
- 1软考中级---系统集成项目管理
- 2太全了!互联网大厂的薪资和职级一览
- 3[1124]flink上下文StreamExecutionEnvironment_streamexecutionenvironment.getexecutionenvironment
- 4FPGA基本开发设计流程,九个步骤搞定_fpga设计开发流程
- 5简易的Python小游戏,上班可玩一天,零基础小白可练手_python小游戏代码简单
- 6[数据集][目标检测]螺丝螺母检测数据集VOC+YOLO格式2100张13类别_数据集螺丝
- 7MySQL数据库介绍、安装(服务端软件安装、客户端软件安装(图形化界面客户端和命令行客户端))_mysql 服务端
- 8使用谷歌Colab(Colaboratory)免费GPU训练自己的模型及谷歌网盘无限容量(Google drive)申请教程_colab租显卡需要多少钱
- 9Mac中安装Node和版本控制工具nvm遇到的坑,2024年最新大厂后端面试_mac node
- 10MySQL问题:2002 - Can‘t connect to server on ‘localhost‘(10061)【已解决】_2002cant connect to server on
大模型 Dalle2 学习三部曲(三)Hierarchical Text-ConditionalImage Generation with CLIP Latents 论文学习_dalle的结构
赞
踩
前言:
今天我们来学习一下Dalle2论文
上篇文章我们说latency diffusion 把图像和文本先压缩到隐空间再进行diffusion,大大提升了diffusion过程的效率,其实我们想想diffusion过程其实我们也完全没必要一直扩散到纯噪声再还原为图像,我们只需要扩散到适合我们生成图像的时候就可以。正所谓好钢用在刀刃上,效果好费时的扩散过程我们只要在关键位置使用就可以,即达到效果,又节省了时间。
那让我们来看看dalle2是怎么做的
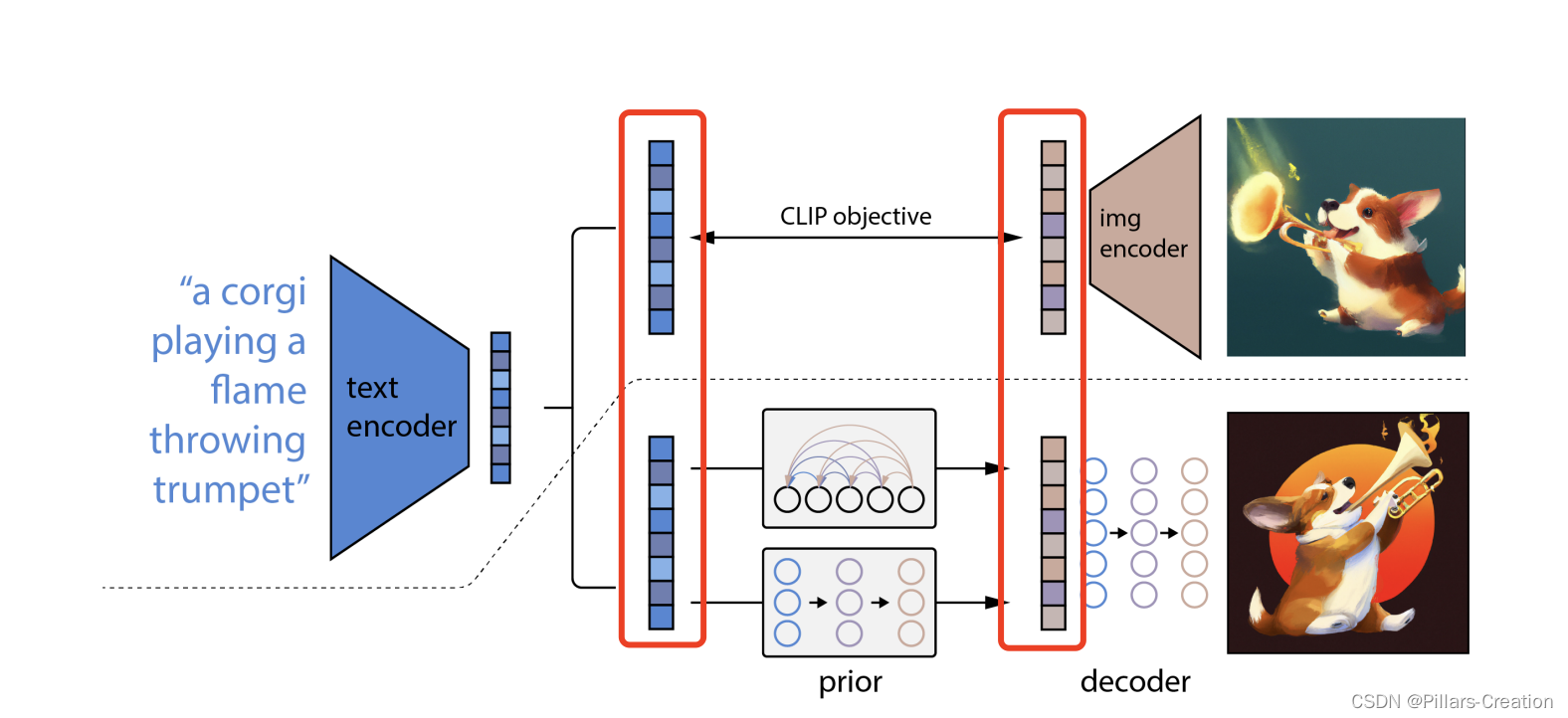
整体结构:
整体结构如图,虚线上部为clip,下部红框隔开的为prior,decoder。中间红框为连接部分用了clip模型的item 隐向量和img隐向量作为了桥接。
结构理解:
我们回想一下VAE,看看这个结构是不是非常的熟悉,也是一个encoder,一个decoder。不同的是VAE中间是一个高斯分布Z,dalle2和Latent Diffusion用diffusion做了一个domain的转换。是不是结构理解一下子就简单起来了
具体过程
下面让我们看看dalle2模型的几个过程
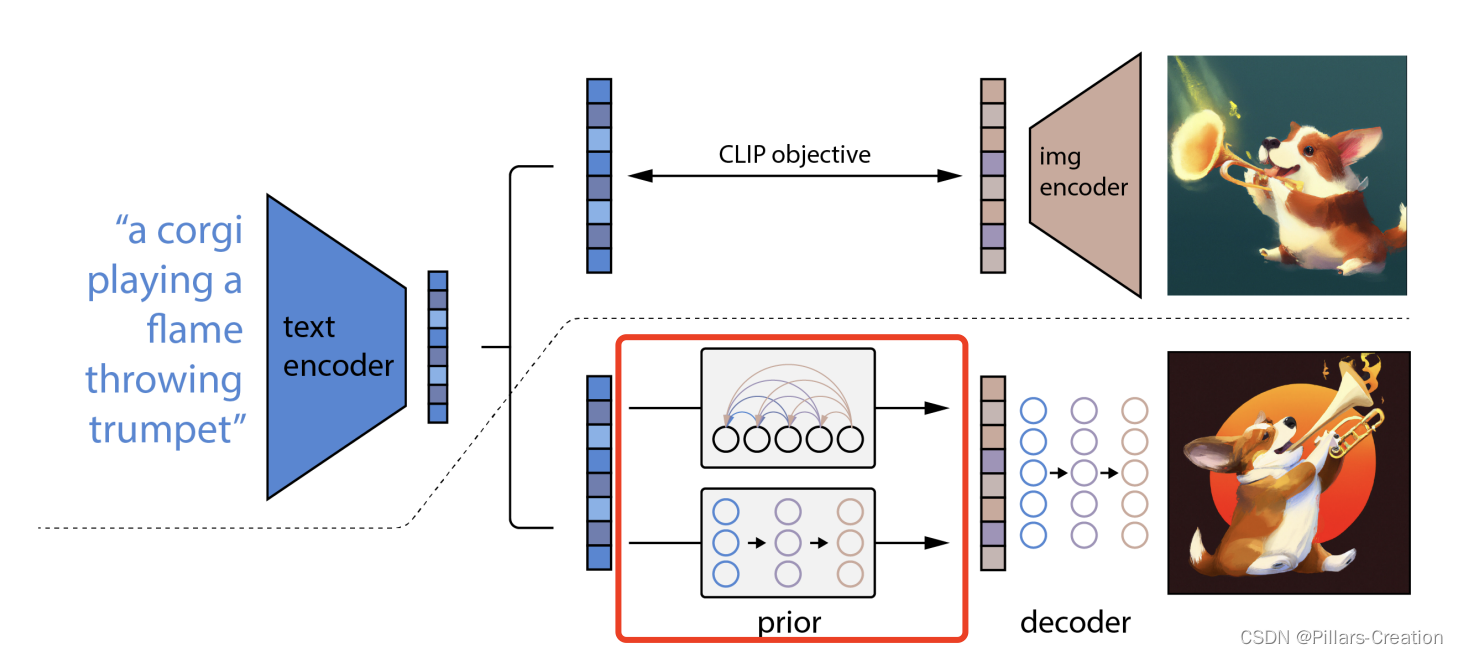
1,prior 过程,
如图红框所示,dalle2在prior过程中用了diffusion过程,是从文本隐空间到图像隐空间的变化。(对比于diffusion从图像到噪声,以及latency diffusion 从 隐空间到噪声),dalle2利用diffsiion完成了最精华的domain变换过程。
- 当我们能对两个隐空间进行转换的时候,剩下的工作就比较简单了,分别训练两个encoder 和 decoder ,文本到图像的转换就完成了。
- 这里还有个问题,那么在prior训练过程文本隐空间到图像隐空间对应关系从哪儿来,论文又很巧妙的想到了clip模型,模型里的文本隐空间到图像隐空间就是现成的样本对。于是把clip里的文本隐空间到图像隐空间放到中间做桥接,很简洁又很高效的dalle2整体架构就完成。
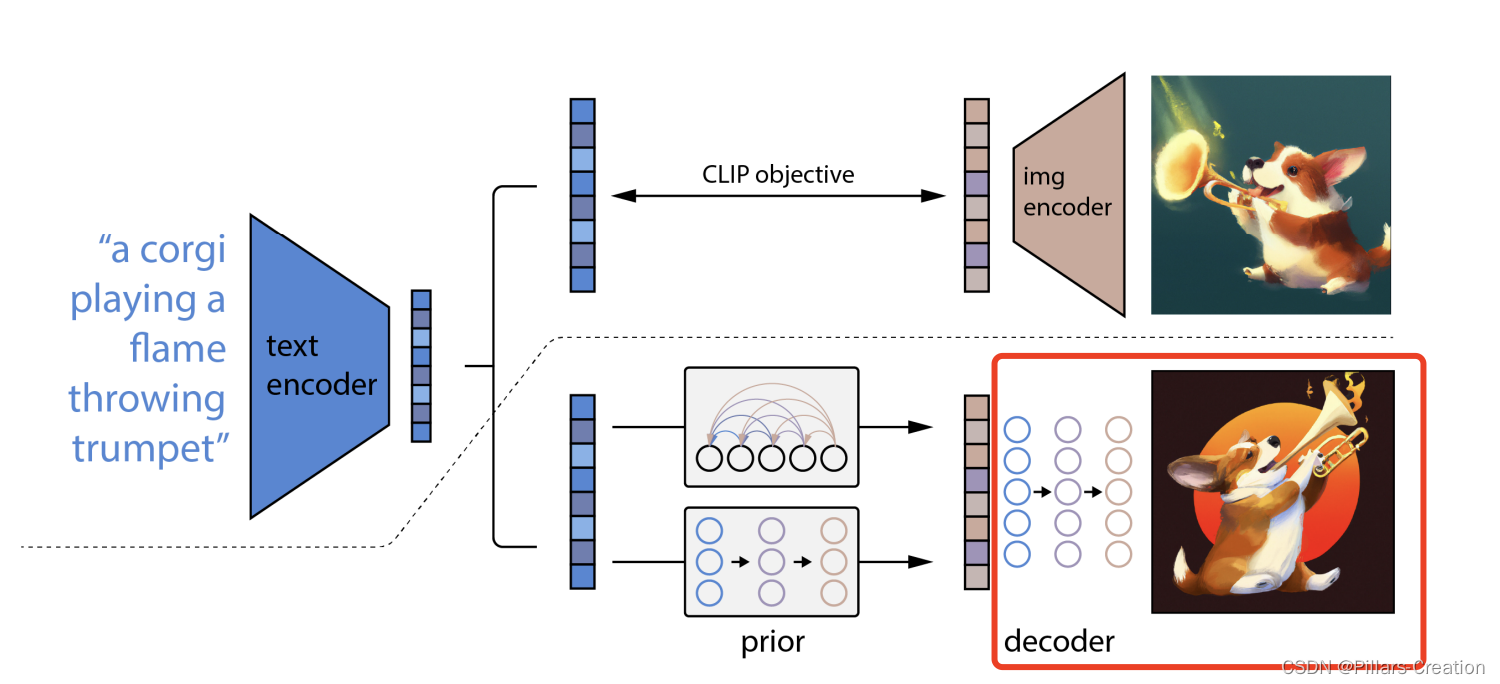
2,decoder过程,
刚刚我们说prior过程dalle2用了diffusion,那么decoder过程用了什么呢,答案是decoder阶段也用了diffusion,刚刚还说好钢用在刀刃,真是啪啪打脸。不过话又说回来你要要是钱多,整把刀都用好钢那也是正常。open ai 财大气粗,资源不是个事,所以都用了diffusion,再说写论文肯定也是把效果堆成最好才容易吸引目光。但是对我们来说可以根据自己的需求进行取舍,比如最后的decode阶段如果你只是个目标检测分类,就完全没必要用diffusion过程,用个分类器就能大大加速。
decoder过程中作者为了生成效果还做了大量的细化
1)在训练期间,以10%的概率随机将CLIP嵌入设置为零,以及以50%的概率随机丢弃文本标题。
2)启用无分类器引导。在训练过程中不使用分类器来指导生成模型的学习
3)为了生成高分辨率图像,训练了两个扩散上采样模型:一个将图像从64×64上采样到256×256分辨率,另一个将其进一步上采样到1024×1024分辨率。
4)为了提高上采样器的鲁棒性,在训练过程中我对调节图像进行了轻微的损坏。对于第一阶段的上采样,论文使用高斯模糊,对于第二阶段,论文使用更多样化的BSR降级。
5)为了减少训练计算量并提高数值稳定性,在目标大小的四分之一的随机图像上进行训练。
6)论文在模型中仅使用空间卷积(即无注意力层),并在推理时直接在目标分辨率上应用模型。因为是卷积因此论文说模型可以很容易泛化到更高的分辨率。
7)发现将上采样器条件化到标题上没有帮助,并使用无引导的无条件ADMNets。
几点疑问:
这里我们会有几点疑问
1, 文本隐空间到图像隐空间对应关系,不用clip行不行
当然是可以,既然刚刚我们说prior过程是完成domian转化,那么这里可以我们换成我们可以找到任何成对的domian
2,直接用两个NN网络代替encoder,decoder,然后端到端训练不是更省事
论文里其实回答了这个,论文提到这种显式生成中间特征的过程,在写实程度和相似程度保持一致的情况下,显著提升结果的多样性和创造力。在生活工作中我们也是这样,每个阶段或者部门完成自己的目标,整体结果才会更符合预期。如果大家都只有一个整体大目标,比如实现共产主义,而没有自己的具体目标,很容易就乱纷纷的,形成不了合力。
3,prior不用diffusion可不可以,答案是可以,作者在prior里就尝试了不同的做法,比如自回归和diffusion的对比,当然实验结果是diffusion的效果最好。

