
- 1chatglm6b和闻达的功能扩展_chatglm 本地知识库
- 2scp命令——安全传输文件_scp 远程到本地
- 3解决Mac OS升级系统后git无法使用的问题_macos sonoma上使用git遇到的问题
- 4搭建个人服务器_自己搭建服务器
- 5动态路由 华三nat 静态路由_H3CNE学习---静态路由、动态路由协议
- 6Git:将本地仓库上传至GitHub的远程仓库_git提交到远程仓库命令
- 7使用RPA通过GPT大模型AI Agent自动执行业务流程任务企业级应用开发实战:如何选取符合业务需求的AI模型和技术_大模型应用流程
- 8一文读懂 MySQL 索引 B+树原理!_mysql索引b+树
- 9JS 创建表格_js表格
- 10如何保证同事的代码不会腐烂?一文带你了解 Alibaba COLA 架构_alibaba.cola.statemachine
只需单卡RTX 3090,低比特量化训练就能实现LLaMA-3 8B全参微调_llama3 8b fine-tuning 需要多少gpu
赞
踩
自 2010 年起,AI 技术历经多个重大发展阶段,深度学习的崛起和 AlphaGo 的标志性胜利显著推动了技术前进。尤其是 2022 年底推出的 ChatGPT,彰显了大语言模型(LLM)的能力达到了前所未有的水平。自此,生成式 AI 大模型迅速进入高速发展期,并被誉为第四次工业革命的驱动力,尤其在推动智能化和自动化技术在产业升级中有巨大潜力。这些技术正在改变我们处理信息、进行决策和相互交流的方式,预示着将对经济和社会各层面带来深远的变革。因此,AI 为我们带来了重大机遇,然而在 AI 技术不断进步的同时,其产业落地也面临诸多挑战,尤其是高昂的成本问题。例如,在商业化过程中,大模型尤其因成本过高而成为企业的一大负担。持续的技术突破虽然令人鼓舞,但如果落地阶段的成本无法控制,便难以持续资助研发并赢得广泛信任。然而,开源大模型的兴起正逐步改变这一局面,它们不仅技术开放,还通过降低使用门槛促进了技术的平等化和快速发展。例如,普通的消费级 GPU 就能够支持 7B/8B 规模模型的全参数微调操作,可能比采用高成本闭源模型成本低几个数量级。在这种去中心化的 AI 范式下,开源模型的应用在保证质量的前提下,可以显著降低边际成本,加速技术的商业化进程。此外,观察显示,经过量化压缩的较大模型在性能上往往优于同等大小的预训练小模型,说明量化压缩后的模型仍然保持了优秀的能力,这为采用开源模型而非自行重复预训练提供了充分的理由。
在 AI 技术的迅猛发展中,云端大模型不断探索技术的极限,以实现更广泛的应用和更强大的计算能力。然而,市场对于能够快速落地和支撑高速成长的智能应用有着迫切需求,这使得边缘计算中的大模型 —— 特别是中小型模型如 7B 和 13B 的模型 —— 因其高性价比和良好的可调性而受到青睐。企业更倾向于自行微调这些模型,以确保应用的稳定运行和数据质量的持续控制。此外,通过回流机制,从应用中收集到的数据可以用于训练更高效的模型,这种数据的持续优化和用户反馈的精细化调整成为了企业核心竞争力的一部分。尽管云端模型在处理复杂任务时精度高,但它们面临的几个关键挑战不容忽视:
-
推理服务的基础设施成本:支持 AI 推理的高性能硬件,尤其是 GPU,不仅稀缺而且价格昂贵,集中式商业运营带来的边际成本递增问题成为 AI 业务从 1 到 10 必须翻越的障碍。
-
推理延迟:在生产环境中,模型必须快速响应并返回结果,任何延迟都会直接影响用户体验和应用性能,这要求基础设施必须有足够的处理能力以满足高效运行的需求。
-
隐私和数据保护:特别是在涉及敏感信息的商业应用场景中,使用第三方云服务处理敏感数据可能会引发隐私和安全问题,这限制了云模型的使用范围。
考虑到这些挑战,边缘计算提供了一个有吸引力的替代方案。在边缘设备上直接运行中小模型不仅能降低数据传输的延迟,提高响应速度,而且有助于在本地处理敏感数据,增强数据安全和隐私保护。结合自有数据的实时反馈和迭代更新,AI 应用将更高效和个性化。
在当前的开源模型和工具生态中,尽管存在众多创新和进步,仍面临一系列不足之处。首先,这些模型和工具往往并未针对本地部署场景进行优化,导致在本地运用时常常受限于算力和内存资源。例如,即便是相对较小的 7B 规模模型,也可能需要高达 60GB 的 GPU 显存 (需要价格昂贵的 H100/A100 GPU) 来进行全参数微调。此外,市场上可选的预训练小型模型数量和规模相对有限,大模型的开发团队往往更专注于追求模型规模的扩展而非优化较小的模型。另一方面,现有的量化技术虽然在模型推理部署中表现良好,但其主要用途是减少模型部署时的内存占用。量化后的模型权重在微调过程中无法进行优化,这限制了开发者在资源有限的情况下使用较大模型的能力。开发者往往希望在微调过程中也能通过量化技术节省内存,这一需求尚未得到有效解决。
我们的出发点在于解决上述痛点,并为开源社区贡献实质性的技术进步。基于 Neural Architecture Search (NAS) 以及相匹配的 Post-Training Quantization (PTQ) 量化方案,我们提供了超过 200 个从不同规模开源大模型序列压缩而来的低比特量化小模型,这些模型涵盖了从 110B 到 0.5B 的规模跨度,并优先保证精度和质量,再次刷新了低比特量化的 SOTA 精度。同时,我们的 NAS 算法深入考量了模型参数量化排布的硬件友好性,使得这些模型能轻易的在主流计算硬件 (如 Nvidia GPU 和 Apple silicon 芯片硬件平台) 进行适配,极大地方便了开发者的使用。此外,我们推出了 Bitorch Engine 开源框架以及专为低比特模型训练设计的 DiodeMix 优化器,开发者可以直接对低比特量化模型在量化空间进行全参数监督微调与继续训练,实现了训练与推理表征的对齐,大幅度压缩模型开发与部署的中间环节。更短的工程链条将大幅度提升工程效率,加快模型与产品迭代。通过结合低比特权重训练技术和低秩梯度技术,我们就能实现在单卡 RTX 3090 GPU 上对 LLaMA-3 8B 模型进行全参数微调(图 1)。上述解决方案简洁有效,不仅节省资源,而且有效地解决了量化模型精度损失的问题。我们将在下文对更多技术细节进行详细解读。
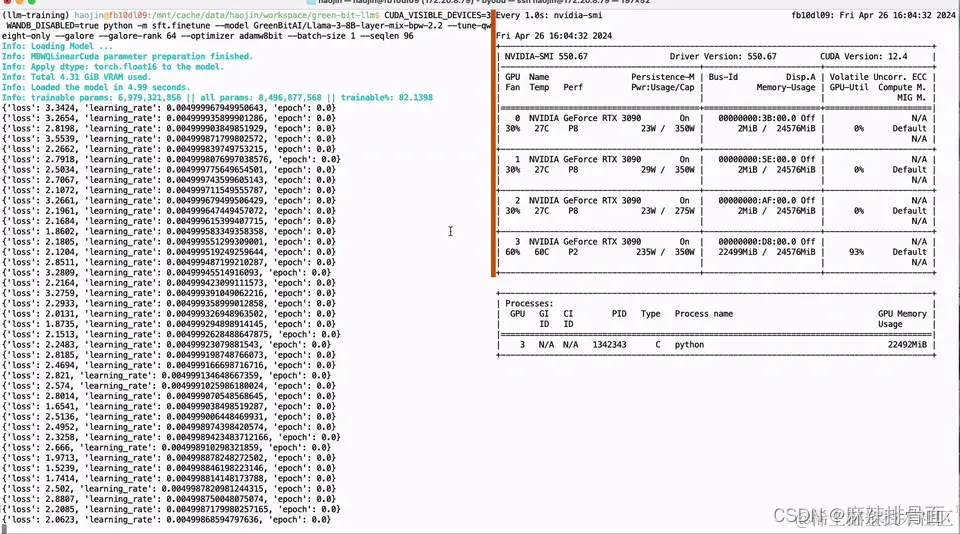
图 1. 单卡 3090 实现 LLaMA-3 8B 全参微调
模型量化
大模型时代的显著特征之一便是模型对计算资源需求的大幅度攀升。GPTQ 与 AWQ 等权重 PTQ 压缩方案以可扩展的方式验证了大语言模型在 4-bit 表征上的可靠性,在相比于 FP16 表征实现 4 倍的权重空间压缩的同时实现了较小的性能丢失,大幅度降低模型推理所需的硬件资源。与此同时,QLoRA 巧妙地将 4-bit LLM 表征与 LoRA 技术相结合,将低比特表征推广至监督微调阶段,并在微调结束后将 LoRA 模块与原始 FP16 模型融合,实现了低资源需求下的模型 Parameter-Efficient-Finetuning (PEFT)。这些前沿的高效工程探索为社区提供了便利的研究工具,大幅度降低了模型研究与产业应用的资源门槛,也进一步激发了学术与产业界对更低比特表征的想象空间。
相比于 INT4,更低比特的 Round-To-Nearest (RTN) 量化如 INT2 表征通常要求原始模型有着更平滑的连续参数空间才能保持较低的量化损失,例如,超大规模模型往往存在容量冗余并有着更优的量化容忍度。而通过 LLM.int8 () 等工作对当前基于 transformer 架构的大语言模型分析研究,我们已经观察到了模型推理中广泛存在着系统性激活涌现现象,少数通道对最终推理结果起着决定性作用。近期 layer-Importance 等多项工作则进一步观测到了不同深度的 transformer 模块对模型容量的参与度也表现出非均匀分布的特性。这些不同于小参数模型的分布特性引申出了大量 Model Pruning 相关研究的同时也为低比特压缩技术提供了研究启示。基于这些工作的启发,我们探索了一种搜索与校准结合的 Two-stage LLM 低比特量化方案。
(1) 首先,我们利用 NAS 相关方法对大语言模型参数空间的量化敏感性进行搜索与排序,利用经典的混合精度表征实现模型参数中的最优比特位分配。为降低模型量化后的大规模硬件部署难度,我们放弃了复杂的矢量量化与 INT3 表征等设计,采用经典 Group-wise MinMax Quantizer,同时仅选择 INT4 (group size 128) 与 INT2 (group size 64) 作为基础量化表征。相对简单的 Quantizer 设计一方面降低了计算加速内核的设计复杂度与跨平台部署难度,另一方面也对优化方案提出了更高的要求。为此,我们探索了 Layer-mix 与 Channel-mix 两种排布下的混合精度搜索空间。其中,Channel-mix 量化由于能更好适配 transformer 架构的系统性激活涌现现象,往往能达到更低的量化损失,而 Layer-mix 量化在具备更优的硬件友好度的同时仍然保持了极佳的模型容量。利用高效的混合精度 NAS 算法,我们能在数小时内基于低端 GPU 如 RTX 3090 上完成对 Qwen1.5 110B 大模型的量化排布统计,并基于统计特性在数十秒内完成任意低比特量级模型的最优架构搜索。我们观察到,仅仅基于搜索与重要性排序,已经可以快速构造极强的低比特模型。
(2) 搜索得到模型的量化排布后,我们引入了一种基于离线知识蒸馏的可扩展 PTQ 校准算法,以应对超低比特量化 (如 2 到 3-bit) 带来的累积分布漂移问题,仅需使用不超过 512 个样本的多源校准数据集,即可在数小时内使用单张 A100 GPU 完成 0.5B-110B 大语言模型的 PTQ 校准。尽管额外的校准步骤引入了更长的压缩时间,从经典低比特以及量化感知训练(QAT)相关研究的经验中我们可以了解到,这是构建低量化损失模型的必要条件。而随着当前开源社区 100B + 大模型的持续涌现 (如 Command R plus、Qwen1.5 110B, LLama3 400B),如何构建高效且可扩展的量化压缩方案将是 LLM 社区系统工程研究的重要组成部分,也是我们持续关注的方向。我们经验性的证明,搜索与校准相结合的低比特量化方案在推进低量化损耗表征模型的同时,在开源社区模型架构适配、硬件预期管理等方面都有着显著优势。
性能分析
基于 Two-stage 量化压缩方案,我们提供了超过 200 个从不同规模开源大模型序列压缩而来的低比特量化小模型,涵盖了最新的 Llama3、Phi-3、Qwen1.5 以及 Mistral 等系列。我们利用 EleutherAI 的 lm-evaluation-harness 库等对低比特量化模型的真实性能与产业场景定位进行了探索。其中我们的 4-bit 量化校准方案基本实现了相对于 FP16 的 lossless 压缩。基于混合 INT4 与 INT2 表征实现的 sub-4 bit 量化校准方案在多项 zero-shot 评测结果表明,搜索与少量数据校准的经典 INT2 量化表征已经足够维持 LLM 在语言模型阅读理解 (BoolQ,RACE,ARC-E/C)、常识推理 (Winogr, Hellaswag, PIQA) 以及自然语言推理 (WIC, ANLI-R1, ANLI-R2, ANLI-R3) 方面的核心能力。

表 1. 低比特量化模型 zero-shot 评测示例
同时我们试图利用进一步的 few-shot 消融对比实验探索超低比特在产业应用中的定位,有趣的现象是,INT2 表征为主体的超低比特 (bpw: 2.2/2.5) 模型在 5-shot 帮助下即可实现推理能力的大幅度提升。这种对少量示例样本的利用能力表明,低比特压缩技术在构造容量有限但足够 “聪明” 的语言模型方面已经接近价值兑现期,配合检索增强 (RAG) 等技术适合构造更具备成本效益的模型服务。

表 2. 低比特量化模型 5-shot 评测示例
考虑到当前少样本 PTQ 校准仅仅引入了有限的计算资源 (校准数据集 < 512),以我们开源的低比特模型作为初始化进行更充分的全参数量化训练将进一步提升低比特模型在实际任务中的表现,我们已经为这一需求的高效实现提供了定制化开源工具。
开源工具
我们推出了三款实用的工具来辅助这些模型的使用,并计划未来持续优化和扩展。
Bitorch Engine (BIE) 是一款前沿的神经网络计算库,其设计理念旨在为现代 AI 研究与开发找到灵活性与效率的最佳平衡。BIE 基于 PyTorch,为低位量化的神经网络操作定制了一整套优化的网络组件,这些组件不仅能保持深度学习模型的高精度和准确性,同时也大幅降低了计算资源的消耗。它是实现低比特量化 LLM 全参数微调的基础。此外,BIE 还提供了基于 CUTLASS 和 CUDA 的 kernel,支持 1-8 bit 量化感知训练。我们还开发了专为低比特组件设计的优化器 DiodeMix,有效解决了量化训练与推理表征的对齐问题。在开发过程中,我们发现 PyTorch 原生不支持低比特张量的梯度计算,为此我们对 PyTorch 进行了少量调整,提供了支持低比特梯度计算的修改版,以方便社区利用这一功能。目前我们为 BIE 提供了基于 Conda 和 Docker 的两种安装方式。而完全基于 Pip 的预编译安装版本也会在近期提供给社区,方便开发者可以更便捷的使用。
green-bit-llm 是为 GreenBitAI low-bit LLM 专门开发的工具包。该工具包支持云端和消费级 GPU 上的高性能推理,并与 Bitorch Engine 配合,完全兼容 transformers、PEFT 和 TRL 等主流训练 / 微调框架,支持直接使用量化 LLM 进行全参数微调和 PEFT。目前,它已经兼容了多个低比特模型序列,详见表 3。

表 3. 已支持低比特模型序列信息
以目前最新的开源大模型 Llama-3 8b base 模型为例,我们选择它的 2.2/2.5/3.0 bit 作为全参数量化监督微调 (Q-SFT) 对象,使用 huggingface 库托管的 tatsu-lab/alpaca 数据集 (包含 52000 个指令微调样本) 进行 1 个 epoch 的最小指令微调对齐训练测试,模型完全在量化权重空间进行学习而不涉及常规的 LoRA 参数优化与融合等后处理步骤,训练结束后即可直接实现高性能的量化推理部署。在这一例子中,我们选择不更新包括 Embedding,、LayerNorm 以及 lm.head 在内的任何其他 FP16 参数,以验证量化空间学习的有效性。传统 LoRA 微调、Q-SFT 配合 Galore 优化器微调以及单纯使用 Q-SFT 微调对低比特 Llama 3 8B 模型能力的影响如表 4 中所示。

表 4. Q-SFT 对量化 LLM 的 zero-shot 能力影响
相比于传统的 LoRA 微调 + 后量化的工程组合,Q-SFT 直接在推理模型量化空间进行学习的方式大幅度简化了大模型从开发到部署之间的工程链条,同时实现了更好的模型微调效果,为更具成本效益的模型扩展提供了解决方案。此外,推理模型与训练模型的表征对齐也为更丝滑的端侧学习与应用提供了可能性,例如,在端侧进行非全参数 Q-SFT 将成为更可靠的端侧优化管线。
在我们的自研低比特模型以外,green-bit-llm 完全兼容 AutoGPTQ 系列 4-bit 量化压缩模型,这意味着 huggingface 现存的 2848 个 4-bit GPTQ 模型都可以基于 green-bit-llm 在量化参数空间进行低资源继续学习 / 微调。作为 LLM 部署生态最受欢迎的压缩格式之一,现有 AutoGPTQ 爱好者可以基于 green-bit-llm 在模型训练和推理之间进行无缝切换,不需要引入新的工程节点。
Q-SFT 和 Bitorch-Engine 能在低资源环境下稳定工作的关键是,我们探索了专用于低比特大模型的 DiodeMix 优化器,以缓解 FP16 梯度与量化空间的表征 Mismatch 影响,量化参数更新过程被巧妙的转换为基于组间累积梯度的相对大小排序问题。更符合量化参数空间的高效定制优化器将是我们未来持续探索的重要方向之一。
gbx-lm 工具将 GreenBitAI 的低比特模型适配至苹果的 MLX 框架,进而能在苹果芯片上高效的运行大模型。目前已支持模型的加载和生成等基础操作。此外,该工具还提供了一个示例,遵循我们提供的详尽指南,用户可以在苹果电脑上迅速建立一个本地聊天演示页面,如下图所示。
如何学习大模型 AGI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/899605

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

