
- 1数据结构_最短路径Floyd算法(C语言)_c语言弗洛伊德法求最短路径
- 2豆瓣api接口
- 3搭建企业个人直播流媒体服务器,使用OBS推送PC桌面流到SRS_obs 推流到 srs
- 4通道注意力机制_即插即用,Triplet Attention机制让Channel和Spatial交互更加丰富(附开源代码)...
- 5【答辩重点一】计算机专业本科毕业设计答辩详细指导_计算机系本科答辩
- 6并查集详解:UF——UF_Tree——UF_Tree_Weighted逐步优化_uf-tree是有序树的意思吗
- 7HTTP请求和数据安全_epass ssl
- 8Asp .Net Core Web API Rate Limit_aspnetcoreratelimit如实现clientid自定义
- 9百度开源进行时
- 10史上最详细的安装Kali-linux教程(附视频教程)_kali下载与安装
数据结构(十三) -- C语言版 -- 树 - 二叉树的遍历(递归、非递归)_数据结构(十三) -- c语言版 -- 树 - 二叉树的遍历
赞
踩
零、读前说明
- 本文中所有设计的代码均通过测试,并且在功能性方面均实现应有的功能。
- 设计的代码并非全部公开,部分无关紧要代码并没有贴出来。
- 如果你也对此感兴趣、也想测试源码的话,可以私聊我,非常欢迎一起探讨学习。
- 由于时间、水平、精力有限,文中难免会出现不准确、甚至错误的地方,也很欢迎大佬看见的话批评指正。
- 嘻嘻。。。。 。。。。。。。。收!
二叉树是一种非线性的数据结构,在怼他进行操作时,总是需要逐一对每个元素进行操作,这样就存在一个操作的顺序的问题,由此提出二叉树的遍历的操作。
所谓二叉树的遍历就是按照一定的顺序访问二叉树的每一个节点一次且仅一次的过程,这里的访问可以是输出、比较、更新、查看元素内容等等操作。
一、递归遍历
遍历指的是:从根节点出发,按照某种次序依次访问二叉树中的所有节点,使每个节点被访问且仅被访问一次。
如果限定先左后右,那就有三种方法:
DLR – 先序遍历 :即先遍历根节点、再遍历左子树、再遍历右子树
LDR – 中序遍历 :即遍历先左子树、再遍历根节点、再遍历右子树
LRD – 后序遍历 :即遍历先左子树、再遍历右子树、再遍历根节点
还有另外一种常用的遍历的方法,
LBL – 层序遍历 : 即先从上到下,从左到右一层一层进行遍历
注: LBL 为博主自己为了在视图上和上面的统一对齐所以自己定义的名称,意取英文(layer by level)TM的缩写而成,希望不要过分关注并吐槽。嘻嘻嘻。。。
1.1、先序遍历
先序遍历:根 -> 左 -> 右
首先,用下面的一个简单的二叉树来表示先序遍历的节点遍历顺序。

首先从根节点 A 开始出发
1、将根节点的数据输出
2、判断是否存在左孩子
1)如果存在则将左孩子输出,并且以左孩子为根节点再开始往下遍历
①将此节点的数据输出
②如果存在则将左孩子输出,并且以左孩子为根节点再开始往下遍历
… …
③如果不存在左孩子,则判断并遍历右孩子
… …
2)如果不存在左孩子,则判断并遍历右孩子
①将此节点的数据输出
②如果存在则将左孩子输出,并且以左孩子为根节点再开始往下遍历
… …
③如果不存在左孩子,则判断并遍历右孩子
… …
3、判断是否存在右孩子
1)如果存在则将左孩子输出,并且以左孩子为根节点再开始往下遍历
①将此节点的数据输出
②如果存在则将左孩子输出,并且以左孩子为根节点再开始往下遍历
… …
③如果不存在左孩子,则判断并遍历右孩子
… …
2)如果不存在左孩子,则判断并遍历右孩子
①将此节点的数据输出
②如果存在则将左孩子输出,并且以左孩子为根节点再开始往下遍历
… …
③如果不存在左孩子,则判断并遍历右孩子
… …
是的,上面这么说明的过程就像一个套娃的模型,一个接一个,一层套一层。。。所以,对于上面图1.1中的这个二叉树的其先序遍历的结果为:
那么,综合所述,其遍历的代码可以这样编了。
/**
* 功 能:
* 二叉树的递归遍历 - 先序遍历
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void Traversal_Before(BiTNode *root)
{
if (root == NULL) return;
// 遍历根节点
printf("%c ", root->data);
// 遍历左子树
Traversal_Before(root->lchild);
// 遍历右子树
Traversal_Before(root->rchild);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
所以,其遍历的效果输出如下图所示咯。

1.2、中序遍历
中序遍历:左 -> 根 -> 右
首先,用下面的一个简单的二叉树来表示中序遍历的节点遍历顺序。

首先从根节点 A 开始出发
1、判断是否存在左孩子
1)如果存在则将继续判断左孩子是否也存在左孩子
①如果存在将继续判断左孩子是否也存在左孩子
… …
②如果不存在左孩子,则将本节点输出,并且回退到其父节点
③判断是否存在右孩子
… …
2)如果不存在左孩子,则将本节点输出
3)判断是否存在右孩子
①如果存在右孩子,则判断右孩子是否存在左孩子
… …
②如果不存在右孩子,则返回
2、将节点的数据输出
3、判断是否存在右孩子
1)如果存在右孩子
①如果存在右孩子,则判断右孩子是否存在左孩子
… …
2)如果不存在右孩子,则返回
是的,上面这么说明的过程就像一个套娃的模型,一个接一个,一层套一层。。。所以,对于上面图1.2中的这个二叉树的其中序遍历的结果为:
那么,综合所述,其遍历的代码可以这样编了。
/**
* 功 能:
* 二叉树的递归遍历 - 中序遍历
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void Traversal_Middle(BiTNode *root)
{
if (root == NULL) return;
// 遍历左子树
Traversal_Middle(root->lchild);
// 遍历根节点
printf("%c ", root->data);
// 遍历右子树
Traversal_Middle(root->rchild);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
所以,其遍历的效果输出如下图所示咯。

1.3、后序遍历
后序遍历:左 -> 右 -> 根
首先,用下面的一个简单的二叉树来表示后序遍历的节点遍历顺序。

首先从根节点 A 开始出发
1、判断是否存在左孩子
1)如果存在则将继续判断左孩子是否也存在左孩子
①如果存在将继续判断左孩子是否也存在左孩子
… …
②如果不存在左孩子,则判断是否存在右孩子
… …
③将本节点数据输出
… …
2)判断是否存在右孩子
①如果存在右孩子,则判断右孩子是否存在左孩子
… …
②如果不存在右孩子,则将本节点输出
3)将本节点数据输出
2、判断是否存在右孩子
1)如果存在右孩子,则判断此右孩子是否存在左孩子
①如果存在左孩子,则判断此左孩子是否也存在左孩子
… …
②如果不存在左孩子,则判断此左孩子是否还存在右孩子
… …
③如果不存在左右孩子,则将本节点输出
2)将本节点数据输出
3、将节点的数据输出
所以,对于上面图1.3中的这个二叉树的其后序遍历的结果为:
那么,综合所述,其遍历的代码可以这样编了。
/**
* 功 能:
* 二叉树的递归遍历 - 后序遍历
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void Traversal_Later(BiTNode *root)
{
if (root == NULL)
return;
// 遍历左子树
Traversal_Later(root->lchild);
// 遍历右子树
Traversal_Later(root->rchild);
// 遍历根节点
printf("%c ", root->data);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
所以,其遍历的效果输出如下图所示咯。

1.4、层序遍历
层序遍历:逐层遍历,按照树的广度(宽度)来进行遍历
首先,用下面的一个简单的二叉树来表示后序遍历的节点遍历顺序。

既然是进行逐层遍历,那么首先需要知道的是到底是这个数有多少层?
首先求出左子树的高度,然后求出右子树的深(高)度,然后谁的的深(高)度高,那么在谁的高度的基础上加1就是此树的深(高)度了。
至于代码的话那先在这个地方卖个关子。详细代码可以参考:https://blog.csdn.net/zhemingbuhao/article/details/105909106
已知树的深度,那么
1、首先从根节点 A 开始出发,此时根节点也是所谓的第一层,遍历输出
2、然后以根节点的左孩子作为新的根节点,遍历且遍历一次,然后再以根节点的右孩子作为新的根节点,遍历且遍历一次
… …
n、遍历第n层,则等同于以n-1层为根节点,遍历且遍历一次其左孩子,然后遍历一次其右孩子
那么问题又来了,怎么来保证它遍历了且只遍历一次呢?
拿在上面的这个二叉树中,以第三层的节点D为例子说明,此时遍历的层数n=3,而其根节点为第二层的B,B的根节点为根节点A(第一层),那么倒着推过来,需要遍历D节点就需要走两次递归的流程(A,B),即此时第3层减去经过的两个节点(A,B)等于1,而在开始遍历的时候根节点A的层数也为1,是不是可以推出来这样一个结论:
所以,这个就是保证遍历且遍历一次的保证的手段。
综上所述,对于上面图1.4中的这个二叉树的其层序遍历的结果为:
那么,综合所述,其遍历的代码可以这样编了。
/**
* 功 能:
* 二叉树的递归遍历 - 第i层的遍历
* 参 数:
* root:要遍历的树
* i :要遍历的层
* 返回值:
* 无
**/
void tree_Level(BiTNode *root, int i)
{
if (root == NULL || i == 0) return;
if (i == 1)
{
printf("%c ", root->data);
return;
}
tree_Level(root->lchild, i - 1);
tree_Level(root->rchild, i - 1);
}
/**
* 功 能:
* 二叉树的递归遍历 - 层序遍历
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void Traversal_Level(BiTNode *root)
{
int i = 0;
if (root == NULL) return;
for (i = 1; i <= tree.Depth(root); i++)
tree_Level(root, i);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
所以,其遍历的效果输出如下图所示咯。

说明:
二叉树的递归遍历 - 层序遍历的代码参考了大佬的博文,感谢!大佬的博客原来链接,详情请自行观摩。
二、非递归遍历
1、深度遍历的运行过程是先进后出的,自然的方法是栈和递归,包含先序遍历,中序遍历,后续遍历
2、广度遍历的运行过程是先进先出的,自然的方法是队列,包含层序遍历
2.1、中序遍历
2.1.1、数据模型分析
对于中序遍历,首先是一直访问左子树,直到左子树不存在,那么在访问左子树的过程中,会一直访问左子树的双亲节点,比如下面图中这样的情况。

为了找到最后一个左子树,他翻山越岭才千辛万苦的到达,所以在找到 D 的过程中,先后依次经历了 A -> B -> C 三个大山。那么在整个中序遍历的过程中,用一个 栈 的模型来表示貌似正好。
就像下面这样进行,从根节点开始。
1、开始遍历,判断A节点是否存在左子树,如果存在左子树,那么就需要去处理这个左子树(B),那么对于存在左子树的A节点来说,那么只能先保存起来。
2、B为A的左子树,那首先需要判断的还是是否左子树,如果存在左子树,那么就去处理这个左子树(C),B节点也需要先保存起来
3、C为B的左子树,同样先去判断是否存在左子树,存在左子树即去处理左子树,然后将C节点保存起来
4、D为C的左子树,同样先去判断是否存在左子树,此时判断D节点不存在左子树,那么也就是意味着此时最底层的左子树被找到了。那么此时D节点即为第一个被输出的节点。
4、根据中序遍历的规则,左子树已经就范,那么需要找到这个左子树的双亲节点,哎,目前最后一次保存的那个节点不就是么,那么拎出来然后输出就是了,也就是C节点。
5、接下里就是这个双亲节点(C)的右子树了,一查,就是E节点,并且E节点也没有其他的左子树什么的,那么就将E节点输出。
6、现在需要找C节点的双亲节点然后需要判断是否存在右子树等子孙,还记得么,倒数第二次保存的节点不就是么(B节点),经查没有其他子孙,拎出来输出完事
7、然后找B节点的双亲节点然后需要判断是否存在右子树等子孙,第一次保存的节点不就是么(A节点),经查也没有其他子孙,拎出来输出完事。
所以遍历的顺序为:
遍历过程中的栈的变化情况如下图所示。栈在整个遍历过程中是动态变化的,结合上面的步骤分析,可以知道在某一时刻栈中的元素就只想这样。

综上所述,所以整个遍历的过程就是一个先进去的后出来,这不就是一个 “栈”的模型么!!!
下面就用栈的模型在进行一个比较典型的树的中序遍历。树的结构图如下图所示。

1、开始遍历,指针指向A,遍历开始
A有左子树,所以A入栈
2、指针移动到A的左子树B
B没有左子树,所以B被访问
3、B有右子树,所以指针指向右子树C
C有左子树,C入栈
4、指针移动到D
D没有左子树,所以D访问
D没有右子树,那么根据栈顶回退到C,此时栈顶出栈,指针回到C位置
5、C没有右子树并且C已经被访问,所以根据目前栈顶回退到A,A被访问
此时,栈的变化的过程为如下图所示。

6、A有右子树,指针指向右子树E
E没有左子树,E被访问
7、E有右子树,指针指向了右子树F
F有左子树,F入栈
8、指针移动到左子树G
G有左子树,G入栈
9、指针移动到左子树H
H没有左子树,被访问
H没有右子树,根据栈顶回退到G,G出栈
10、指针移动到G,G有右子树I
11、指针移动到I
I没有左子树,被访问
I没有右子树,回退到栈顶F,并且访问F
12、F没有右子树,则需要回退,此时栈为空,表示此时树遍历完成
此时,栈的变化的过程为如下图所示。

综上所述,遍历的步骤可以总结为:
步骤一
1、如果节点有左子树,则该节点入栈
2、如果没有左子树,则访问该节点
步骤二
3、如果有右子树,则重复步骤一
4、如果节点没有右子树,则说明节点访问完毕,根据栈顶指示进行回退、访问栈顶节点、访问右子树然后重复步骤一
5、如果栈为空,则表示遍历结束。
2.1.2、代码实现
由上面的分析可知,此时需要用栈来实现遍历,所以,中序遍历的流程可以简单的用下面图来表示。

综上所述,那么中序遍历的代码可以这样写。
/**
* 功 能:
* 查找二叉树的左子树,直到左子树为空
* 参 数:
* root:要操作的树
* 返回值:
* 成功:最底层的左子树,也是中序遍历的第一个节点
* 失败:NULL
**/
BiTNode *checkLeftChild(BiTNode *root, LinkStack *stack)
{
if (root == NULL)
return NULL;
while (root->lchild != NULL)
{
fLinkStack.push(stack, (LinkStackNode *)root);
root = root->lchild;
}
return root;
}
/**
* 功 能:
* 二叉树的非递归遍历 - 中序遍历
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void nonTraversal_Middle(BiTNode *root)
{
if (root == NULL)
return;
// 创建一个栈
LinkStack *stack = fLinkStack.create();
// 一直往左走,判断是否存在左孩子,找到中序遍历的起点
BiTNode *tree = checkLeftChild(root, stack);
while (tree)
{
printf("%c ", tree->data);
// 如果tree有右子树,重复步骤一
if (tree->rchild != NULL)
{
tree = checkLeftChild(tree->rchild, stack); // 右子树中序遍历的起点
}
// 如果tree没右子树,根据栈顶回退
else if (fLinkStack.length(stack) > 0) // 如果栈不为空
{
tree = fLinkStack.top(stack); // 或者可以使用 stack.pop(),看具体的实现
fLinkStack.pop(stack);
}
else // 如果没有右子树,并且栈为空
{
tree = NULL;
}
}
fLinkStack.destroy(stack);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
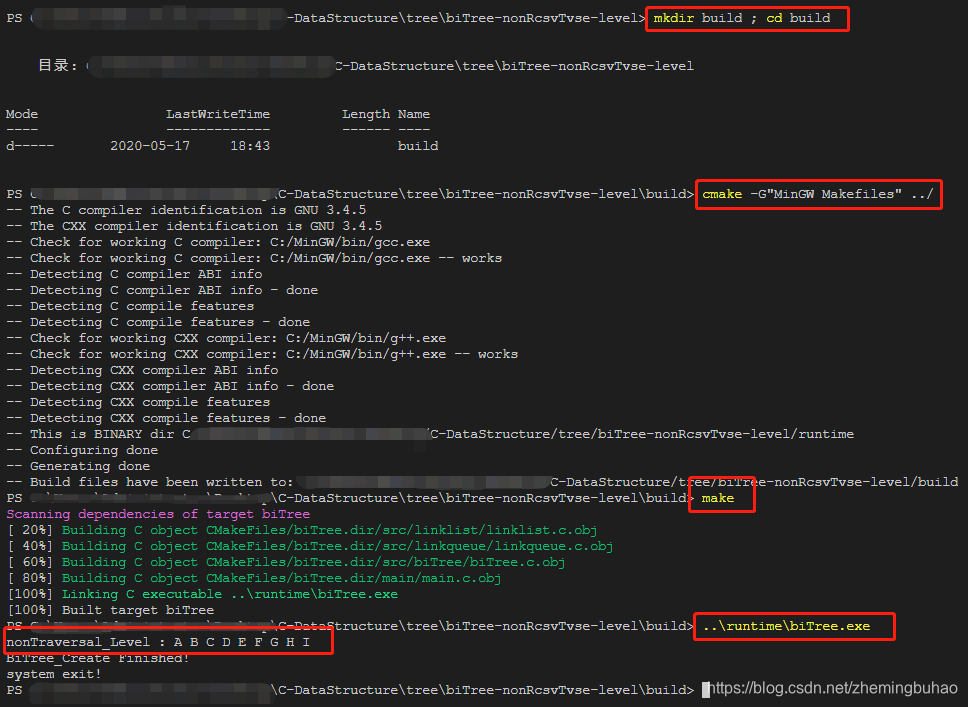
所以,其遍历的效果输出如下图所示咯。

2.2、先序遍历
2.2.1、数据模型分析
先序遍历:根节点 –> 左孩子 -> 右孩子
首先建立一个栈
1、从根节点开始遍历,当指针到达根结点时,打印根结点
2、然后判断根结点是否有左孩子和右孩子
1)如果当前结点存在左孩子
①如果存在右孩子,则将右孩子入栈
②打印左孩子,并且将左孩子作为新的根结点进行判断
2)如果当前结点没有左孩子,则开始判断是否存在右孩子,接下面3
3、然后判断根结点是否存在右孩子
1)如果存在右孩子,将右孩子打印,同时将右孩子作为新的根结点判断。
2)如果没有右孩子,则打印左孩子,同时将左孩子作为新的根结点判断。
4、如果当前结点既没有左孩子也没有右孩子
1)则说明当前结点为叶子结点,此时将从栈中出栈一个节点,将此节点作为当前的根结点
①打印结点
②将当前结点同样按上面1、2、3、4开始依次判断
2)直至当前结点的左右孩子都为空,且栈为空时,遍历结束。
其实总结一句话就是:
从根节点开始,沿着左孩子依次访问途中经过的根节点,同时将右孩子入栈,在遍历访问完左子树后出栈得到右子树作为根节点,如此重复,直到栈空。则完成遍历。
2.2.2、代码实现
由上面的分析可知,此时需要用栈来实现遍历,所以,先序遍历的流程可以简单的用下面图来表示。

综上所述,那么先序遍历的代码可以这样写。
/**
* 功 能:
* 二叉树的非递归遍历 - 先序遍历
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void nonTraversal_Before(BiTNode *root)
{
if (root == NULL) return;
LinkStack *stack = fLinkStack.create();
while (root || fLinkStack.length(stack) > 0)
{
while (root)
{
printf("%c ", root->data);
fLinkStack.push(stack, (LinkStackNode *)root);
root = root->lchild;
}
root = fLinkStack.pop(stack);
root = root->rchild;
}
fLinkStack.destroy(stack);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
所以,其遍历的效果输出如下图所示咯。

2.3、后序遍历
2.3.1、数据模型分析与概要
后序遍历:左孩子 –> 右孩子 -> 根节点
从前面的递归遍历中可以看出来,后序遍历,和先序遍历、中序遍历的区别只是对于节点访问色顺序的变化,所以,在使用到非递归遍历的时候我们使用到的还是栈去实现后序遍历的非递归实现。
但是,对于后序遍历,是先访问左、再访问右子树,然后才访问根节点,在非递归算法中,途经但是不输出的节点需要入栈,但是无论如何,遍历的顺序不能改变,所以在利用栈回退时,并不能确定是从左子树回退到根节点,还是从右子树回退到根节点的,如果从左子树回退到根节点,此时就应该去访问右子树,而如果从右子树回退到根节点,此时就应该访问根节点。
所以这也导致了树的后续非递归遍历的实现也有一定的难度,但是同样的,难度增加意味着需要实现的步骤可能多,那么同样实现的方式也比较多样了。所以,在这儿我大概采用几种比较常见的方式来实现。
2.3.2、实现方法一
首先采用一种比较简单的实现方式,,其主要实现的过程为:
这种遍历方法类似于前序遍历,但是又不是先序遍历,这种遍历的大致思路就是:
1、先将按照 根节点 -> 右孩子 -> 左孩子 的顺序进行遍历,然后将遍历要输出的节点保存起来
2、然后将上面保存起来的数据进行翻转,然后输出即可实现后序遍历的效果。
那么先看看所使用递归的方式来验证一下这种遍历的正确性吧。
实现的代码可以这样写。
/**
* 功 能:
* 二叉树的递归遍历 - 类似于先序遍历
* 遍历的顺序为 : 根节点 -> 右子树 -> 左子树
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void Traversal_rrl(BiTNode *root)
{
if (root == NULL) return;
// 遍历根节点
printf("%c ", root->data);
// 遍历右子树
Traversal_rrl(root->rchild);
// 遍历左子树
Traversal_rrl(root->lchild);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
编译运行之后的效果如图所示。

有上面的图片可以看出来,这种遍历的输出顺序正好和后序遍历的输出是相反的,那么翻转后就是后序遍历的输出了。
综上所述,使用非递归实现 根节点 -> 右子树 -> 左子树 的顺序的代码可以这样写。
/**
* 功 能:
* 二叉树的非递归遍历,遍历顺序 : 根节点 -> 右子树 -> 左子树
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void postOrder_Root_Right_Left(BiTNode *root)
{
if (root == NULL) return;
// 创建一个栈
LinkStack *stack = fLinkStack.create();
fLinkStack.push(stack, root);
while (fLinkStack.length(stack) > 0)
{
root = fLinkStack.pop(stack);
if (root->lchild != NULL)
{
fLinkStack.push(stack, (LinkStackNode *)root->lchild);
}
if (root->rchild != NULL)
{
fLinkStack.push(stack, (LinkStackNode *)root->rchild);
}
printf("%c ", root->data);
}
// 销毁栈
fLinkStack.destroy(stack);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
完成上面的部分代码,对于树的后序遍历只能是完成了一半,我们还需要进行数据的翻转才能算是完成后序遍历的操作,那么对于数据的翻转,相信大家已经很很多种方法可以实现,那么在本文中,为了照顾绝大多数人,采用两种比较简单的方式分别进行实现。
一、将要遍历输出的节点的值先保存在数组中,然后将数组进行反向输出即口。请注意:此处说的是尽心反向输出,而不是将数组进行翻转。
所以代码可以这样写咯。
/**
* 功 能:
* 二叉树的非递归遍历 - 后序遍历
* 遍历顺序 : 根节点 -> 右子树 -> 左子树
* 采用数组进行翻转输出
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void postorder_Root_Right_Left_Array(BiTNode *root)
{
if (root == NULL)
return;
// 定义一个数组,用于保存遍历过程中要输出的节点的值
unsigned char buf[512] = {0};
// 定义一个变量,用于记录树的节点的个数
int i = 0, cnt = 0;
// 创建一个栈
LinkStack *stack = fLinkStack.create();
// 将根节点进行入栈
fLinkStack.push(stack, root);
// 判断栈是否为空
while (fLinkStack.length(stack) > 0)
{
// 出栈
root = fLinkStack.pop(stack);
// 将出栈的节点作为新的根节点,判断出栈的节点是否存在左孩子或者右孩子
if (root->lchild != NULL)
{
// 节点是存在左孩子或者右孩子,直接入栈
fLinkStack.push(stack, (LinkStackNode *)root->lchild);
}
// 将出栈的节点作为新的根节点,判断出栈的节点是否存在左孩子或者右孩子
if (root->rchild != NULL)
{
// 节点是存在左孩子或者右孩子,直接入栈
fLinkStack.push(stack, (LinkStackNode *)root->rchild);
}
// 将原本要输出的节点保存到数组中
// printf("%c ", root->data);
buf[cnt++] = root->data;
}
// 将数组进行反向输出
for (i = cnt; i > 0; i--)
printf("%c ", buf[i - 1]);
// 销毁栈
fLinkStack.destroy(stack);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
二、提到数据的翻转或者反向,那么栈的天然特性可以毫不费力的实现。
所以代码可以这样写咯。
/**
* 功 能:
* 二叉树的非递归遍历 - 后序遍历
* 遍历顺序 : 根节点 -> 右子树 -> 左子树
* 采用 栈 进行翻转输出
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void postOrder_Root_Right_Left_Stack(BiTNode *root)
{
if (root == NULL)
return;
// 创建一个栈,用于遍历过程中记录节点
LinkStack *stack1 = fLinkStack.create();
// 在创建一个栈,用于在输出的节点的翻转
LinkStack *stack2 = fLinkStack.create();
// 将根节点进行入栈
fLinkStack.push(stack1, root);
// 判断栈是否为空
while (fLinkStack.length(stack1) > 0)
{
// 出栈
root = fLinkStack.pop(stack1);
// 将出栈的节点作为新的根节点,判断出栈的节点是否存在左孩子或者右孩子
if (root->lchild != NULL)
{
// 节点是存在左孩子或者右孩子,直接入栈
fLinkStack.push(stack1, (LinkStackNode *)root->lchild);
}
// 将出栈的节点作为新的根节点,判断出栈的节点是否存在左孩子或者右孩子
if (root->rchild != NULL)
{
// 节点是存在左孩子或者右孩子,直接入栈
fLinkStack.push(stack1, (LinkStackNode *)root->rchild);
}
// 将原本要输出的节点保存到 栈 中
// printf("%c ", root->data);
fLinkStack.push(stack2, root);
}
// 将栈中的节点输出
while (fLinkStack.length(stack2) > 0)
{
root = fLinkStack.pop(stack2);
printf("%c ", root->data);
}
// 销毁栈
fLinkStack.destroy(stack1);
fLinkStack.destroy(stack2);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
2.3.3、实现方法二
后序遍历,其的主要的难点在于如何去判断并且确定是 栈的回退 是从 左孩子 回退的还是 从右孩子 回退的用一种方法来去确定回退的根源,那么剩下的遍历过程与先序遍历和中序遍历相差不大了。所以相比前序和后序,后序遍历必须要在压栈时添加信息或者在出栈的时候去做相应的判断。
下面的两种实现方式都采用的是在元素出栈的时候保存节点,然后在下次遍历的过程中的栈顶元素比较来确定当前需要去遍历的是左子树还是右子树。其中主要的代码实现如下所示。
实现代码一:
/**
* 功 能:
* 二叉树的非递归遍历 - 后序遍历
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void nonTraversal_Post(BiTNode *root)
{
if (root == NULL)
return;
// 创建一个栈
LinkStack *stack = fLinkStack.create();
BiTNode *top = NULL, *temp = NULL;
// 节点存在并且栈不为空
while (root || fLinkStack.length(stack) > 0)
{
// 节点存在
while (root) // 从当前节点开始判断是否存在左孩子,一直到最后一个左孩子节点
{
// 将当前节点入栈
fLinkStack.push(stack, (LinkStackNode *)root);
// 将指针指向左孩子节点,然后判断是否存在左孩子
root = root->lchild;
}
// 左孩子不存在,此时获取栈顶元素,根据栈顶元素进行下一步
top = fLinkStack.top(stack);
// 判断是否存在右孩子
// 或者栈顶元素的右孩子与出栈的元素相同
if (top->rchild == NULL || top->rchild == temp)
{
// 如果不存在右孩子,则说明此节点为叶子节点,将节点值打印
printf("%c ", top->data);
// 将此节点出栈,并记录下来用作下次栈顶元素的右孩子的判断
// 用于判断是从左孩子回退的还是右孩子回退的
temp = fLinkStack.pop(stack);
}
else
{
// 将指针指向右孩子节点,然后重新开始判断
root = top->rchild;
}
}
// 销毁栈
fLinkStack.destroy(stack);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
实现代码二:
/**
* 功 能:
* 二叉树的非递归遍历 - 后序遍历
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void nonTraversal_PostOrder(BiTNode *root)
{
if (root == NULL)
return;
// 创建一个栈
LinkStack *stack = fLinkStack.create();
BiTNode *top = root, *temp = NULL;
// 将根节点入栈
fLinkStack.push(stack, root);
// 判断栈是否为空
while (fLinkStack.length(stack) > 0)
{
// 获取栈顶元素,并判断是否有左右孩子
top = fLinkStack.top(stack);
// 不存在左右孩子,表示此节点为叶子节点
// 根据栈顶元素与上次出栈的元素判断来确定是从左或者右孩子回退的
if ((top->lchild == NULL && top->rchild == NULL) ||
((temp == top->lchild || temp == top->rchild) && temp != NULL))
{
printf("%c ", top->data);
// 出栈,并记录下来用作下次栈顶元素的右孩子的判断
temp = fLinkStack.pop(stack);
}
else // 存在左右孩子,入栈
{
if (top->lchild != NULL)
{
fLinkStack.push(stack, top->lchild);
}
if (top->rchild != NULL)
{
fLinkStack.push(stack, top->rchild);
}
}
}
// 销毁栈
fLinkStack.destroy(stack);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
综上所述,所有的实现的方法的效果图如下图所示咯。

2.4、层序遍历
2.4.1、数据模型分析
层序遍历:从根节点开始,逐层开始遍历
对于层序遍历呢,和前面的几种遍历的方式不同点在于,层序层遍历的时候需要从左到右依次去判断此节点是否存在左孩子、右孩子,如果存在左孩子,那么需要将左孩子存起来,然后再去判断右孩子,如果也存在,那么也需要存起来,这样的话,可以完整的判断出当前节点的左右孩子的情况,然后在遍历输出的时候需要先将左孩子输出,再将右孩子输出,这样的话,从存储到取出的顺序来说的话,明显就是一个先进先出的模型,所以采用队列来进行层序遍历的实现。
那么,遍历的思路可这样。
首先创建一个队列
1、从根节点开始遍历,先将根节点入队
2、判断此时队列是否为空
1)如果队列不为空,说明此时节点存在
2)将节点出队列,并且将此节点输出
3)将此节点作为新的根节点,判断此节点是否存在左孩子、右孩子
①如果存在左孩子,则将左孩子入队
②如果存在右孩子,则将右孩子入队
4)如果不存在左孩子右孩子,则返回判断队列是否为空
3、队列为空,则说明遍历结束
2.4.2、代码实现
由上面的分析可知,此时需要用队列来实现遍历,所以,层序遍历的流程可以简单的用下面图来表示。

综上所述,那么层序遍历的代码可以这样写。
/**
* 功 能:
* 二叉树的非递归遍历 - 层序遍历
* 参 数:
* root:要遍历的树
* 返回值:
* 无
**/
void nonTraversal_Level(BiTNode *root)
{
if (root == NULL)
return;
// 创建一个队列
LinkQueue *queue = fLinkQueue.create();
// 将树的根节点入队列
fLinkQueue.append(queue, (LinkQueueNode *)root);
// 队列不为空
while (fLinkQueue.length(queue) > 0)
{
// 出队列,并且将出队列的节点作为根节点进行左右孩子的判断
root = fLinkQueue.subtract(queue);
printf("%c ", root->data);
// 判断是否存在左孩子,存在直接将左孩子入队列
if (root->lchild != NULL)
{
fLinkQueue.append(queue, root->lchild);
}
// 判断是否存在右孩子,存在直接将右孩子入队列
if (root->rchild != NULL)
{
fLinkQueue.append(queue, root->rchild);
}
}
fLinkQueue.destroy(queue);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
所以,其遍历的效果输出如下图所示咯。
本文总结了树的几种遍历方法,分别是递归先序遍历、递归中序遍历、递归后续遍历、递归层序遍历、非递归先序遍历、非递归中序遍历、非递归后续遍历、非递归层序遍历,总共8中遍历方式。所有的方式均已经完美实现,写作不易,如果你觉得文章不错或者对你有用,请动动你那发财的小手 点个赞 啦,当然 关注一波 那就更好啦,哈哈哈哈。。。。


上一篇:数据结构(十二) – C语言版 – 树 - 二叉树的创建与销毁
下一篇:数据结构(十四) – C语言版 – 树 - 二叉树的叶子节点、深度、拷贝等

