
- 112个RAG常见痛点及解决方案_rag 论文
- 2关于GitLab登录/推送/拉取代码时候报错(remote: HTTP Basic: Access deniedfatal: Authentication failed fo ‘xxxx‘.)_gitlab拉取代码到本地报错
- 3Linux Debian12命令终端安装pip install rsa报错error: externally-managed-environment_archlinux externally-managed
- 4[管理与领导-15]:IT基层管理者 - 自我管理 - 转型前的思维误区与思维转变_新晋管理者常见的12个误区
- 5Github 标星 3w+,热榜第一,实现所有算法!
- 6程序员真的是吃青春饭的吗?_程序员是吃青春饭的职业吗
- 7java中级面试题 含答案
- 8Follow That Page - web monitor: we send you an email when your favorite page has changed.
- 9【大模型微调】一文掌握7种大模型微调的方法
- 10如何做好测试用例评审_系统测试案例评审要做什么
cuda编程(一)cuda简介
赞
踩
本文来自樊哲勇的《CUDA编程:基础与实践》笔记。
1.GPU简介
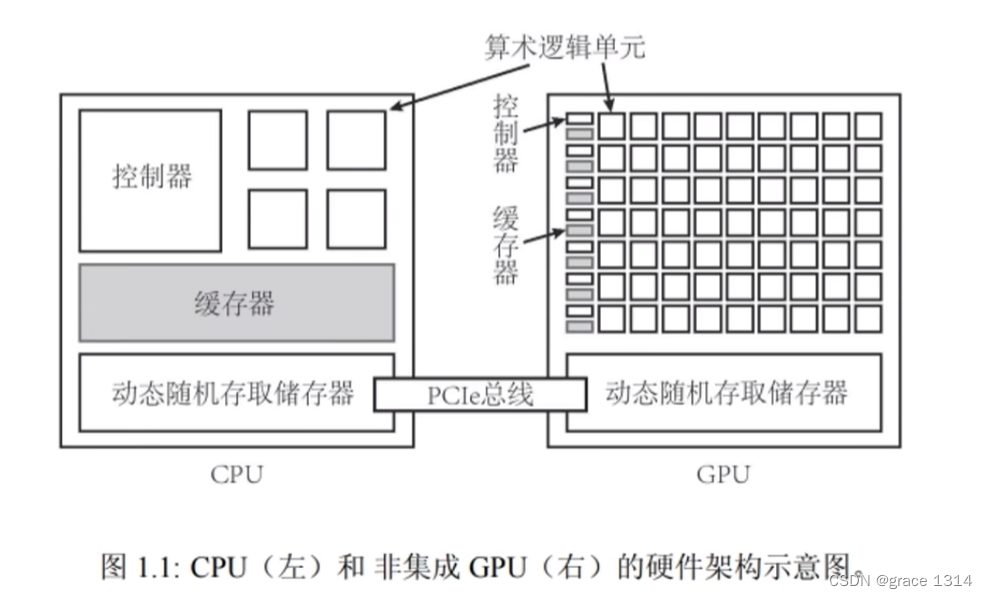
处理器一般包含cache 缓存,ALU 计算单元,contrl 控制中心,ram 内存。
GPU(graphics processing unit)概念,图形处理器,也称显卡(graphics card),适合进行密集数据运算,包含大量ALU计算核心。
CPU(central processing unit)概念,中央处理器,适合进行逻辑,ALU计算核心较少。适合控制性密集任务。
GPU的浮点运算峰值比同时期的CPU高一个量级。而GPU的内存带宽峰值也比同时期CPU高一个量级。
CPU与GPU的显著区别:
一个典型的CPU拥有少数几个快速的计算核心,而一个典型的GPU拥有几百到几千个不那么快速的计算核心。
CPU中有更多的晶体管用于数据缓存(cache)和流程控制(contrl),但GPU中有更多的晶体管用于算术逻辑单元(ALU)。
所以GPU时靠众多的计算核心来获得相对较高的计算性能的。
CPU与GPU都有一个动态随机存取存储器,通过PCle总线进行交互。
CPU+GPU异构架构:
异构计算(heterogeneous,computing)
GPU本身并不能单独计算,CPU+GPU组成异构(heterogenerous)计算架构;
一块单独的GPU是无法独立完成所有计算任务的,它必须在CPU的调度下才能完成特定任务。
CPU起到控制作用,称为Host,主机
GPU作为CPU的协处理器,一般称为Device,设备
主机和设备之间都有自己的DRAM(dynamic random-access memory,动态随机存取内存。),内存访问一般通过PCLe总线连接。
小型任务并不能加速,适合处理大型任务
GPU性能指标:
1.核心数
2.GPU显存容量 ,可计算量越大
3.GPU计算峰值,最大计算能力
计算能力越大并不代表着计算性能越高。
表征计算性能的一个重要参数式浮点数的运算峰值,即每秒最多能执行的浮点数运算次数,英文维Floating-point operations per second,缩写维FLOPS。GPU的浮点数运算峰值在10^12 FLOPs,即teraFLOPS量级。
浮点数运算峰值有单精度和双精度之分。对Tesla系列的GPU来说,双精度浮点数运算峰值一般是单精度浮点数运算峰 值的左右(对计算能力为3.5和3.7的GPU来说,是左右)。对GeForce系列 的GPU来说,双精度浮点数运算峰值一般是单精度浮点数运算峰值的左右。
所以对于计算双精度还是Tesla好,GeForce双精度就差好多。
4.显存带宽,运算单元与显存的传输速率,带宽越大,交换速率越大
GPU中的内存常称为显存。显存容量式制约应用程序性能的一个因素。
目前支持CUDA编程的只有英伟达Nvidia公司推出的GPU,如Quadro OpenGL渲染,专业绘图设计,GeForce游戏娱乐,科学计算,Jetson嵌入式设备。
GPU并不是计算能力越高,性能就越高,两者之间没有简单的正比关系。
什么是CUDA?(异构编程语言)
CUDA(compute unified device architecture)统一计算设备架构
其他异构编程语言,如OpenCL(open computing language),OpenACC(open accelerators),和CUDA Fortan。
OpenCL。这是一个更为通用的为各种异构平台编写并行程序的框架,也是AMD(Ad vanced Micro Devices)公司的 GPU 的主要程序开发工具。
CUDA是一个软件平台,配合GPU使用。
CUDA建立在NVIDIA的CPU上的一个通用并行计算平台和编程模型
基于GPU的并行训练已经是目前深度学习的标配。
CUDA支持C++,python,java。
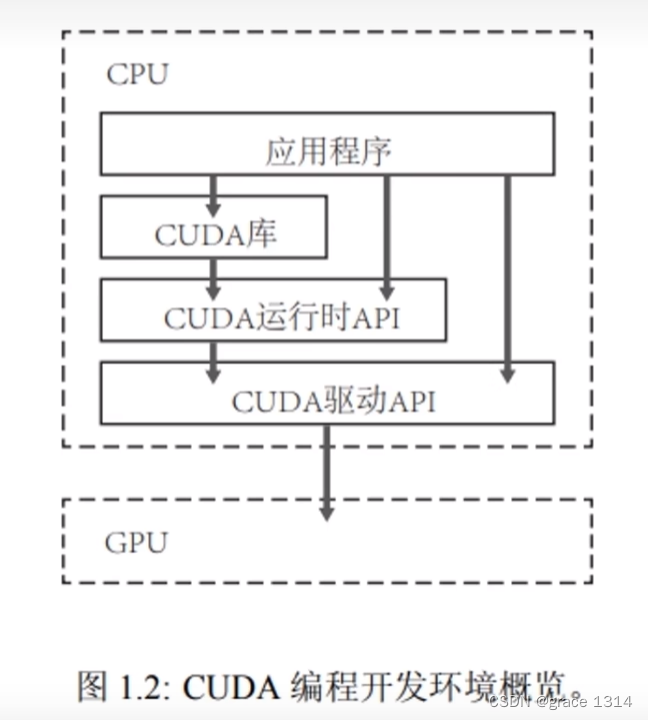
CUDA运行时的API:
CUDA提供两层API接口(Application Programming Interface,应用程序编程接口),CUDA驱动(driver)API和CUDA运行时(runtime)API。
CUDA驱动API式更加底层的API,它为程序员提供了更为灵活的编程接口。
CUDA运行时API式在CUDA驱动API的基础上构建的一个更为高级的API。
从程序的可读性来看,使用CUDA运行时API是更好的选择。在其他编 程语言中使用CUDA的时候,驱动API很多时候是必需的。
两种API调用性能几乎无差异,VS中使用Runtime API
CUDA的版本是GPU软件开发平台的版本,而计算能力对应着GPU硬件架构的版本。
在CUDAC++程序中,既有运行于主机的代码,也有运行于设备的代码。其中,运行于主机的代码需要由主机 的C++编译器编译和链接。
CUDA安装,请查阅其他资料,很多,这里就不列举。
用nvidia-smi 检查与设置设备
nvidia-smi (Nvidia’ssystem management interface)程序检查与设置设备
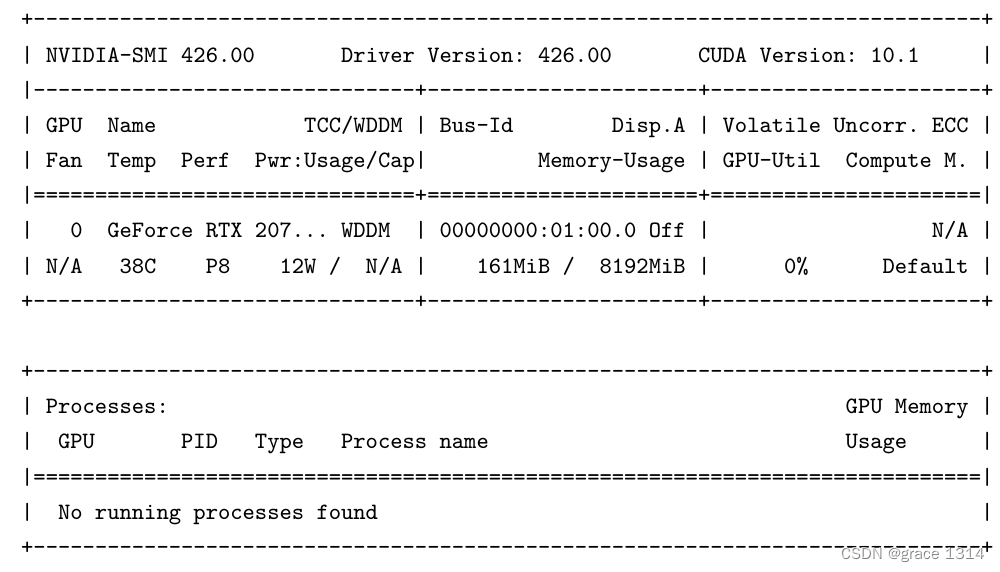 第一行可以看到Nvidiadriver的版本及CUDA工具箱的版本。
第一行可以看到Nvidiadriver的版本及CUDA工具箱的版本。
如果系统中有多个GPU,而且只需要使用某个特定的GPU(比如两个之中更强大的那个), 则可以通过设置环境变量CUDA_VISIBLE_DEVICES 的值在运行CUDA程序之前选定一个GPU。

假如系统中有编号为0和1的两个GPU,想在1号GPU运行CUDA程序,则可以用上面命令设置环境变量。这样设置的环境变量在当前shell session及其子进程中有效。
GPU模式:
GPU处于WDDM(windowsdisplaydrivermodel)模式。另一个可能的模式是TCC (tesla compute cluster)
GPU计算模式
Default :在默认模 式中,同一个GPU中允许存在多个计算进程,但每个计算进程对应程序的运行速度 一般来说会降低。
E.Process,指的是独占进程模式(exclusiveprocess mode),但不适用于处于WDDM模式的GPU。在独占进程模式下,只能运行一个计算进程独占该GPU。

