
热门标签
热门文章
- 1ROS2极简总结-SLAM_ros2 slam
- 2SpringBoot+Vue实现学生宿舍管理系统_学生宿舍管理系统springboot,vue
- 3linux系统 mysql-8.0.32安装_mysql8.0.32 linux
- 4iOS常用第三方库大全,史上最全第三方库收集_100张waterflow网络库地址图片
- 5若依(RuoYi-Vue)+Flowable工作流前后端整合教程_ruoyi-flowable
- 6安卓期末大作业——售票APP源码和设计报告_android期末大作业app源码
- 7【解码未来:Transformer模型家族引领自然语言新纪元】_transfomer家族
- 8深度学习笔记(三)--目标检测算法综述_wordtree
- 9Kubernetes 2018 年度简史_kubernetes哪一年成为事实标准
- 10WebView开源库终极学习方案_x5webview是开源的吗
当前位置: article > 正文
YOLOv5改进策略|YOLO模型优化|Slowfast 和 YOLOv5 检测器 自动驾驶、车辆识别、车牌识别、车道识别、行人识别_slowfast和yolo的区别
作者:码创造者 | 2024-07-26 14:32:38
赞
踩
slowfast和yolo的区别
订阅专栏后私信(留下联系方式)获取完整源码+远程部署
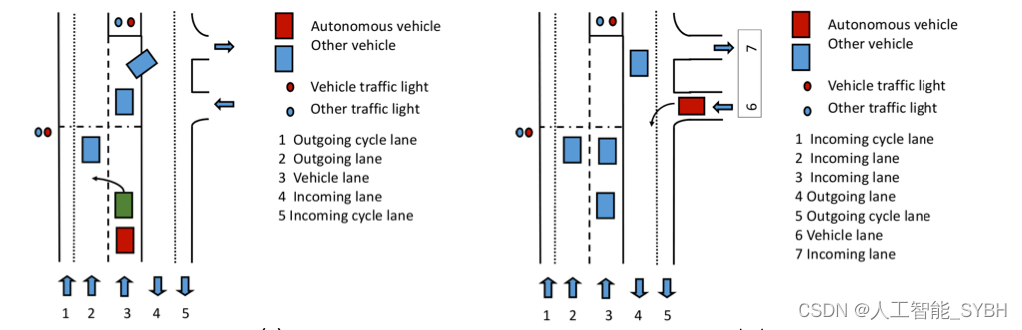
目录
最近几年,自动驾驶(或者机器人辅助驾驶)已成为一个快 速发展的研究领域。全自动驾驶汽⻋的竞赛促使许多大公司, 如谷歌、丰田和福特,开发了自己的概念机器人汽⻋[1]、[2]、 [3]。尽管自动驾驶汽⻋被广泛认为是人工智能实际应用的主要 开发和测试场,但安全性、道德、成本和可靠性方面仍然存在令 人担忧的主要原因[4]。特别是从安全⻆度来看,智能汽⻋需要 强有力地解释与他们共享环境的人类(驾驶员、行人或骑自行⻋ 者)的行为,以便应对他们的决策。态势感知因此,了解其他道 路使用者行为的能力对于自动驾驶⻋辆(AV)的安全部署至关重 要。
最新一代的机器人汽⻋配备了一系列不同的传感器(即激光 测距仪、雷达、摄像头、GPS),以提供有关道路上发生的情况 的数据[5]。然后融合如此提取的信息以建议⻋辆应如何移动 [6]、[7]、[8]、[9]。然而,一些作者认为,视觉对于自动驾驶汽 ⻋来说是一种足够的感知能力,可以在其环境中导航,并得到人 类这样做的能力的支持。无需征召我们自己作为后一种观点的支持者,在本文中我们考虑了以下背景:基于 视觉的自动驾驶[10]来自安装在⻋辆上的摄像头以流媒体、在线 方式捕获的视频序列。
虽然检测器网络 [11] 通常经过训练以促进道路场景中的物体 和演员识别,但这只是让⻋辆“看到”周围的事物。这项工作的 理念是,强大的自动驾驶能力需要以语
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/885789
推荐阅读
相关标签

