
- 1Python算法题集_从前序与中序遍历序列构造二叉树_python 前序遍历
- 2【iOS免越狱】利用IOS自动化WebDriverAgent实现自动直播间自动输入_webdriveragent 滑动
- 3最小生成树超详细介绍_什么是最小生成树
- 4第十三届通信、电路与系统国际会议(ICCCAS 2024)即将召开!_icccas2024
- 5算法学习过程——欧拉(费马小定理、欧拉函数、欧拉定理、欧拉降幂、欧拉筛法)_1_欧拉算法
- 6基于Sim2Real的鸟瞰图语义分割方法
- 7MobaXterm-Chinese中文版本安装及简单使用_mobaxterm汉化
- 8用群辉NAS打造影视墙(Jellyfin篇)_nas jellyfin
- 9verilog中signed的使用_verilog 中signed类型
- 10使用JAR命令打包JAR文件使用Maven打包使用Gradle打包打包Spring Boot应用
1-4 python爬取笔趣阁小说(附带完整代码)_脔仙
赞
踩
笔趣看是一个盗版小说网站,这里有很多起点中文网的小说,该网站小说的更新速度稍滞后于起点中文网正版小说的更新速度。并且该网站只支持在线浏览,不支持小说打包下载。所以可以通过python爬取文本信息保存,从而达到下载的目的
以首页的《一念永恒》作为测试:
1、先查看第一章地址中的html文本:https://www.biqukan.com/1_1094/5403177.html
通过requests库获取:
- # -*- coding:UTF-8 -*-
- import requests
-
- if __name__ == '__main__':
- target = 'http://www.biqukan.com/1_1094/5403177.html'
- req = requests.get(url=target)
- print(req.text)
运行代码,可以看到如下结果:(获取到他的html文本,你可以通过chrome审查元素来对照)
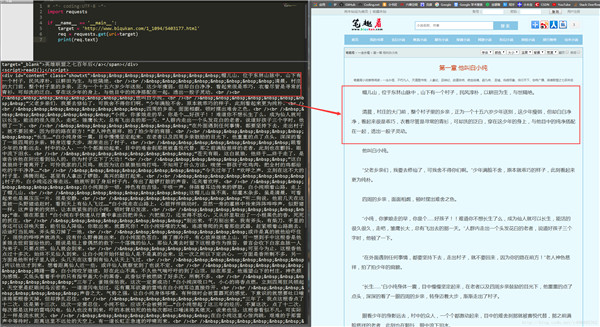
可以看到,我们很轻松地获取了HTML信息。但是,很显然,很多信息是我们不想看到的,我们只想获得如右侧所示的正文内容,我们不关心div、br这些html标签。如何把正文内容从这些众多的html标签中提取出来呢?这就是本次实战的主要内容。
Beautiful Soup
爬虫的第一步,获取整个网页的HTML信息,我们已经完成。接下来就是爬虫的第二步,解析HTML信息,提取我们感兴趣的内容。对于本小节的实战,我们感兴趣的内容就是文章的正文。提取的方法有很多,例如使用正则表达式、Xpath、Beautiful Soup等。对于初学者而言,最容易理解,并且使用简单的方法就是使用Beautiful Soup提取感兴趣内容。
Beautiful Soup的安装方法和requests一样(我安装的是3.7版本):
pip3 install beautifulsoup4Beautiful Soup中文的官方文档:http://beautifulsoup.readthedocs.io/zh_CN/latest/
通过google chrome中审查元素方法,查看一下我们的目标页面,你会看到如下内容:
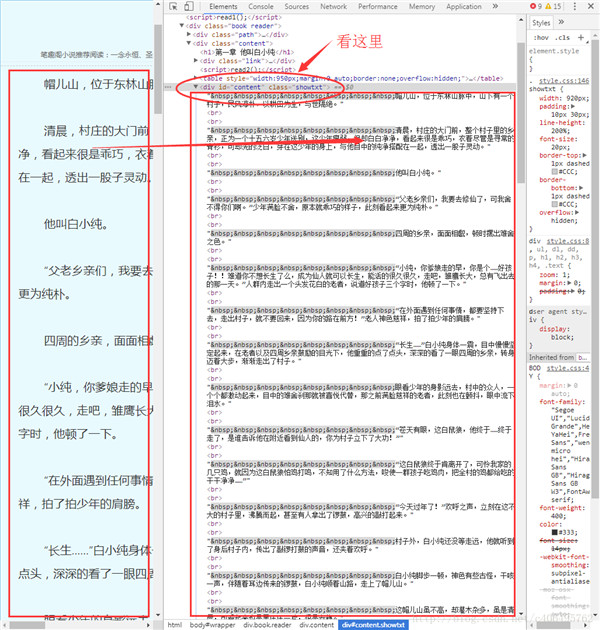
可以看到文本内容都放置在<div id="content", class="showtxt">这个标签中 ,这样就可以开始通过库来获取这个标签中的内容:
- # -*- coding:UTF-8 -*-
- from bs4 import BeautifulSoup
- import requests
- if __name__ == "__main__":
- target = 'http://www.biqukan.com/1_1094/5403177.html'
- req = requests.get(url = target)
- bf = BeautifulSoup(req.text)
- #查询所有div标签,并且class为'showtxt'
- texts = bf.find_all('div', class_ = 'showtxt') print(texts)
获取到如下内容:
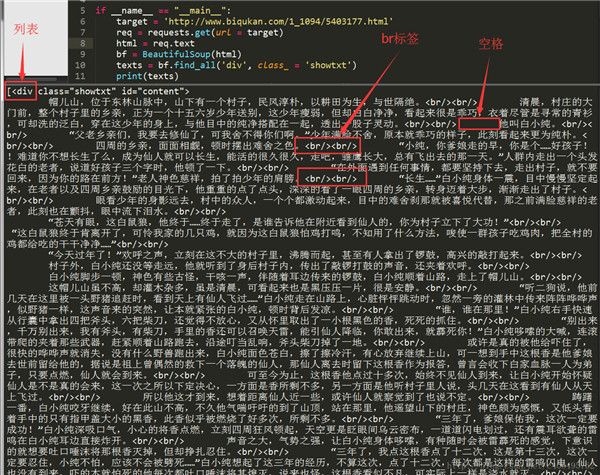
我们可以看到,我们已经顺利匹配到我们关心的正文内容,但是还有一些我们不想要的东西。比如div标签名,br标签,以及各种空格。怎么去除这些东西呢?我们继续编写代码:
- # -*- coding:UTF-8 -*-
- from bs4 import BeautifulSoup
- import requests
- if __name__

