
LLMs之InternLM:InternLM-7B模型的简介、安装、使用方法之详细攻略
赞
踩
LLMs之InternLM:InternLM-7B模型的简介、安装、使用方法之详细攻略
导读:InternLM有 1040亿参数,是在包含1.6万亿token的多语种高质量数据集上训练而成。同时,InternLM-7B完全可商用,支持8k语境窗口长度,中文超ChatGPT,训练和评估动态反馈调整,基于ML deploy部署(基于Fast Transform研发)快速加载大模型,比Transform快到2~3倍,Hybrid Zero提速 ,开放OpenCompass 评测标准。
目录
LLMs之InternLM:InternLM-7B模型的简介、安装、使用方法之详细攻略
LLMs之InternLM:InternLM-20B的简介、安装、使用方法之详细攻略
1、使用 LMDeploy 完成 InternLM 的一键部署。
1、通过以下的代码加载 InternLM 7B Chat 模型
(1)、通过以下的代码加载 InternLM 7B Chat 模型
相关文章
论文简介
LLMs之InternLM:InternLM-7B模型的简介、安装、使用方法之详细攻略
LLMs之InternLM:InternLM/InternLM-7B模型的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之InternLM:InternLM-20B的简介、安装、使用方法之详细攻略
LLMs之InternLM:InternLM-20B的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
代码实战
更新中……
InternLM模型的简介
2023年6月7日,上海人工智能实验室(上海AI实验室)、商汤科技联合香港中文大学、复旦大学及上海交通大学发布千亿级参数大语言模型“书生·浦语”(InternLM)。“书生·浦语”具有 1040亿参数,是在包含1.6万亿token的多语种高质量数据集上训练而成。全面评测结果显示,“书生·浦语”不仅在知识掌握、阅读理解、数学推理、多语翻译等多个测试任务上表现优秀,而且具备很强的综合能力,因而在综合性考试中表现突出,在多项中文考试中取得超越ChatGPT的成绩,其中就包括中国高考各科目的数据集(GaoKao)。
2023年7月6日,在2023世界人工智能大会(WAIC)科学前沿全体会议上,深度学习与计算机专家、上海人工智能实验室教授、香港中文大学教授林达华,发布了“书生通用大模型体系”(以下简称“书生大模型”),包括书生·多模态、书生·浦语InternLM和书生·天际LandMark等三大基础模型,以及首个面向大模型研发与应用的全链条开源体系。当天,正式开源的版本为一个70亿参数的轻量级InternLM-7B,在包含40个评测集的全维度评测中展现出卓越且平衡的性能,全面领先现有开源模型。
InternLM ,即书生·浦语大模型,包含面向实用场景的70亿参数基础模型与对话模型 (InternLM-7B)。模型具有以下特点:
- 使用上万亿高质量预料,建立模型超强知识体系;
- 支持8k语境窗口长度,实现更长输入与更强推理体验;
- 通用工具调用能力,支持用户灵活自助搭建流程;
提供了支持模型预训练的轻量级训练框架,无需安装大量依赖包,一套代码支持千卡预训练和单卡人类偏好对齐训练,同时实现了极致的性能优化,实现千卡训练下近90%加速效率。
论文地址:https://github.com/InternLM/InternLM-techreport/blob/main/InternLM.pdf
InternLM-techreport:GitHub - InternLM/InternLM-techreport
1、InternLM的techreport
我们推出了InternLM,一个具有1,040亿参数的多语言基础语言模型。InternLM使用多阶段渐进式的过程,在1.6T个标记的大型语料库上进行预训练,然后通过微调来与人类喜好相匹配。我们还开发了一个名为Uniscale-LLM的训练系统,用于高效的大型语言模型训练。在多个基准测试上的评估表明,InternLM在多个方面,包括知识理解、阅读理解、数学和编码方面,均实现了最先进的性能。凭借如此全面的能力,InternLM在包括MMLU、AGIEval、C-Eval和GAOKAO-Bench在内的综合考试中取得了出色的表现,而无需使用外部工具。在这些基准测试中,InternLM不仅表现优于开源模型,而且相对于ChatGPT也获得了更优异的性能。此外,InternLM展示了出色的理解中文语言和中华文化的能力,这使得它成为支持面向中文语言应用的基础模型的合适选择。本文详细介绍了我们的结果,包括跨越各种知识领域和任务的基准测试和示例。
(1)、主要结果
随着最新的大型语言模型开始展现人类级别的智能,针对人类设计的考试,如中国的高考、美国的SAT和GRE,被视为评估语言模型的重要手段。值得注意的是,在其关于GPT-4的技术报告中,OpenAI通过跨多个领域的考试对GPT-4进行了测试,并将考试成绩作为关键结果。
我们在以下四个综合考试基准测试中,将InternLM与其他模型进行了比较:
MMLU:基于各种美国考试构建的多任务基准测试,涵盖了小学数学、物理、化学、计算机科学、美国历史、法律、经济、外交等多个学科。

AGIEval:由微软研究开发的基准测试,用于评估语言模型通过人类导向的考试的能力,包括19个任务集,派生自中国和美国的各种考试,例如中国的高考和律师资格考试,以及美国的SAT、LSAT、GRE和GMAT。在这19个任务集中,有9个基于中国的高考(Gaokao),我们将其单独列为一个重要的集合,称为AGIEval(GK)。
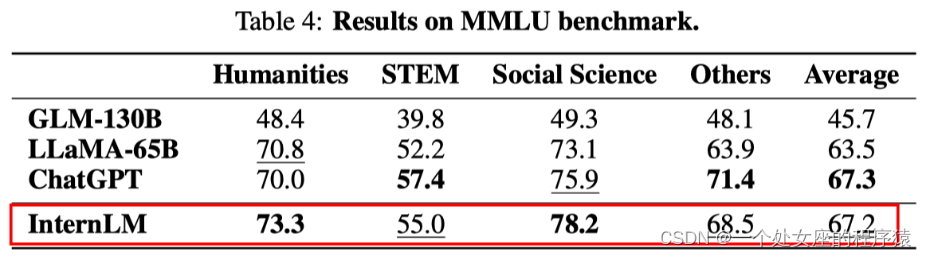

C-Eval:用于评估中文语言模型的综合基准测试,包含52个学科的近14,000道问题,涵盖数学、物理、化学、生物、历史、政治、计算机和其他学科,以及公务员、注册会计师、律师和医生的专业考试。
排行榜地址:https://cevalbenchmark.com/static/leaderboard.html

GAOKAO-Bench:基于中国的高考的综合基准测试,包括高考的所有科目。它提供不同类型的问题,包括多项选择、填空和问答。为了简洁起见,我们将这个基准测试简称为高考。

2、InternLM-7B模型的简介
InternLM ,即书生·浦语大模型,包含面向实用场景的70亿参数基础模型 (InternLM-7B)。模型具有以下特点:
- 使用上万亿高质量预料,建立模型超强知识体系;
- 通用工具调用能力,支持用户灵活自助搭建流程;
官网:internlm/internlm-7b · Hugging Face
3、InternLM、InternLM-7B模型的性能评测
我们使用开源评测工具 OpenCompass 从学科综合能力、语言能力、知识能力、推理能力、理解能力五大能力维度对InternLM开展全面评测,部分评测结果如下表所示,欢迎访问 OpenCompass 榜单 获取更多的评测结果。
| 数据集\模型 | InternLM-Chat-7B | InternLM-7B | LLaMA-7B | Baichuan-7B | ChatGLM2-6B | Alpaca-7B | Vicuna-7B |
|---|---|---|---|---|---|---|---|
| C-Eval(Val) | 53.2 | 53.4 | 24.2 | 42.7 | 50.9 | 28.9 | 31.2 |
| MMLU | 50.8 | 51.0 | 35.2* | 41.5 | 46.0 | 39.7 | 47.3 |
| AGIEval | 42.5 | 37.6 | 20.8 | 24.6 | 39.0 | 24.1 | 26.4 |
| CommonSenseQA | 75.2 | 59.5 | 65.0 | 58.8 | 60.0 | 68.7 | 66.7 |
| BUSTM | 74.3 | 50.6 | 48.5 | 51.3 | 55.0 | 48.8 | 62.5 |
| CLUEWSC | 78.6 | 59.1 | 50.3 | 52.8 | 59.8 | 50.3 | 52.2 |
| MATH | 6.4 | 7.1 | 2.8 | 3.0 | 6.6 | 2.2 | 2.8 |
| GSM8K | 34.5 | 31.2 | 10.1 | 9.7 | 29.2 | 6.0 | 15.3 |
| HumanEval | 14.0 | 10.4 | 14.0 | 9.2 | 9.2 | 9.2 | 11.0 |
| RACE(High) | 76.3 | 57.4 | 46.9* | 28.1 | 66.3 | 40.7 | 54.0 |
- 以上评测结果基于 OpenCompass 20230706 获得(部分数据标注
*代表数据来自原始论文),具体测试细节可参见 OpenCompass 中提供的配置文件。 - 评测数据会因 OpenCompass 的版本迭代而存在数值差异,请以 OpenCompass 最新版的评测结果为主。
4、InternLM-7B模型的局限性
尽管在训练过程中我们非常注重模型的安全性,尽力促使模型输出符合伦理和法律要求的文本,但受限于模型大小以及概率生成范式,模型可能会产生各种不符合预期的输出,例如回复内容包含偏见、歧视等有害内容,请勿传播这些内容。由于传播不良信息导致的任何后果,本项目不承担责任。
InternLM-7B模型的安装
1、Model Zoo
当前通过 InternLM 训练的 InternLM 7B 和 InternLM 7B Chat 已经开源,我们提供两种格式的模型权重以供使用。除了使用 Transformers 格式加载模型之外,还可以通过 InternLM 加载以下格式的权重直接进行继续预训练或人类偏好对齐训练
| 模型 | InternLM 格式权重下载地址 | Transformers 格式权重下载地址 |
|---|---|---|
| InternLM 7B | 编辑 | https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/81561 推荐阅读 相关标签 Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。 |

