曲线确定最佳聚类数目 # 通常是选择SSE开始平坦化的点对应的K值 best_k = sse.index(min(sse[1:])) + 1 # 排除K=1的情况,因为它通常会有很高的SSE print(f"Best number of clusters based on K-SSE: {best_k}") # 使用最佳K值进行K均值聚类 best_kmeans = KMeans(n_clusters=best_k, init='k-means++', max_iter=300, n_init=10, random_state=0) best_kmeans.fit(X) # 可视化聚类结果 plt.scatter(X[:, 0], X[:, 1], c=best_kmeans.labels_, cmap='viridis') centers = best_kmeans.cluster_centers_ plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5) plt.title('KMeans Clustering') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
门限
实际上是手动根据业务需求,设置阈值划分,根据阈值范围给数据进行标签生成。
开源框架
利用开源项目对数据进行二次处理,形成新的特征数据。例如:
https://blog.csdn.net/qq_43128256/article/details/135677292
- 1
6.2 数据增强
数据归一化
数据归一化是一种预处理技术,用于将数据缩放到一个特定的范围,通常是[0, 1]或[-1, 1]。这种技术有助于在机器学习和数据分析中消除量纲或尺度差异,使得不同特征或变量在模型中具有相同的权重。当不同特征的尺度差异很大时,归一化有助于防止某些特征对模型的影响过大,从而改进模型的性能。
import numpy as np from sklearn.preprocessing import MinMaxScaler # 假设我们有一个包含不同尺度特征的数据集 data = np.array([[100, 20, 50], [200, 50, 120], [300, 120, 100], [400, 85, 70]]) # 初始化MinMaxScaler scaler = MinMaxScaler() # 使用fit_transform方法将数据缩放到[0, 1]范围 normalized_data = scaler.fit_transform(data) print("Original Data:") print(data) print("Normalized Data:") print(normalized_data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
数据标准化
使用特征的均值和标准差来进行标准化,使得数据具有零均值和单位方差。这在某些算法(如逻辑回归、支持向量机)中可能更为有用,因为它们对特征的尺度更敏感。
from sklearn.preprocessing import StandardScaler
# 初始化StandardScaler
scaler = StandardScaler()
# 使用fit_transform方法将数据进行标准化
standardized_data = scaler.fit_transform(data)
print("Standardized Data:")
print(standardized_data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
标准化后的数据将不再位于[0, 1]范围,而是根据特征的分布,通常会有负数、零和正数。这种方法的一个关键好处是它不会受到数据集中异常值的影响,因为标准差计算考虑了所有数据点。
数据格式转化
例如:一维数据转化(numpy.array格式reshape)为二维数据,可与CNN等可对二维数据进行特征提取的数据进行配合。

