
- 12024最新python安装教程(小白入门)_python安装教程4
- 2遥感大模型汇总
- 3为什么学完黑盒测试用例设计方法,还是写不好用例?
- 4【故障诊断】基于小波变换实现轮箱振动信号分析附Matlab代码_matlab能进行振动分析中各种故障模拟吗
- 5【多模态】34、LLaVA-v1.5 | 微软开源,用极简框架来实现高效的多模态 LMM 模型_llava-1.5
- 6机器人控制系列教程之UR机器人运动学求解_ur机器人运动解耦
- 7Android Xfermode类似于刮刮卡效果_android xfermodeview 刮刮乐
- 8如何更快地执行 Selenium 测试用例?
- 9前滴滴出行产品经理刘飞:写给产品经理的说明书(上)
- 10浏览器输入域名访问全流程解析_访问域名
VideoLLaMA 2:多模态视频理解新突破,音频理解能力再升级,挑战 GPT-4V_video-llama-2 video-llava-2
赞
踩
前言
近年来,人工智能技术飞速发展,尤其是大模型的出现,为视频理解和生成领域带来了前所未有的机遇。然而,现有的视频大模型(Video-LLM)在处理视频中复杂的时空信息和音频信息方面仍存在不足,例如无法有效融合不同帧的特征,以及忽视了音频信息在场景理解中的重要作用。
为了克服这些挑战,阿里巴巴达摩院发布了 VideoLLaMA 2,一个旨在提升视频时空建模和音频理解能力的开源视频大模型。VideoLLaMA 2 通过引入时空卷积连接器(STC Connector)和音频分支,在多个视频理解和音频理解任务中展现出优异的性能,超越了同类开源模型,并在某些方面接近了闭源模型。
-
Huggingface模型下载:https://huggingface.co/DAMO-NLP-SG/VideoLLaMA2-7B
-
AI快站模型免费加速下载:https://aifasthub.com/models/DAMO-NLP-SG

技术特点
VideoLLaMA 2 的核心技术在于其巧妙的设计和创新性的方法:
-
时空卷积连接器 (STC Connector): 为了更好地处理视频中的时空信息,VideoLLaMA 2 引入了 STC Connector 模块。STC Connector 通过对视频帧进行编码,并利用 3D 卷积和 RegStage 模块进行时空特征聚合,有效地保留了视频中的空间和时间局部细节,同时减少了时空特征的维度。
-
音频分支: 为了提升模型对音频信息的理解能力,VideoLLaMA 2 引入了音频分支,并采用了 BEATs 音频编码器,能够提取更精细的音频特征和时间动态信息。音频分支与视觉分支协同工作,帮助模型更全面地理解视频内容。
-
多模态融合: VideoLLaMA 2 使用了 Mistral-Instruct 或 Mixtral-Instruct 作为语言解码器,将视觉和音频信息进行整合,并生成文本响应,从而提升模型对视频的理解和表达能力。

性能表现
VideoLLaMA 2 在多个视频理解和音频理解任务中展现出优异的性能:
-
视频理解: 在多项视频理解任务中,VideoLLaMA 2 取得了领先的成绩,例如在 EgoSchema、Perception-Test 和 MV-Bench 等多选视频问答(MC-VQA)基准测试中,VideoLLaMA 2-7B 的准确率分别达到了 51.7%、51.4% 和 53.9%,超越了同类开源模型。在视频字幕 (VC) 任务中,VideoLLaMA 2 在 MSVC 基准测试中取得了 2.57 的信息准确性和 2.61 的细节描述评分,也优于其他开源模型。
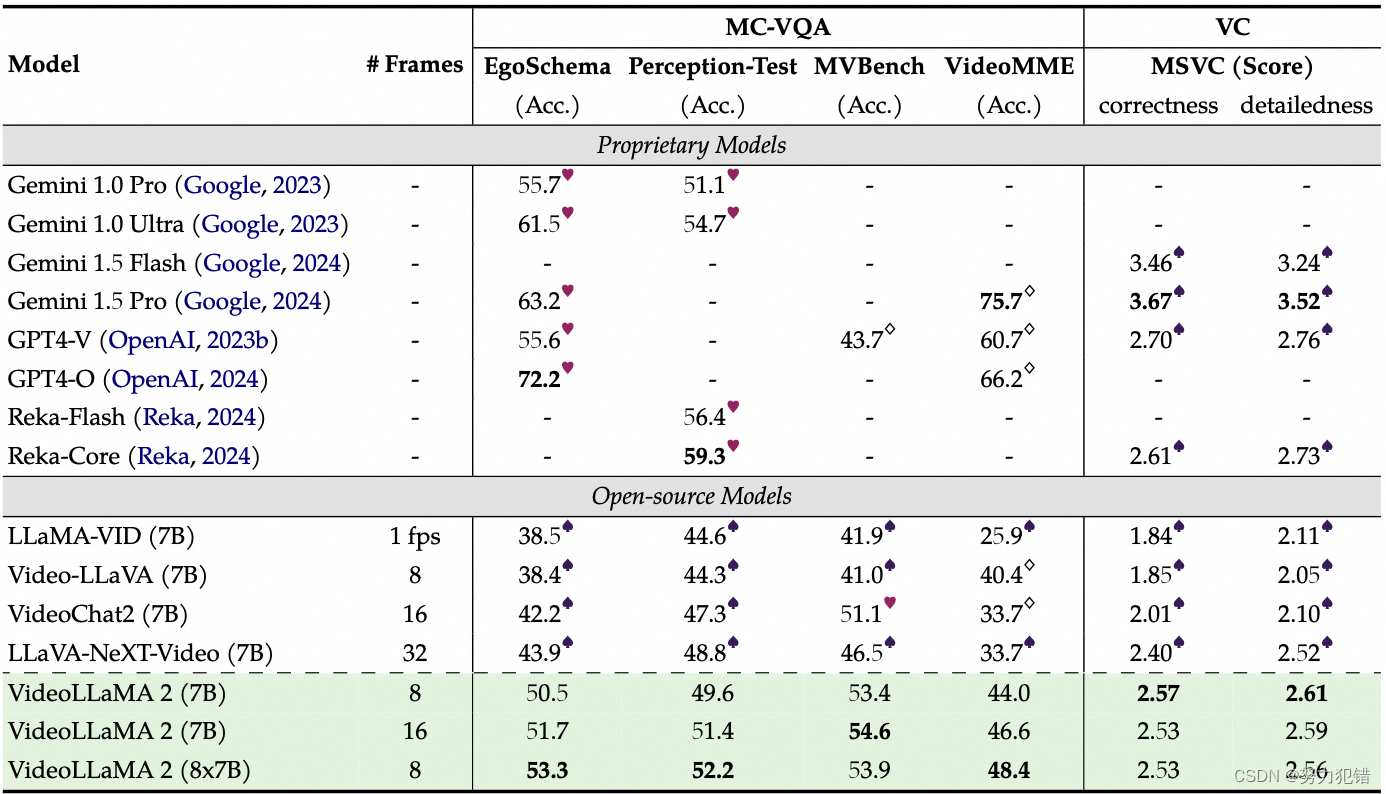
-
音频理解: 在音频理解任务中,VideoLLaMA 2-7B 在 Clotho-AQA 和 TUT2017 等开放式音频问答(AQA)基准测试中也表现优异,在较小的训练数据量下,超过了 Qwen-Audio-7B 模型。
-
音频-视频理解: 在多个音频-视频理解任务中,VideoLLaMA 2-7B 也展现出明显的优势,例如在 MUSIC-QA、AVSD 和 AVSSD 等开放式音频-视频问答(OE-AVQA)基准测试中,其表现优于其他同类模型,体现出 VideoLLaMA 2 对多模态内容的理解和综合能力。
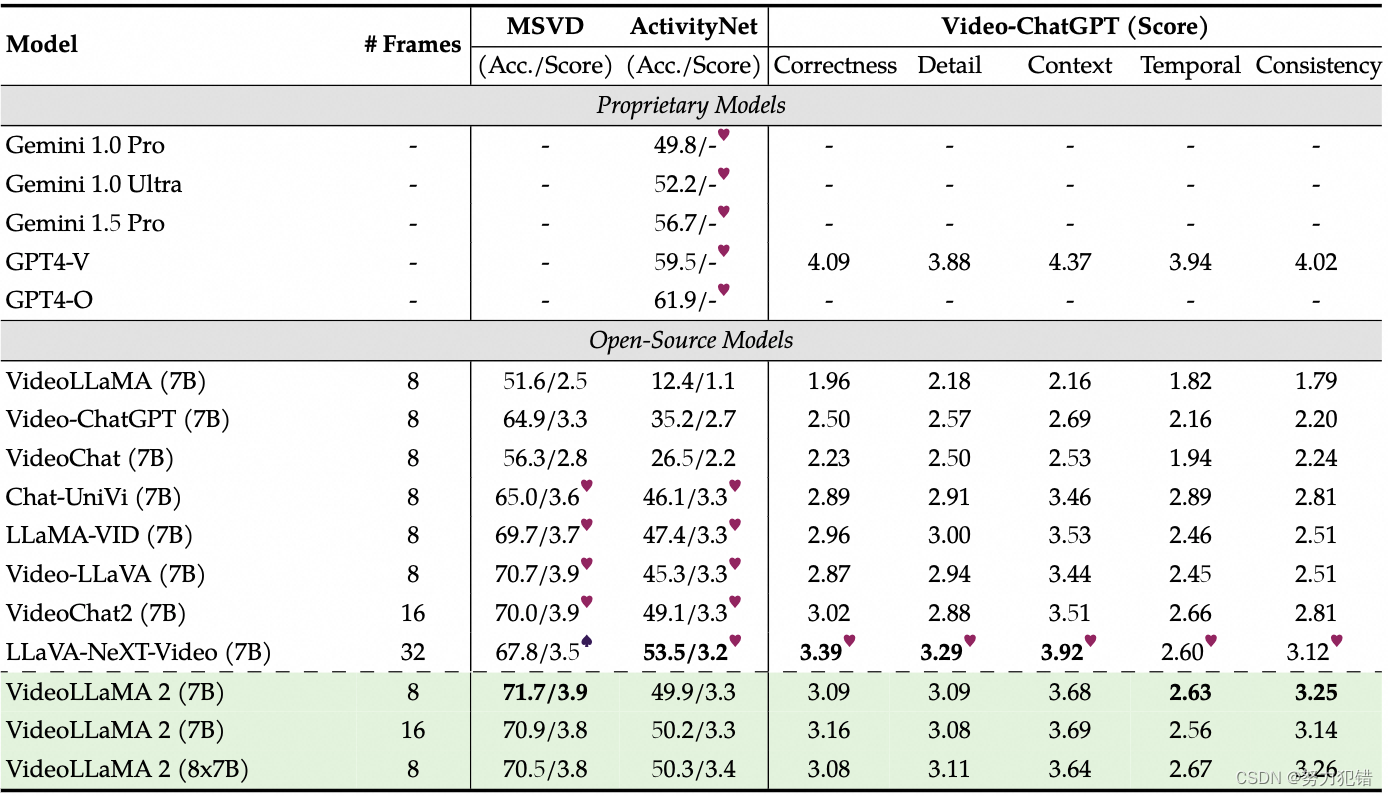
应用场景
VideoLLaMA 2 的强大性能和开源特性,使其在视频分析、理解和生成等领域拥有广泛的应用场景:
-
智能视频分析: VideoLLaMA 2 可以帮助分析视频内容,例如提取关键信息、识别场景、理解事件等,并生成相应的文本描述或回答用户的问题。
-
视频字幕生成: VideoLLaMA 2 可以自动生成视频字幕,为视频内容提供更便捷的访问方式。
-
视频推荐: VideoLLaMA 2 可以根据用户的兴趣和需求,推荐相关的视频内容。
-
视频搜索: VideoLLaMA 2 可以根据用户的文本描述,检索相关的视频内容。
-
虚拟助手: VideoLLaMA 2 可以应用于虚拟助手,帮助用户理解视频内容,并提供相应的帮助。
总结
VideoLLaMA 2 的发布,是视频大模型发展的重要里程碑。它不仅提升了视频理解和音频理解能力,更重要的是,它为开发者提供了更多可能性,推动了视频分析和理解技术的发展,并为智能视频分析系统设立了新的标准。
模型下载
Huggingface模型下载
https://huggingface.co/DAMO-NLP-SG/VideoLLaMA2-7B
AI快站模型免费加速下载
https://aifasthub.com/models/DAMO-NLP-SG

