
热门标签
热门文章
- 1华为OD最新面试手撕代码:编辑距离_华为远程面试有手撕代码吗
- 2jQuery学习进阶篇_jquery jinjie1
- 32024 年 5 月公链研报:监管调整与市场新动向
- 4c语言程序设计形考题库,国开网C语言程序设计形考任务4
- 5Java Springboot SSE如何判断客户端能否正常接收消息_java sseemitter
- 6python GUI工具之PyQt5模块,pyCharm 配置PyQt5可视化窗口_python可视化界面pycharm
- 7盘点5款主流AI绘画工具_dockyai
- 8not in的代替_not in替换
- 9GitHub for Windows使用图文教程,移动架构师成长路线
- 10基于SpringBoot+微信小程序汽车服务系统的设计与实现_车源展示小程序
当前位置: article > 正文
生成对抗网络——GAN深度卷积实现(代码+理解)_卷积实现生成器和判别器
作者:繁依Fanyi0 | 2024-07-24 18:14:27
赞
踩
卷积实现生成器和判别器
本篇博客为 上篇博客的 另一个实现版本,训练流程相同,所以只实现代码,感兴趣可以跳转看一下。
生成对抗网络—GAN(代码+理解)
目录
一、GAN深度卷积实现
1. 模型结构
(1)生成器(Generator)

(2)判别器(Discriminator)

2. 代码实现
- import torch
- import torch.nn as nn
- import argparse
- import torchvision.transforms as transforms
- import matplotlib.pyplot as plt
- from torch.utils.data import DataLoader
- from torchvision import datasets
- import numpy as np
-
-
- parser = argparse.ArgumentParser()
- parser.add_argument("--n_epochs", type=int, default=20, help="number of epochs of training")
- parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
- parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
- parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
- parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
- parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
- parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
- parser.add_argument("--channels", type=int, default=1, help="number of image channels")
- parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
- opt = parser.parse_args()
- print(opt)
-
- # 加载数据
- dataloader = torch.utils.data.DataLoader(
- datasets.MNIST(
- "./others/",
- train=False,
- download=False,
- transform=transforms.Compose(
- [transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
- ),
- ),
- batch_size=opt.batch_size,
- shuffle=True,
- )
-
- def weights_init_normal(m):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
- elif classname.find("BatchNorm2d") != -1:
- torch.nn.init.normal_(m.weight.data, 1.0, 0.02) # 给定均值和标准差的正态分布N(mean,std)中生成值
- torch.nn.init.constant_(m.bias.data, 0.0)
-
- class Generator(nn.Module):
- def __init__(self):
- super(Generator, self).__init__()
-
- self.init_size = opt.img_size // 4 # 原为28*28,现为32*32,两边各多了2
- self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))
-
- self.conv_blocks = nn.Sequential(
- nn.BatchNorm2d(128), # 调整数据的分布,使其 更适合于 下一层的 激活函数或学习
- nn.Upsample(scale_factor=2),
- nn.Conv2d(128, 128, 3, stride=1, padding=1),
- nn.BatchNorm2d(128, 0.8),
- nn.LeakyReLU(0.2, inplace=True),
- nn.Upsample(scale_factor=2),
- nn.Conv2d(128, 64, 3, stride=1, padding=1),
- nn.BatchNorm2d(64, 0.8),
- nn.LeakyReLU(0.2, inplace=True),
- nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
- nn.Tanh(),
- )
-
- def forward(self, z):
- out = self.l1(z)
- out = out.view(out.shape[0], 128, self.init_size, self.init_size)
- img = self.conv_blocks(out)
- return img
-
- class Discriminator(nn.Module):
- def __init__(self):
- super(Discriminator, self).__init__()
-
- def discriminator_block(in_filters, out_filters, bn=True):
- block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1),
- nn.LeakyReLU(0.2, inplace=True),
- nn.Dropout2d(0.25)]
- if bn:
- block.append(nn.BatchNorm2d(out_filters, 0.8))
- return block
-
- self.model = nn.Sequential(
- *discriminator_block(opt.channels, 16, bn=False),
- *discriminator_block(16, 32),
- *discriminator_block(32, 64),
- *discriminator_block(64, 128),
- )
- # 下采样(图片进行 4次卷积操作,变为ds_size * ds_size尺寸大小)
- ds_size = opt.img_size // 2 ** 4
- self.adv_layer = nn.Sequential(
- nn.Linear(128 * ds_size ** 2, 1),
- nn.Sigmoid()
- )
-
- def forward(self, img):
- out = self.model(img)
- out = out.view(out.shape[0], -1)
- validity = self.adv_layer(out)
- return validity
-
- # 实例化
- generator = Generator()
- discriminator = Discriminator()
-
- # 初始化参数
- generator.apply(weights_init_normal)
- discriminator.apply(weights_init_normal)
-
- # 优化器
- optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
- optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
-
- # 交叉熵损失函数
- adversarial_loss = torch.nn.BCELoss()
-
- def gen_img_plot(model, epoch, text_input):
- prediction = np.squeeze(model(text_input).detach().cpu().numpy()[:16])
- plt.figure(figsize=(4, 4))
- for i in range(16):
- plt.subplot(4, 4, i + 1)
- plt.imshow((prediction[i] + 1) / 2)
- plt.axis('off')
- plt.show()
-
- # ----------
- # Training
- # ----------
- D_loss_ = [] # 记录训练过程中判别器的损失
- G_loss_ = [] # 记录训练过程中生成器的损失
- for epoch in range(opt.n_epochs):
- # 初始化损失值
- D_epoch_loss = 0
- G_epoch_loss = 0
- count = len(dataloader) # 返回批次数
- for i, (imgs, _) in enumerate(dataloader):
- valid = torch.ones(imgs.shape[0], 1)
- fake = torch.zeros(imgs.shape[0], 1)
-
- # -----------------
- # Train Generator
- # -----------------
- optimizer_G.zero_grad()
- z = torch.randn(imgs.shape[0], opt.latent_dim)
- gen_imgs = generator(z)
- g_loss = adversarial_loss(discriminator(gen_imgs), valid)
- g_loss.backward()
- optimizer_G.step()
-
- # ---------------------
- # Train Discriminator
- # ---------------------
- optimizer_D.zero_grad()
- real_loss = adversarial_loss(discriminator(imgs), valid)
- fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
- d_loss = (real_loss + fake_loss) / 2
- d_loss.backward()
- optimizer_D.step()
-
- print(
- "[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
- % (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
- )
-
- # batches_done = epoch * len(dataloader) + i
- # if batches_done % opt.sample_interval == 0:
- # save_image(gen_imgs.data[:25], "others/images/%d.png" % batches_done, nrow=5, normalize=True)
-
- # 累计每一个批次的loss
- with torch.no_grad():
- D_epoch_loss += d_loss
- G_epoch_loss += g_loss
-
- # 求平均损失
- with torch.no_grad():
- D_epoch_loss /= count
- G_epoch_loss /= count
- D_loss_.append(D_epoch_loss.item())
- G_loss_.append(G_epoch_loss.item())
-
- text_input = torch.randn(opt.batch_size, opt.latent_dim)
- gen_img_plot(generator, epoch, text_input)
-
-
- x = [epoch + 1 for epoch in range(opt.n_epochs)]
- plt.figure()
- plt.plot(x, G_loss_, 'r')
- plt.plot(x, D_loss_, 'b')
- plt.ylabel('loss')
- plt.xlabel('epoch')
- plt.legend(['G_loss','D_loss'])
- plt.show()

3. 运行结果展示

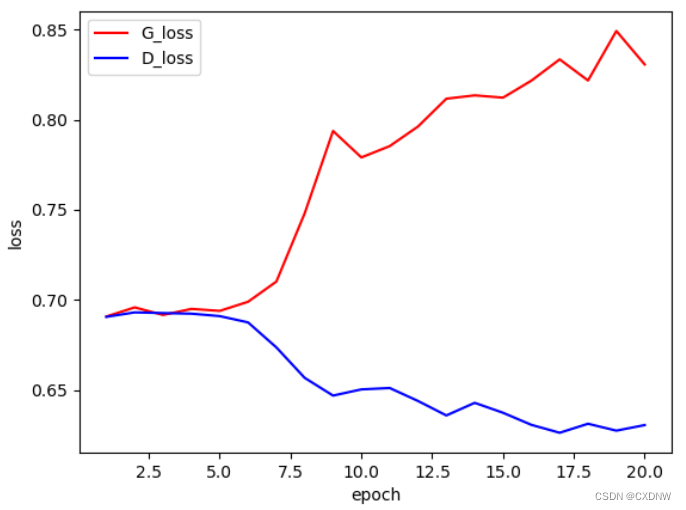

二、学习中产生的疑问,及文心一言回答
1. 模型初始化
函数 weights_init_normal 用于初始化 模型参数,为什么要 以 均值和标准差 的正态分布中采样的数 为标准?

2. 模型训练时
这里“d_loss = (real_loss + fake_loss) / 2” 中的 “/ 2” 操作,在 实际训练中 有什么作用?

由(real_loss + fake_loss) / 2的 得到 的 d_loss 与(real_loss+fake_loss)得到的 d_loss 进行 回溯,两者结果会 有什么不同吗?

3. 优化器定义
设置 betas=(opt.b1, opt.b2) 有什么 实际的作用?通俗易懂的讲一下

betas=(opt.b1, opt.b2) 是怎样 更新学习率的?

4. 训练数据
这里我们用的data为 MNIST,为什么img_size设置为 32,不是 28?

5. 模型结构
(1)生成器
解释一下为什么是“Upsample, Conv2d, BatchNorm2d, LeakyReLU ”这种顺序?


(2)判别器
模型的 基本 运算步骤是什么?其中为什么需要 “Dropout2d( p=0.25, inplace=False)”这一步?

关于“ds_size” 和 “128 * ds_size ** 2”的实际意义?


后续更新 GAN的其他模型结构。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/876155?site
推荐阅读
相关标签

