
热门标签
热门文章
- 1ComfyUI中使用 SD3 模型(附模型下载详细说明)_comfyui sd3
- 2ChatGLM4重磅开源! 连忙实操测试一波,效果惊艳,真的好用!_chatglm4 开源发布时间
- 310款国内可用的AI工具分享,每一款都能让你工作效率翻倍_魔术todo任务分解
- 4普通人也能搞的,0成本,热门副业AI绘画,月入1w+_2024年0成本如何日入10000
- 5聚类模型的算法性能评价
- 6NLP综述:知识脉络图、四大类任务【序列标注(分词、词性标注、NER)、分类任务(文本分类、情感分析)、句子关系判断(顺序判断、相似度计算)、生成式任务(机器翻译、问答 、文本摘要)】_图书馆nlp标注 脉络洞察
- 7百度云不限速客户端让你获取SVIP速度_加速链接获取中啥意思
- 8C++11 智能指针详解_c++ 11所有的智能指针
- 9大模型入门指南:基本技术原理与应用_大模型原理
- 10Kafka和Spark Streaming的组合使用学习笔记(Spark 3.5.1)_2. kafka和structured streaming组合使用 (1)编写生产者程序每1秒生成一
当前位置: article > 正文
毕设项目 大数据房价数据分析及可视化(源码分享)_房价可视化分析
作者:繁依Fanyi0 | 2024-06-27 01:18:44
赞
踩
房价可视化分析
0 前言
今天分享一个大数据毕设项目:毕设分享 大数据房价数据分析及可视化(源码分享)
项目获取:
https://gitee.com/sinonfin/algorithm-sharing
实现效果
毕业设计 房价大数据可视化分析
1 课题背景
房地产是促进我国经济持续增长的基础性、主导性产业。如何了解一个城市的房价的区域分布,或者不同的城市房价的区域差异。如何获取一个城市不同板块的房价数据?
本项目利用Python实现某一城市房价相关信息的爬取,并对爬取的原始数据进行数据清洗,存储到数据库中,利用pyechart库等工具进行可视化展示。
2 数据爬取
2.1 爬虫简介
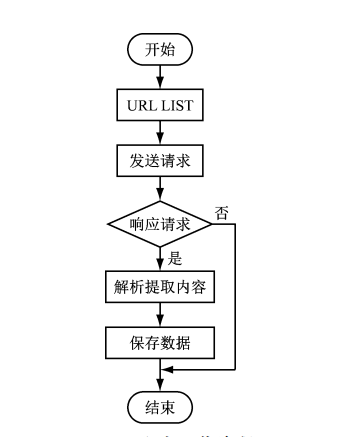
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行。若不能访问则根据爬虫预先设定的策略进行下一个 URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪 装 请求头以便更好地获取网页数据。
爬虫流程图如下:
实例代码
# get方法实例
import requests #先导入爬虫的库,不然调用不了爬虫的函数
response = requests.get("http://httpbin.org/get") #get方法
print( response.status_code ) #状态码
print( response.text )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.2 房价爬取
累计爬取链家深圳二手房源信息累计18906条
- 爬取各个行政区房源信息;
- 数据保存为DataFrame;
相关代码
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm
import math
import requests
import lxml
import re
import time
area_dic = {'罗湖区':'luohuqu',
'福田区':'futianqu',
'南山区':'nanshanqu',
'盐田区':'yantianqu',
'宝安区':'baoanqu',
'龙岗区':'longgangqu',
'龙华区':'longhuaqu',
'坪山区':'pingshanqu'}
# 加个header以示尊敬
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36',
'Referer': 'https://sz.lianjia.com/ershoufang/'}
# 新建一个会话
sess = requests.session()
sess.get('https://sz.lianjia.com/ershoufang/', headers=headers)
# url示例:https://sz.lianjia.com/ershoufang/luohuqu/pg2/
url = 'https://sz.lianjia.com/ershoufang/{}/pg{}/'
# 当正则表达式匹配失败时,返回默认值(errif)
def re_match(re_pattern, string, errif=None):
try:
return re.findall(re_pattern, string)[0].strip()
except IndexError:
return errif
# 新建一个DataFrame存储信息
data = pd.DataFrame()
for key_, value_ in area_dic.items():
# 获取该行政区下房源记录数
start_url = 'https://sz.lianjia.com/ershoufang/{}/'.format(value_)
html = sess.get(start_url).text
house_num = re.findall('共找到<span> (.*?) </span>套.*二手房', html)[0].strip()
print('声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/760905推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

