
AnythingLLM:私人 ChatGPT,构建专属知识库,本地代码库问答助手_anythingllm no embedding model was set.
赞
踩
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学.
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集:《大模型面试宝典》(2024版) 发布!
今天分享如何用大模型+本地资料,构建专属知识库。 技术交流文末获取。
开源地址:https://github.com/Mintplex-Labs/anything-llm
核心解决的是大模型幻觉的问题。我们都知道,大模型对于自己不知道的问题可能会乱答。比如,如果你向大模型询问你们公司今年的战略目标,大模型可能压根没听说过你们公司。这时候如果大模型回复不知道还好点,如果乱答就误人子弟了。
对于幻觉问题,目前是这样解决的,先将背景信息告诉大模型,这样大模型就可以提前学习相关知识, 这时候再向大模型提问,就可以得到准确的答案了。
AnythingLLM 就是解决这样问题的通用框架。除了能解决幻觉问题,还可以用它来读论文、读代码,非常方便。

安装使用非常方便,支持 Win、Mac、Linux 平台,也可以使用Docker安装,不需要编程。
要使用 AnythinLLM,需要设置以下三方面设置
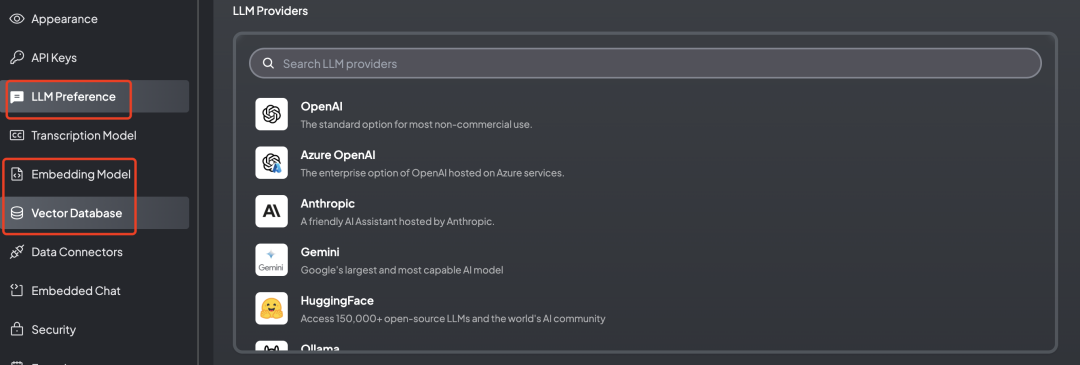
第一,LLM Preference,就是使用哪个大模型,AnythinLLM 支持模型特别多。需要说明的是,如果你用的是中转的ChatGPT接口,选择“Local AI”即可。
第二,Embedding Model,可以把本地资料向量化,这样就可以根据提问的问题,匹配对应的资料片段。如果你的本地资料是保密的,需要用本地的Model,否则可能会造成数据泄露。

第三,Vector Database 向量数据库,用于存储第二步生成向量。选择 AnythingLLM 自带的即可。
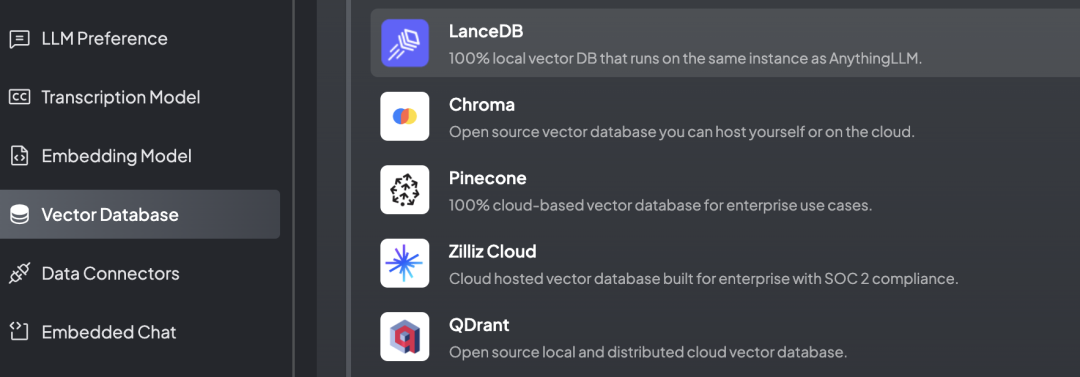
设置完以后,上传本地资料可以使用了。
下面分享一下我使用的示例,给大家参考下。
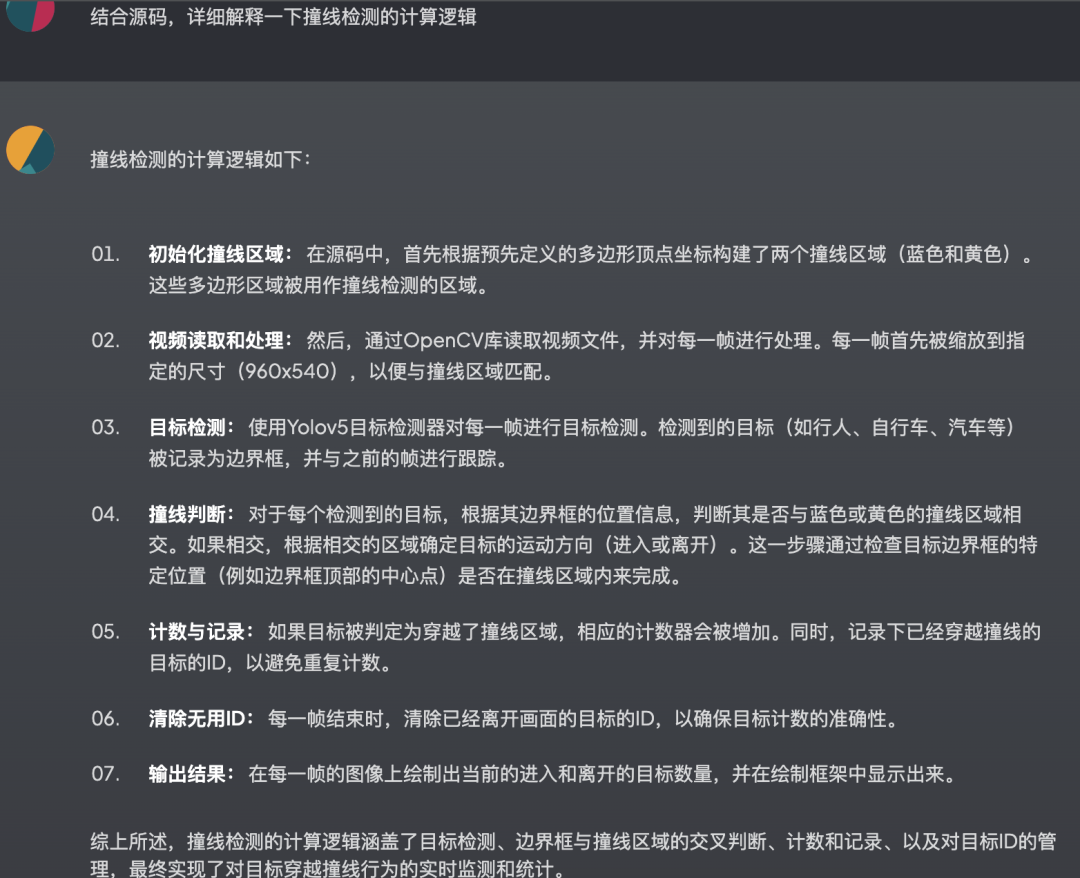
第一个是阅读本地代码,解释其中的代码逻辑
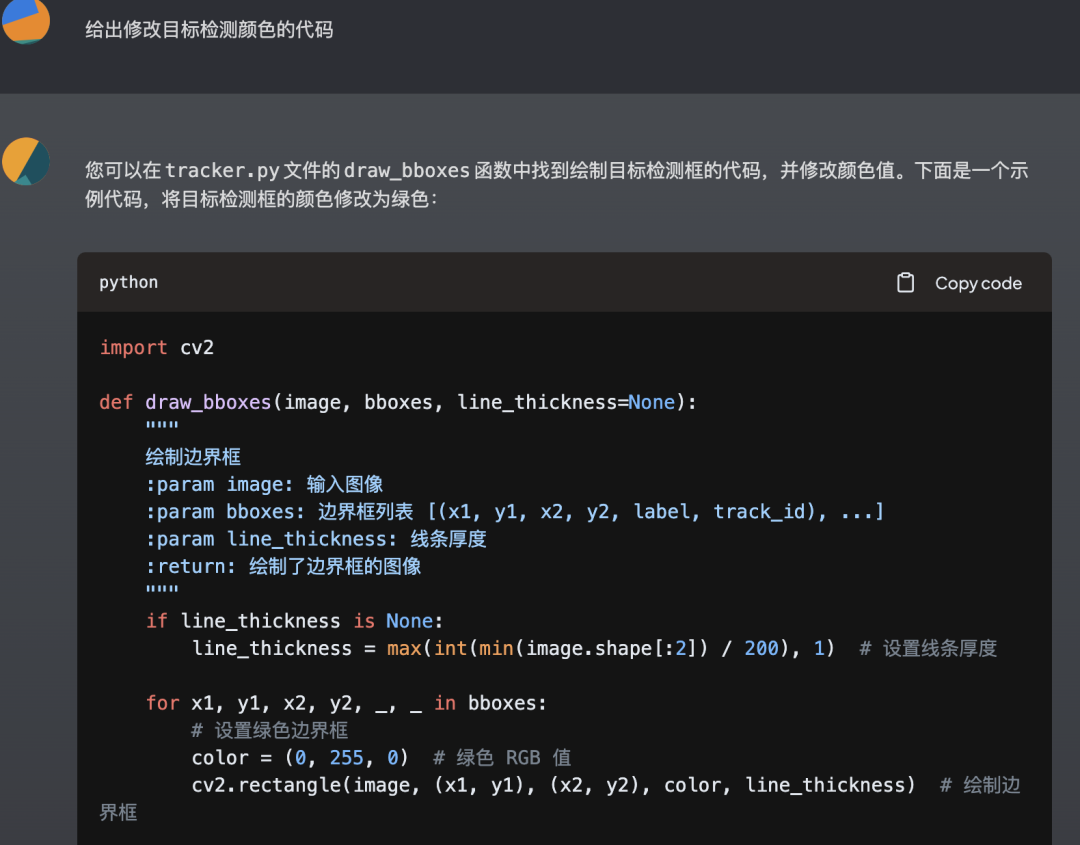
也可以让它开发新需求
第二个示例,则是将它作为论文阅读助手,帮助我们快速阅读论文。
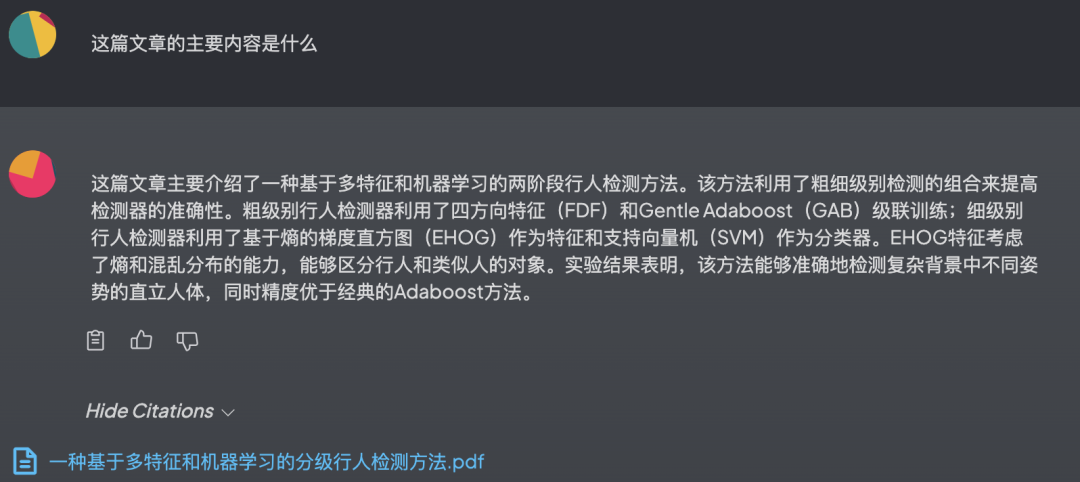
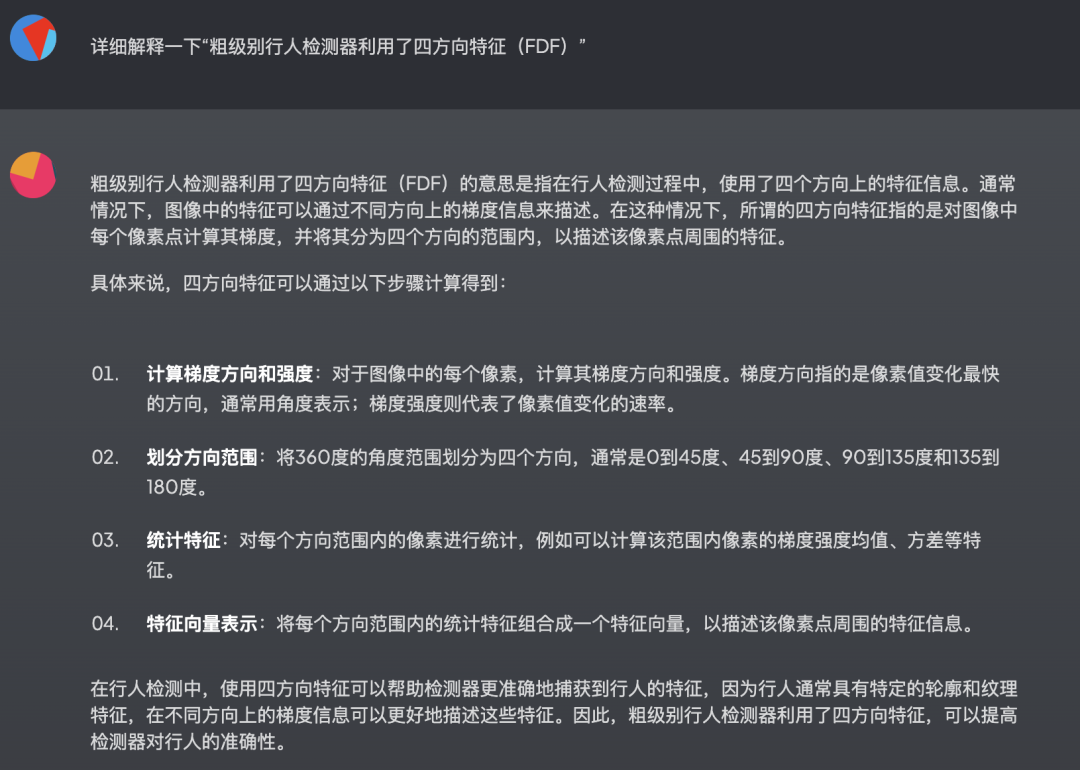
有需要的朋友可以试试。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要获取最新面试题、了解最新面试动态的、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:技术交流

