
- 1AI之DS/CV/NLP:Python与人工智能相关的库/框架(数据可视化常用库、机器学习常用库、数据科学常用库、深度学习常用库、计算机视觉常用库、自然语言处理常用库)的简介、案例应用之详细攻略_ds cv nlp
- 2php上传头像的代码,php头像上传预览实例代码
- 3推荐:物联网区块链项目---IoTeX_物联网 区块链项目
- 4在 VS Code 中使用 GitHub Copilot_vs code github copilot
- 5单链表简单学生信息管理系统(纯C语言实现)_数据结构c单链表学分管理
- 6【EI会议征稿通知】2024年图像处理、智能控制与计算机工程国际学术会议(IPICE 2024)_张召 合肥工
- 7line 5, in <module> import imageioModuleNotFoundError: No module named ‘imageio‘报错,求指点_modulenotfounderror: no module named 'imageio.v3
- 8Python学习之-chardet详解_python chardet
- 9MySQL 高级篇 -- MVCC_使用read uncommitted隔离级别的事务,由于可以堵到
- 10【Anaconda】Windows 系统中 vision mamba环境配置教程_windows mamba环境安装
【mT5多语言翻译】之二——模型:T5模型与mT5模型与前置知识_t5-base 本地运行
赞
踩
·请参考本系列目录:【mT5多语言翻译】之一——实战项目总览
[1] 先体验一下T5的魅力!
由于mT5是T5模型的多语言版本,但是mT5并没有给出微调部分的参数,但是T5给了。所以我们可以先试一下T5模型。
1、先去huggingface下载T5的模型https://huggingface.co/google/flan-t5-base保存到本地文件夹。下图中框柱的部分是我们需要下载并且放到文件夹中的。

2、然后运行下面的demo示例。其中的变量path就是你文件夹的地址。
import torch
from transformers import AutoTokenizer, T5ForConditionalGeneration
path = r"D:\PLMs\t5\flan-t5-base"
tokenizer = AutoTokenizer.from_pretrained(path)
model = T5ForConditionalGeneration.from_pretrained(path).cuda()
text = "translate English to German: Now that you mention it, I have to see how it is implemented in their code."
# 编码输入文本
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding='max_length', max_length=32)
inputs.to('cuda')
with torch.no_grad():
outs = model.generate(input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], )
# 解码输出以获得翻译文本
translated_text = tokenizer.decode(outs[0], skip_special_tokens=False)
print(translated_text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
然后你会得到以下的输出:
<pad> Jetzt, wenn Sie das gesagt haben, muss ich sehen, wie sie in ihrem
- 1
3、同理,如果想把英语翻译为西班牙语,我们只需要把变量text的前缀“translate English to German:”改为“translate English to Spanish:”。
[2] 再体验一下暂时还无法工作的mT5
同上面一样,我们先去huggingface下载mT5的模型https://huggingface.co/google/mt5-base/tree/main保存到本地文件夹。下图中框柱的部分是我们需要下载并且放到文件夹中的。

然后运行下面的demo示例。其中的变量path就是你文件夹的地址。
import torch
from transformers import AutoTokenizer, MT5ForConditionalGeneration
path = r"D:\PLMs\mt5\mt5-base"
tokenizer = AutoTokenizer.from_pretrained(path)
model = MT5ForConditionalGeneration.from_pretrained(path).cuda()
text = "translate English to German: Hugging Face is a technology company based in New York and Paris"
# 编码输入文本
inputs = tokenizer(text, return_tensors='pt', truncation=True, max_length=512)
inputs.to('cuda')
with torch.no_grad():
outs = model.generate(input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_length=128, no_repeat_ngram_size=4, num_beams=4)
# 解码输出以获得翻译文本
translated_text = tokenizer.decode(outs[0], skip_special_tokens=False)
print(translated_text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
然后你会得到以下的输出,发现它根本就不对:
<pad> <extra_id_0> Hugging Face</s>
- 1
这是因为mT5没有针对“translate English to German:”这样的任务训练过。官方提供的mT5参数只是进行过无监督训练的,就像一个橡皮泥,想捏成什么需要我自己针对特定的任务进行微调。
[3] mT5模型源码
因为mT5模型是T5的多语言版,结果和T5一样,因此这里我们就直接来介绍T5模型的源码。
【注意】本文的源码都是基于
transformers库的modeling_t5.py文件讲解的。
本文会先画一下T5模型的大致结构图。然后介绍源码中的类之间的关系。之后会先把耦合较浅、源码简单的类介绍一遍,然后才介绍比较复杂的类。
由于复杂类的参数特别多,所以会先把这些参数大概干了什么事情从宏观的角度介绍一下,然后再看源码就会很简单了。
模型结构图
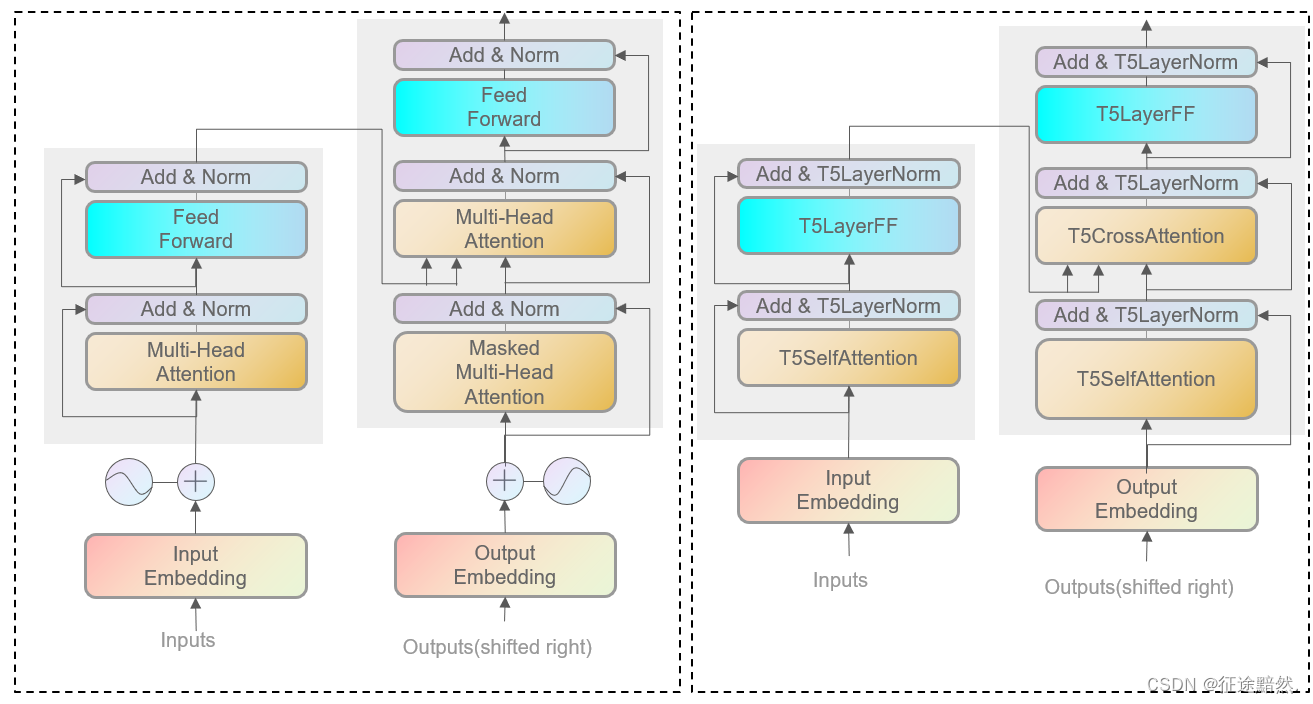
从图2可以看出来,T5基本保持了Transformer的Enc-Dec架构,只是在细节实现上有所区别。
具体来说,T5在模型结构上的改动有:
1、LayerNorm取消了偏置项;
2、解码器部分采用(自注意力结构+交叉注意力结构+前馈层)作为一个block;
3、输入部分只有嵌入层,把位置编码改为了计算注意力时内置的位置偏置;
4、无监督训练时的目标也做了改动;
这些改动并不大,那么T5模型为什么能刷榜呢?因为它的工作在各个层面都做了很多实现,取了最好的trick。参考下面的图3,看看T5论文所做的惊人的实验数量。
【注意】大家可以去看一下原论文中所采用的各种训练策略。论文地址:https://dl.acm.org/doi/10.5555/3455716.3455856
我们再稍微看一下源码中T5Model类的神经网络结构:

从图5中可以看到T5Model模型的结构就是很清爽的编码器+解码器的结构。接着,我们来打印模型的结构,使用如下代码进行打印:
from transformers import T5Model
path = r"xxx"
model = T5ForConditionalGeneration.from_pretrained(path)
print(model)
- 1
- 2
- 3
- 4
T5Model类的编码器结构如下图5所示。编码器与Transformer模型一样还是分成12个块(Block),区别在于第一个块在自注意力层内置了位置偏置,后面的2-12个块的结构是相同的。

T5Model类的解码器结构如下图6所示。分成12个块(Block),然后第一个块在自注意力层内置了位置偏置,紧接着跟交叉注意力模块,后面的2-12个块的结构是相同的。

综上所述,T5Model模型由编码器+解码器构成,编码器是12个块,解码器也是12个块。编码器的每个块由[自注意力层+前馈网络层]构成,解码器的每个块由[自注意力层+交叉注意力层+前馈网络层]构成。无论是编码器还是解码器,它们的第一个块的自注意力层都内置了一个位置偏置。
类关系分析
对于T5模型的构成部分来说,一共有以下类:
T5LayerNorm:层归一化,T5模型中去掉了偏置。
T5DenseActDense与T5DenseGatedActDense:前馈网络,说白了就是线性层+激活函数,区别在于T5DenseGatedActDense多加了一次线性层。
T5LayerFF:把[层归一化、前馈网络、残差连接]整合在了一起。
T5Attention:注意力的实现,核心!自注意力、交叉注意力都是在这里实现的,代码比较难阅读。
T5LayerSelfAttention:自注意力层,对T5Attention进行套壳。
T5LayerCrossAttention:交叉注意力层,对T5Attention进行套壳。
T5Block:一个块。对于编码器,把[T5LayerSelfAttention、T5LayerFF]整合在了一起。对于解码器,把[T5LayerSelfAttention、T5LayerCrossAttention、T5LayerFF]整合在了一起。
T5Stack:n个块堆叠,在base版本的T5中,n=12。
T5Model
上述的10个类,是自上而下互相嵌套的关系。其中T5LayerNorm、T5DenseActDense、T5DenseGatedActDense、T5LayerFF并不涉及注意力,和其他参数没有耦合,所以我们在下一小节先介绍这4个类,把简单的类的源码先看懂。
简单类的源码

如图7所示,首先我们来把比较简单的几个类的源码讲解一下。
T5LayerNorm

如图8所示,T5模型中的层归一化取消了偏置项,只有权重weight,首先对特征求方差均方 ,然后使用使用方差均方的平方根的倒数来对特征进行缩放,随后考虑了一下FP16和BF16精度下的数据转换问题,最后把特征乘以可训练的权重weight就结束了。
【注意】(2024.4.5更新)T5LayerNorm这一小节的图片与介绍有误。不是求方差,而是求均方,此处使用的归一化技术为RMSNorm(均方根归一化)。参考论文为:Root Mean Square Layer Normalization
T5DenseActDense

如图9所示,T5模型中的前馈网络有2个fc层、1个激活函数和1个dropout。激活函数act是读取config来自动加载的。整体流程比较简单:
特征经过第一个线性层——激活——dropout——第二个线性层。
T5DenseGatedActDense

如图10所示,T5DenseGatedActDense是T5模型中的另一种前馈网络,有3个fc层、1个激活函数和1个dropout。激活函数act是读取config来自动加载的。整体流程比较简单:
特征经过第一个线性层——激活——第二个线性层——dropout——第三个线性层。
【注】因为激活函数用了GLU,所以这里才加了个Gated,具体情况可以参考:【T5中的激活函数】GLU Variants Improve Transformer
T5LayerFF

如图11所示,T5LayerFF就更加简单了!它是用来结合层归一化、前馈网络和残差连接的类。在前馈网络的选取方面,需要读取配置来决定使用T5DenseGatedActDense还是T5DenseActDense。
复杂类的源码
由于T5模型的解码器是有交叉注意力机制和自注意力机制的,但是源码把这两种注意力机制整合到了一起,所以就会有很多参数来进行分支控制(if-else控制),我觉得这是源码比较复杂的主要原因。
【注】具体来说,代码中把编码器、解码器整合到了T5Block里,又把交叉注意力和自注意力整合到了T5Attention里,所以在阅读源码的时候,得判断什么时候是解码器在运行、什么时候是编码器在运行,什么时候在算自注意力、交叉注意力。
常见参数介绍
因为分支控制都是通过各个参数来判断的,因此有必要先了解每个参数在代码中具体指代什么。不然的话,直接阅读源码会很痛苦。
这里我选择介绍T5Stack类forward方法的参数,基本能囊括绝大数我们即将会接触到的变量。

如图12所示,以上是T5Stack类forward方法的参数。一定要注意一个前提:T5Stack可以构成编码器,也可以构成解码器,因此以上的这些参数有的是编码器专属,有的是解码器专属,有的是两者公用的。
1、input_ids: 输入文本的token_id。在编码器运行时,它是输入的全本文本。在解码器运行时,它是解码器解码出来的序列。
2、attention_mask: 用于指定对输入序列的哪些部分执行注意力机制,通常用于屏蔽填充标记。它和input_ids是对应的。
3、encoder_hidden_states: 编码器最后一层的输出,是给解码器解码用的。只有在解码阶段才有,编码阶段为None。
4、encoder_attention_mask: 类似于attention_mask,但和encoder_hidden_states是对应的。用于编码器的输出,确保解码器在注意力机制中只关注编码器输出中相关的部分。
【注!重要!】上面的四个参数,在编码时参数1、2表示我们输入的序列信息,参数3、4一直为None。在解码时参数1、2表示解码器解码出的文本序列信息,参数3、4在解码的时候代表着编码器的最终输出。
5、inputs_embeds: 会代替input_ids作为输入的嵌入表示。正常情况下用不到,咱们可以忽略。
6、head_mask: 用于屏蔽某些注意力头。在训练过程中用于实现不同的注意力模式。可能是方便调参、调模型的注意力用的,咱们可以忽略。
7、cross_attn_head_mask: 类似于head_mask,但用于交叉注意力机制。可能是方便调参、调模型的注意力用的,咱们可以忽略。
8、past_key_values: 只有在解码时才会有值,编码时一直为None。表示前n次解码时计算的present_kay_value_state(T5Attention里面的Key,value向量)的值。past_key_values用来计算交叉注意力,编码是不需要的,所以在编码阶段一直为None。
9、use_cache: 指示模型是否使用缓存来存储过去的关键值对,以便在后续的解码步骤中重用。use_cache在解码阶段为True,控制past_key_values每次累计KV向量。
【注】上面的参数,参数8、9比较重要,并且它们只有在解码阶段才会用到。这属于一种简单的缓存机制,利用空间换时间,加速解码。之所以解码器积累的KV向量可以重用,是因为T5解码阶段也是采用了Masked注意力机制(类似于Transformer模型中的解码器使用的Masked注意力)。
10、output_attentions: 如果设置为True,模型将返回注意力权重。
11、output_hidden_states: 如果设置为True,模型将返回所有隐藏层的输出。
【注】上面的参数,参数10、11就是返回中间计算结果,方便大家会有绘制、监控中间向量的需求,又或者会有魔改模型的需求。
12、return_dict: 指定模型是否返回一个字典,其中包含上述所有可能的输出,或者只返回模型的最后一层输出。
最难的T5Attention源码
在讲述T5Attention源码之前,我们来回顾一下大家此时应该掌握了哪些知识:
1、首先对T5模型相关类的套壳关系应该弄懂了。
2、其次那些简单类的源码看懂了。
3、最后对T5模型中的一些常见参数也理解了。
由于T5Stack类、T5Block类的forword函数太长了而且不涉及特别核心的东西,所以我就不贴它们的代码一一对照讲解了,这里会概括地介绍一下,然后大家自行去看这两个类的源码。
T5Stack类在结构上就是对T5Block的堆叠,根据传入的配置来决定是堆叠n个编码器块还是解码器块。在forward时做的最主要的工作就是循环这n个块。
T5Block类在结构上就是构成编码器块或者解码器块,根据传入的配置来决定是构成编码器块还是解码器块。对于编码器,把[T5LayerSelfAttention、T5LayerFF]整合在了一起。对于解码器,把[T5LayerSelfAttention、T5LayerCrossAttention、T5LayerFF]整合在了一起。在forward时的工作在块内流转数据。
下面介绍T5LayerSelfAttention、T5LayerCrossAttention的结构:


如图13、14所示,T5LayerSelfAttention、T5LayerCrossAttention的结构非常简单。不管是自注意力还是交叉注意力,它们底层都是由T5Attention类构成的,它才是核心!
首先来看下T5Attention类的构造函数:

如图15所示,初始化时没啥特别的,q、k、v、o这些都是老生常谈的注意力套餐了。要特别关注的是relative_attention_bias,这是位置编码,和BERT不同的是,T5模型内置在了注意力计算的时候,并且也是用嵌入层来生成的。
由于T5Attention类的forward函数的参数名字和T5Stack有些区别,所以我们再来介绍一下它的参数。
【注】其实只是参数名不同,内容还是那些,大家不用害怕,忍一忍马上就结束了!

T5Attention类forward方法如图16所示,下面是参数介绍。大家可以对照着图12的部分一起看,这样更好理解。
1、hidden_states: 这个是模型的主分支上编码的信息。在编码器阶段,hidden_states就会一直计算下去,演变成句子表征向量。在解码器阶段,hidden_states表示解码器解码出来的序列的表征向量。
2、mask:这里其实就是序列的attention_mask。但是为什么只传一个mask?T5Stack的输入不是有2个mask吗?
【注!重要!】我在图12那边有介绍,T5Stack的输入是有输入序列的id、mask和解码序列的id、mask。在编码器阶段,解码序列的id、mask没有,所以计算注意力时,会传输入序列的hidden_states、mask,这里的
mask就是输入序列的attention_mask。在编码器阶段,编码器首先进行自注意力计算,那它只会传解码序列的hidden_states、mask,这里的mask就是解码序列的attention_mask;之后,编码器会进行交叉注意力的计算,此时解码器已经拿到解码序列的自注意力向量hidden_states了,所以它不再需要解码序列的mask,所以此时的mask是输入序列的attention_mask,用以计算交叉注意力。
综上所述,编码器的自注意力、解码器的自注意力、解码器的交叉注意力传的都不一样。
3、key_value_states: 是在编码器的最后一步生成的,用于在解码器的每一步中提供来自输入序列的上下文信息。key_value_states在交叉注意力中提供计算的数据,在解码器和编码器的自注意力中,这个参数永远是None。其实它同T5Stack的输入encoder_hidden_states是一个东西。
4、past_key_value: 这是上一次解码后的键值状态,用于长序列的生成。如果是第一次迭代或没有提供过去的键值,这个参数将是None。是12维度张量,每个元素是4元组,存放(selfK、V, CrossK、V)。key_value_states和past_key_value只会在第一次解码的时候同时不为空。
其他的参数在上文介绍过,或者不太影响源码阅读,就不再仔细介绍。

T5Attention类forward方法的核心计算流程如图17所示,对于查询向量Q,把它的形状重塑一下。对于键值向量KV,需要用到project函数来重构。project函数是核心部分,控制着交叉注意力、自注意力的计算流。代码如下:

【注】project函数的分支很多,要看懂的话,大家可以从编码器的自注意力计算、解码器的自注意力计算、解码器的交叉注意力计算这三个情况代入进去来看。
如图18所示。
分支1:if key_value_states is None:,此时key_value_states 为空,说明在执行自注意力机制,但是不知道是编码器在执行还是解码器在执行。因为自注意力计算的时候,不会传key_value_states ,它必为None。因此流程要继续往下走。
分支2:elif past_key_value is None:,如果key_value_states 不为空但是past_key_value 为空,说明这个时候编码器已经完成运行,但是解码器是第一次运行,以前的键值还没保存过,此时是第一次解码器解码,并且是交叉注意力计算阶段。
分支3:if past_key_value is not None:,past_key_value不空说明已经至少是第二次解码了,接下来的流程都属于解码器运行阶段。
分支4:if key_value_states is None:,编码器在执行自注意力,因为自注意力计算的时候,不会传key_value_states 。此时需要把以前的计算结果拼接回来。
分支5:elif past_key_value.shape[2] != key_value_states.shape[1]:,这是在支持prefix,和我们正常执行代码无关。
分支6:else:,此时编码器在执行交叉注意力,并且不是第一次解码。
接下来的算法流程就平平无奇了,计算出权重分数,然后乘以value,最后拼接一下需要返回的向量即可。

