
- 12024年最新基于STM32的OV7670摄像头总结_ov7670 dma,看这篇文章就行了
- 2机器人操作实验——抓取及路径实现_机器人抓取实验配置
- 3成为一个优秀的测试工程师需要具备哪些知识和经验?_测试人员需要掌握哪些知识
- 4Vue3-elelment-admin 中 Git提交出现问题_vue3用git提交报错
- 590%国际3A游戏发行商的首选,一文揭秘语音驱动面部动画生成技术!_网易数智
- 6DCMM五个等级,怎么计算出来的?看完你就懂了_dcmm评分标准
- 7分享一个基于Node.js和Vue的农产品销售与交流平台(源码、调试、LW、开题、PPT)
- 8python网络爬虫开发从入门到精通下载_Python网络爬虫开发从入门到精通
- 9Docker_可信镜像中心
- 10【口令爆破】SNETCracker 超级弱口令检查工具 (渗透测试、爆破必备神器!)
腾讯:一种为大规模推荐系统多任务融合量身定制的强化学习算法, 已全量上线...
赞
踩
省时查报告-专业、及时、全面的行研报告库
省时查方案-专业、及时、全面的营销策划方案库
【免费下载】2024年3月份热门报告合集
推荐技术在vivo互联网商业化业务中的实践.pdf
推荐系统基本问题及系统优化路径.pdf
大规模推荐类深度学习系统的设计实践.pdf
荣耀推荐算法架构演进实践.pdf
推荐系统在腾讯游戏中的应用实践.pdf
微信视频号实时推荐技术架构分享
推荐系统的变与不变
作者:刘鹏
单位:腾讯
TLDR: 针对已有研究存在的约束过强、模型不与真实环境交互以及探索效率低等问题,本文提出了一种将强化学习与探索策略融为一体的多任务融合方案IntegratedRL-MTF。该方法通过对过强的约束进行简化和放松,显著提升了模型性能,已经全量上线。

论文:arxiv.org/pdf/2404.17589
0. 摘要
为了最大化一个推荐会话中的累积收益,强化学习被用于多任务融合建模。但是,已有的相关研究存在: 1) 为避免分布外问题,模型的约束过强,严重影响了性能;2) 探索和训练是两个独立的过程,并且模型不与真实环境交互;3) 业界常用探索策略低效并且损害用户体验等问题。针对上述问题,本文提出了一种称为IntegratedRL-MTF的解决方案。IntegratedRL-MTF通过将RL模型和我们设计的探索策略融为一体,对过强的约束进行简化和放松,显著提升了模型性能。此外,我们设计的探索策略极为高效,能够更快的对预定高价值空间进行充分探索。最后,在高效探索策略的基础上,我们采用渐进式训练模式,通过多次线上探索和离线训练进一步增强模型性能。离线和线上实验表明,IntegratedRL-MTF与已有方案相比,取得了显著的提升效果。其中,在我们场景,IntegratedRL-MTF将人均有效消费指标提升了+4.84%,人均时长指标提升了+1.74%。当前,IntegratedRL-MTF已经被部署于多个腾讯的大规模推荐系统并且取得了显著收益。
1. 研究动机
当前,推荐系统(Recommender System, RS)在短视频、电商和社交等平台被广泛应用。在RS中,多任务融合(Multi-Task Fusion, MTF)负责将多任务学习模型(Multi-Task Learning, MTL)生成的多个预估分融合为一个最终分,决定了推荐效果。到目前为止,MTF经历了4个发展阶段,包括网格搜参、贝叶斯搜参、进化策略(Evolution Strategy, ES)和强化学习(Reinforcement Learning, RL)。其中,网格搜参和贝叶斯搜参为不同用户生成相同的融合权重,忽略了个性化并且效率较低,已经很少在大规模RS中应用。ES通过将用户特征作为模型输入,输出个性化的融合权重。但是,ES由于模型训练模式只能支持较小的参数量级,限制了模型性能。此外,上述MTF方案只能对本次推荐的奖励建模,忽略了长程收益。
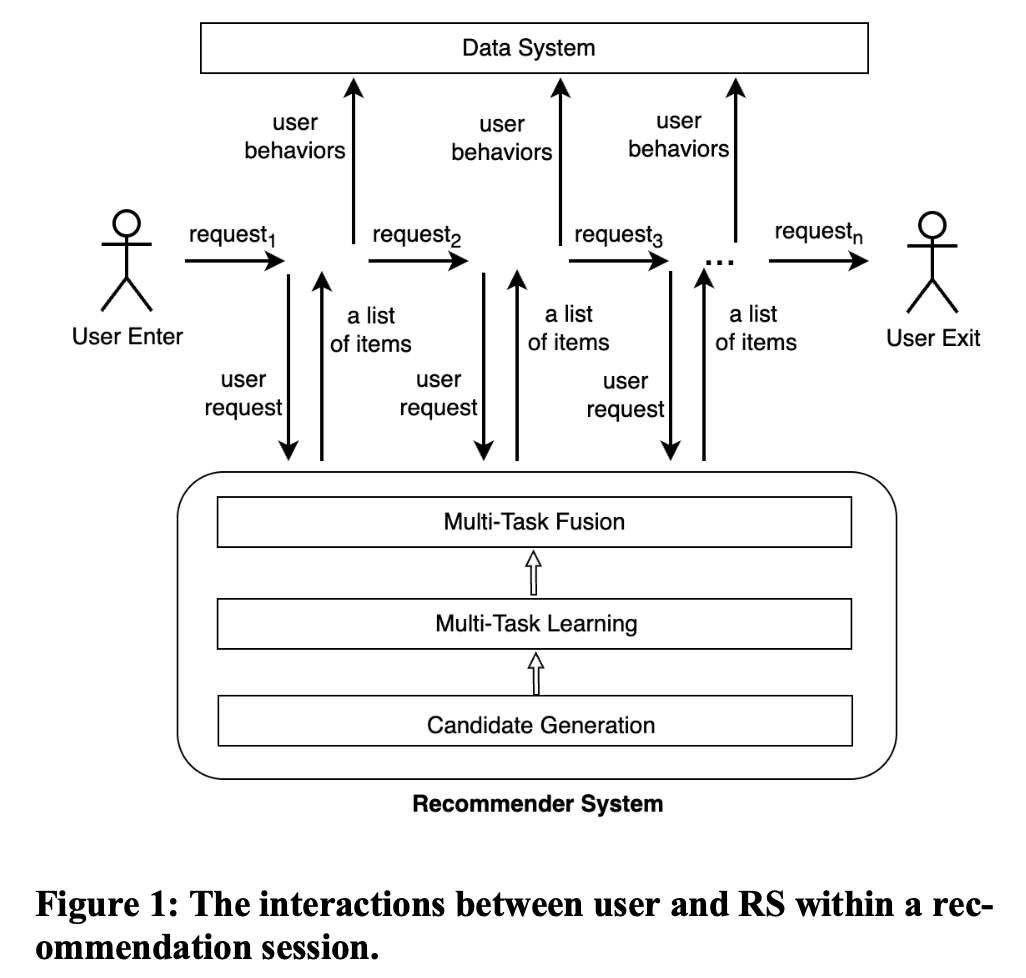
在RS中,本次推荐对后续推荐有明显影响,特别是在一个推荐会话中。一个推荐会话被定义为从用户开始访问RS到离开的整个过程,包括一个或多个连续的请求,如图1所示。因此,为了最大化一个推荐会话中的累积收益,业界近年来将RL用于MTF建模。与ES相比,RL具有支持对长程收益建模、模型能力更强和样本利用率高等优点。但是,已有的off-policy RL-MTF存在以下几个严重问题:
为避免分布外 (Out-of-distribution, OOD) 问题,RL算法的约束过强,严重影响了模型性能。
线上探索和离线训练是两个独立的过程,RL模型不知道线上探索策略并且不再与真实环境(用户)交互。
已有的线上探索策略效率不高,并且过度的探索行为伤害了用户体验。
因此,为解决上述问题,我们针对大规模RS中MTF的特点,提出了一种量身定制的RL-MTF解决方案。(备注:以下介绍较为简单,如有兴趣,请参考原文)
2. 解决方案:IntegratedRL-MTF
2.1 问题定义
我们将RS中多任务融合问题,建模为在一个推荐会话中的马尔可夫决策过程(Markov Decision Process, MDP)。在一个MDP过程中,RS (agent) 与用户 (environment)持续交互,并且依次做出推荐决策,以最大化整个会话中的累积收益,如图1所示。
2.2 奖励函数定义
为了评估本次推荐的收益,我们根据用户的多种反馈行为进行评估,定义如公式2所示。
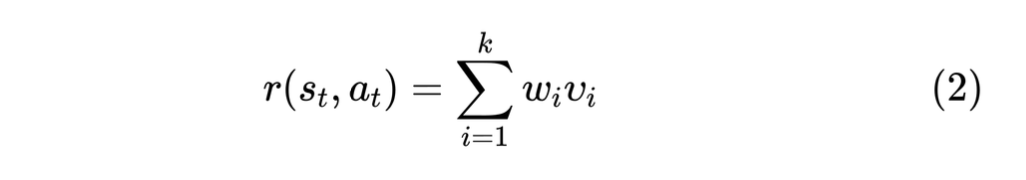
2.3 探索策略
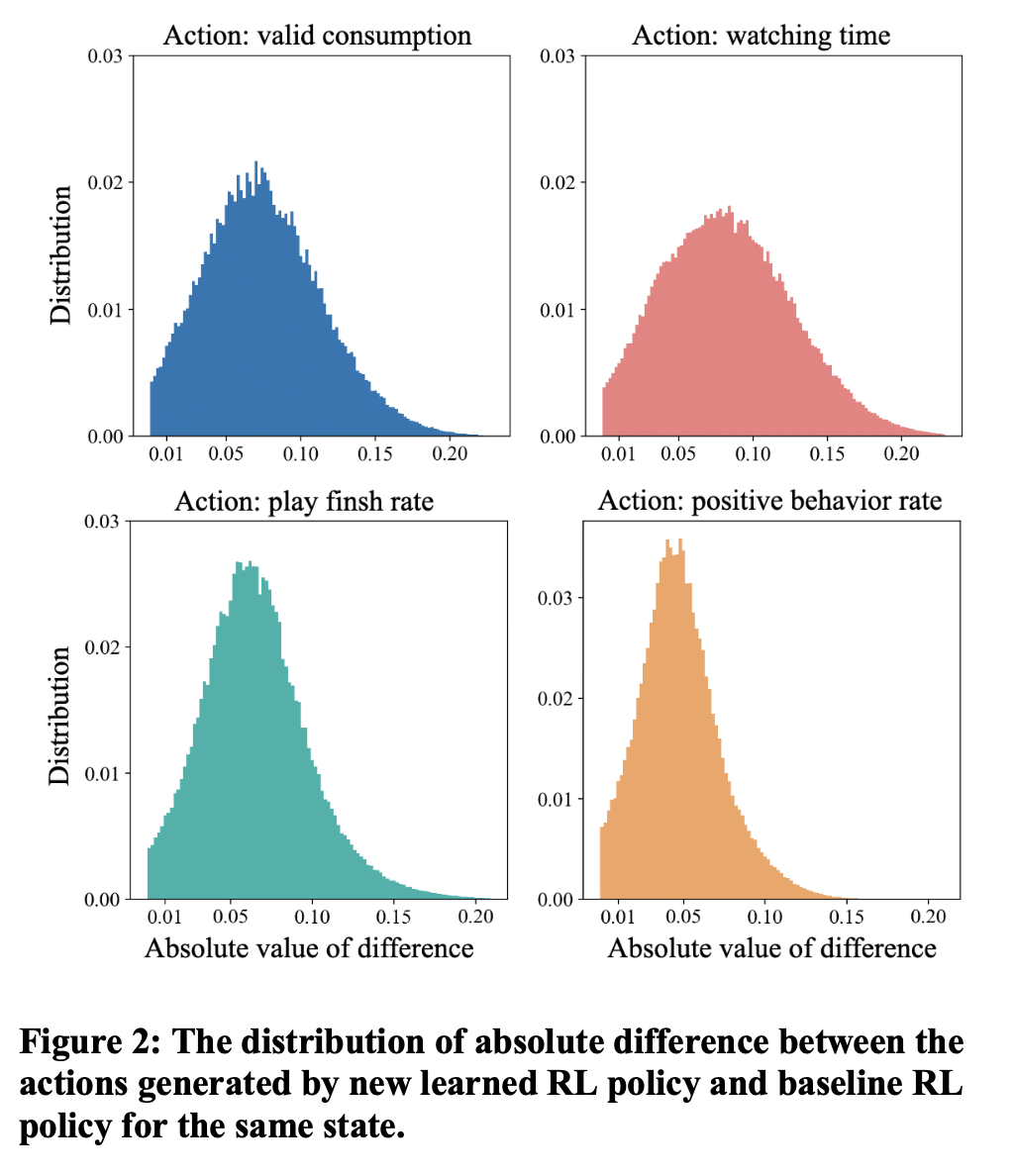
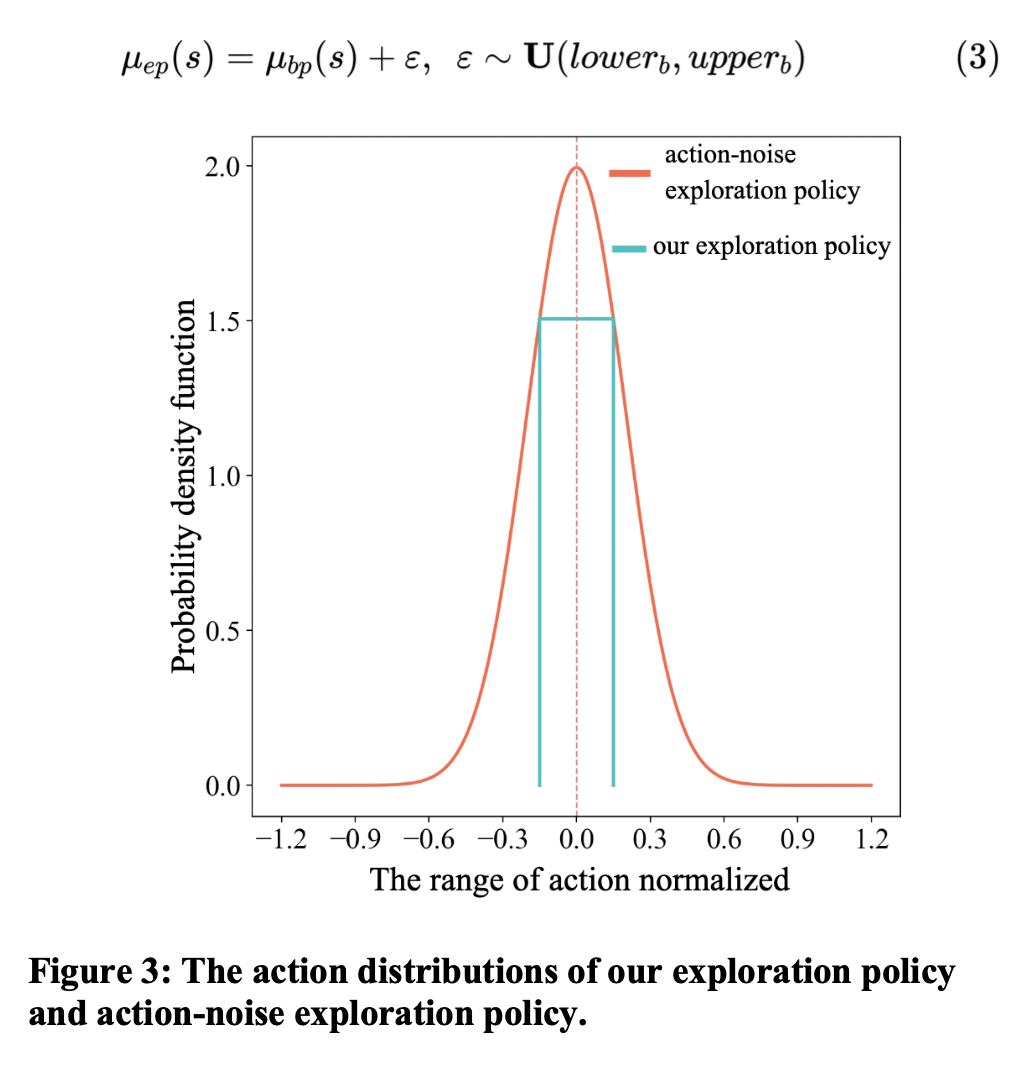
我们通过对多次RL迭代中,base policy与target policy在同一state下action的分布进行分析发现,target policy通常不会明显偏离base policy,这也与我们的直觉相符,如图2所示。因此,我们设计了一种基于上界和下界的个性化探索策略,重点对高价值的空间进行探索,舍弃低价值的空间,以有效提升探索效率,如公式3所示。探索策略的上下界基于之前数据的统计分析和本次需求进行设定。在相同的探索密度要求下,与我们之前使用的基于高斯扰动的探索策略相比,基于上下界的个性化探索策略可以实现倍以上的探索效率提升,如图3所示。此外,我们采用的渐进式训练模式,包括多轮线上探索和离线训练,也增大了探索策略的探索空间。
2.4 Actor
Actor通过将模型与探索策略融为一体,在模型训练时,可以直接得到个性化探索数据分布的上界和下界,从而可以放松过强的约束,显著提升模型性能。此外,为了缓解可能存在的探索不均衡问题,增加了一个基于ensumble critics的一致性惩罚项。由于我们设计的探索策略与传统探索策略相比,具有极高的探索效率,因此,这个惩罚项可以使用很小的权重甚至忽略。

2.5 Critic
我们定义了多个critic,分别进行独立的随机初始化和训练。Critic模型也融合了探索策略,训练如公式6所示。此外,为了进一步提升效果,我们为每个critic定义了一个target critic。
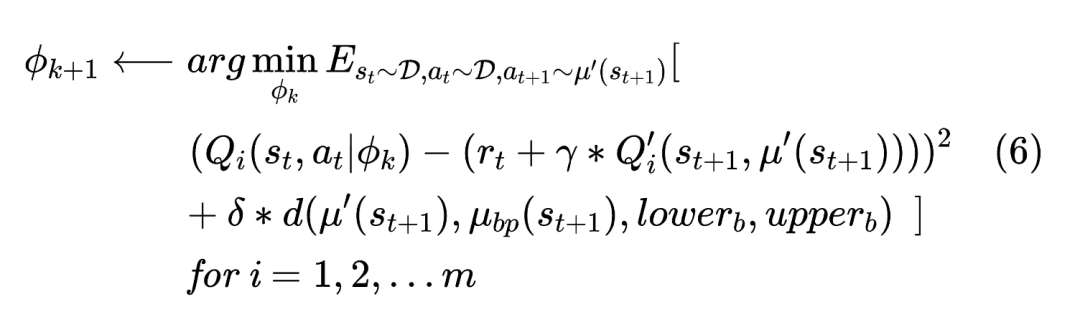
2.6 渐进式训练模式(Progressive Training Mode, PTM)
Off-policy RL的一个严重缺陷是线上探索和模型训练是两个独立的过程。在模型训练时仅依赖之前收集的数据,不再与环境交互。这对Off-policy RL模型的训练效果有严重影响。因此,为了缓解这个问题,我们基于高效的探索策略,采用了渐进式训练模式,通过多轮线上探索和离线训练的迭代,使target policy快速收敛到真实的optimal policy。
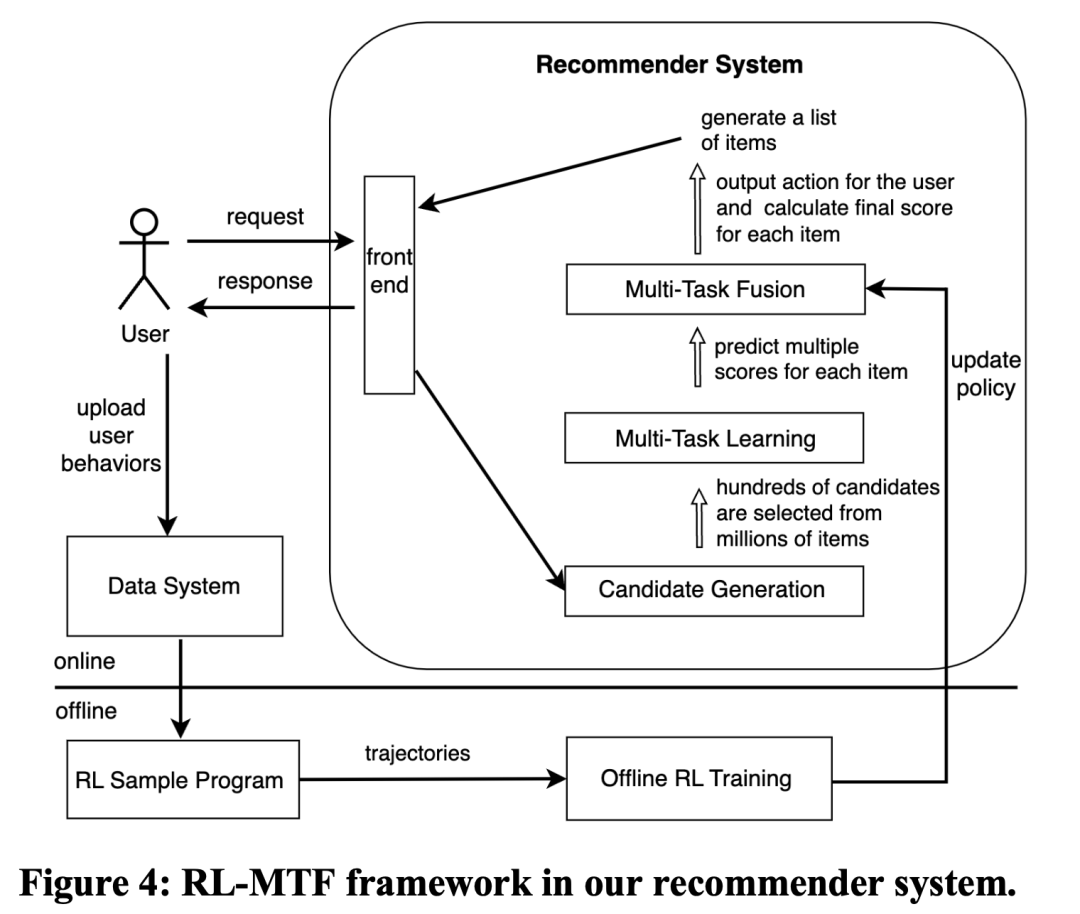
2.7 RL-MTF的实现与部署
RL-MTF在我们推荐系统的实现与部署,如图4所示。
3. 实验部分
3.1 离线实验
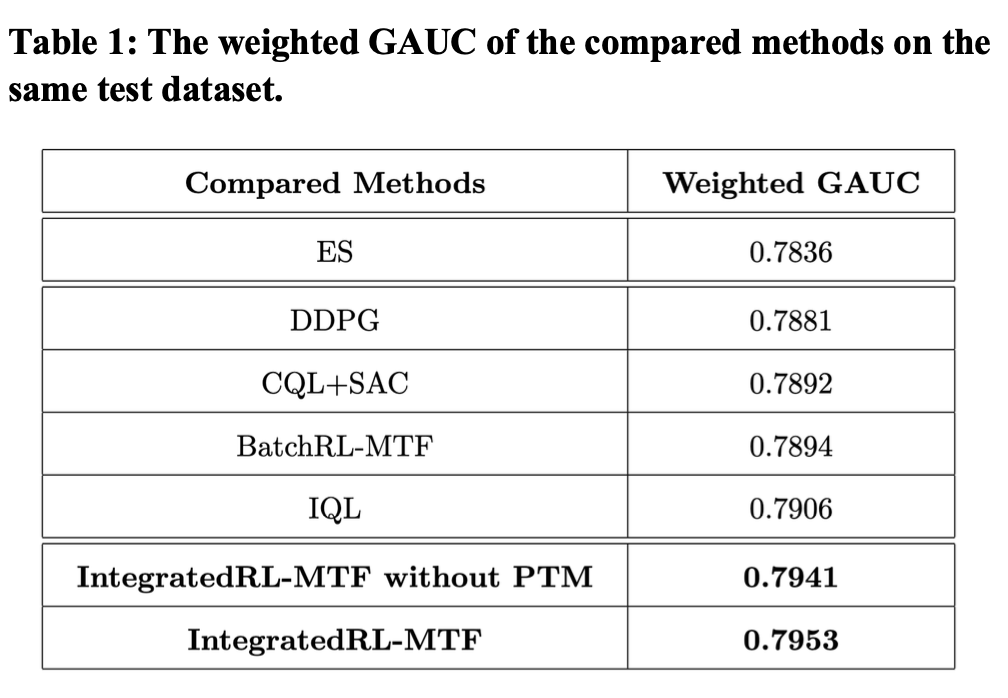
我们的方案与业界相关方案进行了离线对比。与业界常用的评估方法不同,我们提出了一种用于评估最终分排序效果的指标weighted GAUC,更为简单和有效。各方案的离线指标,如表1所示。通过离线指标可以发现我们的方案显著优于已有相关方案。
3.2 线上实验
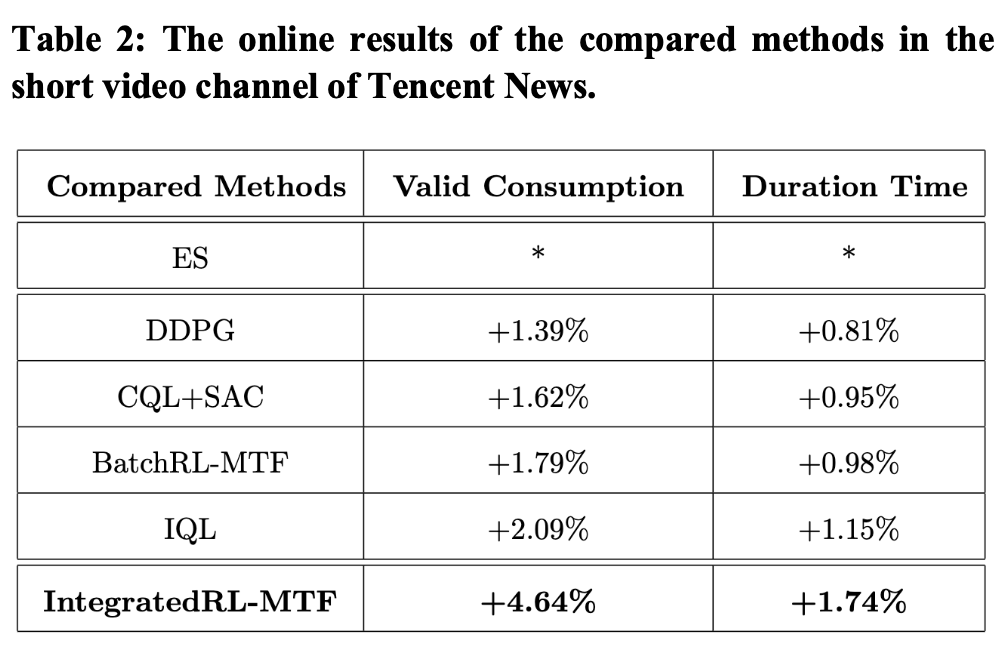
我们将不同模型部署到推荐系统中,进行线上A/B实验,结果如表2所示。线上实验结果表明,我们模型将有效消费指标提升:+4.64%,人均时长指标提升:+1.74%,显著高于已有各方案。
4. 总结
本文指出了已有RL-MTF相关研究存在的问题,并且提出了一种新的解决方案IntegratedRL-MTF。我们方案的创新之处在于针对RS的特点将off-policy RL与探索策略融为一体,在模型训练时可以直接获取探索分布的上下界,从而显著提升了模型能力。针对已有探索策略存在的低效和损伤用户体验问题,我们设计了一种极为高效的探索策略。此外,针对off-policy RL训练仅依赖之前收集数据的问题,我们提出了渐进式训练模式,通过多次线上探索和离线训练进一步增强了模型性能。离线和线上实验表明,我们的方案与业界相关方案相比,取得了显著提升。当前,我们的方案已经全量部署于多个腾讯的大规模推荐系统。我们欢迎与业界专业人员交流和探讨RL-MTF相关研究。
「 更多干货,更多收获 」

【免费下载】2024年3月份热门报告合集
ChatGPT的发展历程、原理、技术架构及未来方向
《ChatGPT:真格基金分享.pdf》
2023年AIGC发展趋势报告:人工智能的下一时代
推荐系统在腾讯游戏中的应用实践.pdf
推荐技术在vivo互联网商业化业务中的实践.pdf
2023年,如何科学制定年度规划?
《底层逻辑》高清配图
推荐技术在vivo互联网商业化业务中的实践.pdf
推荐系统基本问题及系统优化路径.pdf
荣耀推荐算法架构演进实践.pdf
大规模推荐类深度学习系统的设计实践.pdf
某视频APP推荐策略详细拆解(万字长文)关注我们
智能推荐 个性化推荐技术与产品社区 | 长按并识别关注
|

一个「在看」,一段时光
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

