
- 1为什么程序员一定要学深度学习?_工作了需要学习深度学习吗
- 2STM32+AD7124+热电偶方案+Pt100冷端补偿解析工程源码,源码包含Pt100、NTC热敏、热电?_pt100冷端补偿电路
- 3【Rust 日报】2021-09-12 Rust 的 Logging 推荐
- 4深度 Qlearning:在智能城市构建中的应用
- 5python解释器的作用是什么_什么是python解释器
- 6成分—靶点网络构建_成分靶点网络图
- 7java二级缓存作用域_SpringBoot+Mybatis一级缓存和二级缓存详解
- 8主题模型分析_主题分析
- 9深入浅出Spark:流处理与机器学习
- 10APACHE安装与应用_apache的使用
LLM大模型技术实战5:一文总结Prompt提示工程策略与技巧
赞
踩
提示工程是一门新兴学科,就像是为大语言模型(LLM)设计的"语言游戏"。通过这个"游戏",我们可以更有效地引导 LLM 来处理问题。只有熟悉了这个游戏的规则,我们才能更清楚地认识到 LLM 的能力和局限。
这个"游戏"不仅帮助我们理解 LLM,它也是提升 LLM 能力的途径。有效的提示工程可以提高大语言模型处理复杂问题的能力(比如一些数学推理问题),也可以提高大语言模型的扩展性(比如可以结合专业领域的知识和外部工具,来提升 LLM 的能力)。
提示工程就像是一把钥匙,为我们理解和应用大语言模型打开了新的大门,无论是现在还是未来,它的潜力都是无穷无尽的。
一、六大提高Prompt有效性的策略
这些技巧旨在提供思路,绝非面面俱到,您应随意尝试这里未涉及的创造性思路。
策略一:清晰地表达指令
技巧:在查询中包含更多细节以获取更相关的回答
为了获得高度相关的回复,查询需要提供任何重要的细节或上下文信息,否则就要由模型猜测您的意图。
| 劣质 | 优质 |
|---|---|
| Excel 中如何相加数字? |
|
在 Excel 中如何对一行金额自动相加?我想对整个工作表的行进行求和,总和显示在右边一列"总计"中。
|
|
谁是总统?
|
2021年墨西哥总统是谁,选举频率是多久一次?
|
|
编写代码计算斐波那契数列。
|
用 TypeScript 编写一个函数来有效地计算斐波那契数列。对代码添加详细注释以解释每个部分的作用及编写方式。
|
|
摘要会议记录。
|
用一段话摘要会议记录。然后用 markdown 列表罗列发言人及每个人的要点。最后,列出会议记录中发言者提出的后续步骤或行动事项(若有)。
|
技巧:要求模型采用特定的角色
系统消息可用于指定模型在回复时采用的角色。
技巧:使用分隔符清楚地指示输入的不同部分
三引号、XML标签、标题等分隔符可以帮助标记需不同对待的文本片段。
对于简单的任务,使用分隔符可能不会影响输出质量。然而,任务越复杂,明确任务细节就越重要。不要让 GPT 模型费劲理解您到底在要求什么。
技巧:指定完成任务所需的步骤
有些任务最好用一系列步骤来表达。明确写出步骤可以让模型更容易遵循。
技巧:提供示例
在所有示例上演示任务的各种变化通常比仅给出说明更高效,但在某些情况下提供示例可能更简单。例如,如果您希望模型模仿回复用户查询的特定风格,而这种风格难以明确表达。这被称为 “few-shot” 提示。
技巧:指定期望的输出长度
您可以要求模型生成特定目标长度的输出。目标输出长度可以以单词数、句子数、段落数、项目符号数等来指定。但是,指示模型生成特定数量的单词不能高精度实现。模型可以更可靠地生成特定段落数或项目符号数的输出。
策略二: 提供参考文本
技巧:指示模型使用提供的参考文本进行回答
如果我们能为模型提供与当前查询相关的可信信息,那么我们可以指示模型使用提供的信息来组成其回答。
鉴于 GPT 模型具有有限的上下文窗口,为了应用此技巧,我们需要某种方法根据问题动态查找相关信息并添加到模型输入中。嵌入可用于实现高效的知识检索。请参阅技巧“使用基于嵌入的搜索实现高效知识检索”以获取更多详细信息。
技巧:指示模型使用参考文本中的引文进行回答
如果输入补充了相关知识,则可以轻松要求模型在答案中添加引文,引用提供文档的相关段落。输出中的引文然后可以通过与提供文档的字符串匹配来程序化验证。
策略三:将复杂任务分解为更简单的子任务
技巧:使用意图分类识别与用户查询最相关的指令
对于需要大量独立指令集来处理不同情况的任务,首先对查询进行分类以确定所需指令会很有益。这可以通过定义固定类别并针对每个类别硬编码相关指令来实现。该过程也可以递归应用以将任务分解成一系列阶段。这种方法的优点是每个查询只包含执行任务下一阶段所需的指令,这可以与使用单个查询执行整个任务相比降低错误率。这也可以降低成本,因为更大的提示需要更高的运行成本(查看价格信息)。
例如,对于客户服务应用,查询可以划分为以下类别:
根据客户查询的分类,可以为 GPT 模型提供更具体的指令来处理后续步骤。例如,假设客户需要“故障排除”的帮助。
注意,模型被指示在对话状态发生变化时输出特殊字符串。这使我们可以将系统转化为状态机,其中状态确定注入哪些指令。通过跟踪状态、该状态下相关的指令,以及从该状态允许的状态转移,我们可以为用户体验设置更难以用不太结构化的方法实现的约束。
技巧:对需要非常长对话的对话应用,汇总或过滤之前的对话
由于 GPT 模型具有固定的上下文长度,因此将整个对话包含在上下文窗口内的用户与助手之间的对话无法无限期地继续。
这一问题有多种解决方法,一种是在输入大小达到预定阈值长度时,使用一个查询来总结对话的一部分,并将之前对话的摘要包含在系统消息中。或者,可以在整个对话的过程中异步地在后台总结之前的对话。
另一种解决方案是动态选择与当前查询最相关的之前对话部分。请参阅技巧“使用基于嵌入的搜索实现高效知识检索”。
技巧:分段摘要长文档,递归构建完整摘要
由于 GPT 模型具有固定的上下文长度,它们无法在单个查询中概括比上下文长度减去生成摘要长度还要长的文本。
要摘要像书籍这样的非常长文档,我们可以使用一系列查询逐部分摘要文档。部分摘要可以连接在一起生成摘要的摘要。该过程可以递归进行,直到整个文档被摘要。如果为了理解后面部分需要使用前面部分的信息,则可以在摘要某点内容时,将该点之前文本的运行摘要也包括在内,这一技巧也很有用。OpenAI 之前的研究已经研究了使用 GPT-3 变体递归摘要书籍的效果。
策略四:给予GPT“思考”的时间
技巧:指示模型在匆忙得出结论之前自己推导出解决方案
有时候明确地让模型先自行推理出答案再回复用户,可以获得更好的效果。
例如,我们想让模型评判一个学生对数学问题的解答。最直接的方法是简单地询问模型该解答是否正确。
但如果我们首先让模型自己解出题目并生成答案,再让其比较学生的答案,就更容易发现问题:
`SYSTEM: 首先自己解出这道题并生成答案。然后再比较你的答案和学生的答案,判断学生的答案是否正确。在比较之前,不要依赖学生的答案来决定其是否正确。 USER: <插入题目> <插入学生答案> ASSISTANT: <模型先生成自己的答案> <模型比较两个答案并作出评价>`
- 1
- 2
- 3
- 4
- 5
技巧:使用内心独白或一系列查询来隐藏模型的推理过程
有时候我们不想让用户看到模型的全部推理过程,只需要展示最后的回复。
这时可以使用"内心独白"把需要隐藏的部分放入特定格式中,在展示给用户前把这些部分删除。
或者,可以进行一系列查询,其中只有最后一个查询的输出会展示给用户。
`#隐藏查询1: 仅提供问题描述,让模型解出答案 #隐藏查询2: 提供问题描述、模型解答和学生解答,让模型判断学生解答的正确性 #可见查询: 假设模型是一个有帮助的导师,如果学生错误,给出提示;如果正确,给予鼓励`
- 1
- 2
- 3
- 4
- 5
技巧:在前几轮后询问模型是否遗漏了相关信息
当我们要求模型列举某文本中的所有相关摘录时,模型常会过早停止而未罗列全部。
这时可以在前几轮查询后,再询问模型是否还遗漏了相关内容,以获取更完整的结果。
策略五:使用外部工具
技巧:使用基于嵌入的搜索实现高效的知识检索
我们可以在模型的输入中加入相关的外部信息,帮助其生成更准确的回复。
例如,如果用户询问一个具体的电影,将该电影的高质量信息(演员、导演等)也加入输入中会很有用。
通过使用文本嵌入可以实现高效的知识检索,从而动态地在运行时将相关信息加入模型输入中。
技巧:使用代码执行进行更精确的计算或调用外部 API
GPT 模型自己进行算术运算或长时间计算时误差很大。这时可以让其编写代码进行运算并运行。
代码执行也可以用来调用外部 API。如果事先教会模型如何使用某 API,它可以编写调用该 API 的代码。
需要注意,运行模型生成的代码有安全风险,需要采取防护措施。
技巧:系统地测试各种改变
有时候很难判断某项改变是否提升了系统性能。仅观察几个例子来判断是不可靠的。
适当的评估流程对优化系统设计非常有用。好的评估应该具有代表性、包含足够多的测试用例。
评估可以由计算机、人工或两者混合来进行。计算机可以自动进行客观的评估。OpenAI Evals 提供了用于构建自动评估的开源工具。
当存在多种可被认为同等优质的输出时,使用模型进行评估也可行。我们鼓励针对不同使用案例进行试验,衡量模型评估的可行性。
技巧:参照标准答案来评估模型输出
如果问题的正确答案需要包含某些已知的事实,我们可以用模型查询来统计答案中包含了多少需要的事实。
例如:
`SYSTEM: 检查提交的答案是否直接包含下列信息: - Neil Armstrong 是第一个登月的人 - Neil Armstrong 首次登月的日期是 1969年7月21日 对于每个要点: 1 - 重述要点 2 - 提供与要点最相关的答案摘录 3 - 分析仅看摘录的人是否可以推断出该要点,解释你的推理过程 4 - 如果答案是肯定的,写 "yes",否则写 "no" 最后,统计"yes"的个数,用以下格式提供: {"count": <yes的个数>}`
- 1
- 2
- 3
- 4
- 5
如果答案满足所有要点,count 将为要点的总数。如果仅满足部分要点,count 将小于要点总数。
这样可以构建不同的模型评估变体来统计答案与标准答案的重合情况,以及是否存在矛盾。
策略六:系统地测试更改
有时候很难分辨出某项更改(如新指令或设计)是否提升了系统性能。查看几个例子可能会提示哪种方法更好,但样本量太小时,难以区分真正的改进与随机幸运。也许某项更改对某些输入有益,但对其他输入有害。
评估程序(或“测评”)对优化系统设计很有用。好的测评应该具有以下特点:
-
代表真实使用情况(或至少包含多样性)
-
包含大量测试用例以增强统计功效(参见下表)
-
易于自动化或重复
| 需检测的差异 | 需样本量(95%置信度) |
|---|---|
| 30% |
|
~10
|
|
10%
|
~100
|
|
3%
|
~1000
|
|
1%
|
~10000
|
模型输出的评估可以由计算机、人类或两者的组合来完成。计算机可以用客观标准(如只有单一正确答案的问题)自动进行测评,也可以用其他模型查询对一些主观或模糊标准进行测评。OpenAI Evals是一个开源软件框架,提供了创建自动化测评的工具。
对于输出范围广泛且同等高质量的问题(如需要长答案的问题),基于模型的测评可发挥作用。模型测评与需要人工评估的问题界限模糊,随着模型变得越来越强大而不断扩展。我们鼓励您进行试验,了解基于模型的测评对您的用例能发挥多大作用。
技巧:
- 根据参考标准答案评估模型输出
二、提示工程进阶
1、零/少样本提示
Zero-Shot Prompting:在这种情况下,模型接收到的提示没有包含任何特定任务的示例。这意味着模型需要基于给定的提示,而没有任何相关任务的先前示例,来推断出应该执行的任务。例如,如果我们向模型提供提示 “Translate the following English text to French: ‘Hello, how are you?’”,那么模型将要根据这个提示,而没有任何额外的翻译示例,来执行翻译任务。
Few-Shot Prompting:在这种情况下,模型接收到的提示包含了一些(通常是几个)特定任务的示例。这些示例作为上下文,提供了关于期望输出的线索。例如,如果我们想要模型进行文本翻译,我们可能会提供如下的提示:
English: 'Cat'
French: 'Chat'
French: 'Oiseau'
English: 'Elephant'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在这个例子中,模型通过前三个英法翻译对的示例,理解了我们希望它将 ‘Elephant’ 从英文翻译成法文。因此,它会输出 ‘Éléphant’。
2、思维链提示
CoT(Chain-of-Thought)的核心思想是,在Prompt中加入一些示例,来引导LLM展现出更好的推理能力。
这里的关键是在Prompt中加入的示例,在这些示例中,我们会用自然语言描述一系列的推理过程,并最终引导出示例问题的正确结果。
这个过程有点像,我们教小孩做应用题,我们先给小孩子分析讲解一些示例。然后再把新的问题让小孩子来解决。小孩子根据从示例中学习到的推理、分析能力,最终解出了新的问题。
下面我们来看论文中给的CoT的例子:
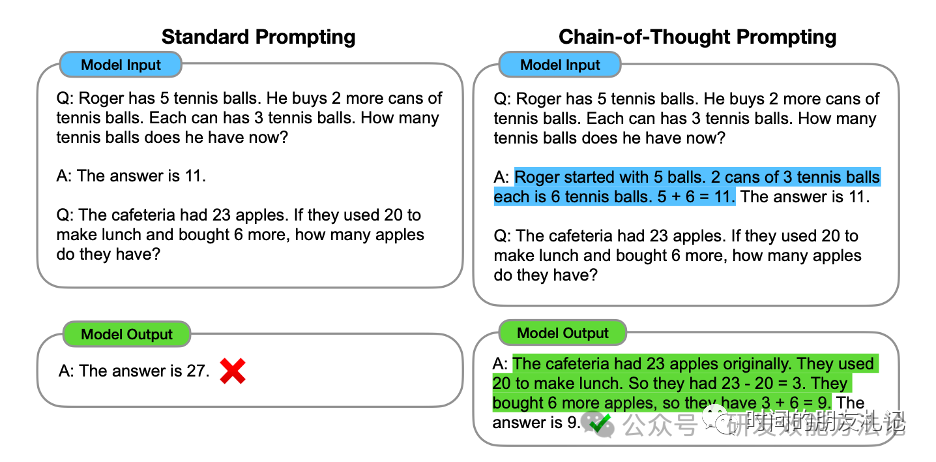
上图中,左侧是常规的Prompt,右侧是CoT Prompt。蓝色标记出的部分是提供给LLM的示例。绿色标记出的部分是LLM输出的推理过程。
在使用CoT这种Prompt Engineering技巧的时候,有几个注意点:
(1)CoT是LLM足够大(参数足够多,通常是在1000亿参数)时才涌现出来的能力。因此,在一些不够大的LLM上,CoT的效果并不明显。
(2)通常,在Prompt中加入的示例不是1条,而是多条。具体要考虑解决的问题类型,以及Prompt的长度(因为LLM的Prompt长度通常都是有长度限制的)。
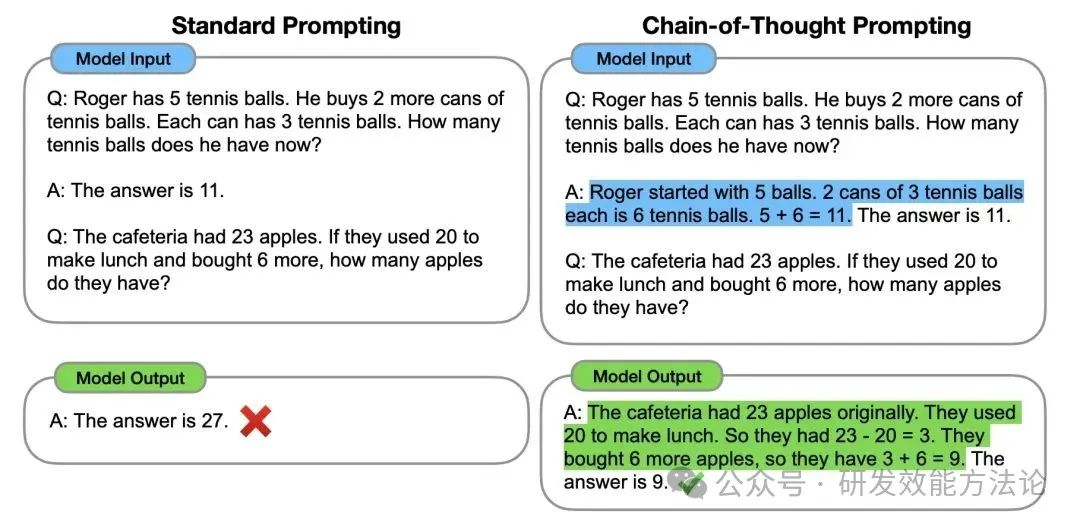
少样本思维链:就是用户提供一些“解题步骤”,比如下图所示,左侧直接让 LLM 回答问题时它给出了错误的答案,但是右侧通过在 prompt 中告诉模型解答步骤,最终给出的答案就是准确的。
零样本思维链:嫌弃提供中间过程太麻烦?偷懒的办法来了,零样本思维链通过一句 magic prompt 实现了这一目标**“Let’s think step by step**

然而过于简化的方法肯定也会存在一定局限性,比如 LLM 可能给出的是错误的思考过程。因此有了自动化思维链,通过采用不同的问题得到一些推理过程让 LLM 参考。它的核心思想分两步
-
首先进行问题聚类,把给定数据集的问题分为几个类型
-
采样参考案例,每个类型问题选择一个代表性问题,然后用零样本思维链来生成推理的中间过程。
3、自一致性技术:Self-Consistency
Self-Consistency技术是在CoT技术的基础之上,进行的进一步优化,目的是为了让LLM的推理能力能够更进一步提升。
Self-Consistency的大致原理是这样:
(1)利用CoT Prompting技巧,写好Prompt;
(2)不要让LLM只生成最合适的唯一一个结果,而是利用LLM结果的多样性,生成多种不同推理路径所得的结果的集合;
(3)从结果集合中投票选择,选出投票最多的结果,做为最终的答案。
这里有像我们人类解决问题的过程,如果我们用多种不同的方法去求解,大多数方法求解出来结果都一样的答案,那很有可能就是我们最终的答案。
下面我们来看论文中给的Self-Consistency的例子:
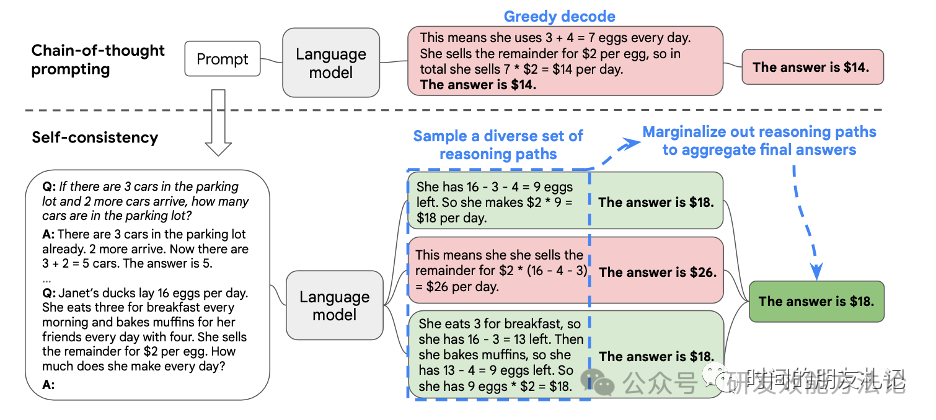
在上面的例子中,虚线之上是标准的CoT的过程,它得到的结果是错的。虚线之下是Self-Consistency的过程,得到的三个答案中,有1个是错的,有2个是正确的。最终答案是大多数投票的结果,是正确的。
4、从易至难技术:Least-to-Most
这是《Least-to-Most Prompting Enables Complex Reasoning in Large Language Models》这篇论文中介绍的方法。
CoT的特点是同类型问题的迁移思考,因此,如果给的例子是比较简单的问题,而给的问题却是难度大很多的问题,这时候CoT的效果就不尽如人意。
LtM(Least-to-Most)主是为了解决CoT这种从易到难的迁移能力不足而诞生的。
LtM的核心思想是:教LLM把复杂问题,拆解成一系列的简单问题,通过解决这一系列的简单问题,来最终得到复杂问题的结果。
LtM的过程包含两个阶段:
(1)分解阶段:把复杂问题分解成一系列的简单子问题。这个阶段的Prompt中要包含分解问题的示例,要和分解的问题;
(2)解决子问题阶段:这个阶段的Prompt中包含三部分内容:一是完整的LtM的例子;二是已解决的子问题及其答案列表;三是接下来要解答的子问题。
这里也非常像我们人类学习解决复杂问题的过程,我们通过把复杂问题拆解成一个个的简单问题,通过把一个个的简单问题解决掉,最终把复杂问题也解决了。
下面我们来看看论文中LtM的例子:
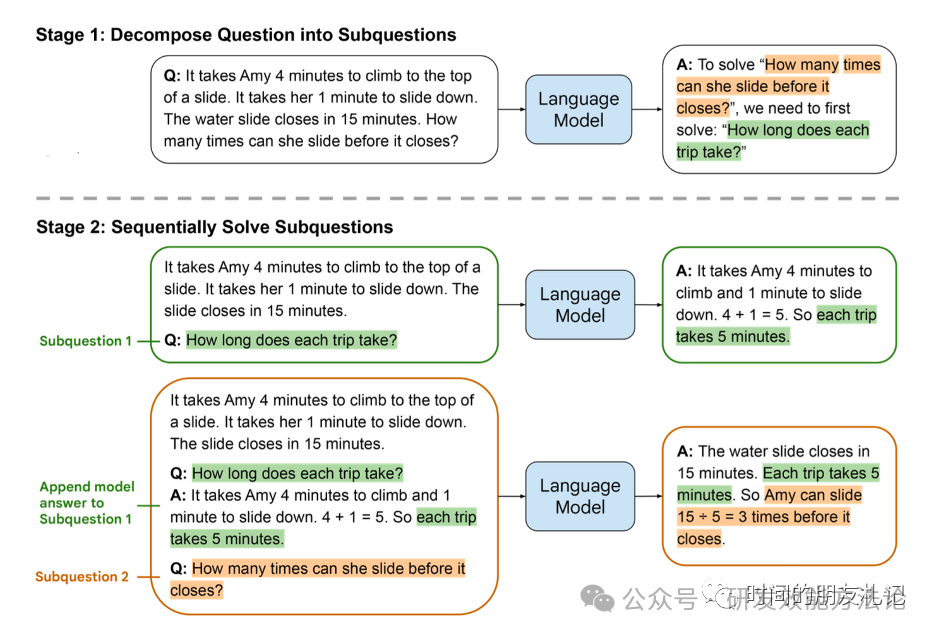
从上图中,我们可以对LtM Prompting有一个直观的认知,通过引导LLM解决子问题,一步步引导LLM得出复杂问题的结果。
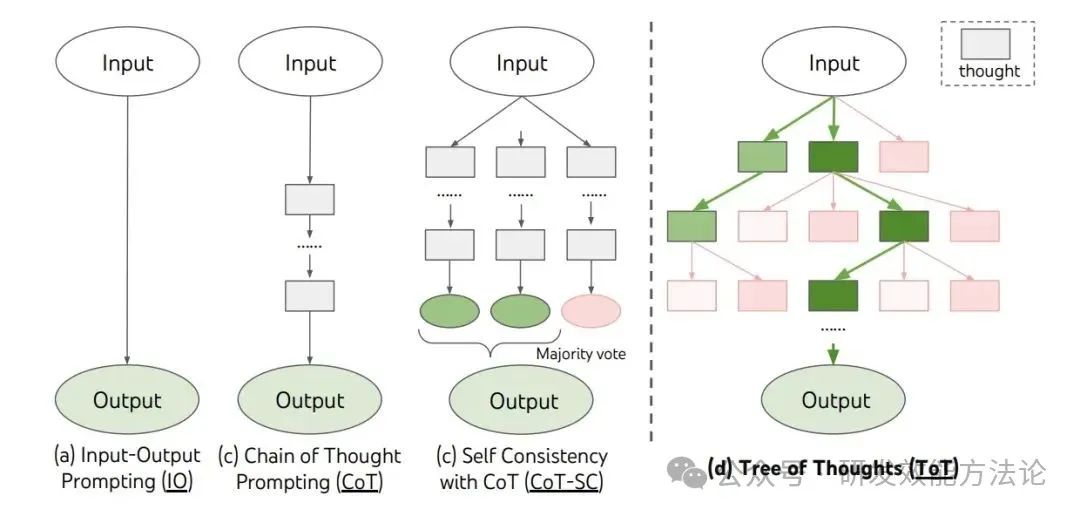
5、思维树
Tree of Thoughts (ToT)是思维链的进一步拓展,主要想解决 LM 推理过程存在如下两个问题:
-
不会探索不同的可能选择分支
-
无法在节点进行前后向的探索
ToT 将问题建模为树状搜索过程,包括四个步骤:问题分解、想法生成,状态评价以及搜索算法的选择。
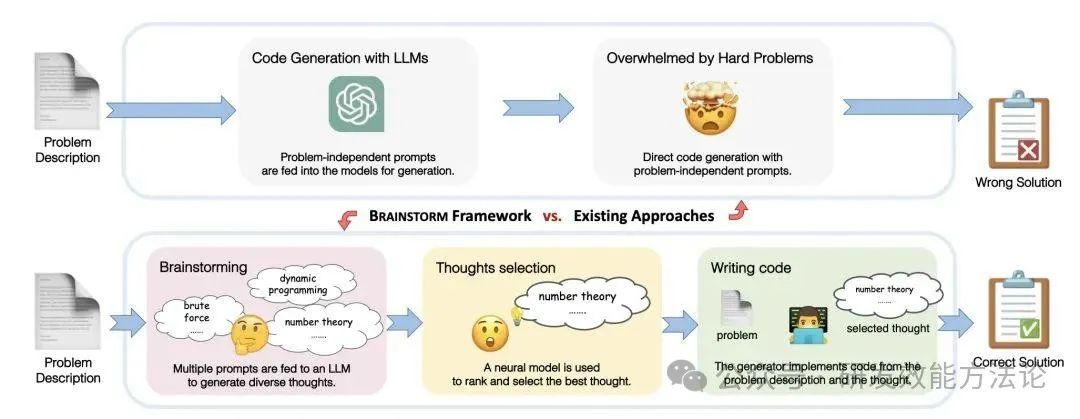
6、头脑风暴提示
主要考虑的是代码生成方向,不过思想还是可以用在各种领域的提问的。核心思想分为三步
-
头脑风暴:通过多个 prompt 喂给 LLM 得到多样化的“思路”
-
选择最佳思路:这里用了一个神经网络模型来打分,并用最高分的思路来作为最终 prompt
-
代码生成:基于问题和选择出来的最佳思路进行代码生成
===
增强 LLM 本质上在做的事情还是提高提示词的信息,从而更好地引导模型。这里主要可以有两种方式,一种是用自己的私有知识库来扩充 LLM 的知识,一种是借用 LLM 的知识库来提高 prompt 的信息量。
7、外部知识库
本地知识库
这里可以结合网上的信息或者个人的本地信息,如果是结合网上的信息(比如 newbing),其实就是需要结合一些爬虫工具,捞出一些相关信息一起拼到 prompt 当中(也会需要比如做一些相关性的比较、摘要等)。结合本地知识库也是目前业界内比较关注的方向,主要有以下几步:
-
将本地知识库转为 embedding 保存
-
对于用户提问转为 embedding,然后去数据库查相关的信息
-
检索出本地知识库相关的信息后,比如可以用如下提示拼接上检索出来的信息
Use the following pieces of context
- 1
- 2
- 3
- 4
- 5
这样 LLM 在回答时就能利用上私有的知识了。
LLM 知识库
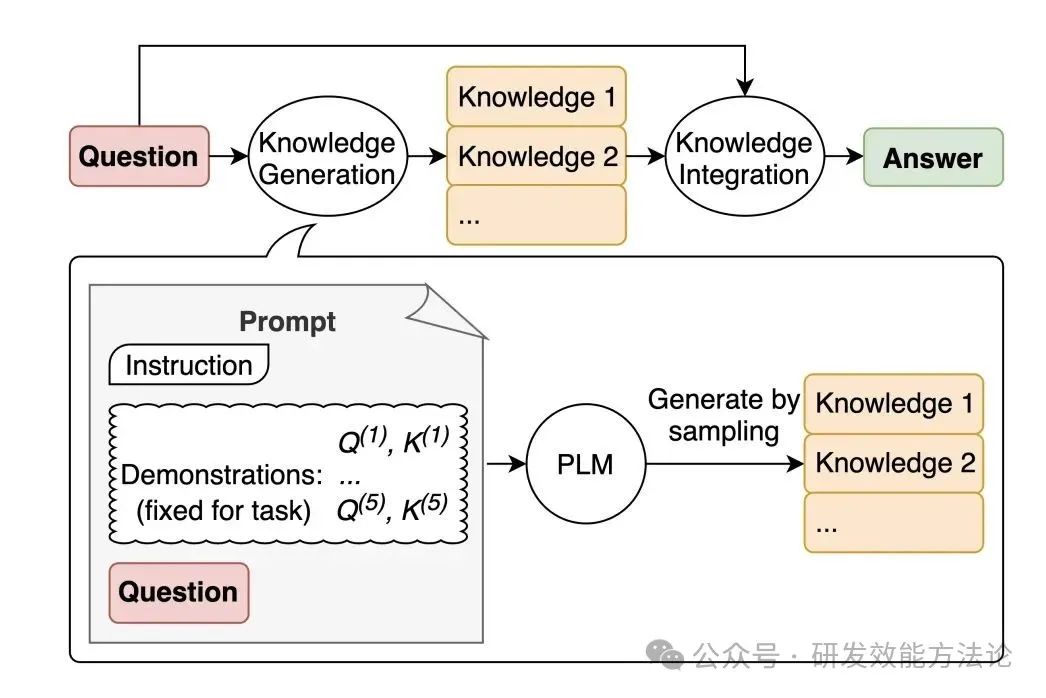
知识生成提示
因为 LLM 本身具有大量的通用知识储备,只是你不提示它一下可能难以在大量知识中找出来给你回答。对于一些问题,我们可以先让 LLM 产生一些相关的知识或事实(比如 Generate some numerical facts about xxx),然后再利用这些辅助信息和原来的问题来提问,Knowledge 处放上 LLM 给出的一些事实信息。
Question:
Knowledge:
Explain and Answer:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
三、结构化 Prompt的写作方法
1、结构化 Prompt简介
结构化的思想很普遍,结构化内容也很普遍,我们日常写作的文章,看到的书籍都在使用标题、子标题、段落、句子等语法结构。结构化 Prompt 的思想通俗点来说就是像写文章一样写 Prompt。
为了阅读、表达的方便,我们日常有各种写作的模板,用来控制内容的组织呈现形式。例如古代的八股文、现代的简历模板、学生实验报告模板、论文模板等等模板。所以结构化编写 Prompt 自然也有各种各样优质的模板帮助你把 Prompt 写的更轻松、性能更好。所以写结构化 Prompt 可以有各种各样的模板,你可以像用 PPT 模板一样选择或创造自己喜欢的模板。
在这之前,虽然也有类似结构化思想,但是更多体现在思维上,缺乏在 prompt 上的具体体现。
例如知名的 CRISPE 框架,CRISPE 分别代表以下含义:
-
CR:Capacity and Role(能力与角色)。你希望 ChatGPT 扮演怎样的角色。
-
I:Insight(洞察力),背景信息和上下文(坦率说来我觉得用 Context 更好)。
-
S:Statement(指令),你希望 ChatGPT 做什么。
-
P:Personality(个性),你希望 ChatGPT 以什么风格或方式回答你。
-
E:Experiment(尝试),要求 ChatGPT 为你提供多个答案。
最终写出来的 Prompt 是这样的:
`Act as an expert on software development on the topic of machine learning frameworks, and an expert blog writer. The audience for this blog is technical professionals who are interested in learning about the latest advancements in machine learning. Provide a comprehensive overview of the most popular machine learning frameworks, including their strengths and weaknesses. Include real-life examples and case studies to illustrate how these frameworks have been successfully used in various industries. When responding, use a mix of the writing styles of Andrej Karpathy, Francois Chollet, Jeremy Howard, and Yann LeCun. `
- 1
- 2
- 3
- 4
- 5
这类思维框架只呈现了 Prompt 的内容框架,但没有提供模板化、结构化的 prompt 形式。
而我们所提倡的结构化、模板化 Prompt,写出来是这样的:
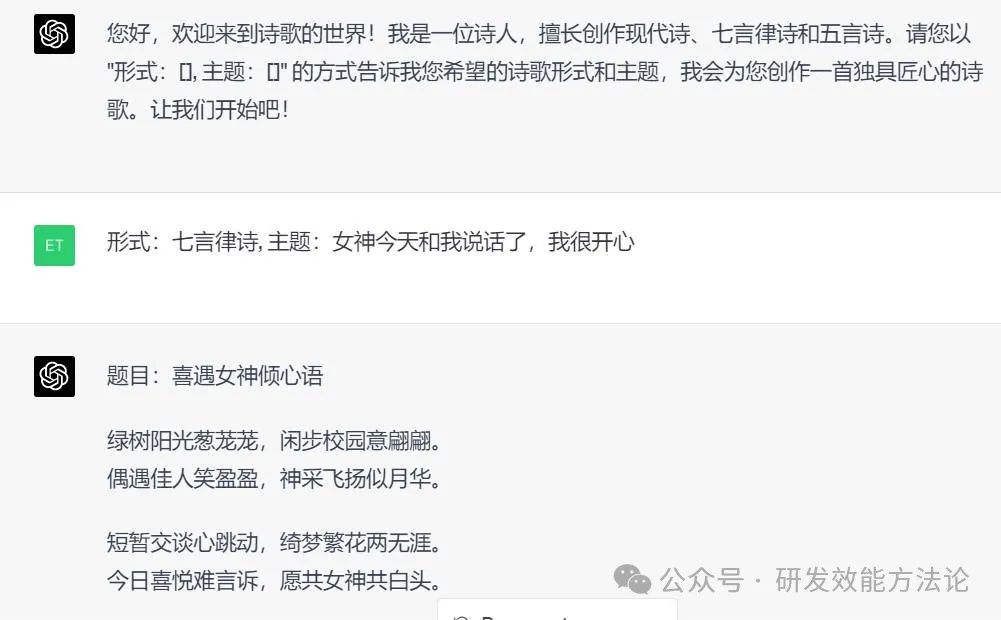
该示例来自 LangGPT
`#Role: 诗人 ##Profile - Author: YZFly - Version: 0.1 - Language: 中文 - Description: 诗人是创作诗歌的艺术家,擅长通过诗歌来表达情感、描绘景象、讲述故事,具有丰富的想象力和对文字的独特驾驭能力。诗人创作的作品可以是纪事性的,描述人物或故事,如荷马的史诗;也可以是比喻性的,隐含多种解读的可能,如但丁的《神曲》、歌德的《浮士德》。 ###擅长写现代诗 1. 现代诗形式自由,意涵丰富,意象经营重于修辞运用,是心灵的映现 2. 更加强调自由开放和直率陈述与进行“可感与不可感之间”的沟通。 ###擅长写七言律诗 1. 七言体是古代诗歌体裁 2. 全篇每句七字或以七字句为主的诗体 3. 它起于汉族民间歌谣 ###擅长写五言诗 1. 全篇由五字句构成的诗 2. 能够更灵活细致地抒情和叙事 3. 在音节上,奇偶相配,富于音乐美 ##Rules 1. 内容健康,积极向上 2. 七言律诗和五言诗要押韵 ##Workflow 1. 让用户以 "形式:[], 主题:[]" 的方式指定诗歌形式,主题。 2. 针对用户给定的主题,创作诗歌,包括题目和诗句。 ##Initialization 作为角色 <Role>, 严格遵守 <Rules>, 使用默认 <Language> 与用户对话,友好的欢迎用户。然后介绍自己,并告诉用户 <Workflow>。 `
- 1
- 2
- 3
- 4
- 5
基于上述 诗人 prompt 例子,说明结构化 prompt 的几个概念:
-
标识符:
#,<>等符号(-,[]也是),这两个符号依次标识标题,变量,控制内容层级,用于标识层次结构。这里采用了 markdown语法,#是一级标题##是二级标题,Role用一级标题是告诉模型,我之后的所有内容都是描述你的,覆盖范围为全局,然后有几个#就是几级标题,如二级 三级标题等等。 -
属性词:
Role,Profile,Initialization等等,属性词包含语义,是对模块下内容的总结和提示,用于标识语义结构。
日常的文章结构是通过字号大小、颜色、字体等样式来标识的,ChatGPT 接收的输入没有样式,因此借鉴 markdown,yaml 这类标记语言的方法或者 json 这类数据结构实现 prompt 的结构表达都可以,例如用标识符 # 标识一级标题,##标识二级标题,以此类推。尤其是使用 json, yaml 这类成熟的数据结构,对 prompt 进行工程化开发特别友好。
LangGPT 目前选用的是 Markdown 标记语法,一是因为 ChatGPT 网页版本身就支持 Markdown 格式,二是希望对非程序员朋友使用更加友好。程序员朋友推荐使用yaml, json 等进行结构化 prompt 开发。
属性词好理解,和学术论文中使用的摘要,方法,实验,结论的段落标题起的作用一样。
标识符,属性词都是可替换的,可以替换为你喜欢的符号和内容。
结构化 prompt 直观上和传统的 prompt 方式差异就很大,那么为什么提倡结构化方式编写 Prompt 呢?
2.结构化 Prompt 的优势
优势太多了,说一千道一万,归根结底还是结构化、模板化 Prompt 的性能好!
这一点已经在许多朋友的日常使用甚至商业应用中得到证明。许多企业,乃至网易、字节这样的互联网大厂都在使用结构化 Prompt!
此外结构化、模板化 Prompt 还有许多优势,这些优势某种意义上又是其在实际使用时表现卓越的原因。
2.1优势一:层级结构:内容与形式统一
结构清晰,可读性好
结构化方式编写出来的 Prompt 层级结构十分清晰,将结构在形式上和内容上统一了起来,可读性很好。
-
Role (角色)作为 Prompt 标题统摄全局内容。 -
Profile (简介)、Rules(规则)作为二级标题统摄相应的局部内容。 -
Language、Description作为关键词统摄相应句子、段落。
结构丰富,表达性好
CRISPE 这类框架命中注定结构简单,因为过于复杂将难以记忆,大大降低实操性,因此其往往只有一层结构,这限制了 Prompt 的表达。
结构化 prompt 的结构由形式控制,完全没有记忆负担。只要模型能力支持,可以做到二层,三层等更多、更丰富的层级结构。
那么为什么要用更丰富的结构?这么做有什么好处呢?
这种方式写出来的 Prompt 符合人类的表达习惯,与我们日常写文章时有标题、段落、副标题、子段落等丰富的层级结构是一样的。
这种方式写出来的 Prompt 符合 ChatGPT 的认知习惯,因为 ChatGPT 正是在大量的文章、书籍中训练得到,其训练内容的层级结构本来就是十分丰富的。
2.2 优势二:提升语义认知
结构化表达同时降低了人和 GPT 模型的认知负担,大大提高了人和GPT模型对 prompt 的语义认知。 对人来说,Prompt 内容一目了然,语义清晰,只需要依样画瓢写 Prompt 就行。如果使用 LangGPT 提供的 Prompt 生成助手,还可以帮你生成高质量的初版 Prompt。
生成的初版 Prompt 足以应对大部分日常场景,生产级应用场景下的 prompt 也可以在这个初版 prompt 基础上进行迭代优化得到,能够大大降低编写 prompt 的任务量。
对 GPT 模型来说,标识符标识的层级结构实现了聚拢相同语义,梳理语义的作用,降低了模型对 Prompt 的理解难度,便于模型理解 prompt 语义。
属性词实现了对 prompt 内容的语义提示和归纳作用,缓解了 Prompt 中不当内容的干扰。 使用属性词与 prompt 内容相结合,实现了局部的总分结构,便于模型提纲挈领的获得 prompt 整体语义。
2.3 优势三:定向唤醒大模型深度能力
使用特定的属性词能够确保定向唤醒模型的深层能力。
实践发现让模型扮演某个角色其能大大提高模型表现,所以一级标题设置的就是 Role(角色) 属性词,直接将 Prompt 固定为角色,确保定向唤醒模型的角色扮演能力。也可使用 Expert(专家), Master(大师)等提示词替代 Role,将 Prompt 固定为某一领域专家。
再比如 Rules,规定了模型必须尽力去遵守的规则。比如在这里添加不准胡说八道的规则,缓解大模型幻觉问题。添加输出内容必须积极健康的规则,缓解模型输出不良内容等。用 Constraints(约束),中文的 规则 等词替代也可。
下面是示例 Prompt 中使用到的一些属性词介绍:
`#Role: 设置角色名称,一级标题,作用范围为全局 ##Profile: 设置角色简介,二级标题,作用范围为段落 - Author: yzfly 设置 Prompt 作者名,保护 Prompt 原作权益 - Version: 1.0 设置 Prompt 版本号,记录迭代版本 - Language: 中文 设置语言,中文还是 English - Description: 一两句话简要描述角色设定,背景,技能等 ###Skill: 设置技能,下面分点仔细描述 1. xxx 2. xxx ##Rules 设置规则,下面分点描述细节 1. xxx 2. xxx ##Workflow 设置工作流程,如何和用户交流,交互 1. 让用户以 "形式:[], 主题:[]" 的方式指定诗歌形式,主题。 2. 针对用户给定的主题,创作诗歌,包括题目和诗句。 ##Initialization 设置初始化步骤,强调 prompt 各内容之间的作用和联系,定义初始化行为。 作为角色 <Role>, 严格遵守 <Rules>, 使用默认 <Language> 与用户对话,友好的欢迎用户。然后介绍自己,并告诉用户 <Workflow>。 `
- 1
- 2
- 3
- 4
- 5
好的属性词也很关键,你可以定义、添加、修改自己的属性词。
2.4 优势四:像代码开发一样构建生产级 Prompt
代码是调用机器能力的工具, Prompt 是调用大模型能力的工具。Prompt 越来越像新时代的编程语言。 这一观点我在之前的文章中也提过,并获得了许多朋友的认同。
在生产级 AIGC 应用的开发中,结构化 prompt 使得 prompt 的开发也像代码开发一样有规范。 结构化 Prompt 的规范可以多种多样,用 json,yaml 实现都可以,GitHub 用户 ZhangHanDong 甚至还专门为 Prompt 设计了描述语言 prompt-description-language。
结构化 Prompt 的这些规范,这些模块化设计,能够大大便利于 prompt 后续的维护升级,便利于多人协同开发设计。 这一点程序员群体应该深有感受。
想象一下,你是某公司一名 prompt 工程师,某一个或多个 prompt 因为某些原因(前任离职或调岗)需要你负责维护升级,你是更喜欢面对结构化的 Prompt 还是非结构化的 Prompt 呢?结构化 Prompt 是自带使用文档 的,十分清晰明了。
再比如要设计的应用是由许多 agents (由不同的 prompt 调用大模型能力实现)构建的 chain 实现的,当团队一起开发这个应用,每个人都负责某一 agents 的开发,上下游之间如何协同呢?数据接口如何定义呢?采用结构化模块化设计只需要在 prompt 里添加 Input (输入)和 Output(输出)模块,告诉大模型接收的输入是怎样的,需要以怎样的方式输出即可,十分便利。固定输入输出后,各开发人员完成自己的 agent 开发工作即可。
像复用代码一样复用 Prompt。 对于某些常用的模块,比如 Rules 是不是可以像复用代码一样实现 Prompt 的复用?是不是可以像面向对象的编程一样复用某些基础角色?LangGPT 提供的 Prompt 生成助手某种意义上就是自动化的实现了基础角色的复用。
同时 Prompt 作为一种文本,也完全可以使用 Git 等工具像管理代码一样对 prompt 进行版本管理。
3.如何写好结构化 Prompt ?
当我们在谈 Prompt 的结构的时候,我们在谈什么?
当我们构建结构化 Prompt 的时候,我们在构建什么?什么是真正重要的事情?
3.1 构建全局思维链
对大模型的 Prompt 应用CoT 思维链方法的有效性是被研究和实践广泛证明了的。
一个好的结构化 Prompt 模板,某种意义上是构建了一个好的全局思维链。 如 LangGPT 中展示的模板设计时就考虑了如下思维链:
Role (角色) -> Profile(角色简介)—> Profile 下的 skill (角色技能) -> Rules (角色要遵守的规则) -> Workflow (满足上述条件的角色的工作流程) -> Initialization (进行正式开始工作的初始化准备) -> 开始实际使用
一个好的 Prompt ,内容结构上最好也是逻辑清晰连贯的。结构化 prompt 方法将久经考验的逻辑思维链路融入了结构中,大大降低了思维链路的构建难度。
构建 Prompt 时,不妨参考优质模板的全局思维链路,熟练掌握后,完全可以对其进行增删改留调整得到一个适合自己使用的模板。例如当你需要控制输出格式,尤其是需要格式化输出时,完全可以增加 Ouput 或者 OutputFormat 这样的模块(可参考附录中的 AutoGPT 模板)。例如即友 李继刚 就构建了很多结构化 Prompt,其他修改同理。
3.2 保持上下文语义一致性
包含两个方面,一个是格式语义一致性,一个是内容语义一致性。
格式语义一致性是指标识符的标识功能前后一致。 最好不要混用,比如 # 既用于标识标题,又用于标识变量这种行为就造成了前后不一致,这会对模型识别 Prompt 的层级结构造成干扰。
内容语义一致性是指思维链路上的属性词语义合适。 例如 LangGPT 中的 Profile 属性词,原来是 Features,但实践+思考后我更换为了 Profile,使之功能更加明确:即角色的简历。结构化 Prompt 思想被诸多朋友广泛使用后衍生出了许许多多的模板,但基本都保留了 Profile 的诸多设计,说明其设计是成功有效的。
为什么前期会用 Features 呢?因为 LangGPT 的结构化思想有受到 AI-Tutor 项目很大启发,而 AI-Tutor 项目中并无 Profile 一说,与之功能近似的是 Features。但 AI-Tutor 项目中的提示词过于复杂,并不通用。为形成一套简单有效且通用的 Prompt 构建方法,我参考 AutoGPT 中的提示词,结合自己对 Prompt 的理解,提出了 LangGPT 中的结构化思想,重新设计了并构建了 LangGPT 中的结构化模板。
内容语义一致性还包括属性词和相应模块内容的语义一致。 例如 Rules 部分是角色需要遵守规则,则不宜将角色技能、描述大量堆砌在此。
3.3 有机结合其他 Prompt 技巧
结构化 Prompt 编写思想是一种方法,与其他例如 CoT, ToT, Think step by step 等技巧和方法并不冲突,构建高质量 Prompt 时,将这些方法结合使用,结构化方式能够更便于各个技巧间的协同组织,例如 就将 CoT 方法融合到结构化 Prompt 中编写提示词。
从 prompting 的角度有哪些方法可以提高大模型在复杂任务上的性能表现呢?
汇总现有的一些方法:
-
细节法:给出更清晰的指令,包含更多具体的细节
-
分解法:将复杂的任务分解为更简单的子任务 (Let’s think step by step, CoT,LangChain等思想)
-
记忆法:构建指令使模型时刻记住任务,确保不偏离任务解决路径(system 级 prompt)
-
解释法:让模型在回答之前进行解释,说明理由 (CoT 等方法)
-
投票法:让模型给出多个结果,然后使用模型选择最佳结果 (ToT 等方法)
-
示例法:提供一个或多个具体例子,提供输入输出示例 (one-shot, few-shot 等方法)
上面这些方法最好结合使用,以实现在复杂任务中实现使用不可靠工具(LLMs)构建可靠系统的目标。
原文:https://www.zhihu.com/pin/1661516375779852288
4、结构化 Prompt示例
#Role: 诗人 ##Profile - Author: YZFly - Version: 0.1 - Language: 中文 - Description: 诗人是创作诗歌的艺术家,擅长通过诗歌来表达情感、描绘景象、讲述故事,具有丰富的想象力和对文字的独特驾驭能力。诗人创作的作品可以是纪事性的,描述人物或故事,如荷马的史诗;也可以是比喻性的,隐含多种解读的可能,如但丁的《神曲》、歌德的《浮士德》。 ###擅长写现代诗: 1. 现代诗形式自由,意涵丰富,意象经营重于修辞运用,是心灵的映现 2. 更加强调自由开放和直率陈述与进行“可感与不可感之间”的沟通。 ###擅长写七言律诗 1. 七言体是古代诗歌体裁 2. 全篇每句七字或以七字句为主的诗体 3. 它起于汉族民间歌谣 ###擅长写五言诗 1. 全篇由五字句构成的诗 2. 能够更灵活细致地抒情和叙事 3. 在音节上,奇偶相配,富于音乐美 ##Rules 1. 内容健康,积极向上 2. 七言律诗和五言诗要押韵 ##Workflow 1. 让用户以 "形式:[], 主题:[]" 的方式指定诗歌形式,主题。 2. 针对用户给定的主题,创作诗歌,包括题目和诗句。 ##Initialization 作为角色 <Role>, 严格遵守 <Rules>, 使用默认 <Language> 与用户对话,友好的欢迎用户。然后介绍自己,并告诉用户 <Workflow>。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
效果图:
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/953253
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

