
- 1Spring Boot WebSocket 客户端_springboot创建websocket客户端_springboot websocket客户端
- 2第2章 信息技术发展——2.3 新一代信息技术及应用(下)_新一代信息技术典型代表之间的关系
- 3C# Web控件与数据感应之 TreeView 类_c# treeview
- 4scrapy获取分页的链接数量不完整_scrapy为啥爬不全页面
- 5【C++】Windows下共享内存加信号量实现进程间同步通信_信号量 windows
- 6YOLOv5独家改进:backbone改进 | 微软新作StarNet:超强轻量级Backbone | CVPR 2024_v5可以和starnet融合么
- 7AI大模型基础环境搭建_ai大模型搭建
- 8论实习、暑期实习、秋招、春招之间的关系_秋招有实习期吗
- 9大语言模型驱动的智能对话新纪元:上下文理解与多轮对话生成技术揭秘_大模型多轮对话
- 10零基础学习MySQL---MySQL入门
Mamba模型(Mmaba1, 没有mamba2)_mamba模型中的bldn分别是什么
赞
踩
问题
Transformer模型基于矩阵乘法,注意力机制中Q、K、V(N×d)会进行大量运算。
如:使用Q、K运算得到score的过程中,将Q每一行与K每一列进行运算,需要N^2次点积,每次点积包含d次乘法。即最终的复杂度为O()。考虑到序列长度(L)、batch大小(B)、多层Transformer块的堆叠(M),计算量为
,参考。
RNN存在梯度消失的问题,且训练时间长。
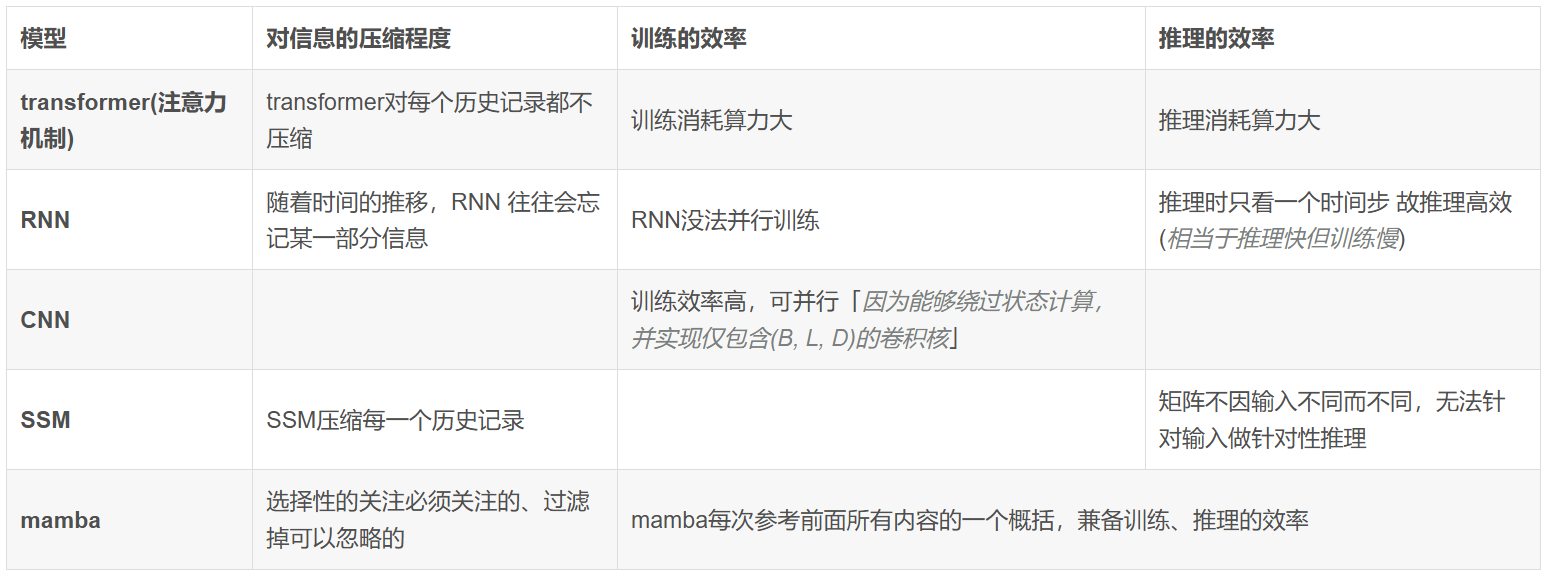
状态空间模型
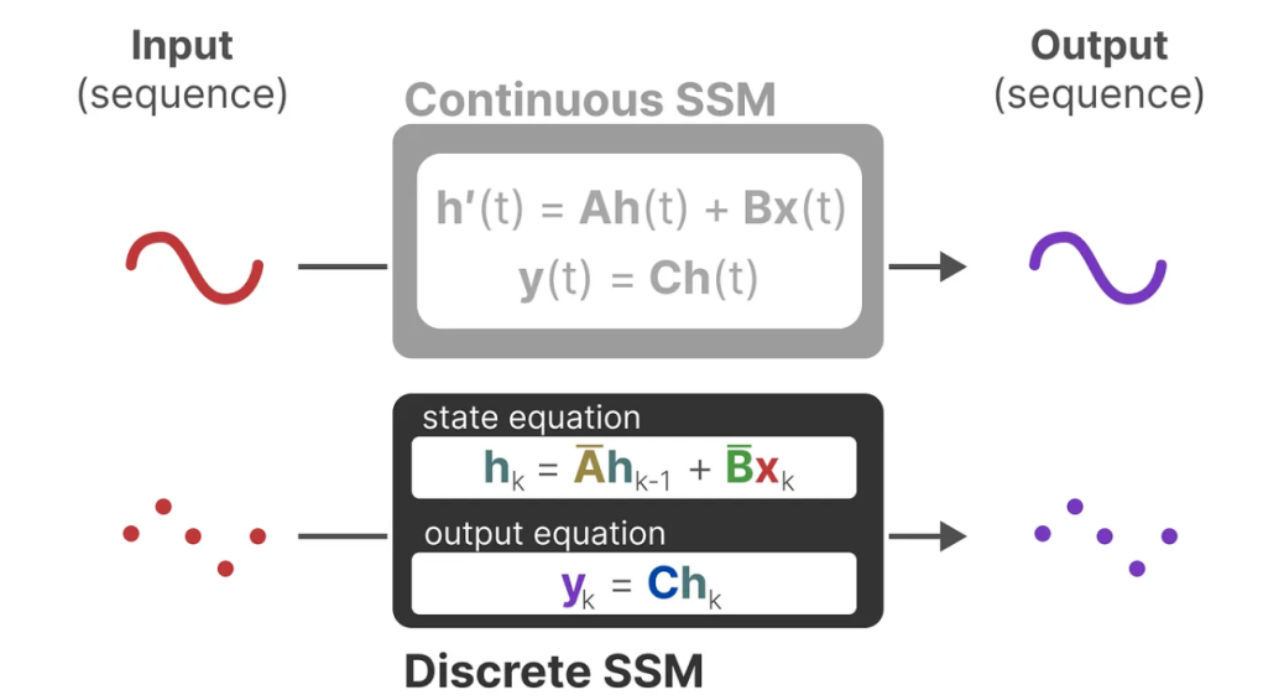
Mamba中的状态空间模型(SSM)的灵感来源于传统的状态空间模型,公式描述如下:

其中,h ( t ) h(t)h(t)是当前的状态量,A AA是状态转移矩阵;x ( t ) x(t)x(t)为输入的控制量,B BB表示控制量对状态量的影响。y ( t ) y(t)y(t)表示系统的输出,C CC表示当前状态量对输出影响,D DD表示当前控制量对输出影响。

这个模型是时不变(time-invariant)系统,时不变系统是输出不会直接随着时间变化的系统。任意时间延迟的输入将得到相同时间延迟的输出(ABCD其实可以带上时间参数,那就是时变系统,延时输入会导致不同的输出)。
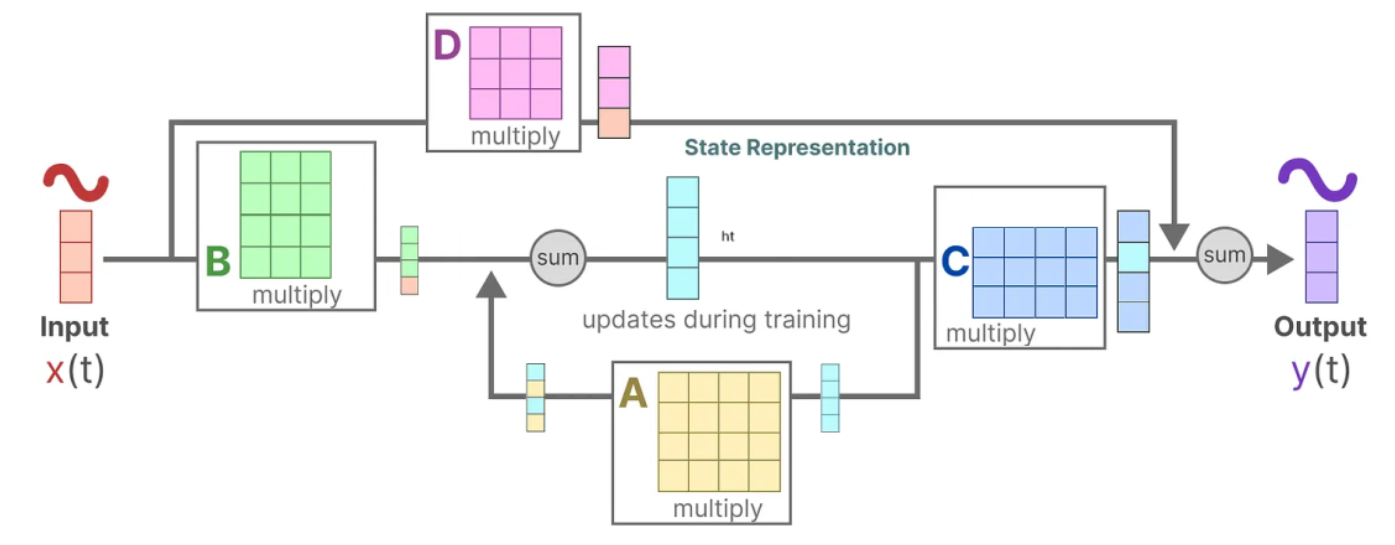
离散化
为了方便运算,将上述状态空间模型离散化,使用零阶保持法。 离散近似的结果为:
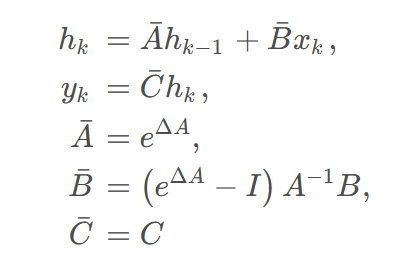
其中I为单位矩阵
卷积化
Mamba中的状态空间模型计算效率最大的提升就在于其序列运算可以卷积化。从0时刻开始向后推导状态空间模型几个时刻后的输出,即可得到如下的形式:

设计适当的卷积核即可将序列运算转化为卷积运算,形式如下所示:
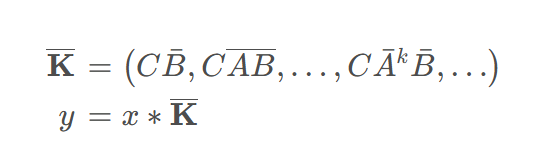
见解:设序列长度为x。使用高性能的卷积模式进行运算时会使用输入的所有信息预先计算K(0...x-1),最后直接与对应位置输入相乘即可。即这时Mamba是非因果的,每个点使用了未来的信息。
选择性机制
传统状态空间模型的时序结构导致了其输出状态完全依赖有序的输入数据。对于增减过、顺序打乱过的输入,在一些不相关数据混杂在序列中出现时,状态空间模型就无法对其进行有效处理。
Mamba针对这一情况进行了改进,在对B BB,C CC矩阵进行计算时,加入了选择性机制,即在计算是引入一个额外的线性层,对输入的输入的控制量和状态量进行选择,加强模型对不同输入形式的适应能力

选择性机制对状态空间模型的改进

并行累加计算流程
mamba结构

与Transformer结构类似,Mamba结构也是由若干Mamba块堆叠而成。一个基本的Mamba块结构如图所示:Mamba块由H3块以及门控MLP组合而成。H3为Hungry Hungry Hippos,是一种状态空间模型的执行方式。Mamba块简化了H3的结构,并与门控MLP结合,添加了残差项防止梯度消失。
使用mamba搭建模型一般会包含3个类似残差连接的部件:SSM内部的D,Mamba中除去SSM的另一条分支最后与SSM结果相乘,Mamba块外,即模型搭建时的残差连接
使用高效硬件乘法时先计算非离散化参数,送至GPU的SRAM(据我所知应该是share memory)中进行离散化及SSM运算,再回传到普通内存(HBM)。
此外,SSM正向传播并不会保存形状为(B, L, D, N)的中间状态以供反向传播训练,而是在反向传播时重新计算,与将其保存到HBM并读取相比,重新计算的耗时更短。
参考:
一文通透想颠覆Transformer的Mamba:从SSM、HiPPO、S4到Mamba_mamba模型-CSDN博客
Mamba模型底层技术详解,与Transformer到底有何不同?-CSDN博客
Mamba:2 状态空间模型 - 大模型知识库|大模型训练|开箱即用的企业大模型应用平台|智能体开发|53AI
原文代码:mamba/README.md 在 main ·状态空格/曼巴 (github.com)
论文:[2312.00752] Mamba:使用选择性状态空间的线性时间序列建模 (arxiv.org)
参考代码:mamba-minimal/README.md at master · johnma2006/mamba-minimal (github.com)

