
- 1Ubuntu-openssh 升级_ubuntu22.04升级ssh
- 256. UE5 RPG 给敌人添加AI实现跟随玩家_ue5 possessedby方法
- 3如何判断样本标注的靠谱程度?置信度学习(CL)简述
- 4python multiprocessing Queue踩坑_python multiprocessing queue 丢数据
- 5统计分析文章中英文单词出现次数及频率(C++实现)_输入一篇文章(文章以半角句号结束),统计其中出现的单词(连续的字母)及出现频率,若(1)_c++单词频率编写
- 6Mac安装YouCompleteMe出现Unexpected exit code -11的解决方案
- 7Activiti:开源流程引擎,Java语言开发的强大工具_activiti开源项目
- 8VMware安装CentOS 8系统_centos8iso映像文件
- 9通义千问Qwen-VL-Chat大模型本地部署(一)
- 10【16】Android基础知识之Window(二) - ViewRootImpl
【布隆过滤器(Bloom Filter)】数据结构:高效判断元素是否存在_布隆过滤器判断一个值是否存在
赞
踩
上一篇博客【位图(Bitmap)】:数据结构:高效存储与处理大量数据 的末尾,提到了布隆过滤器这种数据结构,且位图是布隆过滤器的基础数据结构,而布隆过滤器则是在位图的基础上实现了一种概率型的元素存在性判断方法。
目录
一、布隆过滤器是什么?
1.布隆过滤器的提出
一个像 Yahoo,Hotmail 和 Gmai 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃
圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。
如果用哈希表,每存储一亿个 email 地址, 就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个email 地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB, 即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。除非是超级计算机,一般服务器是无法存储的。
- 用哈希表存储用户记录,缺点:浪费空间或空间不足。
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了。
- 将哈希与位图结合,即布隆过滤器
2.布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
二、布隆过滤器的实现
布隆过滤器的基本思想是:
使用多个哈希函数和一个位数组来表示一个集合,位数组也就是上篇博客介绍的位图。
1.布隆过滤器的插入
当元素被加入集合时,分别使用多个哈希函数计算出多个哈希值,并将对应位数组的值置为1。
示例如下:
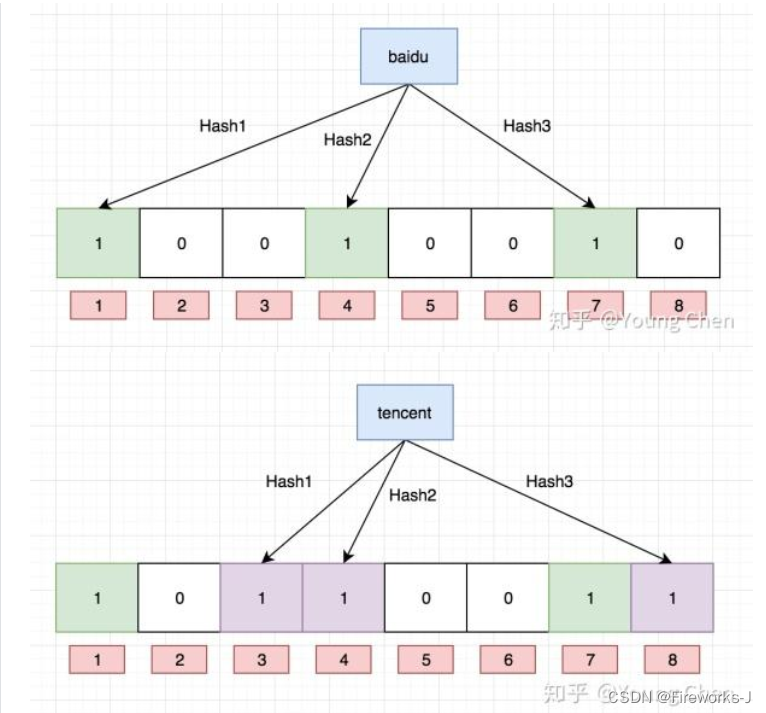
2.布隆过滤器的查找
当判断一个元素是否属于集合时,同样使用多个哈希函数计算哈希值,检查对应位数组的值,如果所有对应位的值都为1,则该元素可能存在于集合中,如果有任何一位为0,则可以确定该元素一定不在集合中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实际上该元素是不存在的。
3.布隆过滤器模拟实现
根据上述思想,可以列出实现一个布隆过滤器的几个关键步骤:
-
初始化位数组:首先需要初始化一个包含 m 位的位数组,将所有位的值都设为 0。
-
选择哈希函数:选择 k 个不同的哈希函数,这些哈希函数可以将输入映射到位数组中的位置。通常可以使用不同的哈希函数来计算出多个哈希值。
-
插入元素:当要向布隆过滤器中插入一个元素时,使用 k 个哈希函数分别计算出元素的 k 个哈希值,并将对应位数组的这 k 个位置设为 1。
-
查询元素:当要查询一个元素是否存在于布隆过滤器中时,同样使用 k 个哈希函数计算出元素的 k 个哈希值,然后检查对应位数组的这 k 个位置的值,如果所有位置的值都为 1,那么可能存在于集合中;如果有任何一个位置的值为 0,那么可以确定该元素一定不存在于集合中。
- import java.util.BitSet;
-
- //构建哈希函数
- class SimpleHash {
- private int cap; //容量
- private int seed; //随机种子
-
- public SimpleHash(int cap, int seed) {
- this.cap = cap;
- this.seed = seed;
- }
-
- //字符串转成哈希值
- public int hash(String key) {
- int h;
- //根据不同的seed,得到不同的哈希值
- return (key == null) ? 0 : (seed * (cap - 1)) & ((h = key.hashCode()) ^ (h >>> 16));
- }
- }
-
- public class BloomFilter {
- public static final int DEFAULT_SIZE = 1 << 24; //方便哈希函数的计算
- public static final int[] seeds = {5, 7, 11, 13, 31, 37, 61};
-
- private BitSet bitset; //位图存储元素
- private int usedSize;
- private SimpleHash[] simpleHashes; //哈希函数所对应类,以构建多个哈希函数
-
- public BloomFilter() {
- bitset = new BitSet(DEFAULT_SIZE);
- simpleHashes = new SimpleHash[seeds.length];
- for (int i = 0; i < simpleHashes.length; i++) {
- //初始化所有哈希对象
- simpleHashes[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
- }
- }
-
- /**
- * 添加元素到布隆过滤器
- * @param val 待添加元素
- */
- public void add(String val) {
- for (SimpleHash simpleHash : simpleHashes) {
- //每个哈希函数生成的位置都存储到位图中
- bitset.set(simpleHash.hash(val));
- }
- }
-
- /**
- * 是否包含val,这里会存在误判
- */
- public boolean contains(String val) {
- for (SimpleHash simpleHash : simpleHashes) {
- //如果bitset中有任一位为0,那么一定不包含val
- if (!bitset.get(simpleHash.hash(val))) {
- return false;
- }
- }
- return true;
- }
-
- //测试
- public static void main(String[] args) {
- BloomFilter bloomFilter = new BloomFilter();
- bloomFilter.add("hello");
- bloomFilter.add("bit");
- bloomFilter.add("baidu");
-
- System.out.println(bloomFilter.contains("baidu"));
- System.out.println(bloomFilter.contains("bai"));
- }
- }

4.布隆过滤器的删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
缺陷:
1. 无法确认元素是否真正在布隆过滤器中【会有误判】
2. 存在计数回绕【回绕意思为:溢出】
三、布隆过滤器的特性与应用
1.布隆过滤器的优点
-
空间效率高:布隆过滤器使用位数组来表示集合中的元素,在能够承受一定的误判时,相比于其他数据结构(如哈希表),需要更少的内存空间。
-
查询速度快:由于布隆过滤器使用多个哈希函数来计算哈希值,并且通过位操作来判断元素是否存在,查询速度非常快,时间复杂度为 O(k),其中 k 是哈希函数的数量。
-
保密性好:布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势。
-
可伸缩性好:布隆过滤器在需要处理大规模数据时依然能够保持良好的性能,可以根据需求动态调整位数组大小和哈希函数数量。
-
适用于大数据场景:在处理海量数据时,布隆过滤器可以有效地降低内存占用,同时提供快速的元素查询功能。且布隆过滤器可以表示全集(所有数据),其他数据结构不能。
-
简化操作:使用同一组散列函数的布隆过滤器可以进行交、并、差运算。
2.布隆过滤器的缺陷
-
误判率:布隆过滤器会存在一定的误判率,即可能会将不属于集合的元素误判为属于集合(false positive)。这是因为多个元素经过哈希函数计算后可能映射到相同的位上,导致冲突。
-
无法删除元素:一旦元素被加入布隆过滤器,就无法从中删除。因为删除元素会影响到其他元素的判断结果,需要额外的技巧来实现删除操作。
-
不支持部分匹配查询:布隆过滤器只能用于检查元素是否存在于集合中,无法支持部分匹配或模糊查询。
-
位数组大小和哈希函数数量的选择困难:为了控制误判率,需要事先确定位数组的大小和哈希函数的数量,这需要根据预期存储的元素数量和误判率进行合理的估计和调整。
-
性能受哈希函数质量影响:布隆过滤器的性能受到哈希函数的质量和分布均匀性的影响,不同的哈希函数可能导致不同的性能表现。
-
不能获取元素本身。
3.布隆过滤器的使用场景
- google的guava包中有对Bloom Filter的实现。
- 网页爬虫对URL的去重,避免爬去相同的URL地址。
- 垃圾邮件过滤,从数十亿个垃圾邮件列表中判断某邮箱是否是垃圾邮箱。
- 解决数据库缓存击穿,黑客攻击服务器时,会构建大量不存在于缓存中的key向服务器发起请求,在数据量足够大的时候,频繁的数据库查询会导致挂机。
- 秒杀系统,查看用户是否重复购买。
布隆过滤器的拓展(含guava包对Bloom Filter的实现):https://www.cnblogs.com/zc110/articles/13380446.html


