
- 1Chainlit系列02- 开发入门聊天应用_chainlit部署
- 2EndNote 、GB/T 7714格式参考文献、文献标题有%J(附安装包)_gbt7714.ens
- 3VSCode 开发C/C++实用插件分享——codegeex_vscode c+调用图插件
- 4python+基于Python的资产管理系统 毕业设计-附源码201117_基于python的资产管理系统源码
- 5ChatGPT 提问攻略:从基础到精通,掌握AI对话的艺术_你用过chartgpt之类的ai工具吗,一般用于提问什么类型的问题呢
- 6ROS基础系列总结_ros机器人开发基础报告
- 7小程序的登录+发布流程_微信小程序开发流程csdn
- 8Vulkan填坑学习Day27-2—多采样抗锯齿(多重采样_Multisampling)_vulkan抗锯齿失效
- 9Mybatis Plus 数据分片-水平分库分表策略_mybatisplus分库分表
- 10Mac 安装Nodejs及NPM常见问题_mac 安装npm
Spark---Master启动及Submit任务提交_spark submit
赞
踩
一、Spark Master启动
1、Spark资源任务调度对象关系图
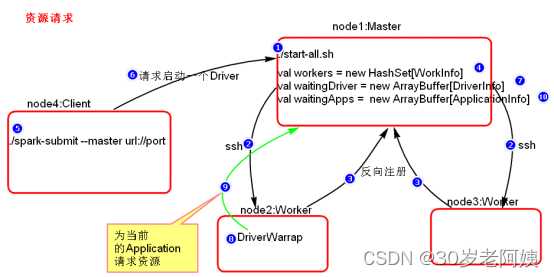
2、集群启动过程
Spark集群启动之后,首先调用$SPARK_HOME/sbin/start-all.sh,start-all.sh脚本中调用了“start-master.sh”脚本和“start-slaves.sh”脚本,在start-master.sh脚本中可以看到启动Master角色的主类:“org.apache.spark.deploy.master.Master”。在对应的start-slaves.sh脚本中又调用了start-slave.sh脚本,在star-slave.sh脚本中可以看到启动Worker角色的主类:“org.apache.spark.deploy.worker.Worker”。
- Master&Worker启动
Spark框架的设计思想是每台节点上都会启动对应的Netty通信环境,叫做RpcEnv通信环境。每个角色启动之前首先向NettyRpcEnv环境中注册对应的Endpoint,然后启动。角色包括:Master,Worker,Driver,Executor等。下图是启动start-all集群后,Master角色启动过程,Master角色的启动会调用“org.apache.spark.deploy.master.Master”主类,执行流程如下:

二、Spark Submit任务提交
- SparkSubmit任务提交
Spark submit提交任务时,调用$SPARK_HOME/bin/spark-submit spark-submit脚本中调用了“org.apache.spark.deploy.SparkSubmit”类。执行此类时,首先运行main方法进行参数设置,然后向Master申请启动Driver。代码流程如下图示:
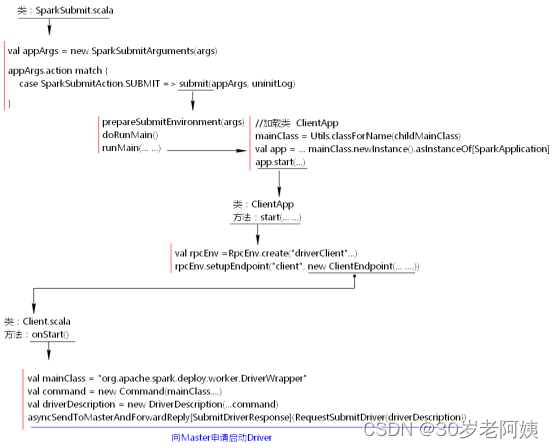
- 启动DriverWrapper类
当提交任务之后,客户端向Master申请启动Driver,这里首先会启动一个DriverWrapper类来对用户提交的application进行包装运行,DriverWrapper类的启动过程如下:
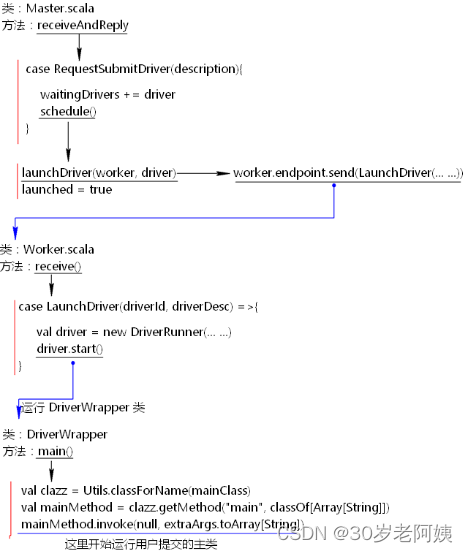
- 注册Driver Endpoint,向Master注册Application
当执行用户的代码时,在new SparkContext时,会注册真正的Driver 角色,这个角色名称为“CoarseGrainedScheduler”,Driver角色注册之后,注册“AppClient”角色,由当前这个角色向Master注册Application。代码流程如下:


