
QAnything-1.4.0&1.4.1版本更新!使用指北!_qanything性能要求
赞
踩
久等了各位!时隔一个多月,我们在4月26日和5月20日接连发布了v1.4.0和v1.4.1两个版本,带来了问答性能,解析效果等多方面的改进,并新增了大量的新功能和新特性
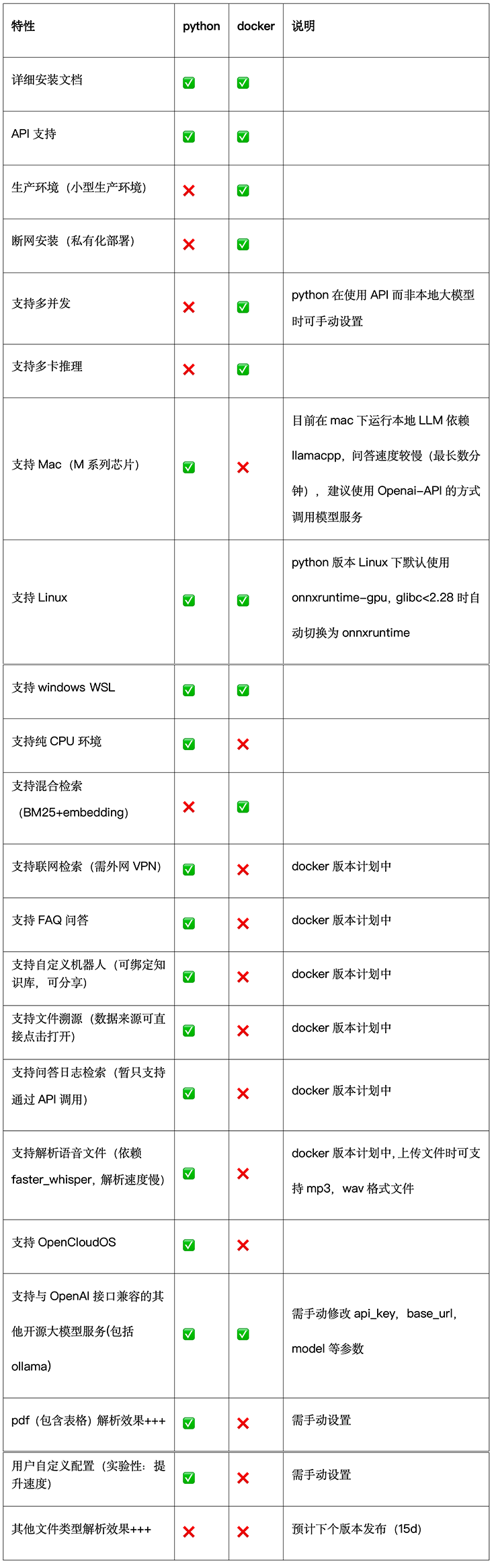
最新特性表
开发背景:
在v1.0.x->v1.3.x的版本迭代过程中,通过分析用户反馈,我们发现绝大部分的问题都是在使用本地大模型时产生的,因此我们把相当一部分工作重心放在了本地大模型的适配上
在这个目标下做了一系列的工作:
-
自动检测显卡的型号,计算能力和内存大小,并根据情况自动调整默认启动参数,以提供用户最佳体验,并给予相关提示。
-
支持Nvidia下全系列显卡,并根据用户硬件条件推荐本地大模型Size(3B,7B等)。
-
提供3种LLM推理运行后端:包括FasterTransformer(默认)、huggingface和vllm,通过FastChat Server API支持加载各种开源大模型。
-
提供纯python版本,自动根据运行环境切换本地大模型,模型自动下载等。
确实解决了一部分问题,但是随后我们发现这种做法类似于打地鼠,我们写的自动化逻辑本意是帮助用户减少手动操作的时间,尽量自动化运行QAnything,这个过程中添加了繁杂的检测和判断逻辑,但是相比用户使用场景的复杂性还远远不够,截止至v1.3.3版本发布,最多的问题仍然是本地模型运行过程中与系统软硬件环境产生的冲突,同时我们还发现大量用户存在使用自定义模型的需求,并不需要我们内置本地大模型(我们考虑到大部分个人用户的硬件条件,内置大模型主要是3B和7B的,实际使用效果欠佳),因此我们及时改变策略,将大模型这块独立出来,仅提供基础的本地大模型,同时提供更方便的使用其他开源大模型的接口,把工作重心放在增加更多的大模型衍生功能,同时进一步降低用户使用门槛上。
新发布的V1.4.0&V1.4.1将新增如下新特性:
-
新增联网检索
-
支持FAQ问答
-
支持自定义Bot
-
支持语音文件
-
支持文件溯源
-
支持问答日志检索
-
支持国产OS(OpenCloudOS)
-
支持所有与OpenAI-API兼容的大模型服务(包含ollama,通义千问DashScope等)
-
支持多卡推理
-
PDF文件解析效果优化(包含表格效果)
以及部分使用上的改进,包括服务启动时间优化,资源占用优化,修复已知问题等
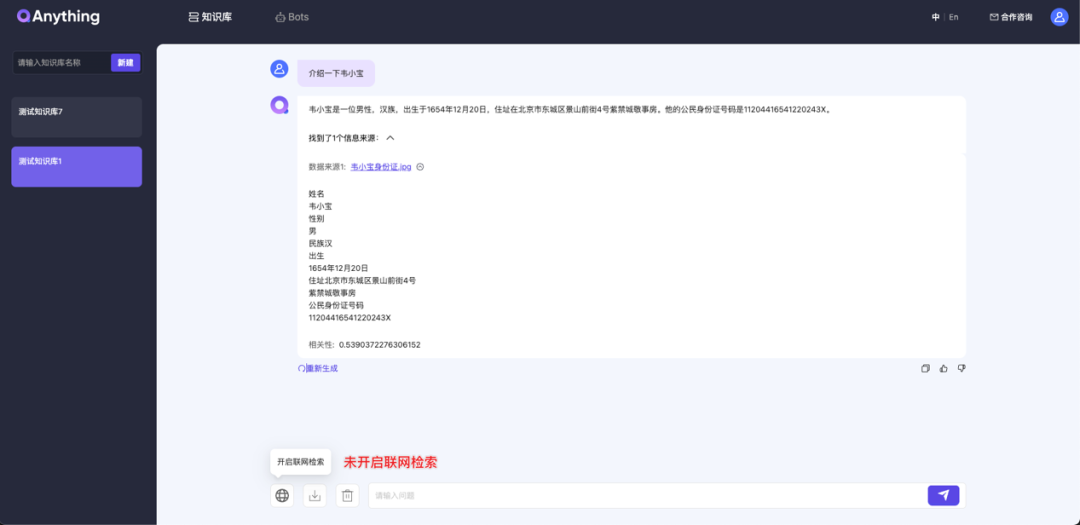
联网检索
注意:联网检索依赖于第三方库:GitHub - deedy5/duckduckgo_search
duckduckgo_search使用依赖外网VPN,如无法获取外网VPN请在前端页面关闭联网检索功能,防止报错。
未开启联网检索:
开启联网检索:

-
- import sys
-
- import requests
-
- import time
-
-
-
- def send_request():
-
- url = 'http://{your_host}:8777/api/local_doc_qa/local_doc_chat'
-
- headers = {
-
- 'content-type': 'application/json'
-
- }
-
- data = {
-
- "user_id": "zzp",
-
- "kb_ids": ["KBf652e9e379c546f1894597dcabdc8e47"],
-
- "question": "介绍一下韦小宝",
-
- "networking": True # True开启联网检索
-
- }
-
- try:
-
- start_time = time.time()
-
- response = requests.post(url=url, headers=headers, json=data, timeout=60)
-
- end_time = time.time()
-
- res = response.json()
-
- print(res['response'])
-
- print(f"响应状态码: {response.status_code}, 响应时间: {end_time - start_time}秒")
-
- except Exception as e:
-
- print(f"请求发送失败: {e}")
-
-
-
-
-
- if __name__ == '__main__':
-
- send_request()

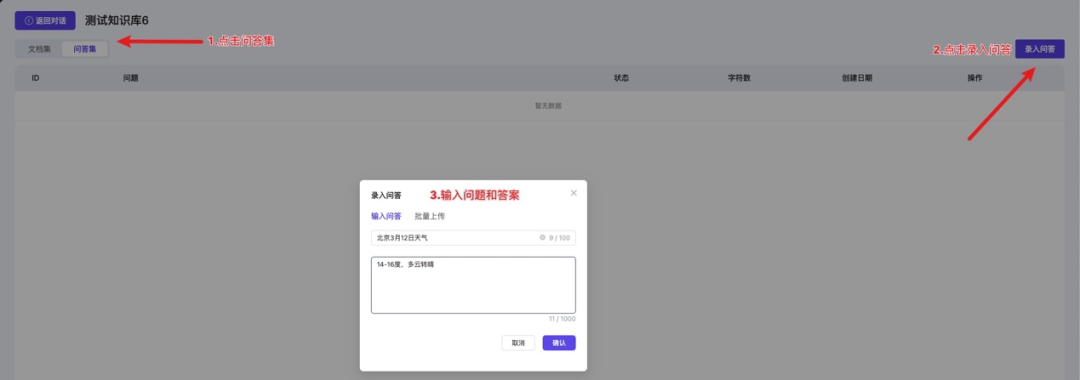
FAQ问答
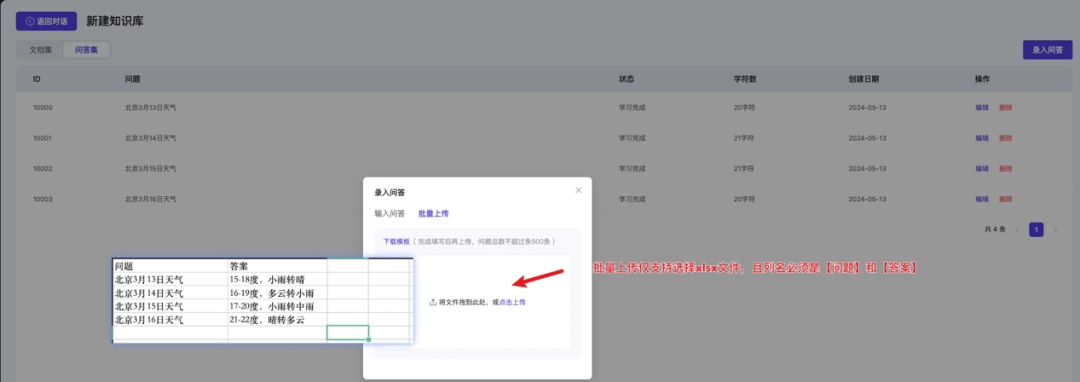
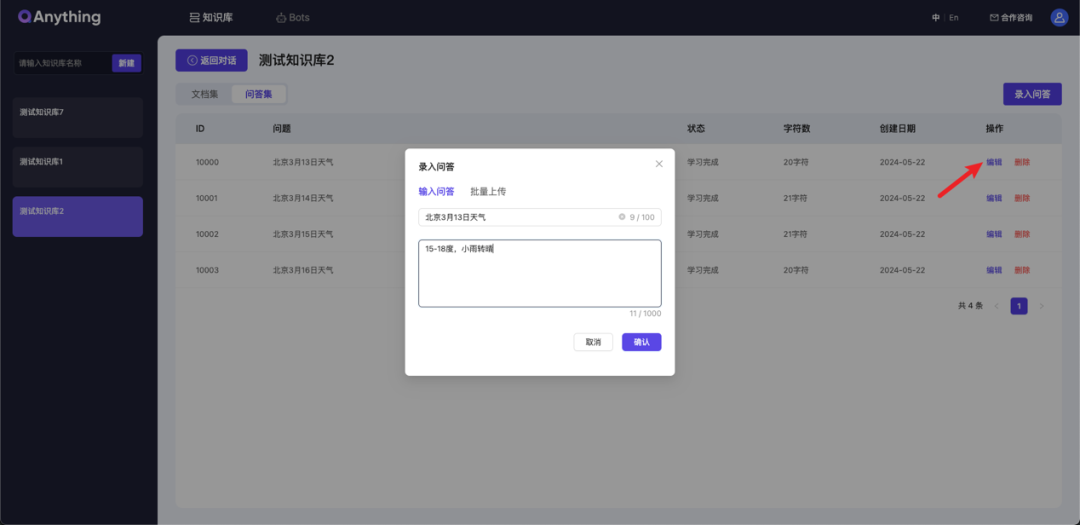
FAQ问答流程和普通问答一致,区别在于FAQ文件需要单独在问答集页面上传,支持手动输入以及excel文件上传两种方式
手动输入:
Excel上传:
编辑FAQ内容
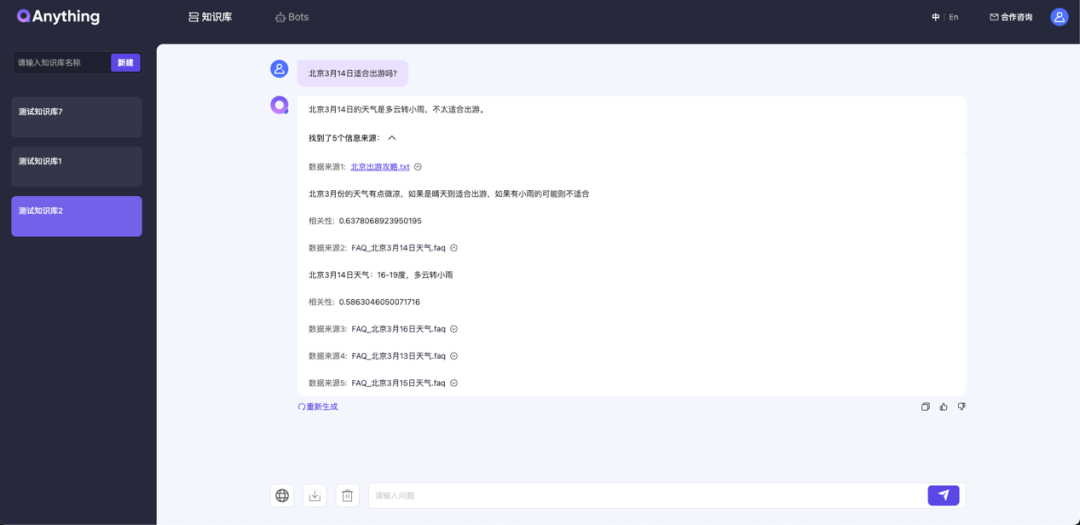
此时针对知识库的问答会同时检索文档集和问答集:
- import os
-
- import requests
-
-
-
- url = "http://{your_host}:8777/api/local_doc_qa/upload_faqs"
-
- folder_path = "./xlsx_data" # 文件所在文件夹,注意是文件夹!!
-
- data = {
-
- "user_id": "zzp",
-
- "kb_id": "KB6dae785cdd5d47a997e890521acbe1c9_FAQ",
-
- }
-
-
-
- files = []
-
- for root, dirs, file_names in os.walk(folder_path):
-
- for file_name in file_names:
-
- if file_name.endswith(".xlsx"):
-
- file_path = os.path.join(root, file_name)
-
- files.append(("files", open(file_path, "rb")))
-
-
-
- response = requests.post(url, files=files, data=data)
-
- print(response.text)
备注:
FAQ上传单次默认最多处理1000行,可手动修改这个限制,仅影响请求处理速度,太多可能会超时
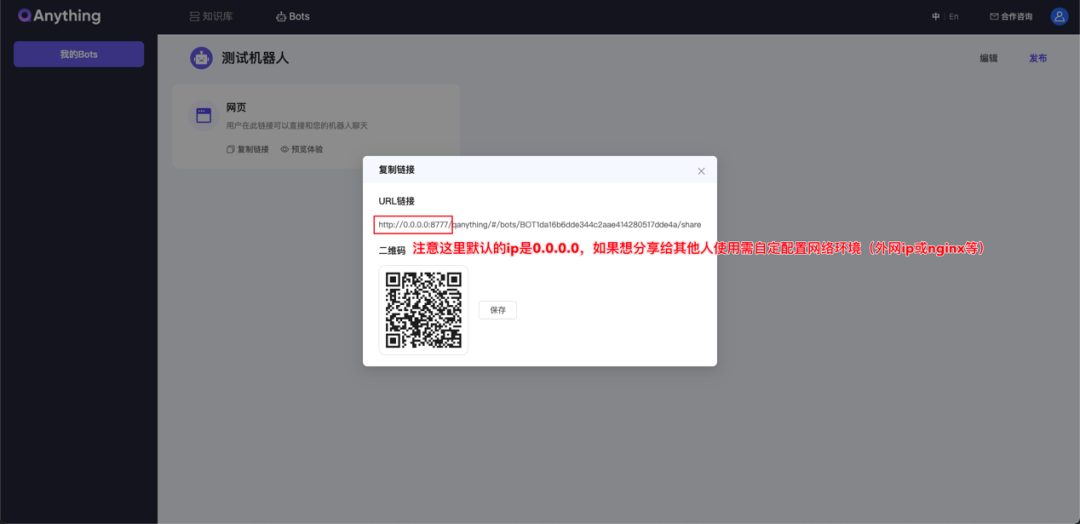
支持自定义Bot
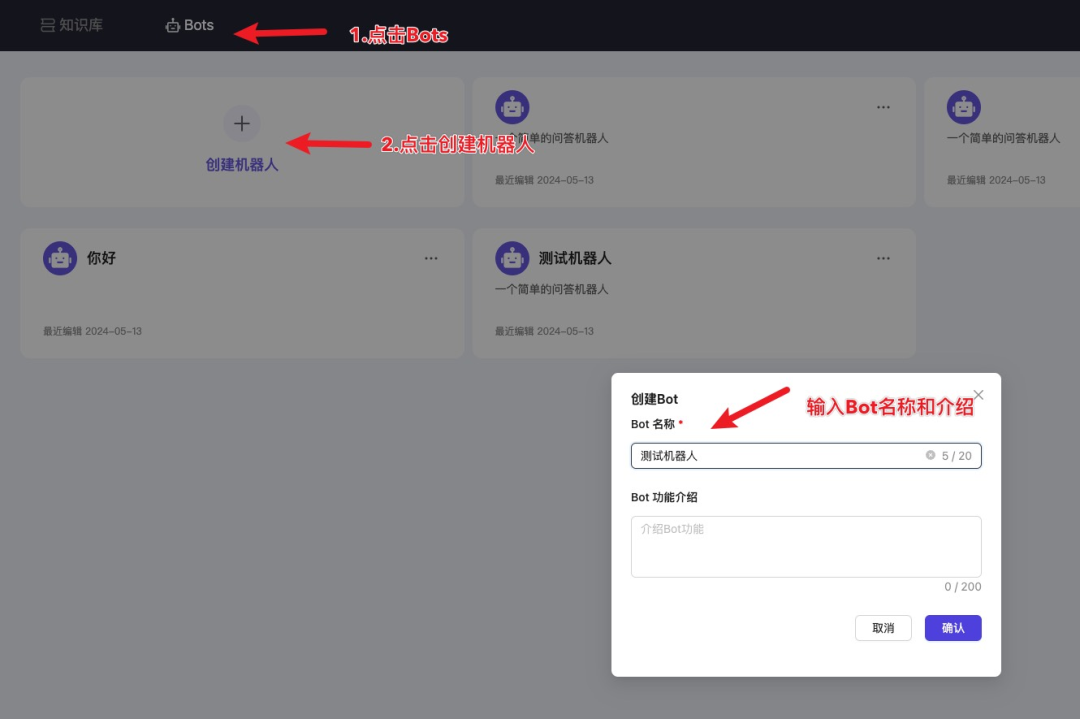
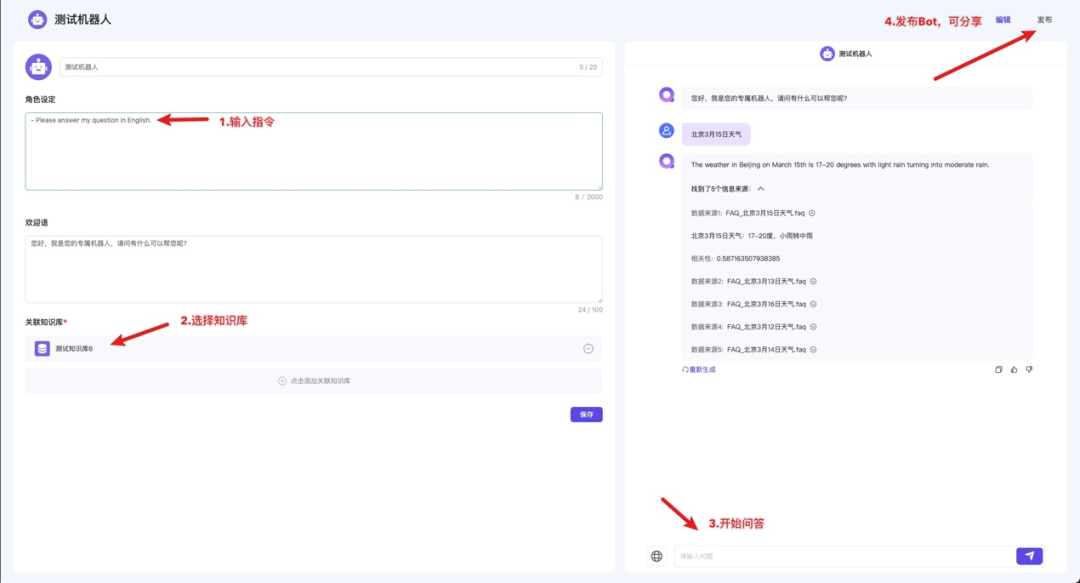
分享页面:
API调用:
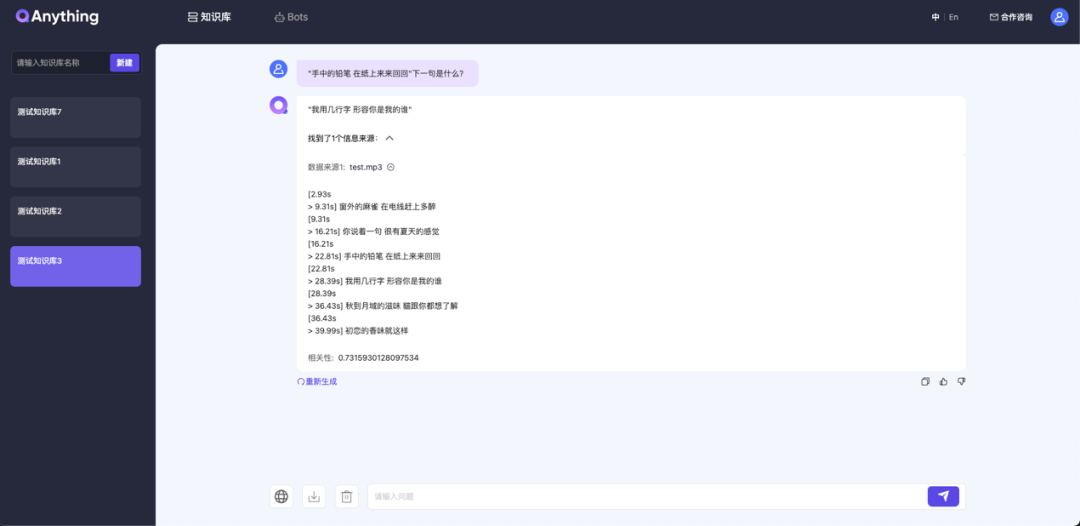
支持语音文件
支持解析MP3和WAV格式文件(依赖faster_whisper,解析速度慢,建议控制语音时长在60秒内)
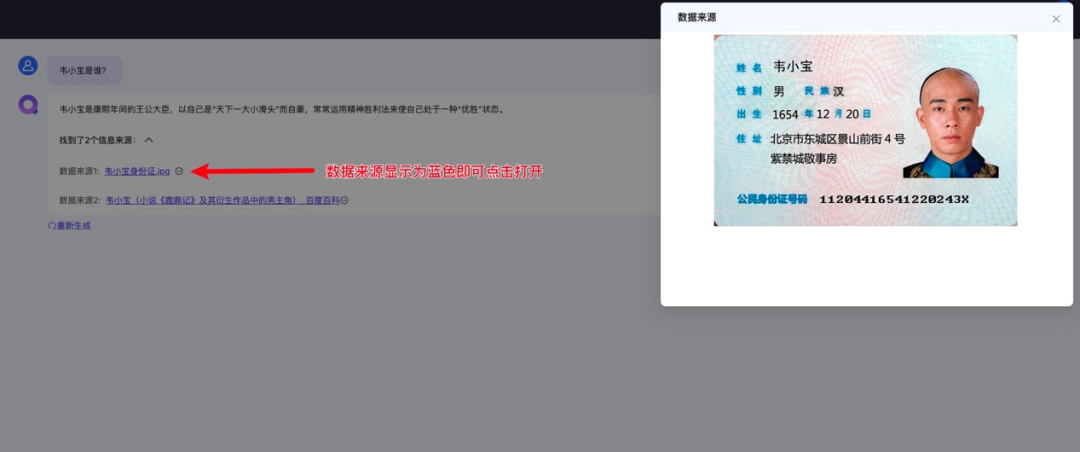
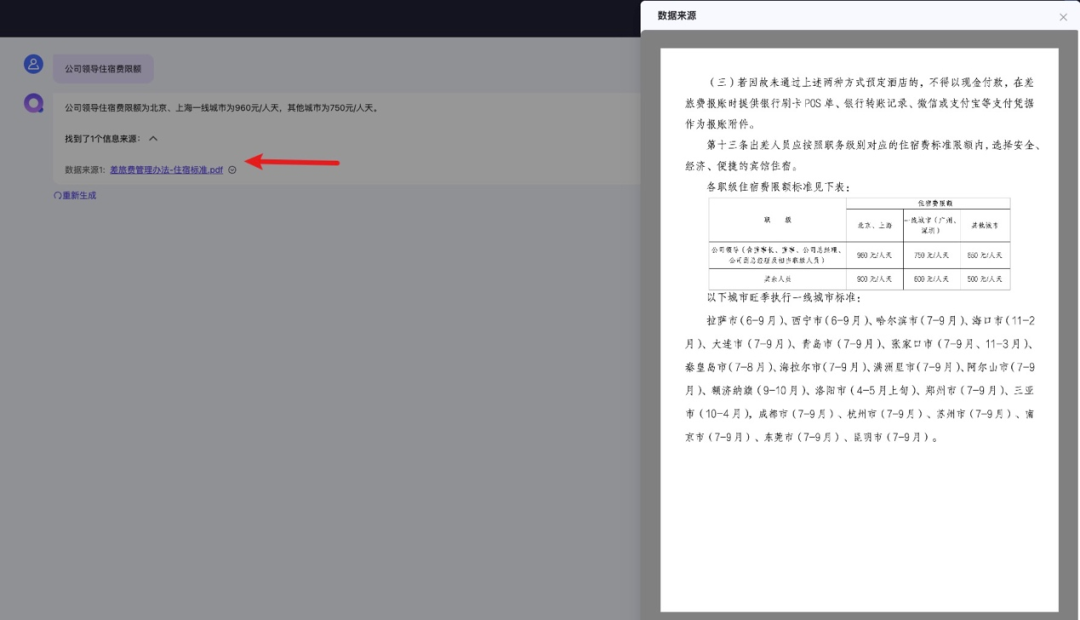
支持文件溯源
目前仅支持以下格式的文件溯源:
pdf,docx,xlsx,txt,jpg,png,jpeg,联网检索网络链接等,其他类型后续将尽快支持
支持问答日志检索(API)
目前仅支持API检索,后续将提供前端页面操作:检索API
- import requests
-
- import json
-
-
-
- url = "http://{your_host}:8777/api/local_doc_qa/get_qa_info"
-
- headers = {
-
- "Content-Type": "application/json"
-
- }
-
- data = {
-
- "user_id": "zzp",
-
- "kb_ids": [
-
- "KBe3f7b698208645218e787d2eee2eae41"
-
- ],
-
- "time_start": "2024-04-01",
-
- "time_end": "2024-04-29",
-
- "query": "韦小宝住址",
-
- "need_info": ["user_id"]
-
- }
-
-
-
- response = requests.post(url, headers=headers, data=json.dumps(data))
-
-
-
- print(response.status_code)
-
- print(response.text)
支持国产OS(OpenCloudOS)
OpenCloudOS是腾讯自研的国产操作系统:官网
OpenCloud 需要在 Docker 容器中运行,请先安装 Docker:Docker 版本 >= 20.10.5 且 docker-compose 版本 >= 2.23.3
- git clone -b qanything-python https://github.com/netease-youdao/QAnything.git
-
- cd QAnything
-
- docker-compose up -d
-
- docker attach qanything-container
-
- pip install -r requirements.txt
-
-
-
- # 随后启动方式与正常使用一致:
-
- https://github.com/netease-youdao/QAnything/blob/master/QAnything%E4%BD%BF%E7%94%A8%E8%AF%B4%E6%98%8E.md#%E5%9C%A8windows-wsl%E6%88%96linux%E7%8E%AF%E5%A2%83%E4%B8%8B%E8%BF%90%E8%A1%8C3b%E5%A4%A7%E6%A8%A1%E5%9E%8Bminichat-2-3b%E8%A6%81%E6%B1%82%E6%98%BE%E5%AD%9810gb
支持所有与OpenAI-API兼容的大模型服务(包含ollama,通义千问DashScope等)
docker版OpenaiAI接口兼容
bash ./run.sh -c cloud -i 0
# 手动输入api_key,base_url,model_name,context_length,除了api_key外均有默认值,且用户输入会自动保存,下次启动不用再次输入
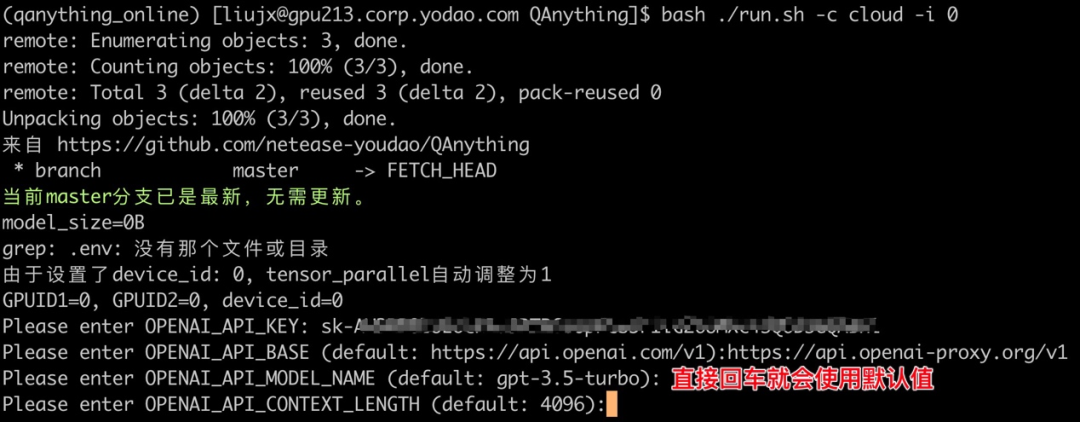
支持任意与OpenaAI接口兼容的服务
通义千问DashScope支持:通义千问DashScopeAPI
# 示例
openai_api_key = "sk-xxx"
openai_api_base = "https://dashscope.aliyuncs.com/compatible-mode/v1"
openai_model_name = "qwen1.5-72b-chat"
ollama支持:本地启动ollama服务
# 例如,当本地运行ollama run qwen:32b
openai_api_key = "ollama"
openai_api_base = "http://localhost:11434/v1"
openai_api_model_name = "qwen:32b"
python版OpenaiAI接口兼容
支持任意与OpenaAI接口兼容的服务
-
- # Linux或WSL上,注意cpu模式需要加-c参数
-
- bash scripts/base_run.sh -s "LinuxOrWSL" -w 4 -m 19530 -q 8777 -o -b 'https://api.openai.com/v1' -k 'sk-xxx' -n 'gpt-3.5-turbo' -l '4096'
-
-
-
- # Mac上
-
- bash scripts/base_run.sh -s "M1mac" -w 2 -m 19530 -q 8777 -o -b 'https://api.openai.com/v1' -k 'sk-xxx' -n 'gpt-3.5-turbo' -l '4096'
通义千问DashScope支持:通义千问DashScopeAPI 自定义
scripts/run_for_openai_api_xxx.sh内容为:
- # Linux或WSL上,注意cpu模式需要加-c参数
-
- bash scripts/base_run.sh -s "LinuxOrWSL" -w 4 -m 19530 -q 8777 -o -b 'https://dashscope.aliyuncs.com/compatible-mode/v1' -k 'sk-xxx' -n 'qwen1.5-72b-chat' -l '4096'
-
-
-
- # Mac上
-
- bash scripts/base_run.sh -s "M1mac" -w 2 -m 19530 -q 8777 -o -b 'https://dashscope.aliyuncs.com/compatible-mode/v1' -k 'sk-xxx' -n 'qwen1.5-72b-chat' -l '4096'
ollama支持:本地启动ollama服务 自定义scripts/run_for_openai_api_xxx.sh内容为:
- # Linux或WSL上,注意cpu模式需要加-c参数
-
- bash scripts/base_run.sh -s "LinuxOrWSL" -w 4 -m 19530 -q 8777 -o -b 'http://localhost:11434/v1' -k 'ollama' -n 'qwen:32b' -l '4096'
-
-
-
- # Mac上
-
- bash scripts/base_run.sh -s "M1mac" -w 2 -m 19530 -q 8777 -o -b 'http://localhost:11434/v1' -k 'ollama' -n 'qwen:32b' -l '4096'
支持多卡推理(仅支持docker版):
# 当使用默认后端时:(bash run.sh启动时不指定-b参数或-b参数为default)
无法使用多卡推理大模型,仅支持使用两张卡省显存
bash ./run.sh -c local -i 0,1 -b defaul # 此时的显存使用逻辑为第一张卡部署大模型,第二张卡部署embedding,rerank,和ocr模型,实际意义不大
# 当使用huggingface或vllm后端时支持多卡推理大模型
# 以下示例为两张卡启动,默认embedding,部署在第一张卡上,rerank,ocr模型部署在第二张卡上,两张卡剩余显存均会用于LLM推理
bash ./run.sh -c local -i 0,1 -b default # 指定0,1号GPU启动,请确认有多张GPU可用,注意设备数量必须是1,2,4,8,16,否则显存无法正常分配
说明:多卡部署是指大模型运行平均分配显存到多张显卡上,但是由于embedding,rerank和ocr模型也需要占用显存(共需4G+显存,启动时占用2G显存,运行后会逐渐上涨至4G左右),目前这三个模型默认会分配到前两个设备上,所以第一张,第二张显卡的显存占用会比其他卡多2G以上,默认启动参数-r(gpu_memory_utilization)=0.81,如果手动设置为0.9以上可能会存在前两张卡显存不足无法启动或启动后运行时显存不足报错的情况
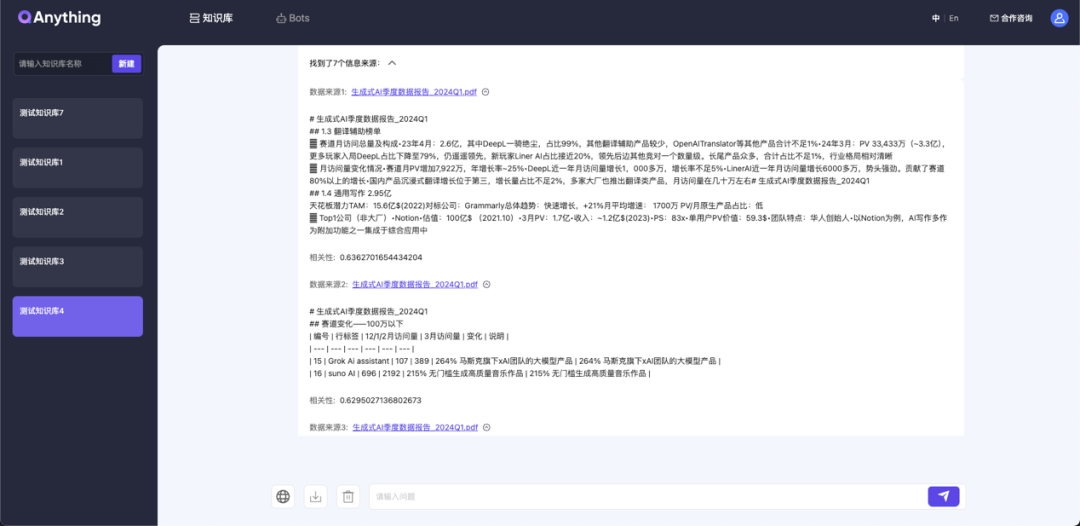
PDF文件解析效果优化(包含表格效果)
表格优化前:

表格优化后:

文字优化前:
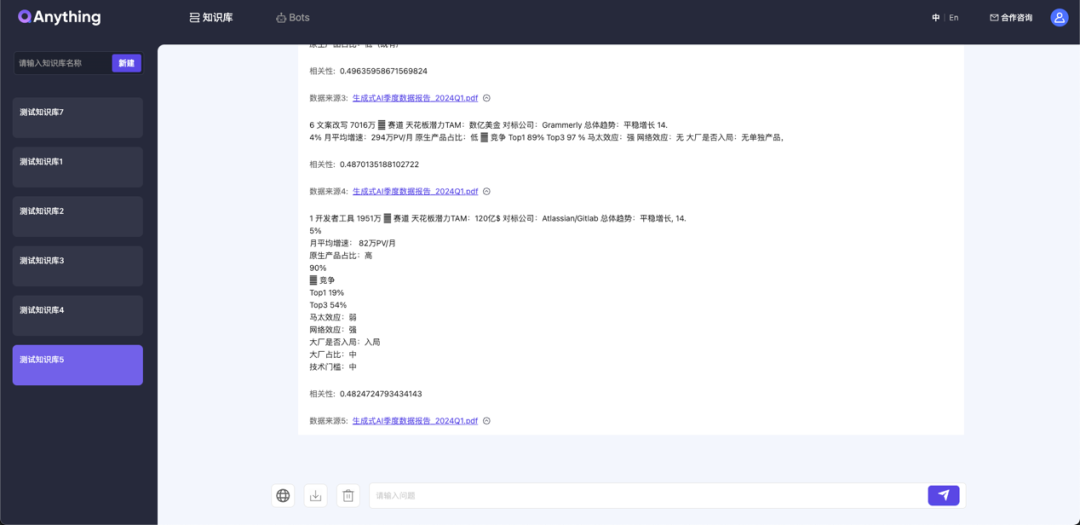
文字优化后:
所有上传的文档以及文档解析后的结果均会保存在项目根目录下的QANY_DB文件夹中,示例如下,可自行查看解析结果:
> pwd
/Users/liujunxiong/workspace/ai_team/qanything-open-source/QANY_DB/content/zzp/e396215cddf44df9bdde7ef3dbf75ad4
> ls -R
QAnything使用说明.pdf QAnything使用说明_1716194377
./QAnything使用说明_1716194377:
QAnything使用说明.json QAnything使用说明_md
./QAnything使用说明_1716194377/QAnything使用说明_md:
QAnything使用说明.md
注意:优化的PDF解析器需要手动开启:详情
更多信息可见:QAnything开源代码地址:GitHub - netease-youdao/QAnything: Question and Answer based on Anything.
线上直接体验:https://qanything.ai

