
- 1深入浅出Python日志打印_python 打印日志
- 2永恒之蓝 (EternalBlue) 漏洞利用原理详解_永恒之蓝漏洞
- 3直播系统开发之对接微信支付sdk流程_微信支付sdk干嘛的
- 4【IEEE出版】第六届电子与通信,网络与计算机技术国际学术会议(ECNCT 2024,7月19-21)_2024 ecnct
- 5Seata 中XA,AT模式浅析_xa at
- 6这是一份简单到没朋友的上手图数据库的图文教程_图数据库怎么访问
- 7性能巅峰对决:Rust vs C++ —— 速度、安全与权衡的艺术_rust语言和c++性能
- 8Mybatis 标签大全及标签中各属性详解_写出10个mybatis中mapper配置文件的标签
- 9git远程分支与本地分支合并_git合并本地分支 与远程分支
- 10网络安全工程师入门教程,从零基础入门到精通,看完这一篇就够了~_网络工程师教学csdn
大数据可视化分析基于Python的招聘网站爬虫及可视化的实现_基于python爬虫的招聘信息数据可视化分析
赞
踩
前言
基于Python的招聘网站爬虫及可视化系统旨在提高数据挖掘的效率,便于科学的管理和分析招聘数据。
本文先分析基于Python的招聘网站爬虫及可视化系统的背景和意义;对常见的爬虫原理,获取策略,信息提取等技术进行分析;本系统使用python进行开发,MySQL数据库进行搭建,实现了招聘的数据爬取;对数据库的查询结果进行检测并可视化分析,对系统的前台界面进行管理,分析爬取的结果,并对招聘数据结果进行大屏显示;最后通过测试实现了数据爬取,存储过滤和数据可视化分析,以及系统管理等功能。
[关键词] 爬虫,python,大数据,关键字,招聘数据
一、项目介绍
本基于Python沧州地区空气质量数据分析及可视化系统以IDEA为平台,使用JAVA语言和MySQL进行开发,首先调查基于Python沧州地区空气质量数据分析及可视化系统的研究背景,提出开发本基于Python沧州地区空气质量数据分析及可视化系统的目的和意义。论文重点是对基于Python沧州地区空气质量数据分析及可视化系统的需求进行分析,设计系统的功能和基于Python沧州地区空气质量数据分析及可视化系统的数据库,对基于Python沧州地区空气质量数据分析及可视化系统进行编码,最后进行测试。
二、开发环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
————————————————
三、功能介绍
3.2 功能需求分析
3.2.1爬虫功能需求分析
在目前计算机信息化快速发展过程中,招聘和求职逐渐转移到网络中来,本题目来源于求职招聘系统研发项目的子项目,该项目主要完成一个招聘数据系统的设计和开发,该系统用于收集当前地方招聘数据,然后通过爬取、清理、存储、统计招聘数据,并进行招聘数据,是现代化招聘管理不可缺少的部分,为热门岗位的推荐提供便捷的模式。本文旨在对智通人才网上的招聘信息、岗位信息进行爬取,收集各种类型的招聘数据信息。然后对招聘数据的内容进行分析,整理招聘数据信息。本系统首先分析智通人才网站的网站结构,查看网站网页的排版,然后读取其包含的招聘信息。具体分为以下几个步骤,指定智通人才网url,爬取网页信息,获取特定的智通人才网url存入队列中,提取招聘数据的信息,将信息存入数据库,然后对岗位和薪资等进行分析,得出招聘数据的可视化视图。
图3-1所示数据清洗和加工用例。
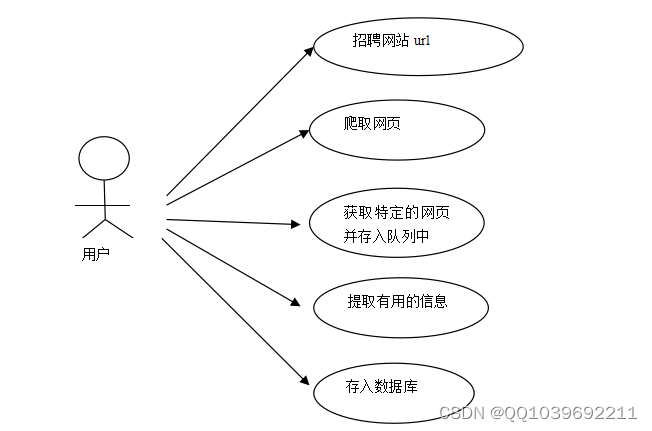
图3-1 数据清洗和加工用例
在本需求分析阶段,不需要关注如何爬取,只需要关注爬取什么样的信息,进行怎样的操作即可,所以先分析智通人才网网站的数据,确定满足系统要求后,然后查看目标网站,将智通人才网内的有关招聘数据进行提取,最后将信息存储到数据库。
3.2.2数据可视化功能需求分析
爬取完招聘数据后,需要对数据进行分析,根据评分和K-means聚类算法分析出招聘数据趋势,并可视化查询处理。本系统使用Python进行编程,通过HTML、JS等方法显示数据。具体包括:招聘数据数据展示、招聘数据分类、用户注册登录、用户管理和爬虫数据管理。其中可视化功能用例图如图3-2所示。
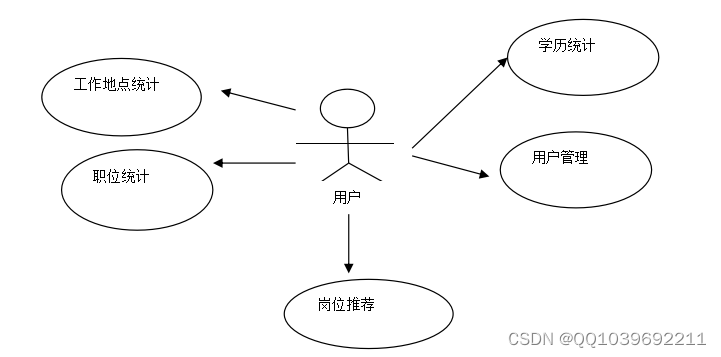
图3-2 数据分析展示用例
基于Python的招聘网站爬虫及可视化系统用户登录,先验证信息、成功启动系统后进行登录。登录验证成功后,获取到登录权限,跳转到系统首页。
进入到基于Python的招聘网站爬虫及可视化系统大屏界面,通过图形化显示出工作地点统计、学历统计、职位统计、公司类型统计、薪资统计。如果查询失败,返回基于Python的招聘网站爬虫及可视化系统的错误页面。
四、核心代码
部分代码:
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {
'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8


