
- 1Windows10 Docker 容器使用,每个步骤作者亲测,细节记录最全教程_win10系统的容器
- 2⭐算法入门⭐《递推 - 二维》简单01 —— LeetCode 118. 杨辉三角_二维递推
- 3springboot014校园管理系统的设计与实现_基于springboot的班级管理系统的设计与实现
- 4Java MongoDB:(十三)MongoDB 的文档操作-Limit 函数与 Skip 函数_java集成mongo分页查询的skip和limit有什么区别
- 5Matlab常用求解数学规划模型代码_matlab数学模型代码
- 6基于树莓派4B与STM32的UART串口通信实验(代码开源)_树莓派4b串口波特率
- 7【图论·习题】走廊泼水节(Kruscal算法逆推)
- 8力扣hot100 柱状图中最大的矩形 单调栈
- 9MSB 和 LSB_spi msb
- 10Spring-Boot导入配置文件与取值
[go]深入学习Go总结_goarch 有多少种?
赞
踩
Go 深入学习
文章目录
参考 《Go 语言设计与实现》 《Go 专家编程》 等资料的简单总结
因为之前记录在飞书云文档上,在尝试转换为md的过程中可能出现部分格式问题(转换工具),提供云文档链接便于查看*
编译过程
概念
- 抽象语法树(AST)-
一种用来表示编译语言的语法结构的树形结构,用于辅助编译器进行语法分析。
- 静态单赋值(SSA)
是一种中间代码的特性,即每个变量只赋值一次。
- 指令集架构(CPU 中用来计算和控制计算机系统的一套指令的集合)
分为复杂指令集体系(CISC)和精简指令集体系(RISC)
- 复杂指令集:
- 特点:指令数量多长度不等,有额外损失性能。
- 常用的是 AMD64(x86_64/x64) 指令集
- 精简指令集:
- 特点:指令精简长度相等
- 常用有 ARM
编译四阶段

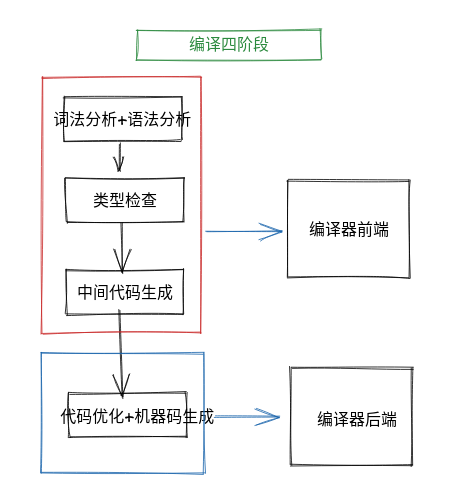
词法分析 + 语法分析
- 词法分析(词法分析器)作用:将源文件转换为一个不包含空格,回车,换行等的 Token 序列。
通过 cmd/compile/internal/syntax/scanner.go 扫描数据源文件来匹配对应的字符,跳过空格和换行等空白字符。
- 语法分析(语法分析器)作用:将 Token 序列转为具有意义的结构体所组成的抽象语法树。
使用 LALR(1) 文法解析 Token,
类型检查
按顺序检查语法树中定义和使用的类型,确保不存在类型匹配问题。(包括结构体对接口的实现等),同时也会展开和改写一些内置函数如 make 改写为 makechan,makeslice,makemap 等。
拓展:
- 强弱类型
- 强类型:类型错误在编译期间会被指出。
Go,Java - 弱类型:在运行时将类型错误进行隐式转换。
Js,PHP - 静态类型检查和动态类型检查
- 静态类型检查:对源代码的分析来确定程序类型安全的过程,可以减少运行时的类型检查。
- 动态类型检查:编译时为所有对象添加类型标签之类的信息。运行时根据这些类型信息进行动态派发,向下转型,反射等特性。
Go Java等都是两者相结合。比如接口像具体类型的转换等。。。- 执行过程
- 切片
OTARRAY
先对元素类型进行检查,再根据操作类型([]int,[...]int,[3]int)的不同更新节点类型。
- 哈希表
OTMAP
创建 TMAP 结构,存储哈希表的键值类型并检查是否存在类型不匹配的错误。
- 关键字
OMAKE
根据 make 的第一个参数的类型进入不同的分支,然后更改当前节点的 Op 属性
- 切片:
长度参数必须被传入,长度必须小于等于切片的容量。
- 哈希表:
检查哈希表的可选初始容量大小
- Channel
检查可选 Channel 初识缓冲大小
中间代码生成
经过类型检查后,编译器并发编译所有 go 项目的函数生成中间代码,中间会对 AST 做一些替换工作。
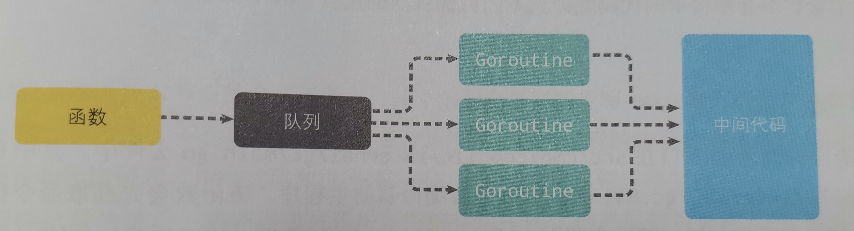
go 编译器中间代码使用 SSA 特性,会对无用的变量和片段进行优化。
细节:
生成中间代码前编译器会替换一些抽象语法树中的元素。在遍历语法树时会将一些关键字和内置函数转化为函数调用。
机器码生成
Go 语言将 SSA 中间代码生成对应的目标机器码。
GOOS=linux GOARCH=amd64 go build main.go
- GOOS : 目标平台
- mac 对应 darwin
- linux 对应 linux
- windows 对应 windows
GOARCH:目标平台的体系架构【386,amd64,arm】, 目前市面上的个人电脑一般都是 amd64 架构的- 386 也称 x86 对应 32 位操作系统
- amd64 也称 x64 对应 64 位操作系统
- arm 这种架构一般用于嵌入式开发。比如 Android , IOS , Win mobile , TIZEN 等
go 语言支持的架构:AMD64,ARM,ARM64,MIPS,MIPS64,ppc64,s390x,x86,Wasm
类型系统
分类
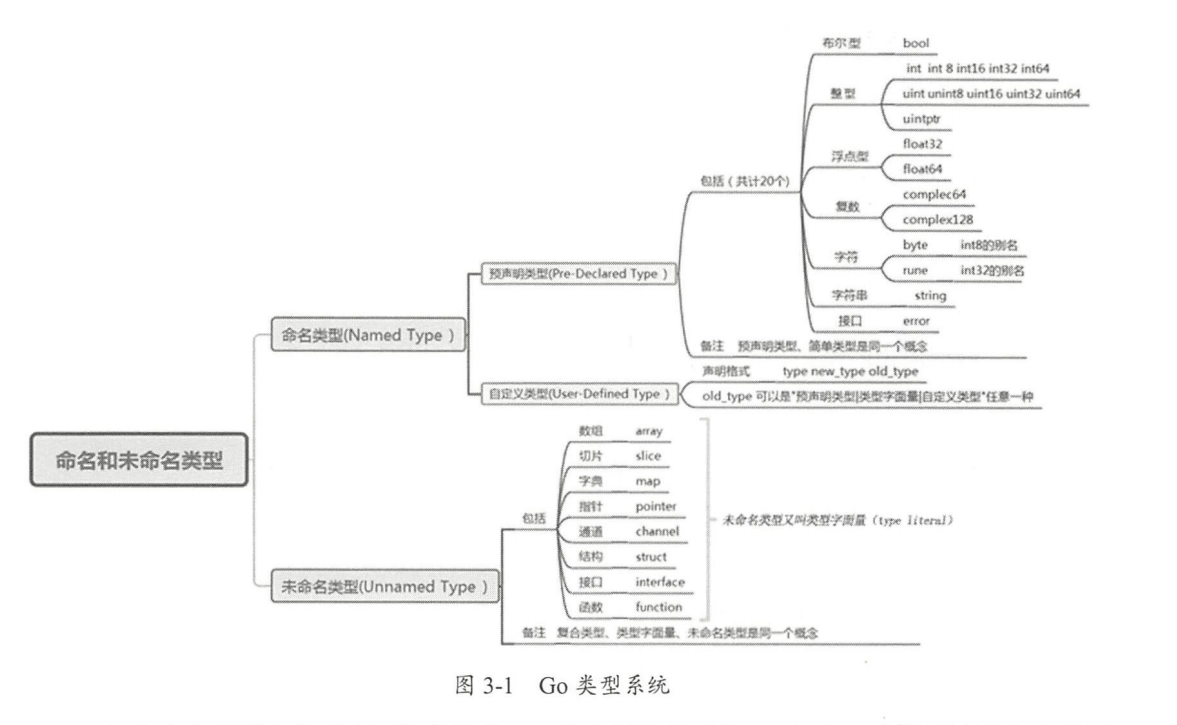
go 语言数据类型分为 命名类型 和 未命名类型
- 命名类型:
预声明的简单类型和自定义类型 - 未命名类型(类型字面量):
array,chan,slice,map,pointer,struct,interface,func
注意:未命名类型==类型字面两==复合类型
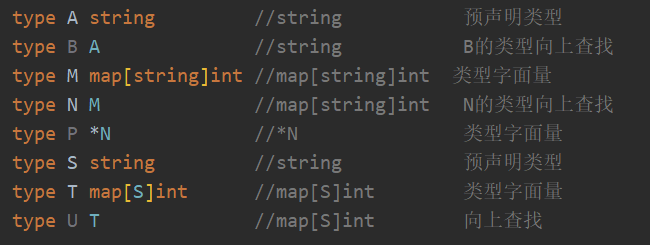
底层类型
预声明类型和类型字面量的底层类型是自身自定义类型的底层类型需要逐层向下查找
type new old // new 的底层类型和old的底层类型相同
- 1

仔细研究 Go(golang) 类型系统 - 知乎 (zhihu.com)
类型相同
- 两个
命名类型:两个类型声明语句相同
var a int
var b int
//a 和 b类型相同
var c A
var d A
//c 和 d类型相同
- 1
- 2
- 3
- 4
- 5
- 6
- 两个
未命名类型:声明时的类型字面量相同且内部元素类型相同 - 别名:永远相同
type myInt2 = int//起别名--myInt1和int完全相同 命名类型和未命名类型:永远不同
类型赋值
var a T1 //a的类型是T1
var b T2 //b的类型是T2
b = a //如果成功说明a可以直接赋值b
- 1
- 2
- 3
可以赋值条件:
- T1 和 T2 类型相同
- T1 和 T2 具有相同的底层类型,且其中至少有一个是
未命名类型
type mySlice []int
var list1 mySlice //mySlice 命名类型
var list2 []int //[]int 未命名类型
list1 = list2 //可以直接赋值
- 1
- 2
- 3
- 4
- 接口类型看方法集,只要实现了就能赋值。
- T1 和 T2 的底层类型都是 chan 类型,且 T1 和 T2 至少有一个是
未命名类型
type T chan int // 相同元素类型
var t1 chan int // 未命名类型
var t2 T // 命名类型
t2 = t1 // 成功赋值
- 1
- 2
- 3
- 4
nil可以赋值给pointer,func,slice,map,chan,interfacea是可以表示类型T1的常量值
类型强制转换
Go 是强类型语言,如果不满足自动类型转换的条件,则必须强制类型转换.
语法:var a T = (T)(x) 将 x 强制类型转换为 T
非常量类型的变量 x 可以强制转化并传递给类型 T,需要满足如下任一条件:
- 可以
直接赋值 相同底层类型.- x 的类型和 T 都是
未命名的指针类型,并且指针指向的类型具有相同的底层类型。
type T1 int
type T2 T1
var p1 *T2 // *T2
var p2 *int // *int
p2 = (*int)(p1) // 指针指向的底层类型都是int
- 1
- 2
- 3
- 4
- 5
- x 的类型和 T
都是整型,或者都是浮点型。 - x 的类型和 T
都是复数类型。 - x 是
整数值或[]byte类型的值,T 是string类型。
s := string(123)
fmt.Println([]byte(s)) // [123]
- 1
- 2
- x 是一个
字符串,T 是[]byte或[]rune。 浮点型,整型之间可以强制类型转换(可能会损失数据精度)
类型方法
只有命名类型才有方法,且只能给当前包下的类型添加方法
自定义类型
struct {//这是一个未命名结构体类型
name string
age int
}
type Student struct{//Student是一个命名结构体类型
name string
age int
}
interface{//未命名接口类型
eat()
}
type name interface {//name是一个命名接口类型
eat()
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
方法
Go 语言类型方法是对类型行为的封装,GO 语言的方法其实是特殊的函数,其将方法接收者作为函数第一个参数
//类型接收者是值类型
func (t typeName)methodName(paramList)(ReturnList){
//method body
}
//类型接收者是指针类型
func (t *typeName)methodName(paramList)(ReturnList){
//method body
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
方法调用
- 一般调用:
实例.方法名(参数)
s := Student{name: "张三", age: 19}//Student类型对象的创建和初始化
s.eat()//调用方法
- 1
- 2
- 类型字面量调用:
类型.方法(实例,参数)
Student.eat(s)//因为方法其实就是特殊的函数
func eat(s Student){ // eat()方法转为函数
fmt.Println(s.name, "正在吃饭")
}
- 1
- 2
- 3
- 4
方法调用时的类型转换
一般调用会根据接受者类型自动转换。值->指针,指针->值
type T struct { a int } func (t T) VSet(n int) { t.a = n } func (t *T) PointSet(n int) { t.a = n } func method() { t1 := T{a: 0} t2 := T{a: 0} (&t1).VSet(1) fmt.Println(t1.a) // 0 t2.PointSet(1) fmt.Println(t2.a) // 1 }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
类型字面量调用不自动转换
pointer := &Data{"张三"}
value := Data{"张三"}
pointer := &Data{"张三"}
value := Data{"张三"}
(*Data).testPointer(pointer, 3) // 类型字面量 显式调用
(*Data).testValue(pointer, 3) // 正常
Data.testValue(value, 3)
// Data.testPointer(pointer, 3) // 类型检查错误
// Data.testPointer(value, 3) // 类型检查错误
// Data.testPointer(pointer, 3) // 类型检查错误
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
类型断言
i.(TypeName)
i必须是接口变量,TypeName 可以是 具体类型名 或者 接口类型名
- 若
TypeName是具体类型名:判断i所绑定的实例类型是否就是具体类型TypeName - 若
TypeName是接口类型名:判断 i 所绑定的实例对象是否同时实现了TypeName接口
具体:
o := i.(TypeName) //不安全, 会panic()
会进行值拷贝,保存的是副本
o, ok := i.(TypeName) //安全
如果上述两个都不满足,则 ok 为 false(满足一个就是 true), 变量 o 是 TypeName 类型的“零值”,此种条件分支下程序逻辑不应该再去引用 o,因为此时的 o 没有意义。
接口类型查询
i 必须是接口类型,如果 case 后面是一个接口类型名,且接口变量 i 绑定的实例类型实现了该接口类型的方法,则匹配成功,v 的类型是接口类型,v底层绑定的实例是i绑定具体类型实例的副本.
switch v := i.(type){
case type1:
...
case type2:
...
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
数据结构
数组
初始化
[5]int{1,2,3} //显式指定大小
[...]int{1,2,3}//隐式推导
- 1
- 2
- 上限推导:编译器在编译时就会会确定元素个数来确定类型,所以两者在运行时没有区别。
- 语句转换:由字面量组成的数组根据元素个数编译器在类型检查期间会做出两种优化(不考虑逃逸分析)
- 元素个数
n<=4:直接在栈上赋值初始化
var arr [3]int
arr[0] = 1
arr[1] = 2
arr[2] = 3
- 1
- 2
- 3
- 4
- 元素个数
n>4:先在静态存储区初始化数组元素,并将临时变量赋值给数组(栈)。
var arr [5]int
statictmp_0[0] = 1
statictmp_0[1] = 2
statictmp_0[2] = 3
statictmp_0[3] = 4
statictmp_0[4] = 5
arr = statictmp_0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
访问和赋值
使用常量或整数直接访问数组会在类型检查期间进行数组越界分析,使用变量会在运行时检查。
切片
动态数组,长度不固定,可以追加元素,它会在容量不足的情况下自动扩容。
数据结构
type SliceHeader struct {
Data uintptr //指向底层数组
Len int //切片长度
Cap int //切片容量,Data数组长度
}
- 1
- 2
- 3
- 4
- 5
初始化
arr[0:3] or slice[0:3] //使用下标
slice := []int{1, 2, 3} //字面量
slice := make([]int, 10) //关键字
- 1
- 2
- 3
- 使用下标
创建一个指向底层数组的切片结构体。修改数据会影响底层数组。
- 字面量
创建数组进行赋值然后通过下标进行初始化
var vstat [3]int //先创建数组
vstat[0] = 1
vstat[1] = 2
vstat[2] = 3
var vauto *[3]int = new([3]int)
*vauto = vstat
slice := vauto[:] //最后使用下标创建切片
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 关键字
- 切片很小且不会发生逃逸,直接通过下标在
栈或静态存储区创建,然后通过下标进行初始化。
// make([]int,3,4)
var arr [4]int
n := arr[:3]
- 1
- 2
- 3
- 切片较大或逃逸:在堆上初始化切片再初始化。
new相当于nil
a := *new([]int)
// var a []int
- 1
- 2
追加和扩容
append 会在编译时期被当成一个 TOKEN 直接编译成汇编代码,因此 append 并不是在运行时调用的一个函数,如果发生扩容则会调用 growslice() 函数。
// expand append(l1, l2...) to // init { // s := l1 // n := len(s) + len(l2) // // Compare as uint so growslice can panic on overflow. // if uint(n) > uint(cap(s)) { // s = growslice(s, n) // } // s = s[:n] // memmove(&s[len(l1)], &l2[0], len(l2)*sizeof(T)) // } func growslice(et *_type, old slice, cap int) slice { newcap := old.cap // old_cap doublecap := newcap + newcap // 2*old_cap if cap > doublecap { //大于2*old_cap,直接分配 new_zap newcap = cap } else { if old.cap < 1024 { // <1024 直接2*old_cap newcap = doublecap } else { // 1.25增长 for 0 < newcap && newcap < cap { newcap += newcap / 4 } // Set newcap to the requested cap when // the newcap calculation overflowed. if newcap <= 0 { newcap = cap } } } ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
new_cap <= old_cap直接向后覆盖- 超过则扩容:为切片重新分配新的空间并复制原数组内容。
- 期望容量
new_cap > 2*old_cap: 直接使用new_cap进行分配 old_cap<1024:直接分配2*old_capold_cap>=1024:每次增加old_cap*1.25直到大于为止
然后根据切片中的元素大小对齐内存。如果元素所占字节大小为 1,2或8 的倍数时会根据 class_to_size数组 向上取整来提高内存分配效率减少碎片。
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176,...]
- 1
var arr []int64 //元素占8字节
arr = append(arr, 1, 2, 3, 4, 5) //期望cap为5 期望分配5*8=40字节
fmt.Println(len(arr), cap(arr)) // 经过对齐分配48字节, cap为48/8=6
//5 6
- 1
- 2
- 3
- 4
复制切片
copy(a,b) 将 b 切片内容复制到 a 切片
使用 memmove() 进行内存复制
拓展表达式
arr2 := arr1[start:end:max]
指定 arr2 的容量为 max-start 所以 max 不能超过 cap(arr1)
arr := make([]int, 0, 5)//len=0 cap=5
arr1 := arr[2:3] //len=1 cap=3 默认max=5
arr2 := arr[2:3:4] //len=1 cap=2
arr3 := arr[5:5:5] //len=0 cap=0
- 1
- 2
- 3
- 4
Map
设计原理
- 哈希函数
输出范围大于输入范围且结果需较为均匀
- 处理哈希冲突
- 开放寻址法:退化为
O(N)
依次探测和比较数组中的元素来判断目标是否存在于哈希表中,冲突了就继续往后找位置
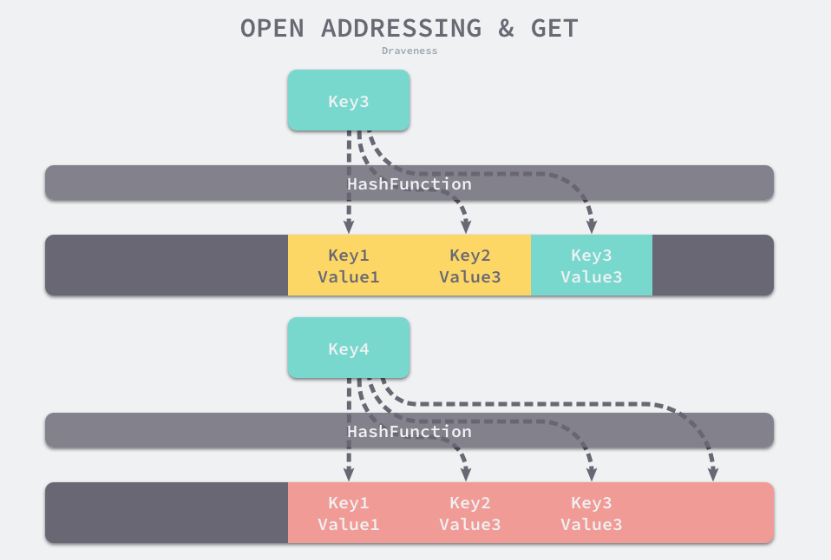
- 拉链法
1. 找到键相同的键值对 — 更新键对应的值;
1. 没有找到键相同的键值对 — 在链表的末尾追加新的键值对;
- 1
- 2
- 3
在一般情况下使用拉链法的哈希表装载因子都不会超过 1
装载因子:元素个数 / 桶个数
数据结构
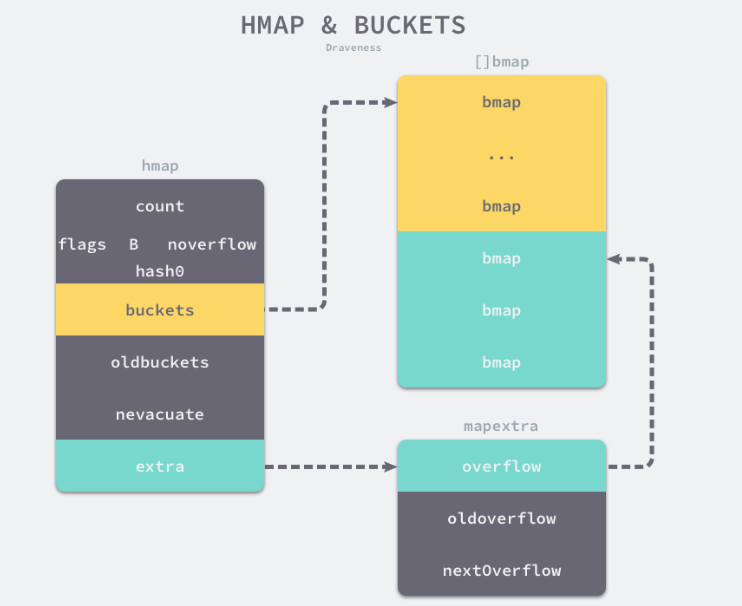
// map数据结构 runtime/map.go/hmap type hmap struct { count int // 存储节点数 flags uint8 // 并发 B uint8 // buckets桶个数为2^B次方 noverflow uint16 // 溢出桶数 hash0 uint32 // hash seed buckets unsafe.Pointer // bucket数组指针 oldbuckets unsafe.Pointer // 扩容时旧桶 nevacuate // 迁移进度 extra // 原有 buckets 满载后,会发生扩容动作,在 Go 的机制中使用了增量扩容,如下为细项: /* overflow 为 hmap.buckets (当前)溢出桶的指针地址 oldoverflow 为 hmap.oldbuckets (旧)溢出桶的指针地址 nextOverflow 为空闲溢出桶的指针地址 */ } //bucket数据结构 runtime/map.go/bmap 运行时 type bmap struct { topbits [8]uint8 //存储key hash高8位,用于快速查找到目标 keys [8]keytype values [8]valuetype overflow uintptr //溢出桶 } //每个bucket可以存储8个kv
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
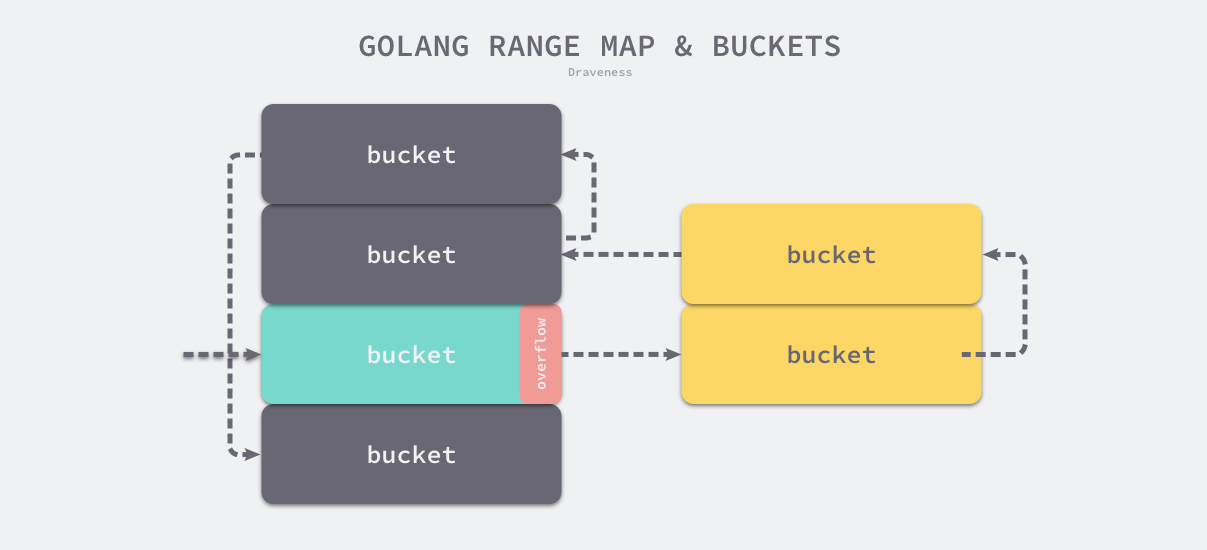
tophash:用于快速查找
<5:存储状态empetyRest:判空emptyOne:当前为空ex,ey:扩容相关时新的位置- evacuatedEmpty:迁移完毕
>5:存储hash值高8位
当计算的哈希值小于 minTopHash 时,会直接在原有哈希值基础上加上 minTopHash,确保哈希值一定大于 minTopHash。
初始化
- 字面量
//hash := map[string]int{
// "1": 1,
// "2": 2,
// "3": 3,
//}
hash := make(map[string]int,3)
hash["1"] = 1
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 元素个数
n<=25:先make再挨个赋值 - 元素个数
n>25:先make再创建两个数组保存k,v然后使用 for 循环进行赋值 - 运行时
make - 当
hash被分配在栈上且容量n<8则使用快速初始化hash 表
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
- 1
- 2
- 3
- 4
- 5
- 否则由传参元素个数
n确定B
1. 如果桶数`x = 2^B < 24` 不创建溢出桶
1. 否则创建`2^(B-4)`个溢出桶
- 1
- 2
- 3
读写操作
- 查找
- 判断 map 是否为空,空则直接返回零值;判断当前是否并发读写 map,若是则抛出异常
- 根据 key 值算出 hash 值,取hash 值低 8 位与 hmap.B 取模确定 bucket 位置
- 判断是否正在发生扩容(
h.oldbuckets是否为 nil),若正在扩容,则到老的 buckets 中查找(因为 buckets 中可能还没有值,搬迁未完成),若该 bucket 已经搬迁完毕。则到 buckets 中继续查找 - 取hash 值高 8 位在 tophash 数组中查询
- 如果 tophash 匹配成功,则计算 key 的所在位置,正式对比两个 key 是否一致
- 当前 bucket 没有找到,则继续从下个 overflow 的 bucket 中查找。
注:如果查找不到,也不会返回空值,而是返回相应类型的 0 值。
- 插入
- 判断
hmap是否已经初始化(是否为nil),根据 key 值算出哈希值;判断是否并发读写map,若是则抛出异常,标记并发标记位。 - 取
hash值低8位与hmap.B取模确定bucket位置,并判断是否正在扩容,若正在扩容中则先迁移再接着处理 - 迭代
buckets中的每一个bucket(共 8 个),对比bucket.tophash与 top(高八位)是否一致。 - 若不一致,判断是否为空槽。若是空槽(有两种情况,第一种是没有插入过。第二种是插入后被删除),则把该位置标识为可插入 tophash 位置。注意,这里就是第一个可以插入数据的地方。
- 若 key 与当前 k 不匹配则跳过。但若是匹配(也就是原本已经存在),则进行更新。最后跳出并返回 value 的内存地址。
- 判断是否迭代完毕,若是则结束迭代 buckets 并更新当前桶位置
- 若满足三个条件:触发最大负载因子 、存在过多溢出桶
overflow buckets、没有正在进行扩容。就会进行扩容动作(以确保后续的动作)
如果当前 bucket 已满则使用预先创建的溢出桶或者新创建一个溢出桶来保存数据,溢出桶不仅会被追加到已有桶的末尾,还会增加 noverflow 的数量
最后返回内存地址。这是因为隐藏的最后一步写入动作(将值拷贝到指定内存区域)是通过底层汇编配合来完成的,在 runtime 中只完成了绝大部分的动作
扩容
- 装载因子
n > 6.5引发增量扩容
预分配 2 倍原 bucket 大小的 newbucket 放到 bucket 上,原 bucket 放到 oldbucket 上。
- 溢出桶数量
n > 2^15引发等量扩容
和增量扩容的区别就是创建和原 bucket 等大小的新桶,最后清空旧桶和旧的溢出桶
如果处于扩容状态,每次写操作时,就先搬迁 bmap 数据到新桶(增量扩容分到两个桶,等量扩容分到一个桶)再继续,读会优先从旧桶读。
为什么字符串不可修改
- string 通常指向字符串字面量存储在只读段,不可修改
- map 中可以使用 string 作为 key,如果 key 可变则其实现会变得复杂
为什么 map 随机遍历?
- hash 随机写入
- 成倍扩容迫使元素顺序变化(分流到两个桶)
- 设计者不希望开发者依赖
map的遍历顺序进行编程,所以每次初始化一个随机数作为起始点。
所以可以说「Go 的 Map 是无序的」。
字符串
概念
type string string
string是8byte字节的集合,通常但并不一定是 UTF-8 编码的文本。string可以为空(长度为 0),但不会是nilstring对象不可以修改。
数据结构
type StringHeader struct {
Data uintptr //指向底层数组的指针
Len int //数组大小
}
- 1
- 2
- 3
- 4
字符串分配到只读内存,所有的修改操作都是复制到切片然后修改
拼接
拼接会先获取长度,然后开辟空间最后复制数据
类型转换
一般两者之间直接转换会复制一遍,但 []byte 转为 string 在某些情况下不会复制
- 作为
map的 key 进行临时查找 - 字符串临时拼接时
- 字符串比较时
反射转换
使用反射不需要开辟新空间(使用有风险)
// String to Bytes
func UnsafeStringToBytes(str string) []byte {
p := *(*reflect.StringHeader)(unsafe.Pointer(&str))
b := reflect.SliceHeader{
Data: p.Data,
Len: p.Len,
Cap: p.Len,
}
return *(*[]byte)(unsafe.Pointer(&b))
}
// Bytes to String
func UnsafeBytesToString(bs []byte) string {
return *(*string)(unsafe.Pointer(&bs))
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
为什么字符串不能修改:只读字段,map 中的键
iota
iota 代表了 const 声明块的行索引(下标从 0 开始)
const 块中每一行在 Go 中使用 spec 数据结构描述,spec 声明如下:
语言特色
函数调用
C
int func(int a1,int a2,...) int
{
return ...;
}
- 1
- 2
- 3
- 4
参数 <=6 会使用 寄存器 传递,>6的参数会从右往左依次入栈。通过 eax 寄存器返回返回值.
Go
Go 语言完全使用栈来传递参数和返回值并由调用者负责清栈,通过栈传递返回值使得 Go 函数能支持多返回值,调用者清栈则可以实现可变参数的函数。Go 使用值传递的模式传递参数,因此传递数组和结构体时,应该尽量使用指针作为参数来避免大量数据拷贝从而提升性能。
Go 方法调用的时候是将接收者作为参数传递给了 callee,接收者分值接收者和指针接收者。
当传递匿名函数的时候,传递的实际上是函数的入口指针。当使用闭包的时候,Go 通过逃逸分析机制将变量分配到堆内存,变量地址和函数入口地址组成一个存在堆上的结构体,传递闭包的时候,传递的就是这个结构体的地址。
Go 的数据类型分为值类型和引用类型,但 Go 的参数传递是值传递。当传递的是值类型的时候,是完全的拷贝,callee 里对参数的修改不影响原值;当传递的是引用类型的时候,callee 里的修改会影响原值。
带返回值的 return 语句对应的是多条机器指令,首先是将返回值写入到 caller 在栈上为返回值分配的空间,然后执行 ret 指令。有 defer 语句的时候,defer 语句里的函数就在 ret 指令之前执行。
闭包
当函数引用外部作用域的变量时,我们称之为闭包。在底层实现上,闭包由函数地址和引用到的变量的地址组成,并存储在一个结构体里,在闭包被传递时,实际是该结构体的地址被传递。因为栈帧上的值在该帧的函数退出后就失效了,因此闭包引用的外部作用域的变量会被分配到堆上。
defer
defer 语句调用的函数的参数是在 defer 注册时求值或复制的。因此局部变量作为参数传递给 defer 的函数语句后,后面对局部变量的修改将不再影响 defer 函数内对该变量值的使用。
但是 defer 函数里使用非参数传入的外部函数的变量,将使用到该变量在外部函数生命周期内最终的值。
接口
一组方法签名的集合。其存在静态类型(绑定的实例的类型)动态类型(方法签名)。
注:类型指针接受者实现接口,类型自身不可进行初始化接口。
类型自身实现接口,类型自身和类型指针均可初始化接口,且因为在调用方法时会对接受者进行复制,所以推荐指针接受者实现接口。
数据结构
//src/runtime/runtime2.go //非空接口 type iface struct { tab *itab // 用来存放接口自身类型和绑定的实例类型及实例相关的函数指针 data unsafe.Pointer // 数据 } type itab struct { inter *interfacetype // 接口自身静态类型 _type *_type // 数据类型 hash uint32 // copy of _type.hash. Used for type switches. _ [4]byte fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter. } //空接口 type eface struct { _type *_type //数据类型信息 data unsafe.Pointer //数据 } // 类型信息 type _type struct { size uintptr // 类型占用的内存空间 ptrdata uintptr // size of memory prefix holding all pointers hash uint32 // 用于判断类型是否相等 tflag tflag align uint8 fieldAlign uint8 kind uint8 equal func(unsafe.Pointer, unsafe.Pointer) bool gcdata *byte str nameOff ptrToThis typeOff }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
反射
反射是指在程序运行期对程序本身进行访问和修改的能力
reflect.TypeOf //能获取类型信息;
reflect.ValueOf //能获取数据的运行时表示;
- 1
- 2
三大法则
//第一法则:反射可以将接口类型变量转换为反射对象 /* 有了变量的类型之后,我们可以通过 Method 方法获得类型实现的方法,通过 Field 获取类型包含的全部字段。 对于不同的类型,我们也可以调用不同的方法获取相关信息: 结构体:获取字段的数量并通过下标和字段名获取字段 StructField; 哈希表:获取哈希表的 Key 类型; 函数或方法:获取入参和返回值的类型; … */ var x int64 = 4 fmt.Println(reflect.TypeOf(x), reflect.ValueOf(x)) //第二法则:反射可以把反射对象还原为接口对象 /* 不过调用 reflect.Value.Interface 方法只能获得 interface{} 类型的变量, 如果想要将其还原成最原始的状态还需要经过如下所示的显式类型转换: v := reflect.ValueOf(1) v.Interface().(int) 当然不是所有的变量都需要类型转换这一过程。 如果变量本身就是 interface{} 类型的,那么它不需要类型转换, 因为类型转换这一过程一般都是隐式的,所以我不太需要关心它,只有在我们需要将反射对象转换回基本类型时才需要显式的转换操作。 */ var a interface{} = 4.0 v := reflect.ValueOf(a) //反射对象 b := v.Interface() //接口对象 fmt.Println(a == b) fmt.Println(reflect.TypeOf(a), reflect.TypeOf(b)) //第三法则:反射对象可修改,value值必须是可设置的 /* func main() { i := 1 v := reflect.ValueOf(i) v.SetInt(10) fmt.Println(i) } $ go run reflect.go panic: reflect: reflect.flag.mustBeAssignable using unaddressable value 由于 Go 语言的函数调用都是传值的,所以我们得到的反射对象跟最开始的变量没有任何关系,那么直接修改反射对象无法改变原始变量,程序为了防止错误就会崩溃。 想要修改原变量只能使用如下的方法: */ i := 1 v = reflect.ValueOf(&i) v.Elem().SetInt(20) //必须是通过目标的指针对其修改 fmt.Println(i)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
当我们想要将一个变量转换成反射对象时,Go 语言会在编译期间完成类型转换,将变量的类型和值转换成了 interface{} 并等待运行期间使用 reflect 包获取接口中存储的信息。
更新变量
/* 当我们想要更新 reflect.Value 时,就需要调用 reflect.Value.Set 更新反射对象, 该方法会调用 reflect.flag.mustBeAssignable 和 reflect.flag.mustBeExported 分别检查当前反射对象是否是可以被设置的以及字段是否是对外公开的: func (v Value) Set(x Value) { v.mustBeAssignable() //是否可以被设置 即必须是一个指针所指向的 x.mustBeExported() //是否对外公开 var target unsafe.Pointer if v.kind() == Interface { target = v.ptr } x = x.assignTo("reflect.Set", v.typ, target) typedmemmove(v.typ, v.ptr, x.ptr) } */ fmt.Println("更新变量======") x := 3 v := reflect.ValueOf(&x) v.Elem().Set(reflect.ValueOf(4)) fmt.Println("更新结构体并获取未导出字段值") test1 := &test{test: 1} vtest := reflect.ValueOf(test1) vtest.Elem().Set(reflect.ValueOf(test{test: 2})) fmt.Println(vtest.Elem().FieldByName("test").Int())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
函数调用
//函数调用 /* 1.通过 reflect.ValueOf 获取函数 Add 对应的反射对象; 2.调用 reflect.rtype.NumIn 获取函数的入参个数; 3.多次调用 reflect.ValueOf 函数逐一设置 argv 数组中的各个参数; 4.调用反射对象 Add 的 reflect.Value.Call 方法并传入参数列表; 5.获取返回值数组、验证数组的长度以及类型并打印其中的数据; */ v := reflect.ValueOf(Add) //反射对象 if v.Kind() != reflect.Func { return } t := v.Type() argv := make([]reflect.Value, t.NumIn()) //入参个数 for i := range argv { if t.In(i).Kind() != reflect.Int { return } argv[i] = reflect.ValueOf(i) //填充参数 } result := v.Call(argv) //调用方法 if len(result) != 1 || result[0].Kind() != reflect.Int { return } fmt.Println(result[0].Int()) // #=> 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
获取匿名字段
func NiM(boy Boy) {
t := reflect.TypeOf(boy)
v := reflect.ValueOf(boy)
fmt.Println(t, v)
// Anonymous:匿名
for i := 0; i < t.NumField(); i++ {
fmt.Println(t.Field(i))
// 值信息
fmt.Println(v.Field(i))
}
fmt.Println(t.FieldByName("private"))
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
设置字段值
func SetValue(o interface{}) { v := reflect.ValueOf(o) newUser := User{ Id: 19, Name: "raja", Age: 19, } // 设置值 v.Elem().Set(reflect.ValueOf(newUser)) fmt.Println(v.Elem()) // 获取指针指向的元素 v = v.Elem() // 取字段 f := v.FieldByName("Name") if f.Kind() == reflect.String { f.SetString("Name") } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
调用方法
func CallFunc(o interface{}) { v := reflect.ValueOf(o) // 获取方法 导出 // fmt.Println(v.MethodByName("hello")) m := v.MethodByName("Hello") t := m.Type() // 构建参数 args := make([]reflect.Value, t.NumIn()) for i := 0; i < len(args); i++ { if t.In(i).Kind() != reflect.String { fmt.Println("Kind Err!") return } args[i] = reflect.ValueOf(strconv.Itoa(i)) } m.Call(args) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
获取标签
func GetTag(o interface{}) {
v := reflect.ValueOf(o)
t := v.Type()
f := t.Field(0)
fmt.Println(f.Tag.Get("json"))
}
- 1
- 2
- 3
- 4
- 5
- 6
泛型 Go1.18+
当你需要针对不同类型书写同样的逻辑,使用泛型来简化代码是最好的
通过引入 类型形参 和 类型实参 这两个概念,我们让一个函数获得了处理多种不同类型数据的能力,这种编程方式被称为 泛型编程。
泛型类型
类型定义中带 类型形参 的类型,称之为 泛型类型(Generic type)
type Slice[T int | float32 | float64] []T
T就是上面介绍过的类型形参(Type parameter),在定义Slice类型的时候T代表的具体类型并不确定,类似一个占位符int|float32|float64这部分被称为类型约束(Type constraint),中间的 | 的意思是告诉编译器,类型形参 T 只可以接收 int 或 float32 或 float64 这三种类型的实参- 中括号里的
T int|float32|float64这一整串因为定义了所有的类型形参(在这个例子里只有一个类型形参 T),所以我们称其为 类型形参列表(type parameter list) - 这里新定义的类型名称叫 Slice[T]
type MyMap[KEY int | string, VALUE float32 | float64] map[KEY]VALUE
其他泛型类型
// 泛型结构体
type MyStruct[T int | float32 | string] struct {
Name string
Data T
}
// 泛型接口
type IPrintData[T int | float32 | string] interface {
Print(data T)
}
// 泛型类型
type MyChan[T int | string] chan T
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
类型实参的相互套用
type WowStruct[T int | float32, S []T] struct {
Data S
MaxValue T
MinValue T
}
ws := WowStruct[float32, []float32]{
Data: []float32{1.1, 2.2},
MaxValue: 2.2,
MinValue: 1.1,
}
fmt.Printf("type of ws:%T\n", ws)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
泛型类型中的语法错误
- 定义泛型类型时,基础类型不能只有类型形参
type CommonType[T int | string | float64] T 错误
- 当类型约束的一些写法会被编译器误认为是表达式时会报错。
type NewT[T *int] []T //T *int会被编译器误认为是表达式 T乘以int,而不是int指针
type NewType2[T *int|*float64] []T // 和上面一样,这里不光*被会认为是乘号,| 还会被认为是按位或操作
type NewType3 [T (int)] []T
- 1
- 2
- 3
为了避免这种误解,解决办法就是给类型约束包上 interface{} 或 加上逗号 消除歧义
type NewT1[T interface{ *int | *float32 }] []T
type NewT2[T *int,] []T
type NewT3[T *int | *float32,] []T
- 1
- 2
- 3
泛型类型的套娃
// Slice 先定义个泛型类型 Slice[T] type Slice[T int | string | float32 | float64] []T // UintSlice ✗ 错误。泛型类型Slice[T]的类型约束中不包含uint, uint8 // type UintSlice[T uint | uint8] Slice[T] // FloatSlice ✓ 正确。基于泛型类型Slice[T]定义了新的泛型类型 FloatSlice[T] 。FloatSlice[T]只接受float32和float64两种类型 type FloatSlice[T float32 | float64] Slice[T] // IntAndStringSlice ✓ 正确。基于泛型类型Slice[T]定义的新泛型类型 IntAndStringSlice[T] type IntAndStringSlice[T int | string] Slice[T] // IntSlice ✓ 正确 基于IntAndStringSlice[T]套娃定义出的新泛型类型 type IntSlice[T int] IntAndStringSlice[T] // WowMap 在map中套一个泛型类型Slice[T] type WowMap[T int | string] map[string]Slice[T] // WowMap2 在map中套Slice[T]的另一种写法 type WowMap2[T Slice[int] | Slice[string]] map[string]T
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
匿名结构体不支持泛型
// 错误:
testCase := struct[T int|string] {
caseName string
got T
want T
}[int]{
caseName: "test OK",
got: 100,
want: 100,
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
泛型类型接收者
type MySlice[T int | float32] []T
func (s MySlice[T]) Sum() (sum T) {
for _, v := range s {
sum += v
}
return
}
var s MySlice[int] = []int{1, 2, 3, 4}
fmt.Println(s.Sum())
var s2 MySlice[float32] = []float32{1.1, 2.2, 3.3, 4.4, 5.5}
fmt.Println(s2.Sum())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
使用类型断言动态判断变量的类型
func (s Slice1[T]) Switch() {
for _, v := range s {
t := reflect.TypeOf(v)
switch t.Kind() {
case reflect.<em>Int</em>:
fmt.Println("Int")
case reflect.<em>Float32</em>, reflect.<em>Float64</em>:
fmt.Println("Float")
default:
fmt.Println("I Dont Know")
}
return
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
泛型函数
func Add[T int | float32 | float64](a, b T) T {
return a + b
}
- 1
- 2
- 3
匿名函数不支持泛型
// 错误:
fnGeneric := func[T int | float32](a, b T) T {
return a + b
}
- 1
- 2
- 3
- 4
不支持泛型方法
// 错误:
func (receiver A) Add[T int | float32 | float64](a T, b T) T {
return a + b
}
- 1
- 2
- 3
- 4
但是可以使用泛型类型接收者来曲线救国
type A[T int | float32 | float64] struct {
}
func (receiver A[T]) Add(a, b T) T {
return a + b
}
- 1
- 2
- 3
- 4
- 5
- 6
类型约束
type Int interface { ~int | ~int8 | ~int16 | ~int32 | ~int64 } type Uint interface { ~uint | ~uint8 | ~uint16 | ~uint32 } type Float interface { ~float32 | ~float64 } type SliceElement interface { Int | Uint | Float | ~string // 组合了三个接口类型并额外增加了一个 string 类型 } type IntUintFloatSlice[T SliceElement] []T // 使用 '|' 将多个接口类型组合
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
~ 指定底层类型
使用 ~ 时有一定的限制:
~ 后面的类型不能为接口
~ 后面的类型必须为基本类型
类型交集
type AllInt interface {
Int | Uint
}
type AllUInt interface { // 接口代表的类型集是 AllInt 和 Uint 的交集
AllInt
Uint
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
接口的两种类型
基本接口
接口定义中如果只有方法的话,那么这种接口被称为基本接口。
基本接口因为也代表了一个类型集,所以也可用在类型约束中。
type MyErr interface {
Err()
}
- 1
- 2
- 3
一般接口
如果接口内不光只有方法,还有类型的话,这种接口被称为 一般接口(General interface)
一般接口类型不能用来定义变量,只能用于泛型的类型约束中
// 接口类型 ReadWriter 代表了一个类型集合,所有以 string 或 []rune 为底层类型,并且实现了 Read() Write() // 这两个方法的类型都在 ReadWriter 代表的类型集当中 type ReadWriter interface { ~string | ~[]rune Print() } // 实现了ReadWriter 一般接口 type StringReadWriter string func (s StringReadWriter) Print() { fmt.Print("StringReadWriter:", s) } // 因为类型不匹配,所以没有实现接口 type BytesReadWriter []byte func (s BytesReadWriter) Print() { fmt.Print("StringReadWriter:", s) } type MySlice[T ReadWriter] []T var s MySlice[StringReadWriter] = []StringReadWriter{"1", "2", "3"} for _, v := range s { v.Print() } // 类型和方法没有完全匹配 // var s2 MySlice[BytesReadWriter] = []BytesReadWriter{{'1', '2', '3'}, {'2', '3', '4'}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
泛型接口
type DataProcessor[T any] interface { Process(oriData T) (newData T) Save(data T) error } type DataProcessor2[T any] interface { int | ~struct{ Data any } DataProcessor[T] } type CSVProcessor struct{} func (c CSVProcessor) Process(oriData string) string { return "" } func (c CSVProcessor) Save(oriData string) error { return nil } // 错误。DataProcessor2[string]是一般接口不能用于创建变量 var processor DataProcessor2[string] // 正确,实例化之后的 DataProcessor2[string] 可用于泛型的类型约束 type ProcessorList[T DataProcessor2[string]] []T // 正确,接口可以并入其他接口 type StringProcessor interface { DataProcessor2[string] PrintString() } // 错误,带方法的一般接口不能作为类型并集的成员(参考6.5 接口定义的种种限制规则 type StringProcessor interface { DataProcessor2[string] | DataProcessor2[[]byte] PrintString() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
接口定义的限制规则
- 用
|连接多个类型的时候,类型之间不能有相交的部分(即必须是不交集):
type MyInt int
// 错误,MyInt的底层类型是int,和 ~int 有相交的部分
type _ interface {
~int | MyInt
}
- 1
- 2
- 3
- 4
- 5
- 6
但是相交的类型中是接口的话,则不受这一限制:
type MyInt int
type _ interface {
~int | interface{ MyInt } // 正确
}
type _ interface {
interface{ ~int } | MyInt // 也正确
}
type _ interface {
interface{ ~int } | interface{ MyInt } // 也正确
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 类型的并集中不能有类型形参
type MyInf[T ~int | ~string] interface {
~float32 | T // 错误。T是类型形参
}
type MyInf2[T ~int | ~string] interface {
T // 错误
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 接口不能直接或间接地并入自己
type Bad interface {
Bad // 错误,接口不能直接并入自己
}
type Bad2 interface {
Bad1
}
type Bad1 interface {
Bad2 // 错误,接口Bad1通过Bad2间接并入了自己
}
type Bad3 interface {
~int | ~string | Bad3 // 错误,通过类型的并集并入了自己
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 接口的并集成员个数大于一的时候不能直接或间接并入
comparable接口
type OK interface { comparable // 正确。只有一个类型的时候可以使用 comparable } type Bad1 interface { []int | comparable // 错误,类型并集不能直接并入 comparable 接口 } type CmpInf interface { comparable } type Bad2 interface { chan int | CmpInf // 错误,类型并集通过 CmpInf 间接并入了comparable } type Bad3 interface { chan int | interface{comparable} // 理所当然,这样也是不行的 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 带方法的接口(无论是基本接口还是一般接口),都不能写入接口的并集中
type _ interface { ~int | ~string | error // 错误,error是带方法的接口(一般接口) 不能写入并集中 } type DataProcessor[T any] interface { ~string | ~[]byte Process(data T) (newData T) Save(data T) error } // 错误,实例化之后的 DataProcessor[string] 是带方法的一般接口,不能写入类型并集 type _ interface { ~int | ~string | DataProcessor[string] } type Bad[T any] interface { ~int | ~string | DataProcessor[T] // 也不行 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
泛型的加入,无疑增加了复杂度。我个人认为,能不用泛型就不用泛型。在演讲中,两位大佬提到,在以下场景可以考虑使用泛型:
- 对于 slice、map、channel 等类型,如果它们的元素类型是不确定的,操作这类类型的函数可以考虑用泛型
- 一些通用目的的数据结构,比如前面提到的二叉树等
- 如果一些函数行为相同,只是类型不同,可以考虑用泛型重构
注意,目前 Go 方法不支持类型参数,所以,如果方法有需要泛型的场景,可以转为函数的形式。
常见关键字
for range
使用 for range 最终都会转换为普通的 for 循环
现象
- 遍历数组时同时修改数组的元素(追加),不会造成无限循环
func testSliceRange() {
nums := []int{1, 2, 3, 4}
for i := range nums {
nums = append(nums, 1)
fmt.Println(nums[i])
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
for _,v := range nums的v是同一个变量- 遍历清空数组,切片,哈希表这些地址连续的结构时会直接选择清空这一片的内容
- 使用
for range遍历map时被引入随机性,强调不要依赖map的遍历顺序
循环结构
// 经典循环
for Ninit ; Left ; Right {
NBody
}
- 1
- 2
- 3
- 4
编译器会在编译期间把所有 for range 转换为经典循环。
数组和切片
- 遍历数组或者切片清空元素
直接调用 runtime.memclrNoHeapPointers 清空全部数据并更新遍历数组的索引
for range a {}直接转换为下列形式
ha := a // 复制数组
hv1 := 0
hn := len(ha) // 获取长度
v1 := hv1
for ; hv1 < hn; hv1++ {
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
for i := range a {}在循环体中添加了v1 = hv1语句,传递遍历数组时的索引
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
v1 = hv1
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
for i,v := range a {}循环使用v变量
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1 // 下标
v2 := nil // 值
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 = hv1, tmp
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
哈希表
编译器会根据 range 返回值的数量在循环体中插入需要的赋值语句:
ha := a
hit := hiter(n.Type)
th := hit.Type
mapiterinit(typename(t), ha, &hit)
for ; hit.key != nil; mapiternext(&hit) {
key := *hit.key
val := *hit.val
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
遍历方式:随机选一个起始桶,遍历桶中元素,再遍历溢出桶,再遍历下一个桶,直到回到最开始。
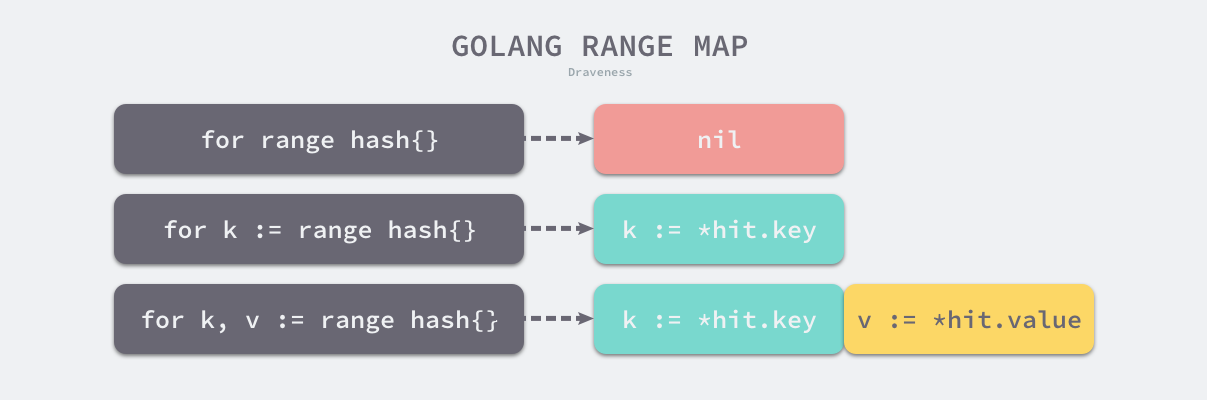
注意:hash 表的遍历时插入是随机的,不保证是否会被遍历到。
字符串
遍历时会获取字符串的索引对应字节转换为 rune 类型,并更新索引。
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
if hv2 < utf8.RuneSelf { // ascii
hv1++
} else {
hv2, hv1 = decoderune(ha, hv1) // unicode
}
v1, v2 = hv1t, hv2
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
channel
for v := range ch {} 会被转换为下列,(channel 关闭了会结束,没数据会阻塞)
ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha { // 会判断是否close
v1 := hv1
hv1 = nil
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
select
现象
- 非阻塞收发操作
如果存在可收发的 channel 时会直接处理该 channel 对应的操作
如果不存在上述情况,且存在 default 则执行 default 语句
- 多个 channel 同时响应会随机选一个执行
为了避免饥饿问题发生
实现原理
select 类似一个函数,输入 cases 节点切片,选择一个节点,返回索引和查询结果。
编译器会根据 select 中 case 的不同做出不同优化
- 空
select
直接调用 runtime.block() 阻塞
select中只有一个case
转换为 if 语句,如果 chan 为 nil 则直接阻塞
if ch == nil { // nil 直接阻塞
block()
}
v, ok := <-ch // case ch <- v
- 1
- 2
- 3
- 4
select存在两个case,其中一个case是default
非阻塞接发消息。
select存在多个case- 编译期间将所有的
case转换成包含Channel以及类型等信息的 scase 结构体并展开select为selectgo。 - 通过
selectgo从多个就绪的channel中返回一个可执行的channel返回对应的case索引
type scase struct {
c *hchan //操作的chan
elem unsafe.Pointer //读取或者写入的数据
}
- 1
- 2
- 3
- 4
selectgo 函数:初始化(确认加锁和轮训顺序),循环(查找就绪 Channel,没有就绪的就写入收发队列并阻塞,唤醒后找到对应 channel)
- 随机生成一个遍历的轮询顺序
pollOrder(防止饥饿)并根据 Channel 地址排序生成锁定顺序lockOrder(排序去重,防止重复加锁);
注意如果尝试写入数据到已经关闭的 channel 则会 panic
- 根据
pollOrder遍历所有的case查看是否有可以立刻处理的 Channel;
1. 如果存在,直接获取 `case` 对应的索引并返回,解锁所有channel;
1. 如何不存在,但存在`default`,解锁并返回。
1. 如果不存在,则将当前go程加入到所有`channel`的收发队列<strong>并等待唤醒</strong>
- 1
- 2
- 3
- 4
- 5
- 当调度器唤醒当前 Goroutine 时,会再次按照
lockOrder遍历所有的case,从中对比找到需要被处理的case的索引。
Defer
延迟调用:使用 defer 的最常见场景是在函数调用结束后完成一些收尾工作,例如在 defer 中回滚数据库的事务或者文件描述符的关闭。
规则
- 作用域:向 defer 关键字传入的函数会在函数返回之前按照栈的顺序执行。
定义 defer 类似于入栈操作,执行 defer 类似于出栈操作。
- 预计算参数:延迟函数的参数在 defer 语句出现时就已经确定下来了
func deferFuncParameter() {
var aInt = 1
defer fmt.Println(aInt)
aInt = 2
return
}
// output: 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 延迟函数可能操作主函数的具名返回值
func deferFuncReturn() (ret int) {
i := 1
defer func() {
result++
}()
return i
}
// output: 2
// ret = i ; defer ; return
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
数据结构
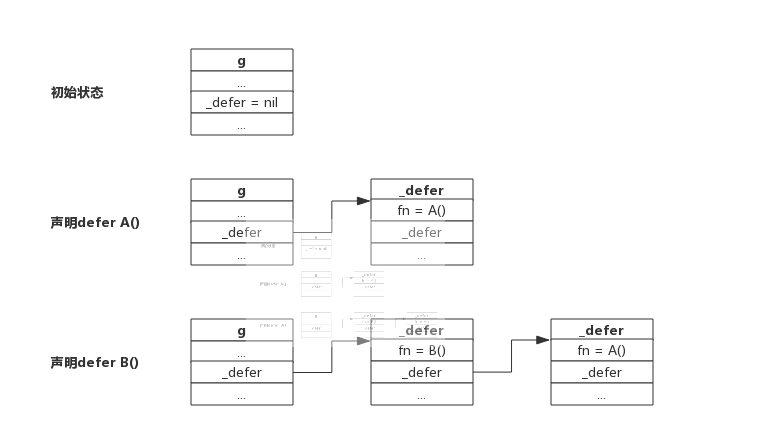
所有 defer 结构体都通过 link 串联成一个链表
type _defer struct {
siz int32 // 参数和结果的内存大小
openDefer bool // 表示当前 defer 是否经过开放编码的优化;
sp uintptr // 函数栈指针
pc uintptr // 程序计数器
fn *funcval // 函数地址
_panic *_panic // 是触发延迟调用的结构体,可能为空
link *_defer // 指向自身结构的指针,用于链接多个defer
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

根据条件不同,存在三种机制处理 defer
堆中分配 [兜底方案] 1.1 ~ 1.12,
- 编译期将
defer关键字转换成 deferproc 函数并在调用defer关键字的函数返回之前插入 deferreturn函数; - 运行时调用 deferproc 会将一个新的 defer 结构体追加到当前
Goroutine的链表头; - 运行时调用 deferreturn 会从
Goroutine的链表中取出 _defer 结构并依次执行;
栈中分配 [函数中出现最多一次] 1.13
编译器会将 runtime._defer 分配到栈上
开放编码 [defer <= 8,return * defer <=15] 1.14
使用代码内联优化 defer 关键字.
- 编译期间判断
defer(<8)和return数量来确定是否开启代码优化。 - 编译期间在栈上创建
8bit的延迟比特数组。每一位表示对应的 defer 是否需要被执行。 - 执行:如果
defer的执行可以在编译时确定则直接插入到返回语句前,否则在运行中通过 deferreturn 和延迟比特判断。
panic 和 recover
panic能够改变程序的控制流,调用panic后会立刻停止执行当前函数的剩余代码,并在当前 Goroutine 中递归执行调用方的defer;recover可以中止panic造成的程序崩溃。它是一个只能在defer中发挥作用的函数,在其他作用域中调用不会发挥作用;
现象
- 跨协程失败
panic 只会触发当前函数的 延迟调用,如果没有被捕获,最后结束程序。
- 无效的崩溃恢复
recover 必须在 defer 中使用才可以捕获后续的 panic
- 嵌套崩溃
可以在 defer 中 panic,但可以被 recovery 捕获。
make 和 new
make 初始化内置的数据结构,chan,map,slice 。
slice:指定len(必填)和cap。map:预估数据容量大小chan:缓冲区大小
new 只接受一个参数,这个参数是一个类型,分配好内存后,返回一个指向该类型内存地址的指针。同时请注意它同时把分配的内存置为零,也就是类型的零值。
都会先进行逃逸分析,然后再进行内存分配。
并发编程
Goroutine
线程和协程的区别
- 对于 进程、线程,都是有内核进行调度,有 CPU 时间片的概念,进行 抢占式调度(有多种调度算法)
- 对于 协程(用户级线程),这是对内核透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的,因为是由用户程序自己控制,那么就很难像抢占式调度那样做到强制的 CPU 控制权切换到其他进程/线程,通常只能进行 协作式调度,需要协程自己主动把控制权转让出去之后,其他协程才能被执行到。
goroutine 和协程区别
- 本质上,goroutine 就是协程。 对 goroutine 调度进行了封装和处理,当遇到长时间执行或者进行系统调用时,会主动把当前 goroutine 的 CPU § 转让出去,让其他 goroutine 能被调度并执行,也就是 Golang 从语言层面支持了协程。
- Go 的一大特色就是从语言层面原生支持协程,在函数或者方法前面加 go 关键字就可创建一个协程。
其他方面的比较
内存消耗方面
每个 goroutine (协程) 默认占用内存远比 Java 、C 的线程少。
- goroutine:2KB
- 线程:8MB
切换调度开销方面
goroutine 远比线程小
- 线程:涉及模式切换(从用户态切换到内核态)、16 个寄存器、PC、SP…等寄存器的刷新等。
- goroutine:只有三个寄存器的值修改 - PC / SP / DX.
乐观锁,悲观锁
存在共享资源 X 需要被多个线程修改:
- 取值
- 修改
- 写入
悲观锁
每次操作都先获取锁,操作完再释放锁。
乐观锁
前两步正常进行,第三步完了再判断下是否进行了修改,修改了就重新走一遍或者放弃。
atomic 可以在不形成临界区和创建互斥量的情况下完成并发安全的值替换操作。
CAS
CAS用来确保在乐观锁下对某一共享变量的操作没有被其他线程修改过。
CAS(V,A,B):内存位置(V)、预期原值(A)和新值 (B),如果内存地址里面的值和 A 的值是一样的,那么就将内存里面的值更新成 B。CAS 是通过无限循环来获取数据的,如果在第一轮循环中,a 线程获取地址里面的值被 b 线程修改了,那么 a 线程需要自旋,到下次循环才有可能机会执行。
问题:
- 自旋锁:可能造成开销大
- ABA:需要每次更新版本号来确保中途变量没有被修改
type value struct { v interface{} // 实际值 stamp int64 // 版本号 } func (v *value) Value() interface{} { return v.v } func (a *ABA) Load() *value { v := a.value.Load().(*value) return v } func (a *ABA) Store(t interface{}) { v, ok := a.value.Load().(*value) p := &value{v: t} if ok { p.stamp = v.stamp + 1 } a.value.Store(p) } func (a *ABA) CompareAndSwap(old *value, new interface{}) bool { newOne := &value{v: new, stamp: old.stamp + 1} return a.value.CompareAndSwap(old, newOne) // 比较旧版本号是否被改变 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
死锁
发生的必要条件,打破任意一个即可。
- 互斥:解决临界区安全(不考虑破坏)。
- 请求保持:一个进程因请求资源而阻塞时,对已占有的资源不释放。
- 不可抢占:进程已获得的资源,在未使用之前,不能强行剥夺(抢夺资源)。
- 循环等待:若干进程之间形成一种头尾相接的循环等待的资源关闭(死循环)。
解决方法:
- 请求保持:所有的进程在开始运行之前,必须一次性的申请其在整个运行过程各种所需要的全部资源。
- 不可抢占:当持有一定资源的线程在无法申请到新的资源时必须释放已有的资源,待以后需要使用的时候再重新申请
- 循环等待:规定资源的申请顺序
并发哲学
CSP 通信顺序进程(在进程之间正确通信)作为 Go 的核心思想之一,让并发程序更容易被编写和理解。
通过通信来共享内存,而不是通过共享内存来通信
mutex 和 channel 的选择

atomic
基本操作
// TSL // // old = *addr // *addr = new // return old func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) // FAA // // *addr += delta // return *addr func AddInt32(addr *int32, delta int32) (new int32) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) // CAS // // if *addr == old { // *addr = new // return true // } // return false func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) // Read func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64) func LoadUint32(addr *uint32) (val uint32) func LoadUint64(addr *uint64) (val uint64) func LoadUintptr(addr *uintptr) (val uintptr) func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) // Write func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintptr, val uintptr) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) // https://juejin.cn/post/6907091130039894023
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
atomic.Value
内部第一次通过禁用调度器并通过 CAS 来存储值和类型,否则通过原子操作存储值。
// 零值为nil 使用后不允许被拷贝 type Value struct { v interface{} // ifaceWords } type ifaceWords struct { // 类型 typ unsafe.Pointer // 值 data unsafe.Pointer } // 不能存 nil,存一次后类型就固定了 func (v *Value) Store(val interface{}) { if val == nil { panic("sync/atomic: store of nil value into Value") } vp := (*ifaceWords)(unsafe.Pointer(v)) vlp := (*ifaceWords)(unsafe.Pointer(&val)) // 抢占乐观锁 for { typ := LoadPointer(&vp.typ) if typ == nil { // 禁止当前 P 被抢占 runtime_procPin() // 调用CAS抢占乐观锁,没抢到就继续 if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(^uintptr(0))) { runtime_procUnpin() continue } // 存储值和类型 // Complete first store. StorePointer(&vp.data, vlp.data) StorePointer(&vp.typ, vlp.typ) runtime_procUnpin() return } // 判断是否还在抢占乐观锁 if uintptr(typ) == ^uintptr(0) { continue } // First store completed. Check type and overwrite data. if typ != vlp.typ { panic("sync/atomic: store of inconsistently typed value into Value") } // 只需要存值就系 StorePointer(&vp.data, vlp.data) return } } func (v *Value) Load() (val interface{}) { vp := (*ifaceWords)(unsafe.Pointer(v)) typ := LoadPointer(&vp.typ) if typ == nil || uintptr(typ) == ^uintptr(0) { // First store not yet completed. return nil } data := LoadPointer(&vp.data) vlp := (*ifaceWords)(unsafe.Pointer(&val)) vlp.typ = typ vlp.data = data return }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
context
在 go 程构建的树形结构中同步信号来减少计算资源浪费。
建议直接看这个《go 专家编程》context 实现
Context
type Context interface {
Deadline() (deadline time.Time, ok bool) // 返回 context.Context 被取消的时间,也就是完成工作的截止日期;
Done() <-chan struct{} // nnel
Err() error // 返回 context.Context 结束的原因,它只会在 Done 方法对应的 Channel 关闭时返回非空的值;
// 如果 context.Context 被取消,会返回 Canceled 错误;
// 如果 context.Context 超时,会返回 DeadlineExceeded 错误;
Value(key interface{}) interface{} // 用于父子上下文之间传递数据
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
emptyCtx 只是一个实现了 Context 的结构,可以作为所有 context 的根节点
type emptyCtx int
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
- 1
- 2
- 3
- 4
- 5
- 6
context 包中实现 Context 接口的 emptyCtx,除了 emptyCtx 外,还有 cancelCtx、timerCtx 和 valueCtx 三种,正是基于这三种 context 实例,实现了上述 4 种类型的 context。
cancelCtx
type cancelCtx struct {
Context
mu sync.Mutex // protects following fields
done atomic.Value // of chan struct{}, created lazily, closed by first cancel call
children map[canceler]struct{} // set to nil by the first cancel call
err error // set to non-nil by the first cancel call
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Done()返回errchan
func (c *cancelCtx) Done() <-chan struct{} {
d := c.done.Load()
if d != nil {
return d.(chan struct{})
}
c.mu.Lock()
defer c.mu.Unlock()
d = c.done.Load()
if d == nil {
d = make(chan struct{}) // 懒汉模式创建
c.done.Store(d)
}
return d.(chan struct{})
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Err()返回错误
func (c *cancelCtx) Err() error {
c.mu.Lock()
err := c.err
c.mu.Unlock()
return err
}
- 1
- 2
- 3
- 4
- 5
- 6
cancel ()取消当前上下文- 判断是否取消
ctx - 关闭通知
channel cancel下游- 删除下游节点
- 把自己从上游移除
func (c *cancelCtx) cancel(removeFromParent bool, err error) { if err == nil { panic("context: internal error: missing cancel error") } c.mu.Lock() // 判断是否取消 if c.err != nil { c.mu.Unlock() return // already canceled } c.err = err // 关闭channel d, _ := c.done.Load().(chan struct{}) if d == nil { c.done.Store(closedchan) // 放入关闭的channel } else { close(d) // 关闭channel } // cancel下游 for child := range c.children { // NOTE: acquiring the child's lock while holding parent's lock. child.cancel(false, err) } // 删除下游节点 c.children = nil c.mu.Unlock() // 把自己从上游移除 if removeFromParent { removeChild(c.Context, c) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
WithCancel()
主动调用 Cancel() 会从父节点移除
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
if parent == nil {
panic("cannot create context from nil parent")
}
c := newCancelCtx(parent) // 初始化cancel实例
propagateCancel(parent, &c) // 将 cancelCtx 实例添加到其父节点的 children 中 (如果父节点也可以被 cancel 的话)
return &c, func() { c.cancel(true, Canceled) } // 返回 cancelCtx 实例和 cancel () 方法
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
timerCtx
timerCtx 在 cancelCtx 基础上增加了 deadline 用于标示自动 cancel 的最终时间,而 timer 就是一个触发自动 cancel 的定时器。
由此,衍生出 WithDeadline () 和 WithTimeout ()。这两种类型实现原理一样,后者构造前者:
- deadline: 指定最后期限,比如
context将2018.10.20 00:00:00之时自动结束 - timeout: 指定最长存活时间,比如 context 将在 30s 后结束,和上面差不多。
type timerCtx struct {
cancelCtx
timer *time.Timer // 单次定时器
deadline time.Time
}
- 1
- 2
- 3
- 4
- 5
cancel()
和 cancelCtx 差不多,但是最后需要停止 timer
func (c *timerCtx) cancel(removeFromParent bool, err error) {
c.cancelCtx.cancel(false, err)
if removeFromParent {
removeChild(c.cancelCtx.Context, c)
}
c.mu.Lock()
if c.timer != nil {
c.timer.Stop()
c.timer = nil
}
c.mu.Unlock()
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
WithTimeout()
- 判断当前截止日期是否比新的早
- 初始化一个
timerCtx实例 - 将
timerCtx实例添加到其父节点的children中 (如果父节点也可以被cancel的话) - 启动定时器,定时器到期后会自动 cancel 本 context,然后从父节点删除
- 返回
timerCtx和cancel ()方法
valueCtx
valueCtx 只是在 Context 基础上增加了一个 key-value 对,用于 在各级协程间 传递一些数据。
由于 valueCtx 既不需要 cancel,也不需要 deadline,那么只需要实现 Value () 接口即可。
WithValue()
func WithValue(parent Context, key, val interface{}) Context {
if parent == nil {
panic("cannot create context from nil parent")
}
if key == nil {
panic("nil key")
}
if !reflectlite.TypeOf(key).Comparable() {
panic("key is not comparable")
}
return &valueCtx{parent, key, val}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Value()
当前 ctx 没有则去 上游ctx 寻找
func (c *valueCtx) Value(key interface{}) interface{} {
if c.key == key {
return c.val
}
return c.Context.Value(key)
}
- 1
- 2
- 3
- 4
- 5
- 6
同步原语和锁(SYNC)
互斥锁
数据结构
type Mutex struct {
state int32 //互斥锁的状态
sema uint32 //信号量
}
- 1
- 2
- 3
- 4
waiter(29)阻塞协程数starving(是否饥饿)woken(是否有协程被唤醒)locked(是否被锁定)
加锁
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
CAS尝试将locked=1加锁成功- 否则判断是否可以
自旋 - 可以自旋就将
woken置为1,然后空转尝试获取锁 - 否则就直接阻塞等待被唤醒
解锁
func (m *Mutex) Unlock() {
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// Outlined slow path to allow inlining the fast path.
// To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock.
m.unlockSlow(new)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
饥饿模式下会直接把锁给下一个等待者普通模式下如果没有等待的协程,就选择唤醒等待者(有的话)或者直接返回
自旋
- 好处
更充分的利用 CPU,尽量避免协程切换
- 自旋条件;
- 多 CPU
- 当前协程为了获取此锁进入自旋数量
<4 - 当前机器上
至少存在一个正在运行的处理器P且其运行队列为空
总结:当 CPU 闲着的时候可以让它忙一下。
饥饿模式
当自旋的协程每次都抢到锁,为了防止正常阻塞的等待锁的协程不被饿死,当协程等待时间超过 1ms 时就会启动饥饿模式,处于饥饿模式下,不会启动自旋过程,也即一旦有协程释放了锁,那么一定会唤醒协程,被唤醒的协程将会成功获取锁,同时也会把等待计数减 1。
如果 当前协程是最后一个协程 或者 等待时间小于1ms 就 恢复为普通模式
读写锁
数据结构
type RWMutex struct {
w Mutex // held if there are pending writers
writerSem uint32 // 写阻塞等待的信号量,最后一个读协程释放锁后会释放
readerSem uint32 // 读阻塞等待的信号量,持有写锁的协程释放锁后会释放
readerCount int32 // 正在读协程的个数
readerWait int32 // 写阻塞时读协程的个数
}
const rwmutexMaxReaders = 1 << 30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
writerSem:写阻塞等待的信号量,最后一个读协程释放锁后会释放readerSem:读阻塞等待的信号量,持有写锁的协程释放锁后会释放readerCount:正在读协程的个数,用于阻塞读者readerWait:阻塞写的读协程的个数,用于读解锁时唤醒写协程
写锁
先将 readerCount 变为负值阻止之后的读然后等待现有的读结束。同时将当前的读数量记录到 readerWait
func (rw *RWMutex) Lock() {
// First, resolve competition with other writers.
rw.w.Lock()
// 通过将readerCount变为负值,阻塞后续访问的reader
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
// 记录当前reader的数量,然后阻塞
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
写解锁
先将 readerCount变正然后释放信号量唤醒阻塞的读,然后解锁
func (rw *RWMutex) Unlock() {
// 恢复正值,释放后续的reader
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
// 唤醒已经阻塞的reader
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// Allow other writers to proceed.
rw.w.Unlock()
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
读锁
将 readerCount+1 同时判断如果小于 0 说明在此之前有写操作就阻塞,否则就执行阻塞等待信号量
func (rw *RWMutex) RLock() {
// 增加reader数,如果是负数说明前面有write,则阻塞
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
读解锁
将 readerCount-1 同时判断如果 小于0 说明有写锁,之后将 readerWait-1 同时判断如果自己是最后一个阻塞写的读就唤醒写。
func (rw *RWMutex) RUnlock() {
// 减少reader数,并判断如果是最后一个reader则释放writer
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
// Outlined slow-path to allow the fast-path to be inlined
rw.rUnlockSlow(r)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
chan 实现读写锁
const RWMutexMaxReaders = 1 << 30 //一个无法达到的最大读数量 type RWMutex struct { mu chan struct{} //互斥锁 readerCount int32 // 读数量 readerWait int32 // 写等待的读的数量 wchan chan struct{} //用于唤醒等待读的写 rchan chan struct{} //用于唤醒等待写的读 } func NewRWMutex() *RWMutex { return &RWMutex{mu: make(chan struct{}, 1), wchan: make(chan struct{}), rchan: make(chan struct{})} } func (rw *RWMutex) Lock() { rw.mu <- struct{}{} //获取锁 //阻止之后的读操作,等待现有的读操作 if r := atomic.AddInt32(&rw.readerCount, -RWMutexMaxReaders) + RWMutexMaxReaders; r > 0 { atomic.AddInt32(&rw.readerWait, r) //增加写阻塞时读数量 <-rw.wchan } } func (rw *RWMutex) Unlock() { //唤醒等待的读 if r := atomic.AddInt32(&rw.readerCount, RWMutexMaxReaders); r > 0 { for i := 0; i < int(r); i++ { rw.rchan <- struct{}{} } } //解锁 <-rw.mu } func (rw *RWMutex) RLock() { //增加读数量,如果有写就等待写 if r := atomic.AddInt32(&rw.readerCount, 1); r < 0 { <-rw.rchan } } func (rw *RWMutex) RUnlock() { //减少读数量,有写等待就进一步判断如果自己是最后一个读就唤醒写 if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 { if rwait := atomic.AddInt32(&rw.readerWait, -1); rwait == 0 { rw.wchan <- struct{}{} } } } func main() { rw := NewRWMutex() num := 0 wg := new(sync.WaitGroup) wg.Add(100) for i := 0; i < 100; i++ { go func(i int) { defer wg.Done() switch i % 2 { case 0: rw.Lock() defer rw.Unlock() num++ case 1: time.Sleep(time.Duration(rand.Intn(2)) * time.Millisecond) rw.RLock() defer rw.RUnlock() fmt.Println(num) } }(i) } wg.Wait() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
WaitGroup
WaitGroup 可以等待一组协程结束
Add 可以更新 WaitGroup 中的计数器 counter。虽然 Add 方法传入的参数可以为负数,但是计数器只能是非负数,一旦出现负数就会发生程序崩溃。当调用计数器归零,即所有任务都执行完成时,才会通过 Semrelease 唤醒处于等待状态的 Goroutine。
type WaitGroup struct { noCopy noCopy // 确保不会拷贝 state1 [3]uint32 } func (wg *WaitGroup) Add(delta int) { statep, semap := wg.state() state := atomic.AddUint64(statep, uint64(delta)<<32) v := int32(state >> 32) w := uint32(state) if v < 0 { panic("sync: negative WaitGroup counter") } if v > 0 || w == 0 { return } *statep = 0 for ; w != 0; w-- { runtime_Semrelease(semap, false, 0) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
Wait 会在计数器 大于0 并且不存在等待的 Goroutine 时,调用Semacquire 陷入睡眠。
func (wg *WaitGroup) Wait() { statep, semap := wg.state() for { state := atomic.LoadUint64(statep) v := int32(state >> 32) if v == 0 { return } if atomic.CompareAndSwapUint64(statep, state, state+1) { runtime_Semacquire(semap) if +statep != 0 { panic("sync: WaitGroup is reused before previous Wait has returned") } return } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
在 ThreadSafeCalcWords 中的递归情况下,您在调用 wg.Add 之前先调用 wg.Done。这意味着在实际完成所有工作之前,wg 可以降为 0 (这将触发 Wait 完成)。在 Wait 仍在解析过程中的同时再次调用 Add 会触发错误
Once
可以保证在 Go 程序运行期间的某段代码只会执行一次。
两次判断,一次加锁来防止重复初始化
type Once struct {
// done表示动作是否已经执行
done uint32
m Mutex
}
- 1
- 2
- 3
- 4
- 5
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 如果传入的函数已经执行过,会直接返回;
- 如果传入的函数没有执行过,会执行传入的函数:
Cond
Cond 让一组 goroutine 在特定条件下被唤醒
Cond 不是一个常用的同步机制,但是在条件长时间无法满足时,与使用 for {} 进行忙碌等待相比,Cond 能够让出处理器的使用权,提高 CPU 的利用率。使用时我们也需要注意以下问题:
- Cond.Wait 在调用之前一定要使用获取互斥锁,否则会触发程序崩溃;
- Cond.Signal 唤醒的 Goroutine 都是队列最前面、等待最久的 Goroutine;
- Cond.Broadcast 会按照一定顺序广播通知等待的全部 Goroutine;
type Cond struct {
// 用于保证结构体不会在编译期间拷贝;
noCopy noCopy
// 用于保护内部的 notify 字段,Locker 接口类型的变量
L Locker
// 一个 Goroutine 的链表,它是实现同步机制的核心结构;
notify notifyList
// 用于禁止运行期间发生的拷贝;
checker copyChecker
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Wait()
func (c *Cond) Wait() {
c.checker.check()
t := runtime_notifyListAdd(&c.notify)
c.L.Unlock()
runtime_notifyListWait(&c.notify, t)
c.L.Lock()
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 调用 notifyListAdd 将等待计数器加一并解锁;
- 调用 notifyListWait 等待其他 Goroutine 的唤醒并加锁:
Signal(),Broadcast
func (c *Cond) Signal() {
c.checker.check()
runtime_notifyListNotifyOne(&c.notify)
}
func (c *Cond) Broadcast() {
c.checker.check()
runtime_notifyListNotifyAll(&c.notify)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- Signal 方法会唤醒队列最前面的 Goroutine;
- Broadcast 方法会唤醒队列中全部的 Goroutine;
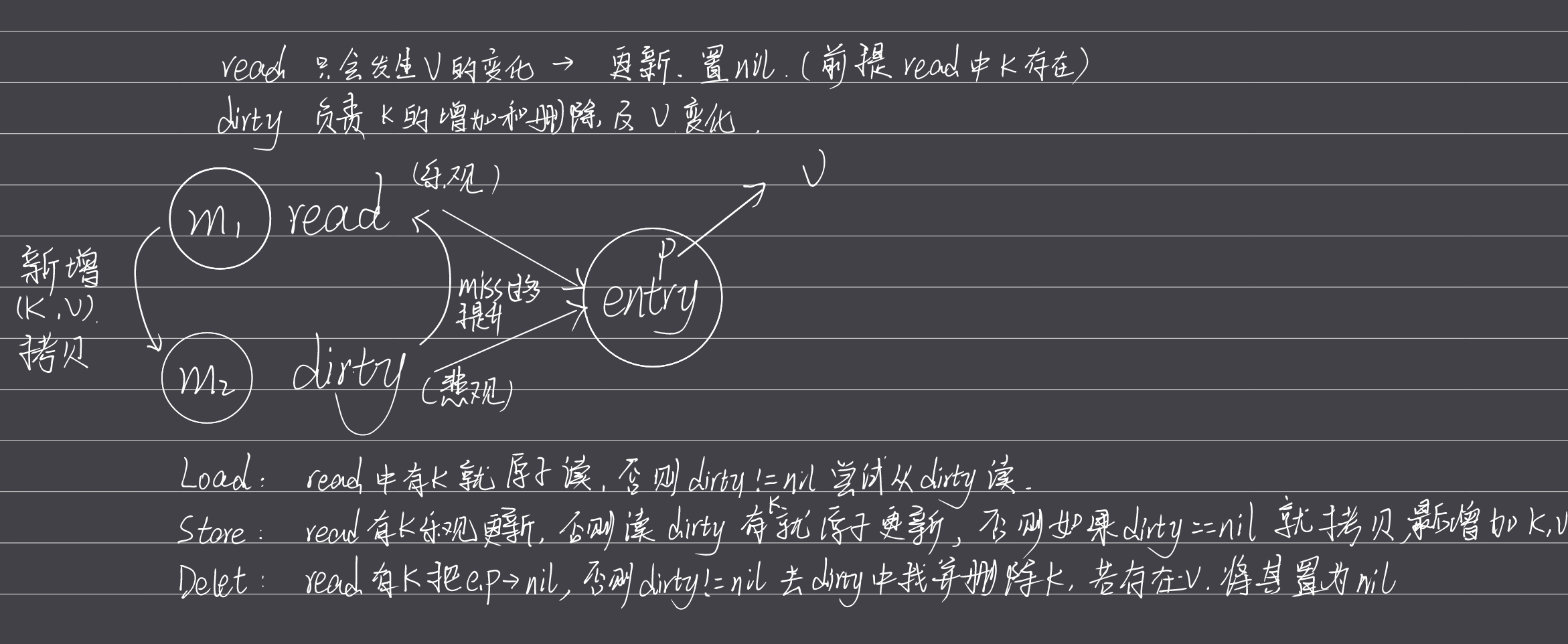
sync.Map
内置 map 不支持并发读写
type Map struct {
// 保护加锁字段
mu Mutex
// readOnly 结构是只读,但其中的操作也有写
read atomic.Value
// 最终写入的数据
dirty map[interface{}]*entry
// 计数器,每次read没有,读dirty就+1
misses int
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
sync.Map 的实现原理可概括为:
Load:read里面有key就直接原子读,否则如果dirty!=nil就尝试从dirty读(如果错过次数太多就将dirty提升到read,设置dirty=nil,amended=false)Store:read里面或者dirty有key就分别用乐观锁和原子操作更新对应的值,否则如果dirty为nil就拷贝read到dirty(amended=false,e.p如果等于nil->expunged),添加k,v到dirtyDelete:和Load差不多,read中有key则将e.p->nil,否则如果dirty!=nil,去dirty中找并删除key,如果read中这个值存在将v设置为nil
Read 使用原子操作,只发生值的更改,更新,设置 nil(延迟删除),不会扩容
dirty 操作需要加锁,主要是会增加和删除键,也会发生 v 的变化。
指令重排与内存模型
内存模型:描述的是并发环境中多 goroutine 读相同变量的时候,变量的可见性条件。
由于 CPU 指令重排和多级 Cache 的存在,保证多核访问同一个变量这件事儿变得非常复杂
不同 CPU 架构的处理方式也不一样,再加上编译器的优化也可能对指令进行重排。
所以编程语言需要一个规范,来明确多线程同时访问同一个变量的可见性和顺序,在编程语言中,这个规范被叫做内存模型。
重排和可见性问题
由于指令重排,代码并不一定会按照你写的顺序执行。
var a,b int
go func(){
a = 1
b = 2
}
go func(){
print(a) // 未初始化
print(b) // 已经初始化
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
程序在运行的时候,两个操作的顺序可能不会得到保证
happens-before
在一个 goroutine 内部,程序的执行顺序和它们的代码指定的顺序是一样的,即使编译器或者 CPU 重排了读写顺序,从行为上来看,也和代码指定的顺序一样。
对于另一个 go 程而言,则都有可能。
如何保证读写一致?
在 goroutine 内部对一个局部变量 v 的读,一定能观察到最近一次对这个局部变量 v 的写。
如果要保证多个 goroutine 之间对一个共享变量的读写顺序,在 Go 语言中,可以使用并发原语为读写操作建立 happens-before 关系,这样就可以保证顺序了。
小知识
- 在 Go 语言中,对变量进行零值的初始化就是一个写操作。
- 如果对超过机器 word(64bit、32bit 或者其它)大小的值进行读写,那么,就可以看作是对拆成 word 大小的几个读写无序进行。
- Go 并不提供直接的 CPU 屏障(CPU fence)来提示编译器或者 CPU 保证顺序性,而是使用不同架构的内存屏障指令来实现统一的并发原语。
Go 语言中保证的 happens-before 关系
除了单个 goroutine 内部提供的 happens-before 保证,Go 语言中还提供了一些其它的 happens-before 关系的保证,下面我来一个一个介绍下。
Init 函数
应用程序的初始化是在单一的 goroutine 执行的。
- 如果包
p导入了包q,那么,q的init函数的执行一定happens before p的任何初始化代码。 这里有一个特殊情况需要你记住:main 函数一定在导入的包的 init 函数之后执行。 - 包级别的变量在同一个文件中是按照声明顺序逐个初始化的,除非初始化它的时候依赖其它的变量。同一个包下的多个文件,会按照文件名的排列顺序进行初始化。这个顺序被定义在 Go 语言规范中,而不是 Go 的内存模型规范中。
goroutine
启动 goroutine 的 go 语句的执行,一定 happens before 此 goroutine 内的代码执行。
如果 go 语句传入的参数是一个函数执行的结果,那么,这个函数一定先于 goroutine 内部的代码被执行。
所以,如果你想观察某个 goroutine 的执行效果,你需要使用同步机制建立 happens-before 关系,比如 Mutex 或者 Channel。
Channel
- 往 Channel 中的发送操作,happens before 从该 Channel 接收相应数据的动作完成之前,即第 n 个 send 一定 happens before 第 n 个 receive 的完成。
- close 一个 Channel 的调用,肯定 happens before 从关闭的 Channel 中读取出一个零值。
- 对于 unbuffered 的 Channel,也就是容量是 0 的 Channel,从此 Channel 中读取数据的调用一定 happens before 往此 Channel 发送数据的调用完成。
- 如果 Channel 的容量是 m(m>0),那么,第 n 个 receive 一定 happens before 第 n+m 个 send 的完成。
Mutex/RWMutex
对于互斥锁 Mutex m 或者读写锁 RWMutex m,有 3 条 happens-before 关系的保证。
- 第 n 次的 m.Unlock 一定 happens before 第 n+1 m.Lock 方法的返回;
- 对于读写锁 RWMutex m,如果它的第 n 个 m.Lock 方法的调用已返回,那么它的第 n 个 m.Unlock 的方法调用一定 happens before 任何一个 m.RLock 方法调用的返回,只要这些 m.RLock 方法调用 happens after 第 n 次 m.Lock 的调用的返回。
这就可以保证,只有释放了持有的写锁,那些等待的读请求才能请求到读锁。
- 对于读写锁 RWMutex m,如果它的第 n 个 m.RLock 方法的调用已返回,那么它的第 k (k<=n)个成功的 m.RUnlock 方法的返回一定 happens before 任意的 m.RUnlockLock 方法调用,只要这些 m.Lock 方法调用 happens after 第 n 次 m.RLock。
也就是说: 对于 Mutex,在锁已被持有时,新的 Lock 请求必须等旧的 Unlock 返回才返回,否则将阻塞。 这样阻塞等待就安排了 happens-before 关系,相当于实现了两个线程间的同步。 类似的 RWMutex,则是写锁优先,后来的写锁必须等原读锁释放。
WaitGroup
对于一个 WaitGroup 实例 wg,在某个时刻 t0 时,它的计数值已经不是零了,假如 t0 时刻之后调用了一系列的 wg.Add(n) 或者 wg.Done(),并且只有最后一次调用 wg 的计数值变为了 0,那么,可以保证这些 wg.Add 或者 wg.Done() 一定 happens before t0 时刻之后调用的 wg.Wait 方法的返回。
这个保证的通俗说法,就是 Wait 方法等到计数值归零之后才返回。
Once
对于 once.Do(f) 调用,f 函数的那个单次调用一定 happens before 任何 once.Do(f) 调用的返回。 换句话说,就是函数 f 一定会在 Do 方法返回之前执行。
atomic
其实,Go 内存模型的官方文档并没有明确给出 atomic 的关系保证。
依照 Ian Lance Taylor 的说法,因为这个问题太复杂,有很多问题需要去研究,所以,现阶段还是不要使用 atomic 来保证顺序性。
在 go 的并发原语代码中,有很多对锁的双重检查,都是由 happends-before 保证的。
拓展原语
ErrGroup
为我们在一组 Goroutine 中提供了同步、错误传播以及上下文取消的功能
errgroup.Group.Go 方法能够创建一个 Goroutine 并在其中执行传入的函数,而 errgroup.Group.Wait 会等待所有 Goroutine 全部返回,该方法的不同返回结果也有不同的含义:
- 如果返回错误 — 这一组 Goroutine 最少返回一个错误;
- 如果返回空值 — 所有 Goroutine 都成功执行;
func main() { var g errgroup.Group var urls = []string{ "https://www.google.com", "https://www.baidu.com", } for i := range urls { g.Go(func() error { if resp, err := http.Get(urls[i]); err != nil { return err } else { return resp.Body.Close() } }) } if err := g.Wait(); err == nil { // 等待一个错误 log.Println(err) } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
结构:
type Group struct {
cancel func()
wg sync.WaitGroup
errOnce sync.Once
err error
}
- 1
- 2
- 3
- 4
- 5
- 6
cancel— 创建 context.Context时返回的取消函数,用于在多个Goroutine之间同步取消信号;wg—用于等待一组 Goroutine 完成子任务的同步原语;errOnce— 用于保证只接收一个子任务返回的错误;
方法:
WithContext()传入ctx控制时长,在出现错误时会cancel()
func WithContext(ctx context.Context) (*Group, context.Context) {
ctx, cancel := context.WithCancel(ctx)
return &Group{cancel: cancel}, ctx
}
- 1
- 2
- 3
- 4
Go()方法能够创建一个Goroutine并在其中执行传入的函数,并返回第一个出错的go程Wait()会等待所有Goroutine全部返回,然后调用cancel()
Semaphore
信号量是在并发编程中常见的一种同步机制,在需要控制访问资源的进程数量时就会用到信号量,它会保证持有的计数器在 0 到 初始化的权重 之间波动。
- 每次获取资源时都会将信号量中的计数器减去对应的数值,在释放时重新加回来;
- 当遇到计数器大于信号量大小时,会进入休眠等待其他线程释放信号;
Acquire()
Acquire 方法能用于获取指定权重的资源,其中包含三种不同情况:
- 当信号量中剩余的资源大于获取的资源并且没有等待的
Goroutine时,会直接获取信号量; - 如果超过上限,会等待
ctx被cancel() - 遇到其他情况时会将当前 Goroutine 加入到等待列表并通过
select等待调度器唤醒当前 Goroutine,Goroutine 被唤醒后会获取信号量; TryAcquire()
只会非阻塞地判断当前信号量是否有充足的资源,如果有充足的资源会直接立刻返回 true,否则会返回 false:
Release()
当我们要释放信号量时,Release 方法会从头到尾遍历 waiters 列表中全部的等待者,如果释放资源后的信号量有充足的剩余资源就会通过 Channel 唤起指定的 Goroutine。
SingleFlight
它能够在一个服务中抑制对下游的多次重复请求。一个比较常见的使用场景是:我们在使用 Redis 对数据库中的数据进行缓存,发生缓存击穿时,大量的流量都会打到数据库上进而影响服务的尾延时。
Group 能有效地解决这个问题,它能够限制对同一个键值对的多次重复请求,减少对下游的瞬时流量。
结构:
type Group struct { mu sync.Mutex // protects m m map[string]*call // lazily initialized } type call struct { wg sync.WaitGroup //这些字段在WaitGroup完成之前写入一次,并且只在WaitGroup完成后读取。 val interface{} err error forgotten bool // dups 和 chans 两个字段分别存储了抑制的请求数量以及用于同步结果的 Channel。 dups int chans []chan<- Result }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Do同步等待
先查看是否有相同的 key 在执行,如果没有把自己加入 map 中,然后执行 func
否则就等待并返回前面的请求的结果。
DoChan异步等待
开新协程处理数据,返回 缓冲chan
计时器
采用四叉堆
- 上推节点的操作更快。假如最下层某个节点的值被修改为最小,同样上推到堆顶的操作,N 叉堆需要的比较次数只有二叉堆的 logv2 倍。
- 对缓存更友好。二叉堆对数组的访问范围更大,更加随机,而 N 叉堆则更集中于数组的上部,这就对缓存更加友好,有利于提高性能。
- Go1.10 之前由全局唯一四叉堆维护
所有 go 程对计时器操作都会争夺互斥锁,性能消耗大
- Go1.10 之后将全局四叉堆分为 64 个小的四叉堆
理想情况下,堆数和处理器数量相同,但是如果处理器数量超过 64,则可能多个处理器上的计时器就在一个桶中,每个桶由一个 go 程去处理。但是这个 go 程造成处理器和线程之间频繁切换引起性能问题
- Go1.13 之后采用网络轮训器方式
所有计时器都采用最小四叉堆的形式存放在处理器 P 中,计时器都交给处理器的网络轮训器和调度器来触发。
Ticker:返回只读chan定时发送信息,最后需要stopTimer:单次延时触发。
Channel
设计原则
不同协程通过channel来进行同步和数据传输。
使用特性
- 先进先出,队列特性
- 读取或写入
- 读取:
1. `nil`:阻塞
1. `open`非空:值
1. `open`空:阻塞
1. `close`:默认值,false
1. `只写`:编译错误
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 写入:
1. `nil`:阻塞
1. `满`:阻塞
1. 未满:写入值
1. <strong>关闭</strong><strong>:panic</strong>
1. `只读`:编译错误
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- close
1. <strong>nil</strong><strong>:panic</strong>
1. `open`未空:关闭chan,直到通道耗尽,然后读取默认值
1. `open`空:关闭chan,读取默认值
1. `关闭`:panic
1. `只读`:编译错误
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结构
type hchan struct { qcount uint // 当前队列中剩余元素 dataqsiz uint // 环形队列长度(cap) buf unsafe.Pointer // 唤醒队列指针 elemsize uint16 // 元素大小 closed uint32 // 标识关闭 elemtype *_type // 元素类型 sendx uint // 队列下标(下一个写入存放的位置) recvx uint // 队列下标(下一个读取的位置) recvq waitq // 等待读的协程队列 sendq waitq // 等待写的协程队列 lock mutex // 不允许互斥读写 } // 双向链表 type waitq struct { first *sudog last *sudog }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
创建
make(chan) 会在编译阶段被转换为 makechan 函数
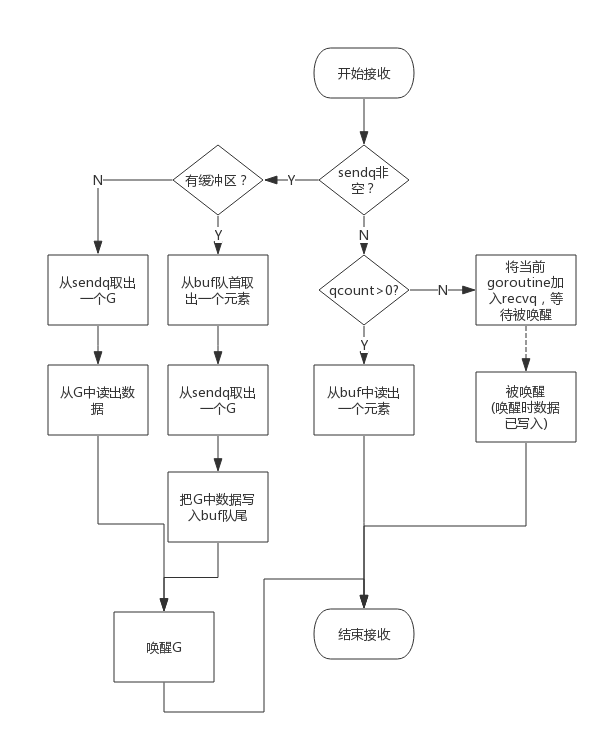
发送数据
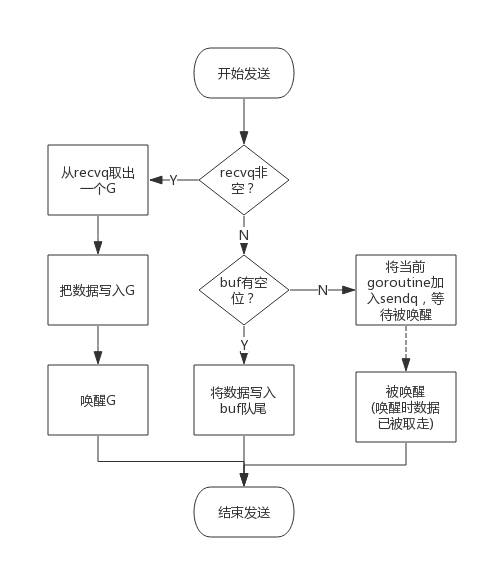
chan <- i 会被转换为 chansend 函数,参数 block 表示是否阻塞发送
- 存在等待的接收者:直接发送
拷贝数据,唤醒接受方
- 存在可用缓冲:写入缓冲区
创建的 channel 有缓冲区且没有满
- 无缓冲区或满了且没有接受者:阻塞发送
接收数据
i<-ch,编译期间最终都会调用 chanrecv函数,从 nil 阻塞接收数据会直接让出处理器。
- 存在等待的发送者:直接获取数据
- 缓冲区不为空:从缓冲区读
- 无缓冲区或无数据:阻塞等待
关闭管道
当 Channel 是一个 空指针 或者 已经被关闭时,Go 语言运行时都会直接崩溃并抛出异常。
关闭 chan 会通知所有阻塞读该 chan 的协程,返回默认值。
控制协程数量
缓冲chan+WaitGroup
package main import ( "fmt" "math" "sync" "runtime" ) var wg = sync.WaitGroup{} // 任务 func busi(ch chan bool, i int) { fmt.Println("go func ", i, " goroutine count = ", runtime.NumGoroutine()) <-ch wg.Done() } func main() { //模拟用户需求go业务的数量 task_cnt := math.MaxInt64 ch := make(chan bool, 3) // 缓冲channel for i := 0; i < task_cnt; i++ { wg.Add(1) ch <- true go busi(ch, i) } wg.Wait() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
无缓冲chan+工作池+WaitGroup
package main import ( "fmt" "math" "sync" "runtime" ) var wg = sync.WaitGroup{} func busi(ch chan int) { for t := range ch { fmt.Println("go task = ", t, ", goroutine count = ", runtime.NumGoroutine()) wg.Done() } } func sendTask(task int, ch chan int) { wg.Add(1) ch <- task } func main() { ch := make(chan int) //无buffer channel goCnt := 3 //启动goroutine的数量 for i := 0; i < goCnt; i++ { //启动go go busi(ch) } taskCnt := math.MaxInt64 //模拟用户需求业务的数量 for t := 0; t < taskCnt; t++ { //发送任务 sendTask(t, ch) } wg.Wait() }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
并发组件
无锁队列(lock-free)
通过一个排外锁可以实现队列的并发访问。一般实现队列的时候通过指针,而且只在队头队尾操作
// LKQueue 无锁队列 type LKQueue struct { head unsafe.Pointer // 第一个 tail unsafe.Pointer // 最后一个 } // 节点 type node struct { value interface{} // 当前 value next unsafe.Pointer // next } // NewLKQueue returns an empty queue. func NewLKQueue() *LKQueue { n := unsafe.Pointer(&node{}) return &LKQueue{head: n, tail: n} } // 原子读 func load(p *unsafe.Pointer) (n *node) { return (*node)(atomic.LoadPointer(p)) } // cas func cas(p *unsafe.Pointer, old, new *node) (ok bool) { return atomic.CompareAndSwapPointer( p, unsafe.Pointer(old), unsafe.Pointer(new)) } // Enqueue 写入元素到队列 func (q *LKQueue) Enqueue(v interface{}) { n := &node{value: v} for { tail := load(&q.tail) // 当前最后一个 next := load(&tail.next) // 最后一个的下一个 if tail == load(&q.tail) { // 判断是否被修改 if next == nil { // 这是最后一个 if cas(&tail.next, next, n) { cas(&q.tail, tail, n) // 尝试将当前队列末尾指向这个节点,失败说明有其他的操作了 return } } else { // 不是最后一个 试着把tail摆动到下一个节点 cas(&q.tail, tail, next) } } } } // Dequeue removes and returns the value at the head of the queue. // It returns nil if the queue is empty. func (q *LKQueue) Dequeue() interface{} { for { head := load(&q.head) // 头 tail := load(&q.tail) // 尾 next := load(&head.next) // 头的下一个 if head == load(&q.head) { // are head, tail, and next consistent? if head == tail { // is queue empty or tail falling behind? if next == nil { // is queue empty? return nil } // tail is falling behind. try to advance it cas(&q.tail, tail, next) } else { // read value before CAS otherwise another dequeue might free the next node v := next.value if cas(&q.head, head, next) { return v // Dequeue is done. return } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
GMP
go 的协程调度器,负责协程的切换
- 单进程:进程阻塞浪费 CPU
- 多进程:切换资源消耗高
- 多线程:一个线程占用内存大,调度消耗 CPU
于是线程被分为用户态线程(协程)和内核态线程,一个“用户态线程”必须要绑定一个“内核态线程”,但是 CPU 并不知道有“用户态线程”的存在,它只知道它运行的是一个“内核态线程”。
映射关系
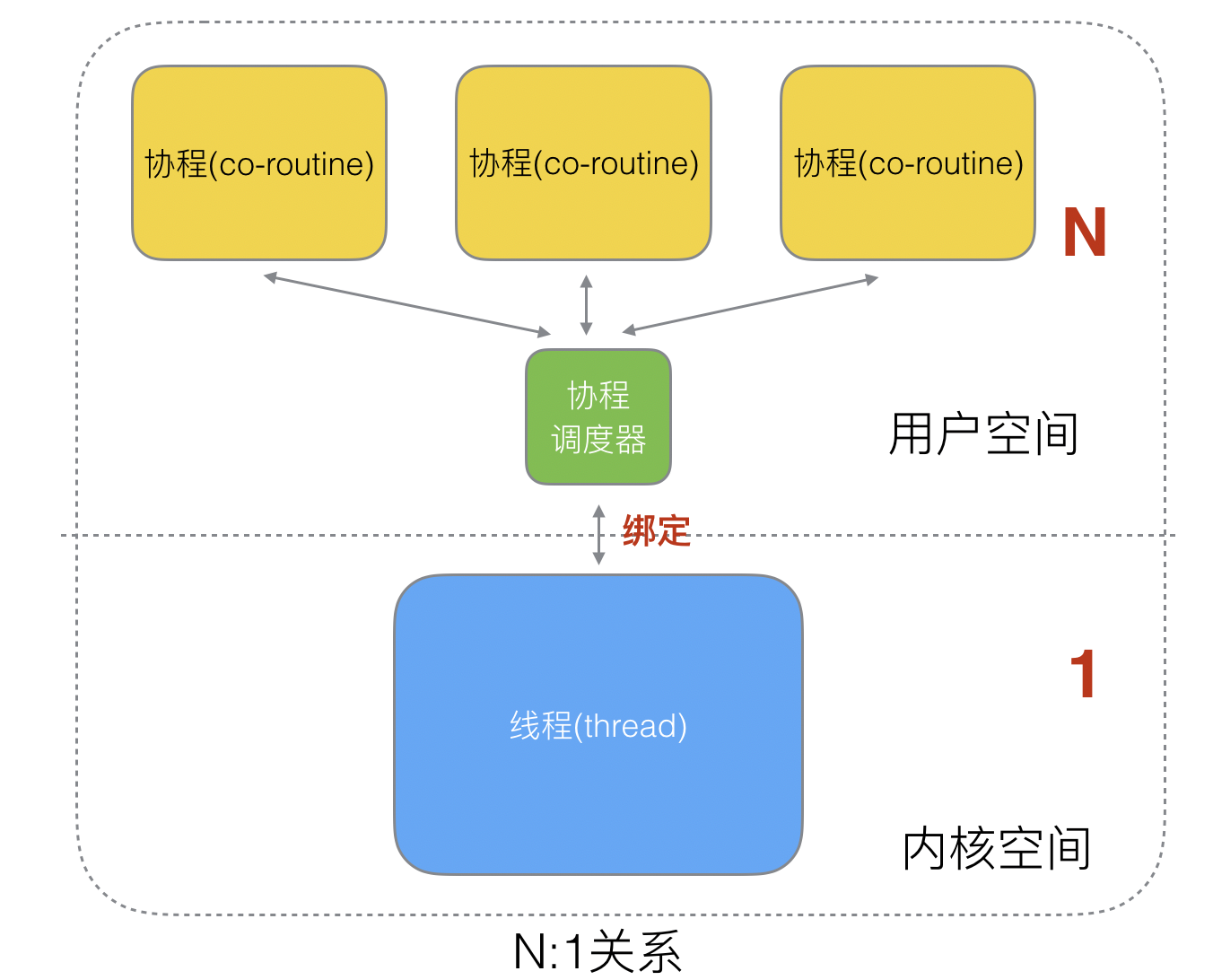
N:1
优点:协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。
缺点:
- 无法利用 CPU 多核加速能力,无法并行。
- 一个协程阻塞,整个进程都阻塞。
1:1
1 个协程绑定 1 个线程,这种最容易实现。协程的调度都由 CPU 完成了,不存在 N:1 缺点,
缺点:
协程的创建、删除和切换的代价都由内核态完成,有点略显昂贵了。
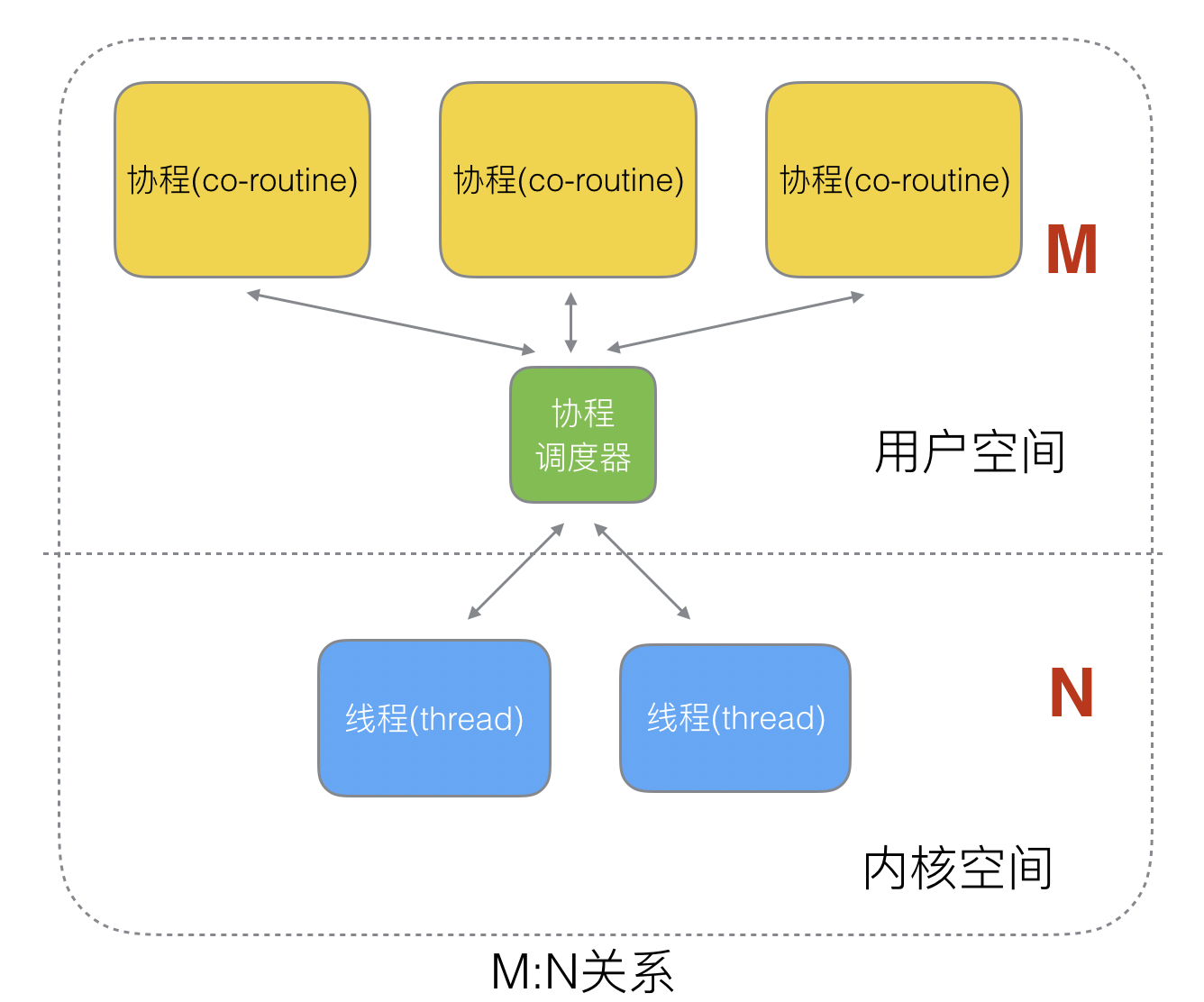
N:N
M 个协程绑定 N 个内核线程,是 N:1 和 1:1 类型的结合,克服了以上 2 种模型的缺点,但实现起来最为复杂。

协程跟线程是有区别的,线程由内核态调度是抢占式的,协程由用户态调度是协作式的,一个协程让出 CPU 后,才执行下一个协程。
goroutine(Go 的协程)
Go 中,协程被称为 goroutine,它非常轻量,一个 goroutine 只占几 KB,并且这几 KB 就足够 goroutine 运行完,这就能在有限的内存空间内支持大量 goroutine,支持了更多的并发。虽然一个 goroutine 的栈只占几 KB,但实际是可伸缩的,如果需要更多内容,runtime 会自动为 goroutine 分配。
GM 调度器
G:协程 M:线程
缺点:
- M 对 G 进行操作都需要持有全局锁,激烈的锁竞争
- M 转移 G 会造成延迟和额外负担:比如新的 Go 程肯定和原本的 Go 程资源相关。
- CPU 在 M 上状态切换增加系统开销
GMP 调度器
G:go 程,M:线程,P:协程处理器包含了运行 goroutine 的资源,
GMP 模型
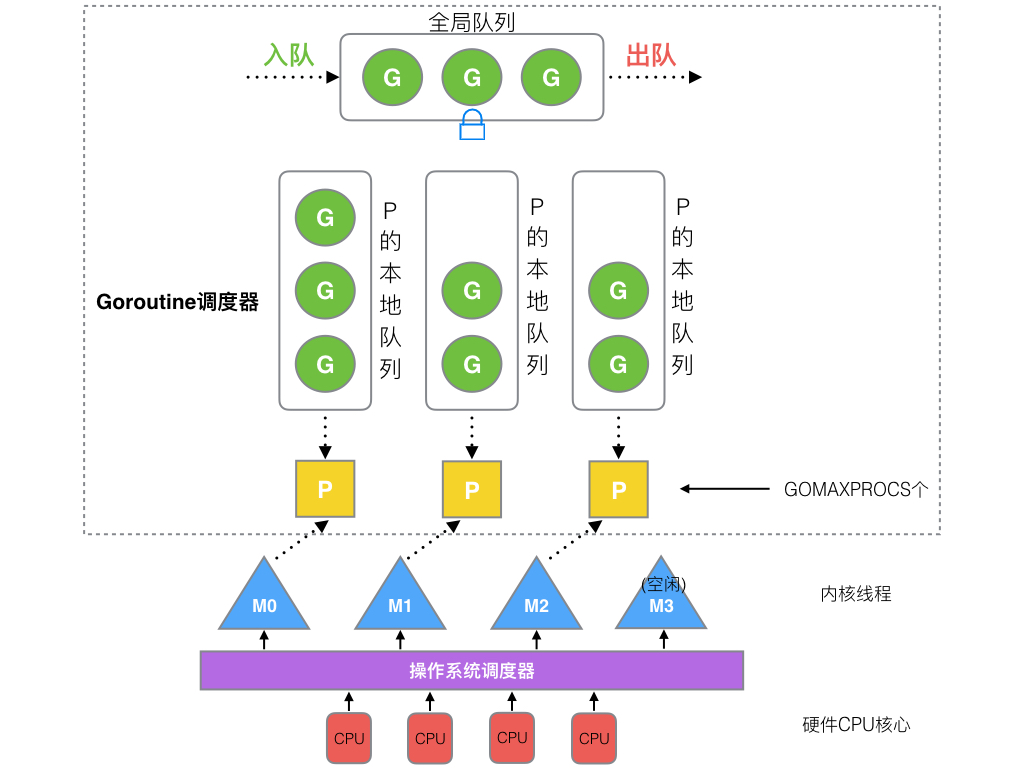
Go 调度本质是把大量的 goroutine 分配到少量线程上去执行,并利用多核并行,实现更强大的并发。

- 全局队列:存放等待运行的 go 程,它可以从全局 G 队列获取 G,没有时执行
work stealing从其他 P 偷 G。 - P 本地队列:类似全局队列,数量有限(256);新建 G 时优先加入本地队列,如果满了移动一半去全局
- P 列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有
GOMAXPROCS(可配置)个。 - M:线程运行任务需要获取 P,从 P 的本地队列获取 G,P 空 M 就尝试去全局拿一批 G 放本地,或者去其他 P 本地偷一半。M 执行本地队列的 G。
Goroutine 调度器和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到CPU的核上执行。
P 和 M
- 数量
- P 数量
由启动时环境变量 $GOMAXPROCS 或者是由 runtime 的方法 GOMAXPROCS() 决定。这意味着在程序执行的任意时刻都只有 $GOMAXPROCS 个 goroutine 在同时运行。
- M 的数量:
-
go 语言本身的限制:go 程序启动时,会设置 M 的最大数量,默认 10000.但是内核很难支持这么多的线程数,所以这个限制可以忽略。
- runtime/debug 中的 SetMaxThreads 函数,设置 M 的最大数量
- 一个 M 阻塞了,会创建新的 M。
M 和 P 没绝对关系,一个 M 阻塞 P 去创建或切换其他 M。
- 创建时间
- P 何时创建:运行时就会根据最大数量来创建
- M 何时创建:没有 M 来关联 P,P 就会去寻找或者创建新的 M。
调度器设计策略
复用线程:避免频繁的创建,销毁。
work stealing机制
当本地队列或者全局队列无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
hand off机制
当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
利用并行:GOMAXPROCS 设置 P 的数量,最多有 GOMAXPROCS 个线程分布在多个 CPU 上同时运行。GOMAXPROCS 也限制了并发的程度,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
抢占:在 coroutine 中要等待一个协程主动让出 CPU 才执行下一个协程,在 Go 中,一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死,这就是 goroutine 不同于 coroutine 的一个地方。
go func() 调度流程
go func创建 G 程- 新的 G 优先存在本地队列,本地满了存到全局
- M 会从 P 中弹出一个 G 执行,P 如果为空会去全局或者其他队列偷
- 当 M 执行一个 G 时如果发生了 IO 或者其他阻塞操作,M 会阻塞。然后 P 就会被脱离 M,寻找其他空闲的 M 或者新建 M 去执行。
- M 恢复后会尝试绑定 P,如果没有 P 则 M 会休眠加入空闲线程,然后 G 会放入全局队列。
调度器生命周期
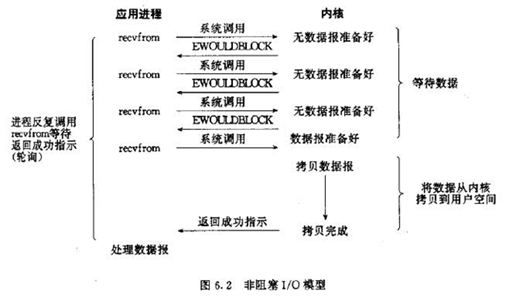
特殊的 M0 和 G0
M0:M0 负责初始化和启动第一个 G,之后和其他 M 相同
G0:G0 是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
在 Go 中 g0 作为一个特殊的 goroutine,为 scheduler 执行调度循环提供了场地(栈)。对于一个 M 来说,g0 总是它第一个创建的 goroutine。
之后,它会不断地寻找其他普通的 goroutine 来执行,直到进程退出。
当需要执行一些任务,且不想扩栈时,就可以用到 g0 了,因为 g0 的栈比较大。
g0 其他的一些“职责”有:创建 goroutine、deferproc 函数里新建_defer、垃圾回收相关的工作(例如 stw、扫描 goroutine 的执行栈、一些标识清扫的工作、栈增长)等等。
package main
import "fmt"
func main() {
fmt.Println("Hello world")
}
- 1
- 2
- 3
- 4
- 5
- runtime 创建并关联 M0,G0
- 调度器初始化:初始化 M0,栈,GC,并创建所有 P
- 程序启动时会为
runtime.main创建goroutine,称它为 main goroutine 吧,然后把main goroutine加入到 P 的本地队列。 - 启动
M0,M0会从本地获取G(main g)然后执行 M根据G中的栈信息和调度信息设置运行环境M退出GM获取可运行的G,直到main.main退出,runtime.main执行defer或panic处理,或者runtime.exit退出
调度过程中阻塞
用户态阻塞
当 goroutine 因为 channel 操作或者 network I/O 而阻塞时,对应的 G 会被放置到某个 wait 队列(如 channel 的 waitq),该 G 的状态由_Gruning 变为_Gwaitting,而M会跳过该 G 尝试获取并执行下一个 G,如果此时没有 runnable 的 G 供 M 运行,那么 M 将解绑 P,并进入 sleep 状态;当阻塞的 G 被另一端的 G2 唤醒时(比如 channel 的可读/写通知),G 被标记为 runnable,尝试加入 G2 所在 P 的 runnext,然后再是 P 的 Local 队列和 Global 队列。
系统调用阻塞
当 G 被阻塞在某个系统调用上时,此时 G 会阻塞在_Gsyscall 状态,M 也处于 block on syscall 状态,此时的 M 可被抢占调度:执行该 G 的 M 会与 P 解绑,而 P 则尝试与其它 idle 的 M 绑定,继续执行其它 G。如果没有其它 idle 的 M,但 P 的 Local 队列中仍然有 G 需要执行,则创建一个新的 M;当系统调用完成后,G 会重新尝试获取一个 idle 的 P 进入它的 Local 队列恢复执行,如果没有 idle 的 P,G 会被标记为 runnable 加入到 Global 队列。
Go 调度场景
- 新建协程:优先加到本地队列
P1 拥有 G1,G1 创建 G2,为了局部性,G2 优先加入到 P1 的本地队列
- 协程切换:
G0负责从本地队列获取G来执行
G1 完成后,M 上 G 切换到 G0,G0 负责协程的调度。从 P 本地队列获取 G2,然后切换到 G2 运行。
- 本地队列满:将本地队列的一半 G 放到全局队列
假设每个 P 的本地队列只能存 3 个 G。G2 要创建了 6 个 G,前 3 个 G(G3, G4, G5)已经加入 p1 的本地队列,p1 本地队列满了。此时创建 G7,则需要负载均衡(把 P1 中前一半 G 和新的 G 打乱后移动到全局队列)
- 唤醒 M:在创建 G 时,运行的 G 会尝试唤醒其他空闲的 P 和 M 组合
假定 G2 唤醒了 M2,M2 绑定了 P2,并运行 G0,但 P2 本地队列没有 G,M2 此时为自旋线程,寻找 G
- 从全局队列获取:本地没有了就从全局队列中获取
至少从全局队列取 1 个 g,但每次不要从全局队列移动太多的 g 到 p 本地队列,给其他 p 留点。
这是从全局队列到 P 本地队列的负载均衡。
- 窃取 G:全局和本地队列都没有 G 了,M 会从其他有 G 的队列中窃取一半的 G 到本地
- 自旋 M:全局和本地都没 G 可运行,M 则处于自旋状态来寻找 G
创建和销毁 M,CPU 也会浪费时间,我们希望当有新 goroutine 创建时,立刻能有 M 运行它,如果销毁再新建就增加了时延,降低了效率。当然也考虑了过多的自旋线程是浪费 CPU,所以系统中最多有 GOMAXPROCS 个自旋的线程(当前例子中的 GOMAXPROCS=4,所以一共 4 个 P),多余的没事做线程会让他们休眠。
- M 阻塞系统调用:P 会脱离 M 并寻找可用的 M 来绑定(如果本地有 G)
- M 非阻塞系统调用:M 会和 P 解绑,但之后会优先和先前的 P 绑定。
网络轮训器
网络轮训器可以用于监控网络 IO,文件 IO 等,利用操作系统提供的 IO 多路复用模型来提升 IO 设备的利用率和性能。
IO 模型
IO 即数据的读取(接收)或写入(发送)操作。
通常用户进程中的一个完整 IO 分为两阶段:
- 用户进程空间 <–> 内核空间
- 内核空间 <–> 设备空间(磁盘、网络等)。
IO 有内存 IO、网络 IO 和磁盘 IO 三种,通常我们说的 IO 指的是后两者。
Eg: 对于一个输入操作来说,进程 IO 系统调用后,内核会先看缓冲区中有没有相应的缓存数据,没有的话再到设备中读取,因为设备 IO 一般速度较慢,需要等待;内核缓冲区有数据则直接复制到进程空间。
所以,对于一个网络输入操作通常包括两个不同阶段:
- 等待网络数据到达网卡 → 读取到内核缓冲区,数据准备好;
- 从内核缓冲区复制数据到进程空间。
阻塞IO模型
进程发起 IO 系统调用后,进程被阻塞,转到内核空间处理,整个 IO 处理完毕后返回进程。操作成功则进程获取到数据。
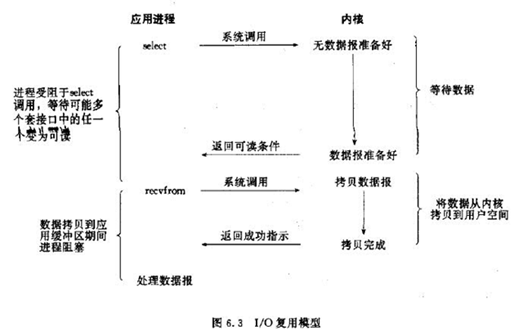
非阻塞IO模型
进程发起 IO 系统调用后,如果内核缓冲区没有数据,需要到 IO 设备中读取,进程返回一个错误而不会被阻塞;
进程发起 IO 系统调用后,如果内核缓冲区有数据,内核就会把数据同步返回进程。
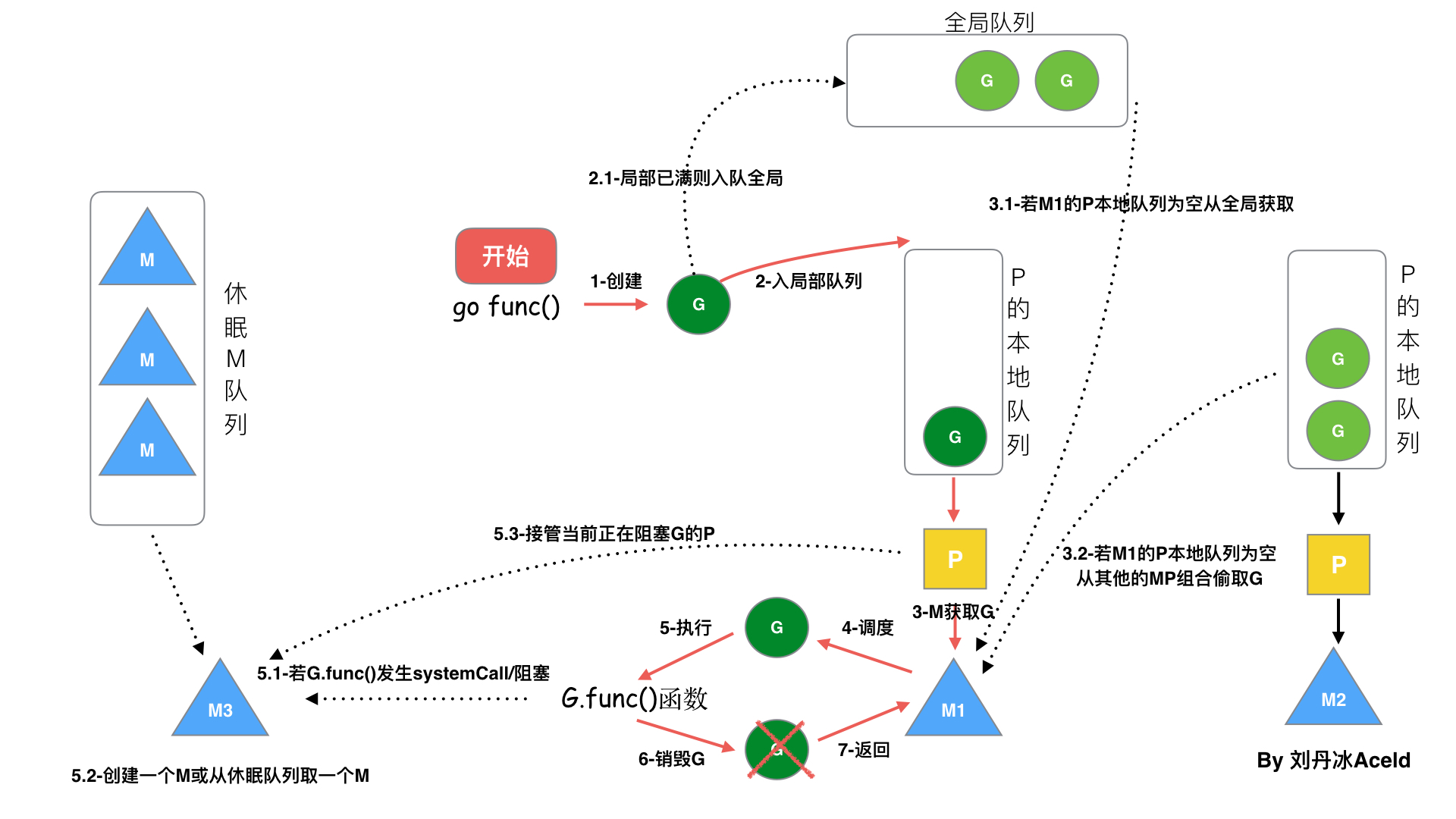
IO多路复用模型
多个进程的 IO 可以注册到一个复用器 select 上,可以用一个进程调用 select 来阻塞监听所有注册的 IO,如何都没有数据返回,进程阻塞,如果任一 IO 在内核缓冲区有数据,select 就返回通知。监听进程则可以自己或者告知其他进程读取。
即多路 IO 复用可以让一个进程阻塞等待多个 IO 操作。
select,poll
Poll 无数量限制
select实现多路复用的方式是,将已连接的Socket都放到一个文件描述符集合,然后调用select函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此Socket标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll不再用BitsMap来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。epollepoll在内核里使用红黑树来跟踪进程所有待检测的文件描述字(增删改一般时间复杂度是O(logn))。epoll使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个socket有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,接受者从就绪链表中获取事件。

epoll 支持边缘触发和水平触发
- 边缘触发:有事件来了内核只通知一次,程序要保证一次性将内核缓冲区的数据读取完;
- 水平触发:服务器端不断地从 epoll_wait 中苏醒,直到内核缓冲区数据被 read 函数读完才结束
信号驱动IO模型
当进程发起一个 IO 操作,会向内核注册一个信号处理函数,然后进程返回不阻塞;当内核数据就绪时会发送一个信号给进程,进程便在信号处理函数中调用 IO 读取数据。

异步IO模型
当进程发起一个 IO 操作,进程返回(不阻塞),但也不能返回结果;内核把整个 IO 处理完后,会通知进程结果。如果 IO 操作成功则进程直接获取到数据。
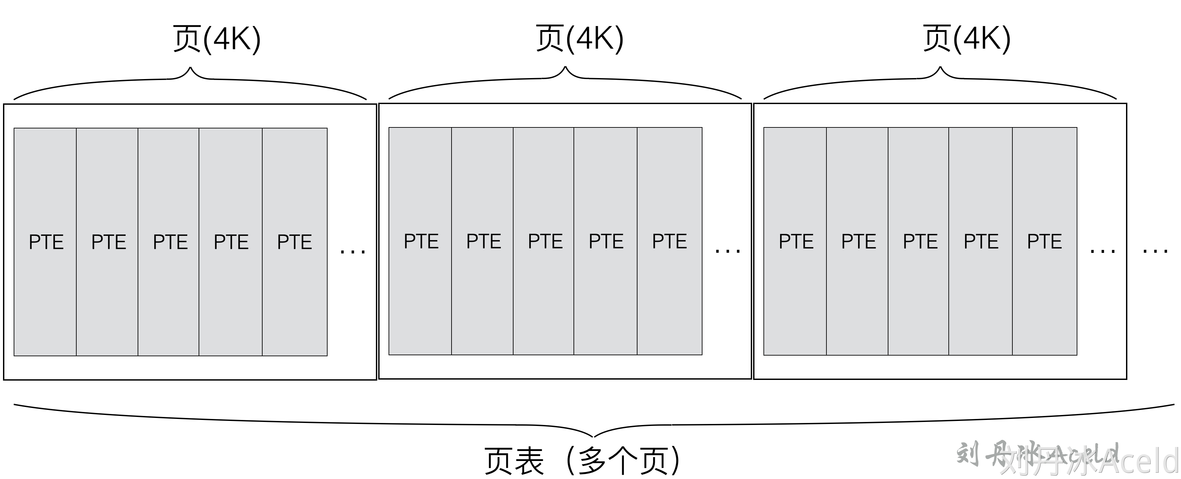
所以, 阻塞 IO 模型、非阻塞 IO 模型、IO 复用模型、信号驱动的 IO 模型者为同步 IO 模型,只有异步 IO 模型是异步 IO。
同步和异步IO
主要是指访问数据的机制 (即实际 I/O 操作的完成方式)
同步:一般指主动请求并等待 I/O 操作完毕的方式,I/O 操作未完成前,会导致应用进程挂起
异步:是指用户进程触发 IO 操作以后便开始做自己的事情,而当 IO 操作已经完成的时候会得到 IO 完成的通知(异步的特点就是通知), 这可以使进程在数据读写时也不阻塞。
阻塞或者非阻塞 I/O 说白了是一种读取或者写入操作函数的实现方式,阻塞方式下读取或者写入函数将一直等待,而非阻塞方式下,读取或者写入函数会立即返回一个状态值。
内存管理
操作系统如何管理内存
操作系统运行多个进程,每个进程需要一定内存,但很多不一定使用,而且多个进程同时使用一块内存容易造成冲突,所以引入操作系统提供的虚拟内存来解决。
虚拟内存
基于物理内存地址的一个虚拟的逻辑地址,应用程序只能使用虚拟地址,操作系统会提供一个映射关系来管理分配。应用程序不需要考虑冲突和容量问题,操作系统负责逻辑和物理地址的转换。
虚拟内存的目的是为了解决以下几件事:
- 物理内存无法被最大化利用。
读共享,写拷贝,可以将一个物理地址映射到多个逻辑地址,写时进行拷贝重新映射。
- 程序逻辑内存空间使用独立。
- 内存不够,继续虚拟磁盘空间。
可以将磁盘挂在虚拟地址上。
MMU 内存管理单元
专门用来管理虚拟内存和物理内存映射关系的东西
虚拟内存本身怎么存放
虚拟内存本身是通过一个叫页表(Page Table)的东西来实现的,接下来介绍页和页表这两个概念。
页:一个内存单位
页是操作系统中用来描述内存大小的一个单位名称,操作系统虚拟内存空间分成一页一页的来管理,每页的大小为 4K(可配置)。磁盘和主内存之间的置换也是以页为单位来操作的
页表
基于页的一个数组,里面存放页表项(PTE),每个页表项表示虚拟地址和物理地址的映射关系。
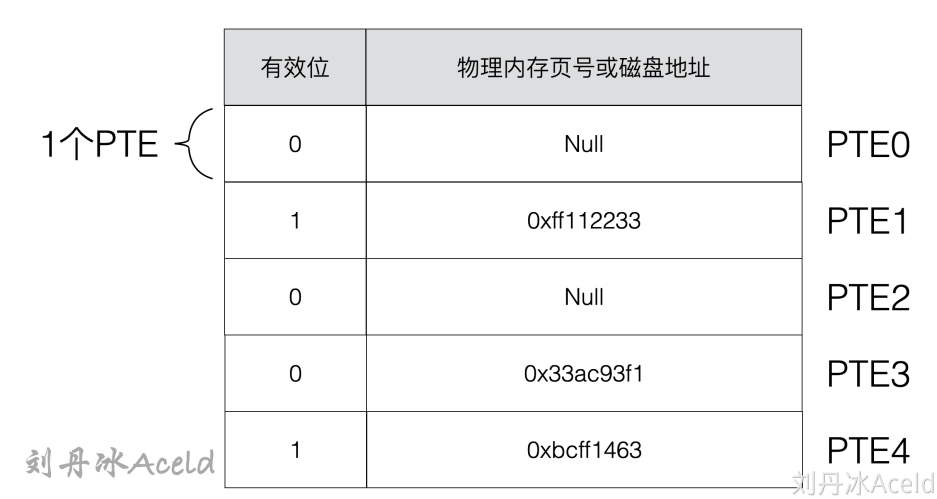
页表项(PTE)
每个 PTE 是由一个有效位和一个包含物理页号或者磁盘地址组成,有效位表示当前虚拟页是否已经被缓存在主内存中(或者 CPU 的高速缓存 Cache 中)。
CPU 把虚拟地址给 MMU,MMU 去物理内存中查询页表,得到实际的物理地址。
当然 MMU 不会每次都去查的,它自己也有一份缓存叫 TLB 是为了加速地址翻译。
TCMalloc
Golang 的内存管理就是基于 TCMalloc 的核心思想来构建的。
所有线程程共享的内存池会导致内存申请需要和全局 BufPool 打交道,为了线程安全需要频繁加锁和解锁。
而 TCMalloc 最大优势就是每个线程都会独立维护自己的内存池。
层级模型
TCMalloc 则为每个线程预分配一块缓存,每个线程在申请内存的时候会先从线程缓存池中申请。每个线程缓存池共享一块中心缓存。
优点:线程独立缓存减少加锁发生次数
内存对象划分:
而对于中,大对象的内存申请,TCMalloc 提供一个全局共享的内存堆PageHeap。当然对其进行操作需要进行加锁。
页堆主要时当中心缓存没空间时向其申请,过多时退还,以及线程在申请大对象超过 Cache 的内存单元块单元大小时也会直接向页堆申请。
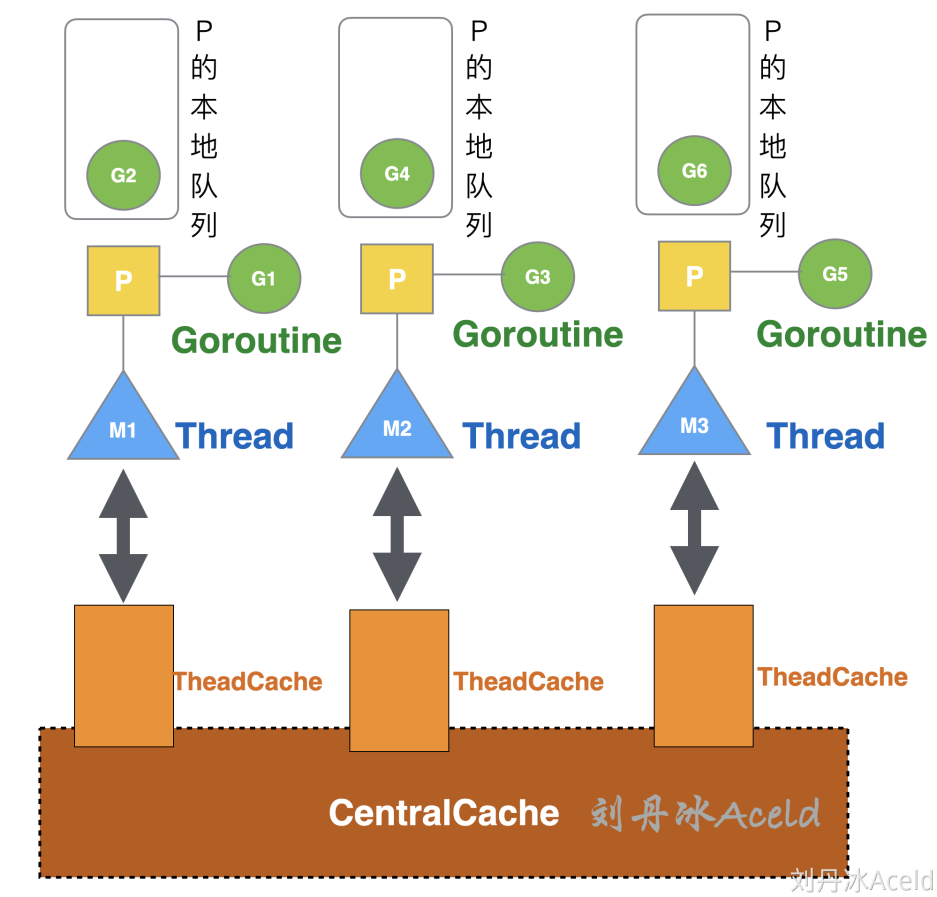
基础结构
TCMalloc 将虚拟内存划分为多份同等大小的 Page,每个 Page 默认 8KB,可以通过 地址指针+偏移量 来确定 Page 位置。
Span
多个连续的 Page 称之为是一个 Span,其定义含义有操作系统的管理的页表相似。
TCMalloc 是以 Span 为单位向操作系统申请内存的。每个 Span 记录了第一个起始 Page 的编号 Start,和一共有多少个连续 Page 的数量 Length。
同时span 之间通过双向链表来连接。
Size Class
在256KB 以内的小对象会被 TCMalloc 划分为多个内存刻度,同一个刻度下的内存集合称为Size Class.
每个 Size Class 都对应一个字节大小。在申请小对象内存时,TCMalloc 会根据申请字节向上取一个 Size Class 的 Span(多个 page 组成)的内存块给使用者。
ThreadCache
ThreadCache 即线程自己的缓存。其对于每个 SizeClass 都有一个对应的 FreeList,表示当前缓存中还有多少空闲的内存可用。
流程:申请小对象直接通过 ThreadCache 获取对应 Size Class 的一个 Span,如果对应的 Size Class 下的链表为 nil,则 ThreadCache 会向 ThreadCache 申请空间,线程用完内存后也是直接归还到本线程对应刻度下的 span 双向链表中。
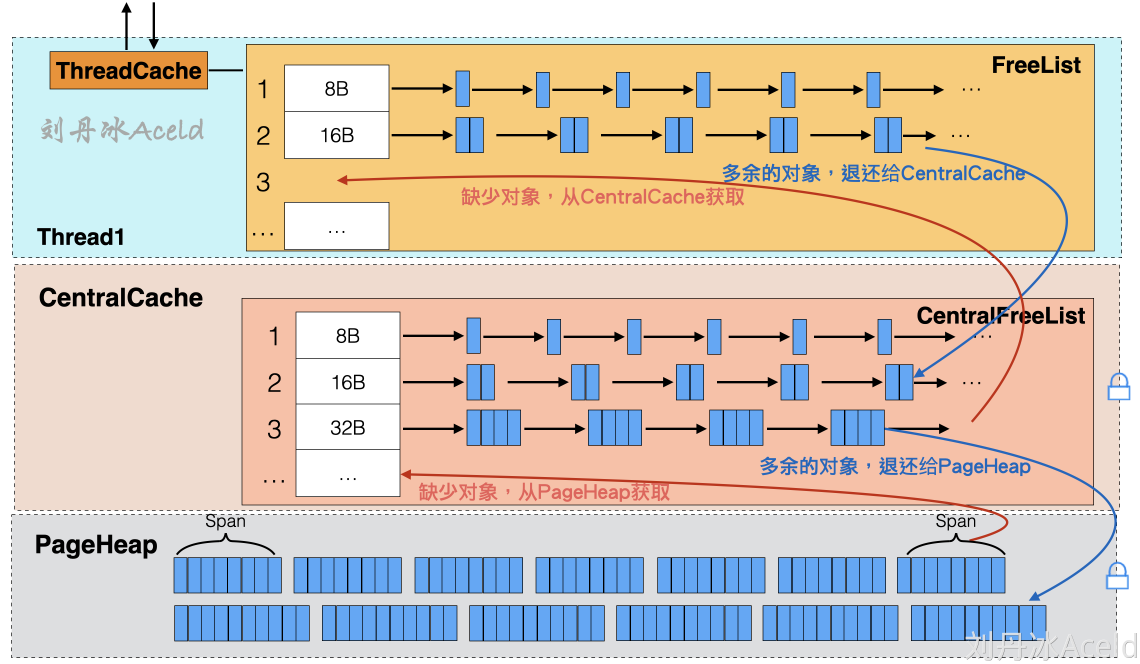
CentralCache
CentralCache 是所有线程共用的。其结构和 ThreadCache 相似,各个刻度的 span 链表被放置在 CentralFreeList 之中。
流程:ThreadCache 在内存不够时会向 CentralFreeList 申请指定刻度的内存,当其内存多余时也会归还给 CentralFreeList。PageHeap 和 CentralFreeList 关系也类似。
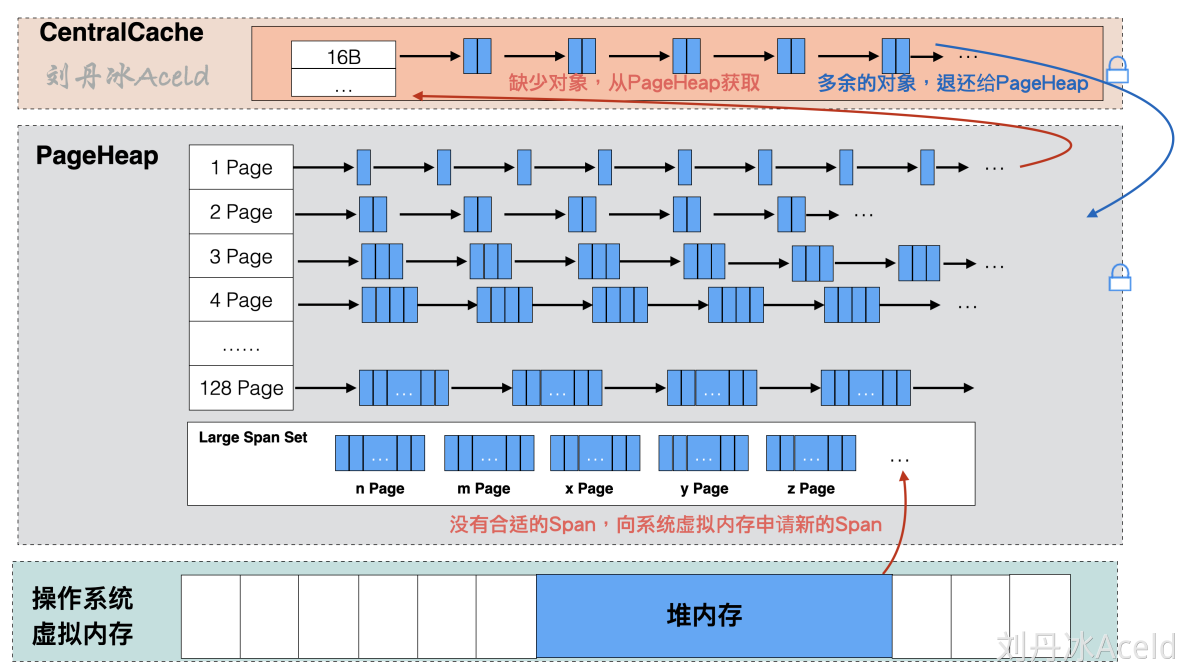
PageHeap
Heap 与 CentralCache 不同的是 CentralCache 是与 ThreadCache 布局一模一样的缓存,主要是起到针对 ThreadCache 的一层二级缓存作用,且只支持小对象内存分配。而PageHeap则是针对CentralCache的三级缓存,弥补对于中对象内存和大对象内存的分配,PageHeap 也是直接和操作系统虚拟内存衔接的一层缓存。
当一二级缓存都无法分配对应的内存时,三次缓存则通过系统调用来从虚拟内存的堆区中获取内存来填充。
PageHeap 内部的 Span 管理采取两种方式
128个 page 以内使用链表128以上的 page 则通过有序集合来存放
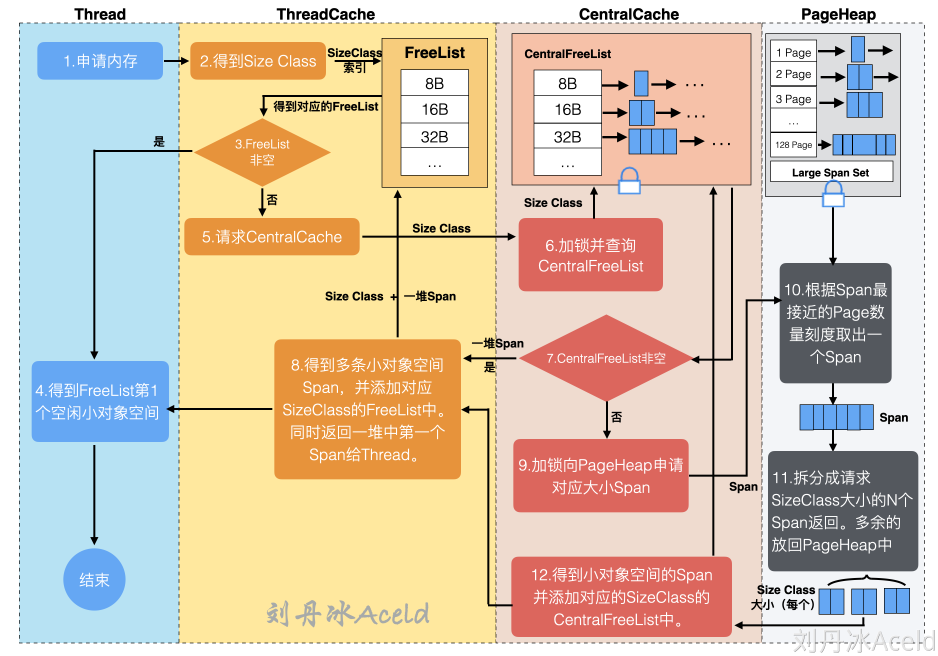
小对象分配
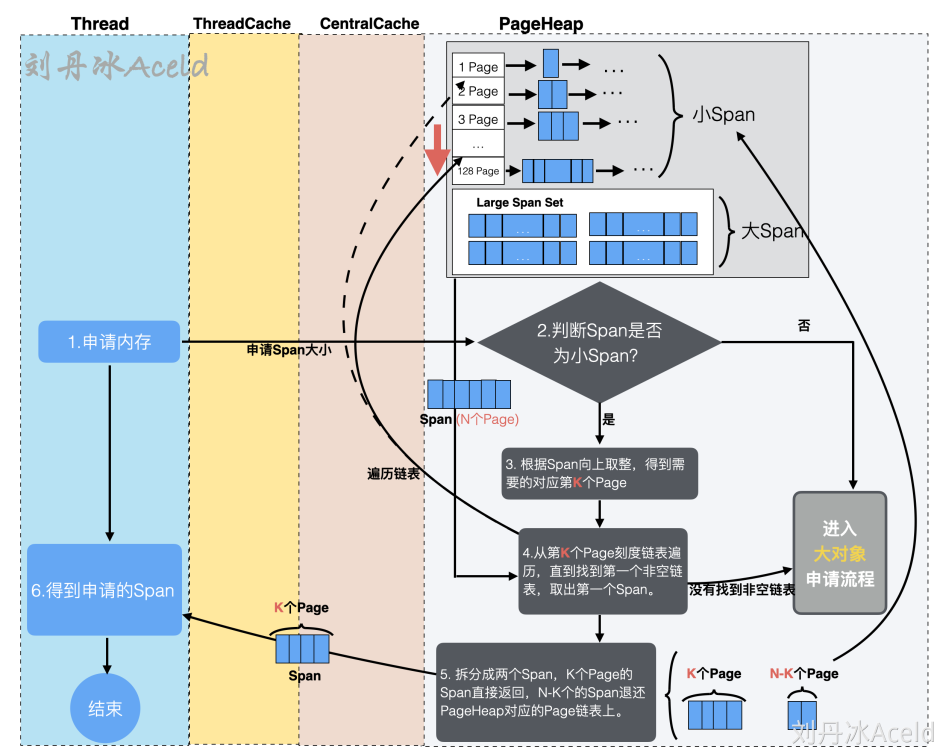
用户线程优先访问本地内存缓存,申请指定大小的 span,如果有就返回一个空闲的 span,否则 本地内存缓存 会向 中心缓存 申请 SizeClass 大小的 span,中心缓存收到请求后返回多个 span,本地缓存返回一个 span 给线程。中心缓存不够就去 Pageheap,Pageheap 在得到申请请求之后返回多个 SizeClass 大小的 span 给中心缓存。
中对象分配
中对象是在 256KB-1M 之间的内存。TCMalloc 会直接从 Pageheap 获取。
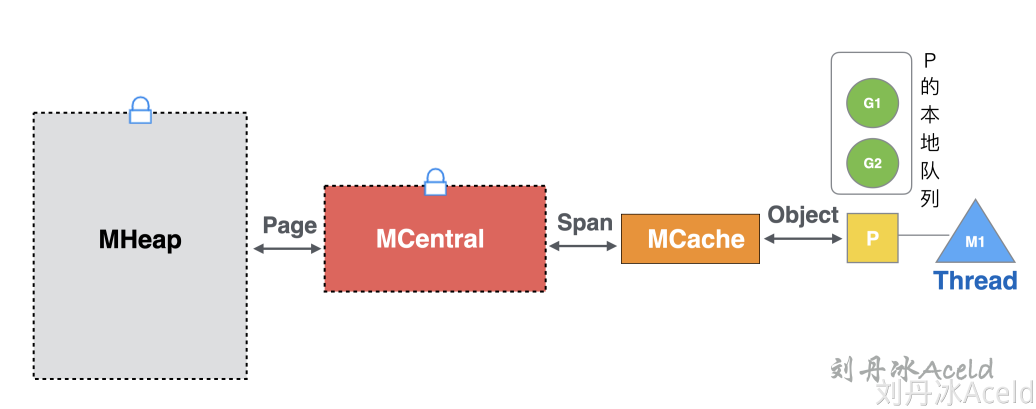
PageHeap 将 128 个 Page 以内大小的 Span 定义为 小Span,将 128 个 Page 以上大小的 Span 定义为 大Span。
所以中对象划分为小 span 进行分配。
(1)Thread 用户逻辑层提交内存申请处理,如果本次申请内存超过 256KB 但不超过 1MB 则属于中对象申请。TCMalloc 将直接向 PageHeap 发起申请 Span 请求。
(2)PageHeap 接收到申请后需要判断本次申请是否属于小 Span(128 个 Page 以内),如果是,则走小 Span,即中对象申请流程,如果不是,则进入大对象申请流程。
(3)PageHeap 根据申请的 Span 在小 Span 的链表中向上取整,得到最适应的第 K 个 Page 刻度的 Span 链表。
(4)得到第 K 个 Page 链表刻度后,将 K 作为起始点,向下遍历找到第一个非空链表,直至 128 个 Page 刻度位置,找到则停止,将停止处的非空 Span 链表作为提供此次返回的内存 Span,将链表中的第一个 Span 取出。如果找不到非空链表,则当错本次申请为大 Span 申请,则进入大对象申请流程。
(5)假设本次获取到的 Span 由 N 个 Page 组成。PageHeap 将 N 个 Page 的 Span 拆分成两个 Span,其中一个为 K 个 Page 组成的 Span,作为本次内存申请的返回,给到 Thread,另一个为 N-K 个 Page 组成的 Span,重新插入到 N-K 个 Page 对应的 Span 链表中。
大对象分配
对于超过 128 个 Page(即 1MB)的内存分配则为大对象分配流程。大对象分配与中对象分配情况类似,Thread 绕过 ThreadCache 和 CentralCache,直接向 PageHeap 获取
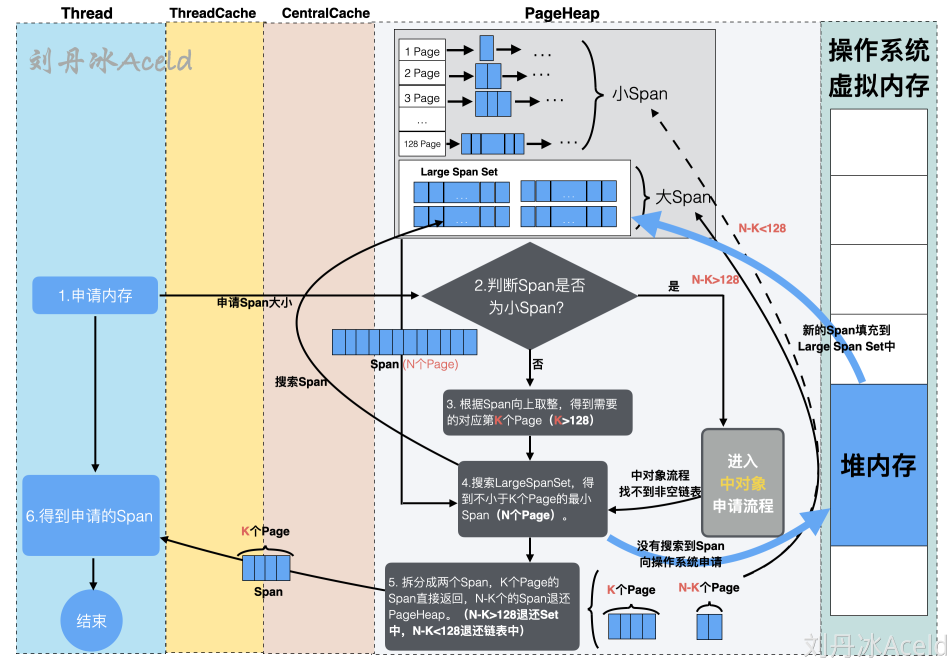
进入大对象分配流程除了申请的 Span 大于 128 个 Page 之外,对于中对象分配如果找不到非空链表也会进入大对象分配流程
(1)Thread 用户逻辑层提交内存申请处理,如果本次申请内存超过 1MB 则属于大对象申请。TCMalloc 将直接向 PageHeap 发起申请 Span 。
(2)PageHeap 接收到申请后需要判断本次申请是否属于小 Span(128 个 Page 以内),如果是,则走小 Span 中对象申请流程(上一节已介绍),如果不是,则进入大对象申请流程
(3)PageHeap 根据 Span 的大小按照 Page 单元进行除法运算,向上取整,得到最接近 Span 的且大于 Span 的 Page 倍数 K,此时的 K 应该是大于 128。如果是从中对象流程分过来的(中对象申请流程可能没有非空链表提供 Span),则 K 值应该小于 128。
(4)搜索 Large Span Set 集合,找到不小于 K 个 Page 的最小 Span(N 个 Page)。如果没有找到合适的 Span,则说明 PageHeap 已经无法满足需求,则向操作系统虚拟内存的堆空间申请一堆内存,将申请到的内存安置在 PageHeap 的内存结构中,重新执行(3)步骤
(5)将从 Large Span Set 集合得到的 N 个 Page 组成的 Span 拆分成两个 Span,K 个 Page 的 Span 直接返回给 Thread 用户逻辑,N-K 个 Span 退还给 PageHeap。其中如果 N-K 大于 128 则退还到 Large Span Set 集合中,如果 N-K 小于 128,则退还到 Page 链表中。
Go 堆内存管理
层级模型
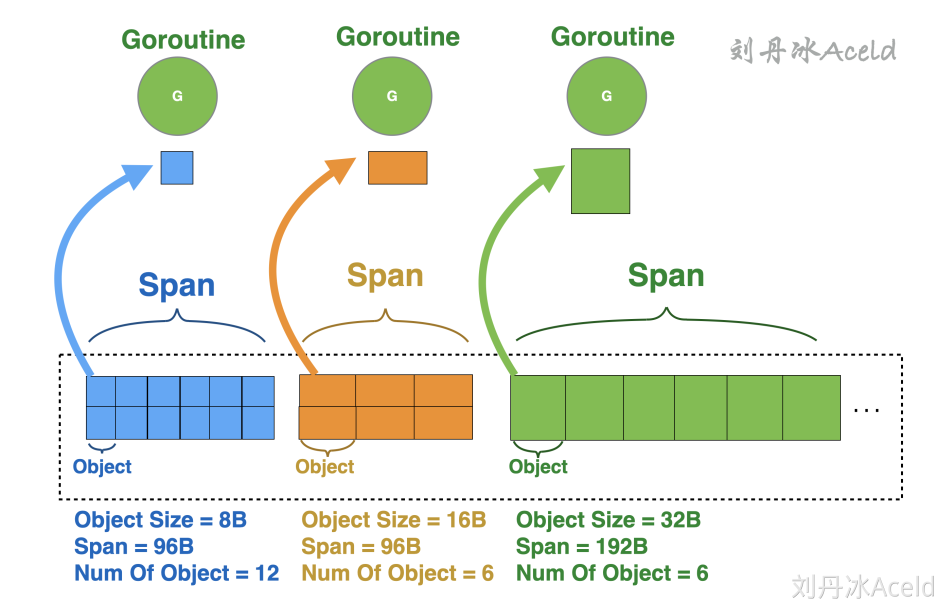
其中协程逻辑层与MCache的内存交换单位是Object,MCache与MCentral的内存交换单位是Span,而MCentral与MHeap的内存交换单位是Page。
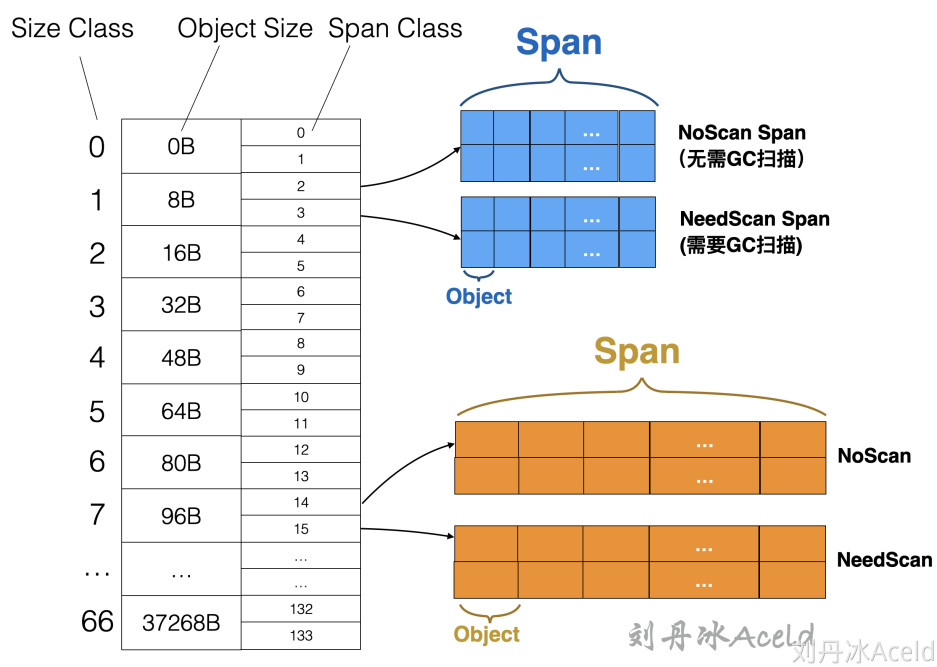
Golang 内存管理中依然保留 TCMalloc 中的 Page、Span、Size Class 等概念
Page
Page 表示 Golang 内存管理与虚拟内存交互内存的最小单元。操作系统虚拟内存对于 Golang 来说,依然是划分成等分的 N 个 Page 组成的一块大内存公共池。
golang 内存管理模型延续了 TCMalloc 的概念,一个 Page 的大小依然是 8KB。
mSpan
与 TCMalloc 中的 Span 一致。mSpan 概念依然延续 TCMalloc 中的 Span 概念,在 Golang 中将 Span 的名称改为 mSpan,依然表示一组连续的 Page。
Size Class 相关
Object Size:指协程应用逻辑一次向 Golang 内存申请的对象Object大小。
Object 是 Go 内存管理模块更细化的管理单元。一个 span 在初始化时会被分为多个 Object。逻辑层向 Go 内存模型取内存实际是获取 Object。
注意: Page 是 Golang 内存管理与操作系统交互衡量内存容量的基本单元,Golang 内存管理内部本身用来给对象存储内存的基本单元是 Object。
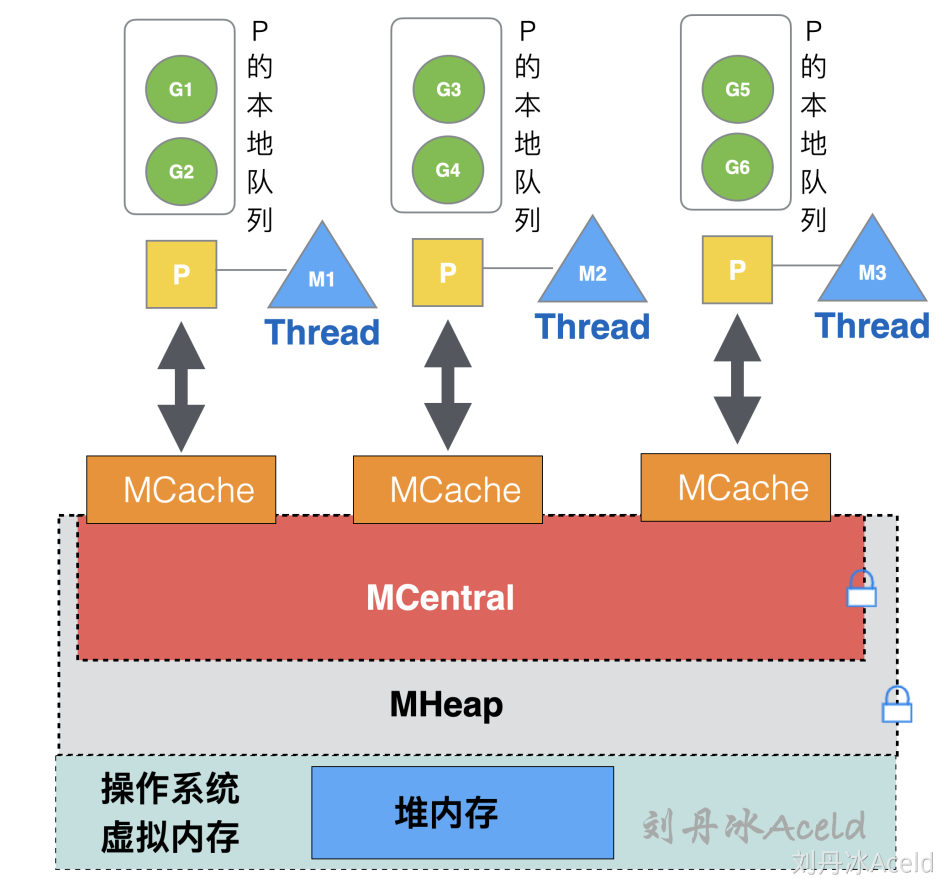
Size Class:表示一块内存的所属规格或者刻度
Golang 内存管理中的 Size Class 是针对 Object Size 来划分内存的。也是划分 Object 大小的级别。比如 Object Size 在 1Byte~8Byte 之间 的Object 属于 Size Class 1 级别,Object Size 在 8B~16Byte 之间的属于 Size Class 2 级别。
Span Class:表示一块内存的所属规格或者刻度,也是划分 Object 大小的级别。
其中一个 Span 为存放需要 GC 扫描的对象(包含指针的对象)
另一个 Span 为存放不需要 GC 扫描的对象(不包含指针的对象)
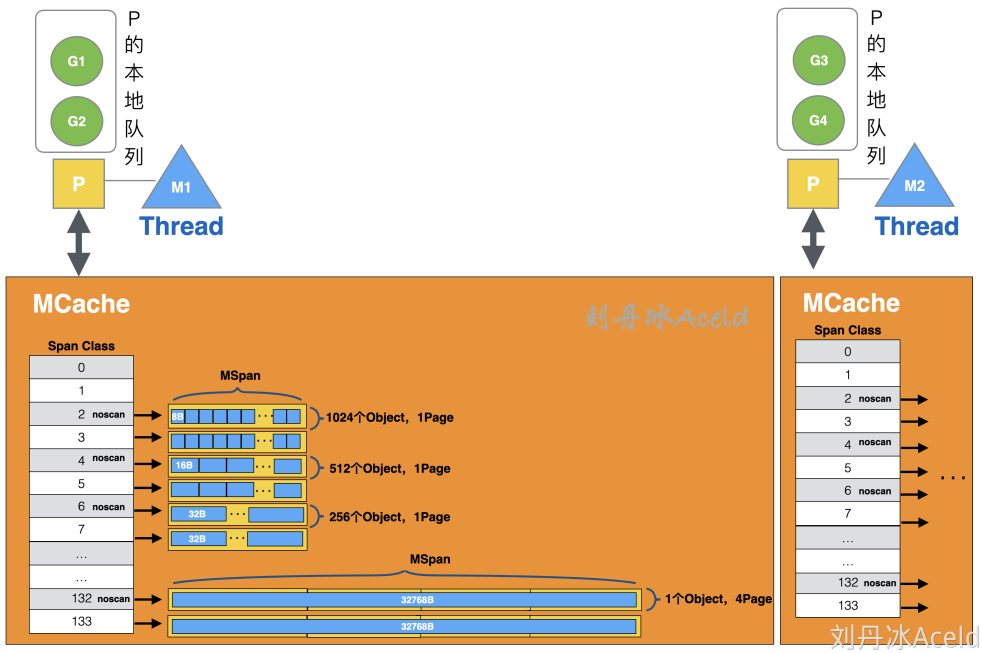
// 标题Title解释: // [class]: Size Class // [bytes/obj]: Object Size,一次对外提供内存Object的大小 // [bytes/span]: 当前Object所对应Span的内存大小 // [objects]: 当前Span一共有多少个Object // [tail wastre]: 为当前Span平均分层N份Object,会有多少内存浪费 // [max waste]: 当前Size Class最大可能浪费的空间所占百分比 // class bytes/obj bytes/span objects tail waste max waste // 1 8 8192 1024 0 87.50% // 2 16 8192 512 0 43.75% // 3 32 8192 256 0 46.88% // 4 48 8192 170 32 31.52% // 5 64 8192 128 0 23.44% // 6 80 8192 102 32 19.07% // 7 96 8192 85 32 15.95% // 8 112 8192 73 16 13.56%
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
MCache:协程缓存
类似于 TCMalloc 的 ThreadCache,协程访问不需要加锁。MCache 绑定在 处理器P 中,因为实际可运行的 M 数量和 P 相同。
MCache 中每个 Span Class 都会对应一个 MSpan,不同 Span Class 的 MSpan 的总体长度不同
当其中某个 Span Class 的 MSpan 已经没有可提供的 Object 时,MCache 则会向 MCentral 申请一个对应的 MSpan。
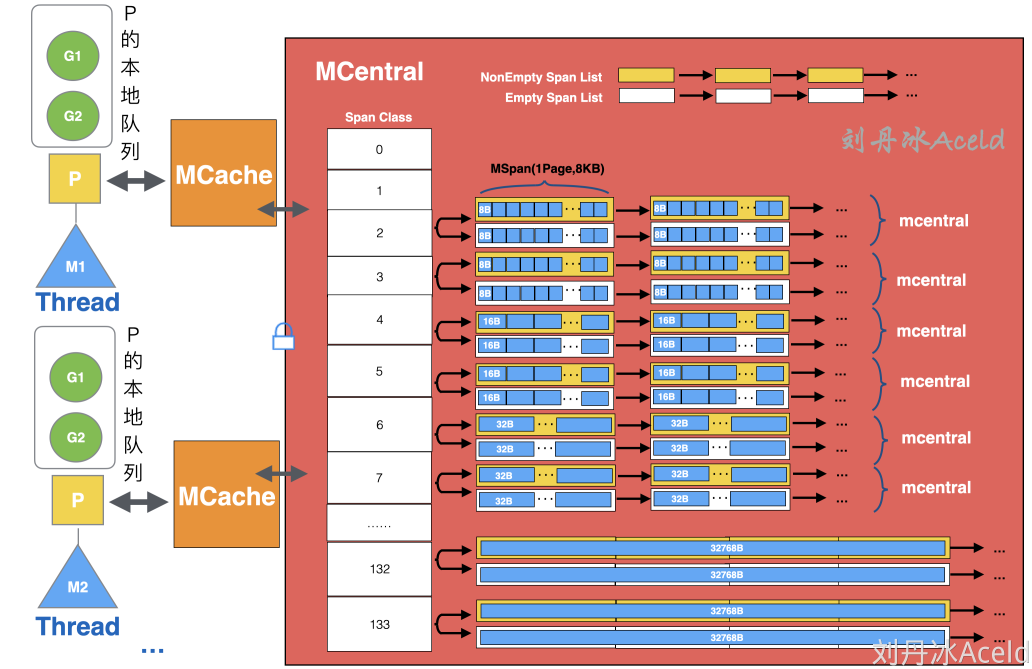
注:申请大小时是 0 则返回固定地址表示 nil。
MCentral
当 MCache 中某个 Size Class 对应的 Span 被一次次 Object 被上层取走后,如果出现当前 Size Class 的 Span 空缺情况,MCache 则会向 MCentral 申请对应的 Span。
每个 span class 存在两个 span 链表。
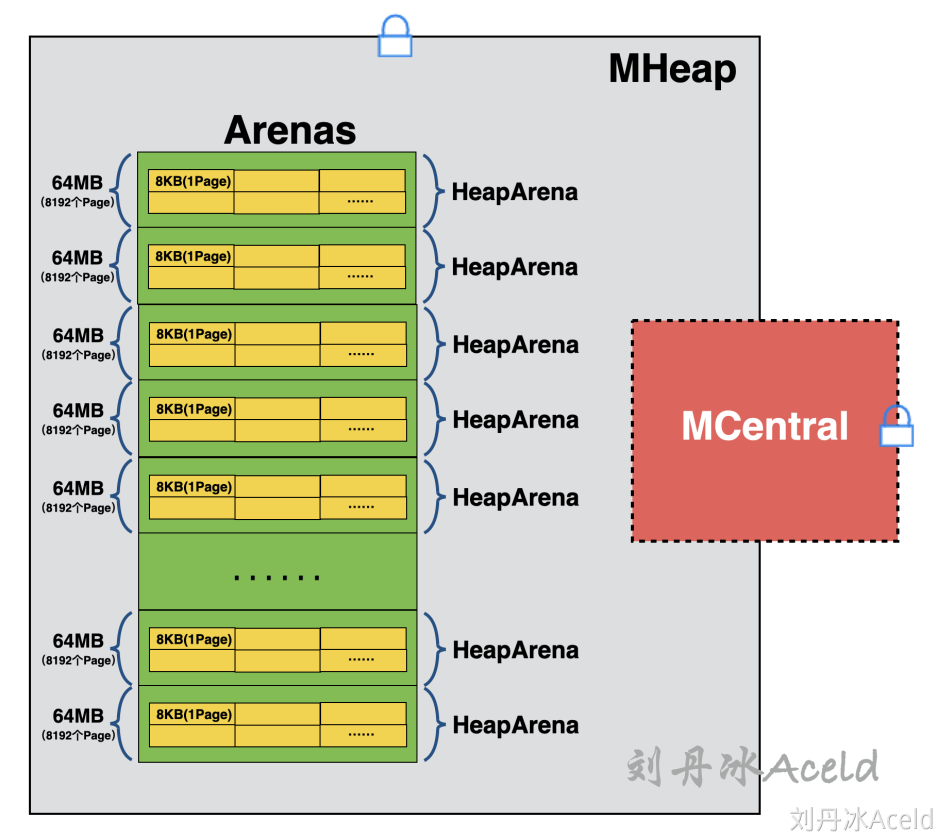
注意:MCentral 是表示一层抽象的概念,实际上每个 Span Class 对应的内存数据结构是一个 mcentral,即在 MCentral 这层数据管理中,实际上有 Span Class 个 mcentral 小内存管理单元。
- NonEmpty Span List(非空,退还的 span 放里面)
表示还有可用空间的 Span 链表。链表中的所有 Span 都至少有 1 个空闲的 Object 空间。如果 MCentral 上游 MCache 退还 Span,会将退还的 Span 加入到 NonEmpty Span List 链表中。
- Empty Span List(可能为空,分配的 span 放这里)
表示没有可用空间的 Span 链表。该链表上的 Span 都不确定是否还有空闲的 Object 空间。如果 MCentral 提供给一个 Span 给到上游 MCache,那么被提供的 Span 就会加入到 Empty List 链表中。
注意:go1.16+ 将链表更改为集合,两个集合元素为了GC,一个已扫描,一个未扫描。
type mcentral struct {
// mcentral对应的spanClass
spanclass spanClass
partial [2]spanSet // 维护全部空闲的Span集合
full [2]spanSet // 维护存在非空闲的Span集合
}
- 1
- 2
- 3
- 4
- 5
- 6
MHeap
MHeap 是对内存块的管理对象,是通过 Page 为内存单元进行管理。用 HeapArena 详细管理每一系列 Page 结构。
1 个 HeapArena 存储着多个连续的 page
MHeap 中 HeapArena 占用了绝大部分的空间,其中每个 HeapArean 包含一个 bitmap,其作用是用于标记当前这个 HeapArena 的内存使用情况。其主要是服务于 GC 垃圾回收模块。
bitmap 共有两种标记,
- 标记对应地址中是否存在对象
- 标记此对象是否被 GC 模块标记过,所以当前
HeapArena中的所有Page均会被bitmap所标记。
ArenaHint 为寻址 HeapArena 的结构,其有三个成员:
(1)addr,为指向的对应 HeapArena 首地址。
(2)down,为当前的 HeapArena 是否可以扩容。
(3)next,指向下一个 HeapArena 所对应的 ArenaHint 首地址。
MCentral 实际上就是隶属于 MHeap 的一部分,从数据结构来看,每个 Span Class 对应一个 MCentral,而之前在分析 Golang 内存管理中的逻辑分层中,是将这些 MCentral 集合统一归类为 MCentral 层。
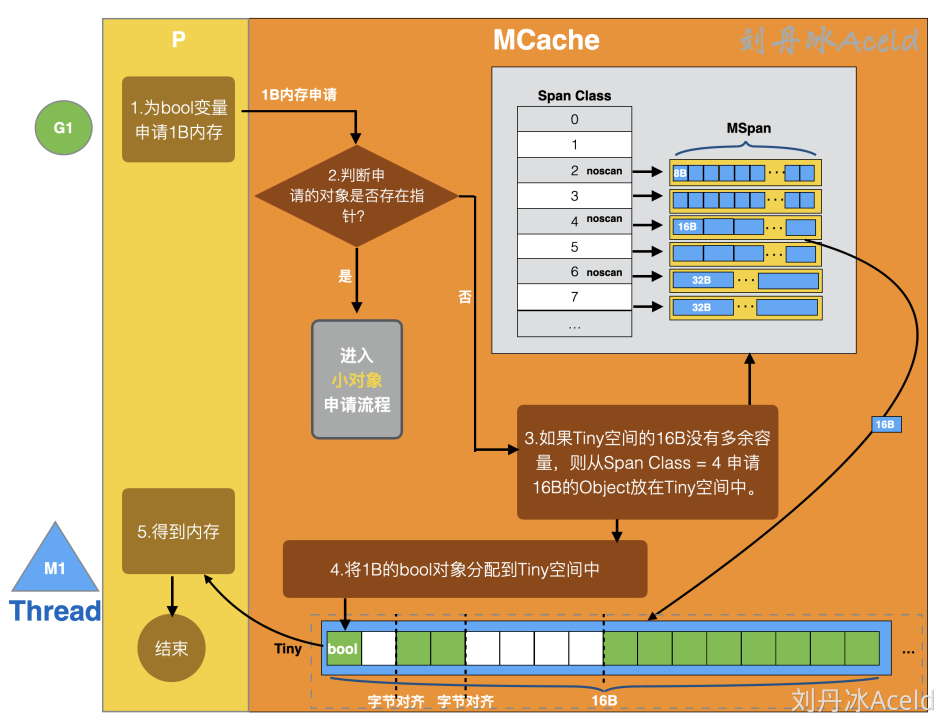
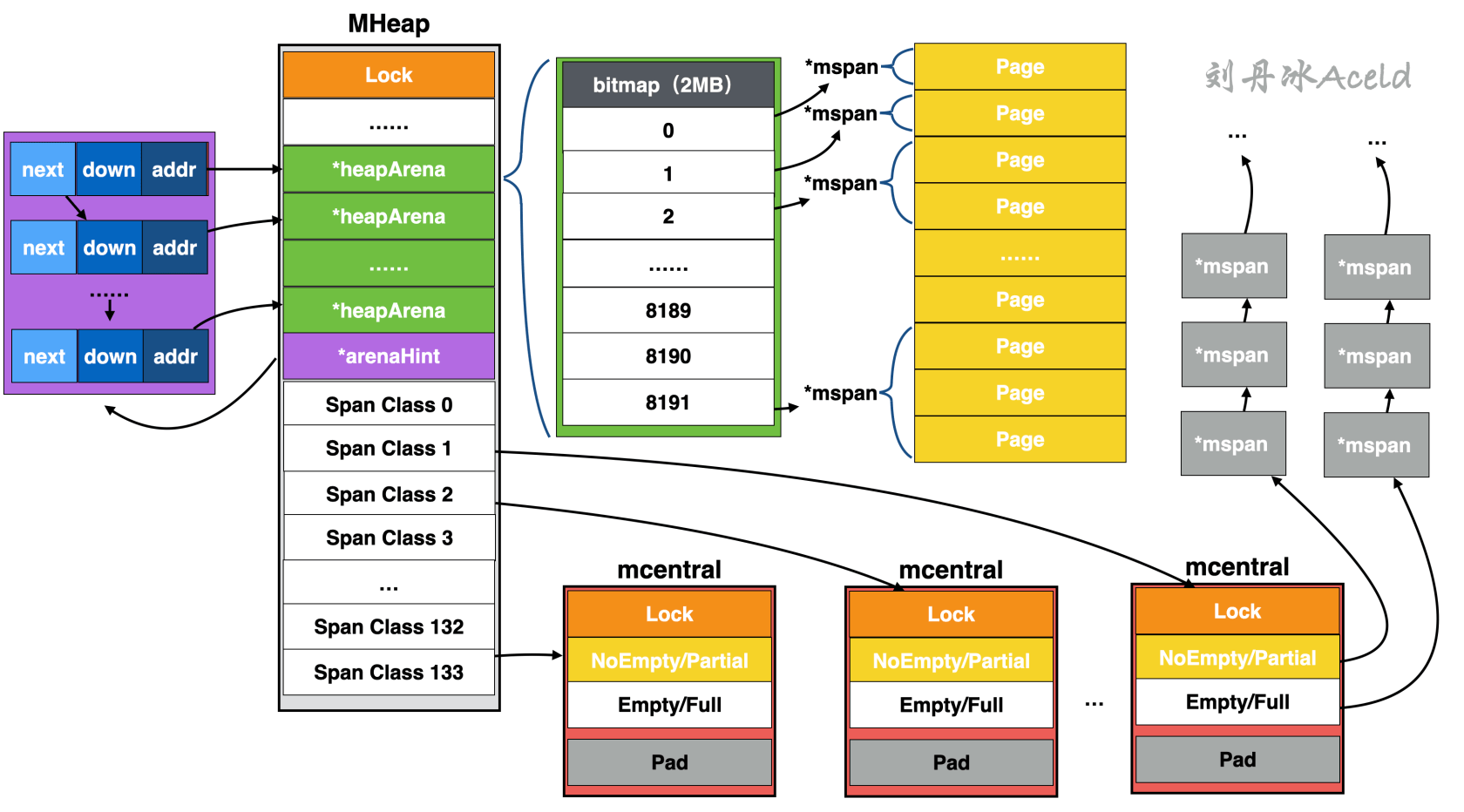
分配流程
Tiny 对象(小于 16B)
在 MCache 中存在一个 Tiny 空间(16B),原因是因为如果协程逻辑层申请的内存空间小于等于 8B,容易造成内存浪费。所以直接开一个连续空间保存 Tiny 对象。
注:不包含指针,否则进入小对象分配。
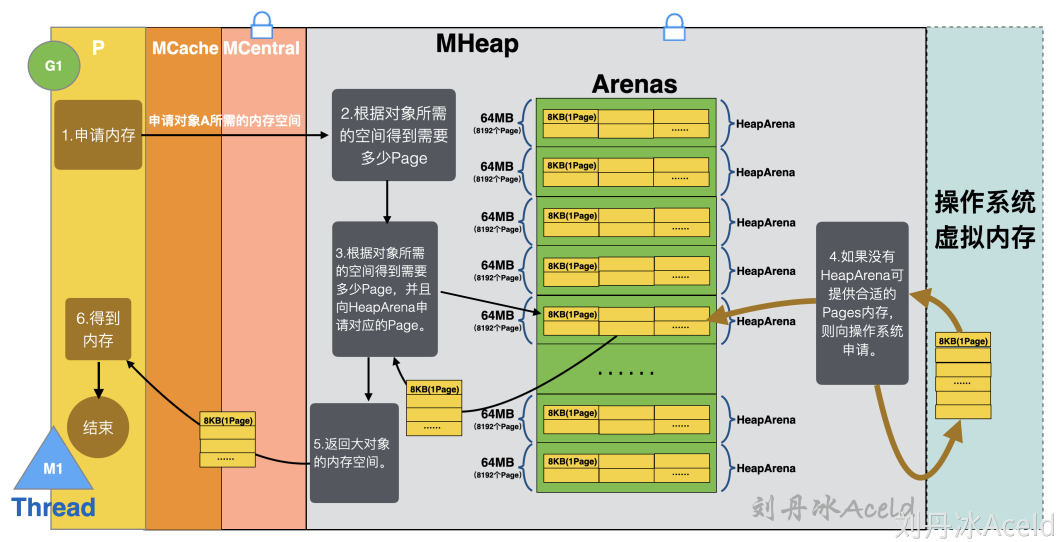
MCache 中对于 Tiny 微小对象的申请流程如下:
- 将类型放置在 16B 的 Tiny 空间中,以字节对齐的方式。
- 如果
Tiny中没有多余的存储空间,则从Span中获取Object放到Tiny缓冲区。
小对象(16B-32B)
对于对象在 16B 至 32B 的内存分配,Golang 会采用小对象的分配流程

- 根据对象大小找到对齐的
Size Class索引,再根据是否有指针选择不同的mspan链表分配object - 如果定位的
Span Class中的Span所有的内存块Object都被占用,则MCache会向MCentral申请一个Span。 - 如果
MCache中不够会去MCenter中请求Span,MCenter会从非空链表中获取Span,然后MCache取其中的Object返回。 - 如果
MCenter中没有对应的Span就会向操作系统申请。
大对象(大于 32B)
大对象是直接从 MHeap 中分配。对于不满足 MCache 分配范围的对象,均是按照大对象分配流程处理。
大对象分配流程是协程逻辑层直接向 MHeap 申请对象所需要的适当 Pages,从而绕过从 MCaceh 到 MCentral 的繁琐申请内存流程。
- MHeap 根据对象所需的空间计算得到需要多少个
Page。 - 如果
Arenas中没有Heap可提供合适的Pages内存,则向操作系统的虚拟内存申请,且填充至Arenas中。
Go 栈内存管理
栈区的内存一般由编译器自动分配和释放,其中存储着函数的入参以及局部变量,这些参数会随着函数的创建而创建,函数的返回而消亡,一般不会在程序中长期存在,这种线性的内存分配策略有着极高地效率。
逃逸分析
手动分配可能会出现问题:
- 不需要分配在堆中的元素分配到堆中:浪费空间,效率低
- 应该分配在堆上的分配到栈上:悬挂指针,影响内存安全
go 语言编译器会自动决定把一个变量放在栈还是放在堆,编译器会做逃逸分析,当发现变量的作用域没有跑出函数范围,就可以在栈上,反之则必须分配在堆。(堆中的变量引用了栈上的变量)
可以在函数定义时添加 //go:noinline 编译指令来阻止编译器内联函数
逃逸规则
引用对象的引用类型赋值
一般而言,给一个引用对象的引用类成员进行赋值可能出现逃逸现象
Go 语言中的引用类型有 func(函数类型),interface(接口类型),slice(切片类型),map(字典类型),channel(管道类型),*(指针类型) 等。
切片扩容或容量太大
大小未知 或 栈空间不足,逃逸到堆上。
channel 传指针,无法确定路径
闭包
逃逸案例
// 1. slice 为引用类型,interface{} 为引用类型,所以 二次访问 造成后者逃逸 data := []interface{}{1,2} data[0] = 2 // 2. map 引用类型,interface{} 引用类型,造成后者逃逸 data := make(map[string]interface{}) data["key"] = 200 //3. map 引用类型,interface{} 引用类型, 造成kv逃逸 data := make(map[interface{}]interface{}) data[100] = 200 //4. map 引用, []string 引用,造成后者逃逸 data := make(map[string][]string) data["key"] = []string{"value"} //5. [] 引用,*int 引用,后者逃逸 data := []*int{nil} data[0] = &a // a逃逸 //6. func 引用,*int 引用,导致后者逃逸 data := 10 f := foo f(&data) fmt.Println(data) // data逃逸 //7. func 引用,[]string 引用,后者逃逸 s := []string{"aceld"} foo(s) fmt.Println(s) // s逃逸 //8. chan 引用,[]string 引用,后者逃逸 ch := make(chan []string) s := []string{"aceld"} go func() { ch <- s }()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
栈内存空间
栈专门为了函数执行而准备的,存储着函数中的局部变量以及调用栈,内存用完就可以直接释放。
Go 语言使用用户态线程 Goroutine 作为执行上下文,它的额外开销和默认栈大小都比线程小很多。
- v1.0 ~ v1.1 — 最小栈内存空间为
4KB; - v1.2 — 将最小栈内存提升到了
8KB; - v1.3 — 使用连续栈 替换之前版本的分段栈;
- v1.4 — 将最小栈内存降低到了
2KB;
从 4KB 提升到 8KB 是临时的解决方案,其目的是为了减轻分段栈中的栈分裂对程序的性能影响
分段栈
所有 Go 程在初始化时会分配一块固定内存空间。
当 Goroutine 调用的函数层级或者局部变量需要的越来越多时,运行时会创建一个新的栈空间,这些栈空间虽然不连续,但是当前 Goroutine 的多个栈空间会以链表的形式串联起来,运行时会通过指针找到连续的栈片段:
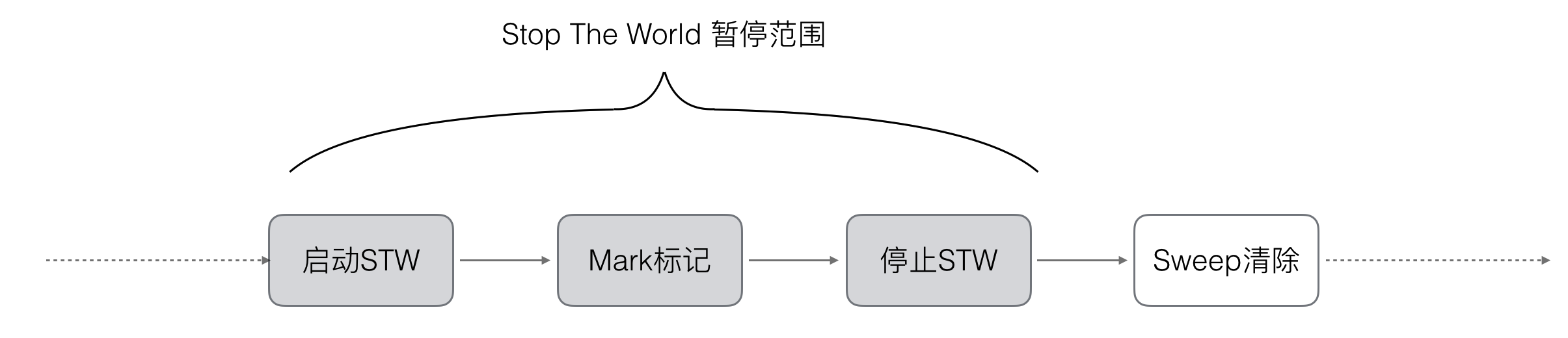
一旦申请的栈空间不需要,运行时就会释放。
分段栈机制虽然能够按需为当前 Goroutine 分配内存并且及时减少内存的占用,但是它也存在两个比较大的问题:
- 如果当前 Goroutine 的栈几乎充满,那么任意的函数调用都会触发栈扩容,当函数返回后又会触发栈的收缩,如果在一个循环中调用函数,栈的分配和释放就会造成巨大的额外开销,这被称为热分裂问题;
- 一旦
Goroutine使用的内存越过了分段栈的扩缩容阈值,运行时会触发栈的扩容和缩容,带来额外的工作量;
连续栈
其核心原理是每当程序的栈空间不足时,初始化一片更大的栈空间并将原栈中的所有值都迁移到新栈中,新的局部变量或者函数调用就有充足的内存空间。
扩容操作:
- 在内存空间中分配更大的栈内存空间;
- 将旧栈中的所有内容复制到新栈中;
- 将指向旧栈对应变量的指针重新指向新栈;
- 指向栈对象的指针不能存在于堆中,所以指向栈中变量的指针只能在栈上,我们只需要调整栈中的所有变量就可以保证内存的安全了。
- 销毁并回收旧栈的内存空间;
因为需要拷贝变量和调整指针,连续栈增加了栈扩容时的额外开销,但是通过合理栈缩容机制就能避免热分裂带来的性能问题。
在 GC 期间如果 Goroutine 使用了栈内存的四分之一,那就将其内存减少一半,这样在栈内存几乎充满时也只会扩容一次,不会因为函数调用频繁扩缩容。
Go GC
刘丹冰 yyds Draven 也是 这位也是
垃圾回收是编程语言中提供的自动的内存管理机制,自动释放不需要的对象,让出存储器资源,无需程序员手动执行。
GC 回收的是什么?
在应用程序中会使用到两种内存,分别为堆(Heap)和栈(Stack),GC负责回收堆内存,而不负责回收栈中的内存。
GC 算法的种类
主流的垃圾回收算法有两大类,分别是追踪式垃圾回收算法和引用计数法。而 Go 语言现在用的三色标记法就属于追踪式垃圾回收算法的一种。
Go 垃圾回收算法
Go 的垃圾收集器从一开始到现在一直在演进,
- V1.3 标记清除算法
- 从 v1.5 版本 Go 实现了基于三色标记清除的并发垃圾收集器,大幅度降低垃圾收集的延迟从几百 ms 降低至 10ms 以下
- 在 v1.8 又使用混合写屏障将垃圾收集的时间缩短至 0.5ms 以内。
GC 触发时机
- 内存达到上限或内存扩大一倍
- 定期删除
- 手动触发
Go1.3 标记-清除
此算法主要有两个步骤:
- 暂停应用程序的执行, 从根对象出发标记出可达对象。
- 清除未标记的对象,恢复应用程序的执行。
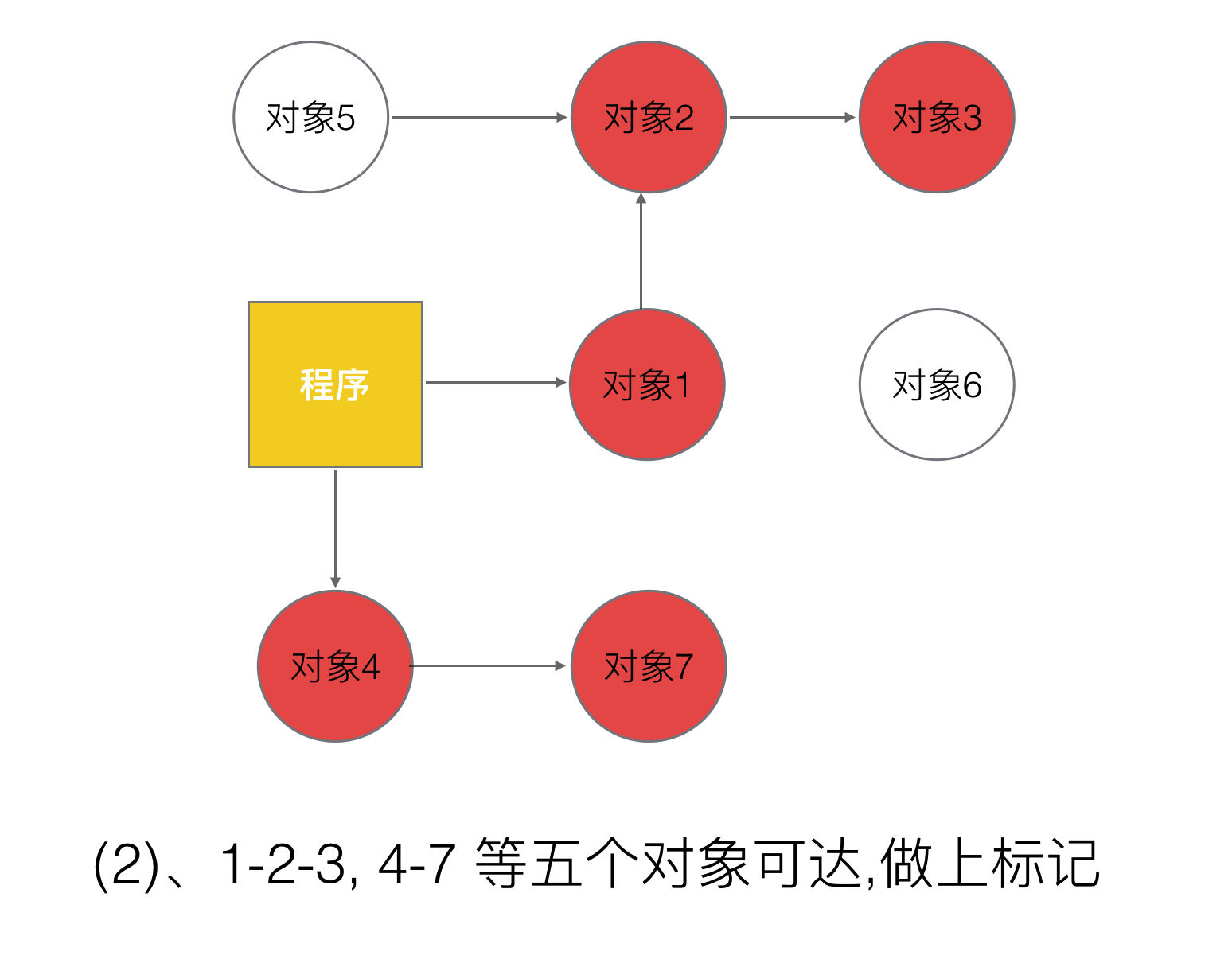
缺点
- 全程 STW,程序卡顿
- 标记需要扫描整个堆
- 清除数据会产生碎片
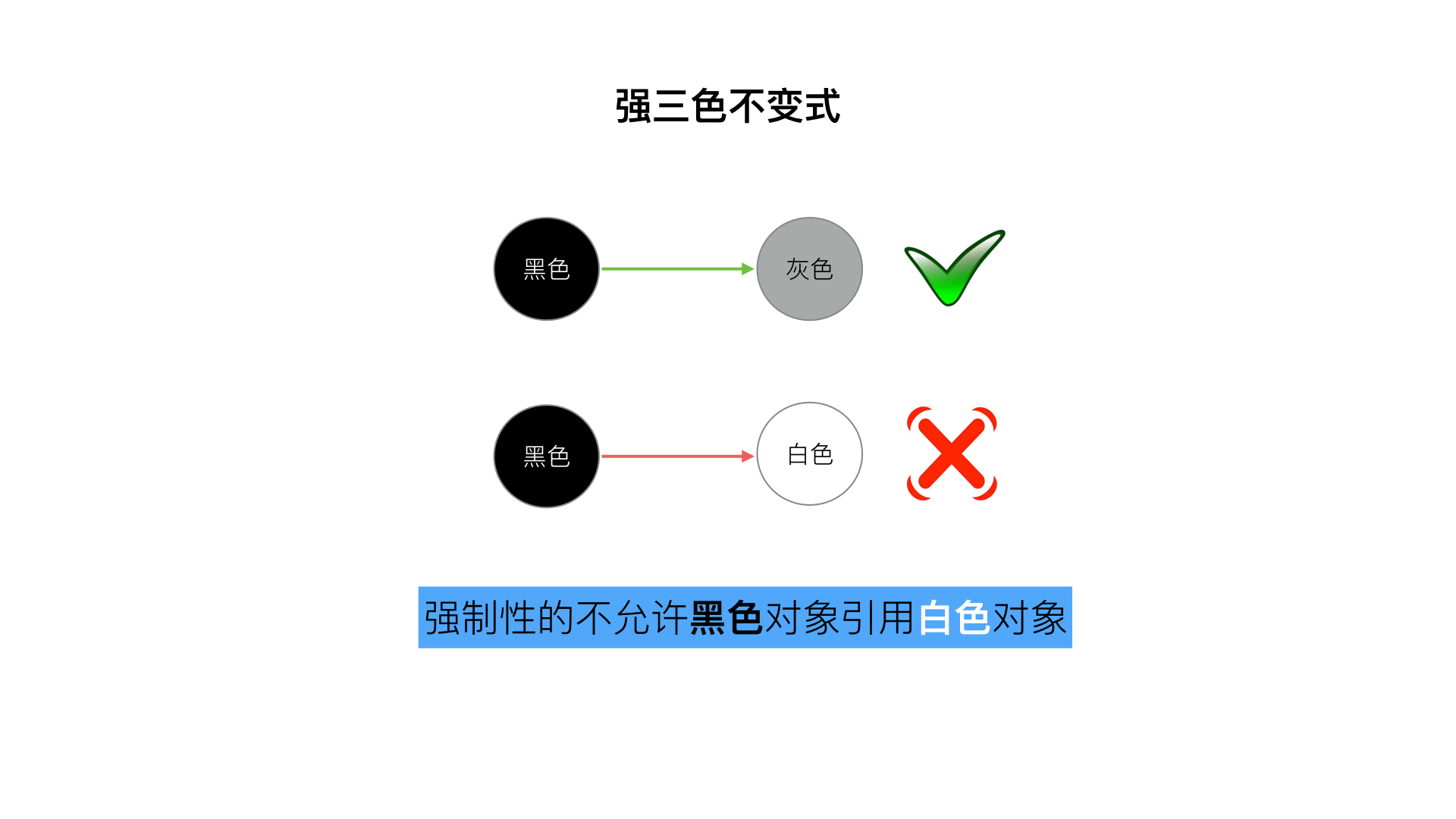
Go1.5 三色并发标记清除法
三色标记算法将程序中的对象分成白色、黑色和灰色三类:
- 白色对象 — 潜在的垃圾,其内存可能会被垃圾收集器回收;
- 黑色对象 — 活跃的对象,包括不存在任何引用外部指针的对象以及从根对象可达的对象,垃圾回收器不会扫描这些对象的子对象;
- 灰色对象 — 活跃的对象,因为存在指向白色对象的外部指针,垃圾收集器会扫描这些对象的子对象;
普通三色并发标记流程
- GC 开始时会从根节点遍历所有对象,标记为灰色
- 按顺序遍历灰色节点,将其引用的白色节点标记为灰色,最后此灰色节点标记为黑色
- 重复步骤 2,直到没有灰色节点,清除所有白色节点
因为此过程可能会改变指针的引用,导致内存安全性问题所以需要 STW。
Eg:灰断开白且黑指向白:导致被引用对象被清除(这个白色如果有下游,也会被清除)
三色不变性
想让并发或者增量算法中保证正确性,需要满足两种三色不变性中的一种
- 强三色不变性:黑不能指向白
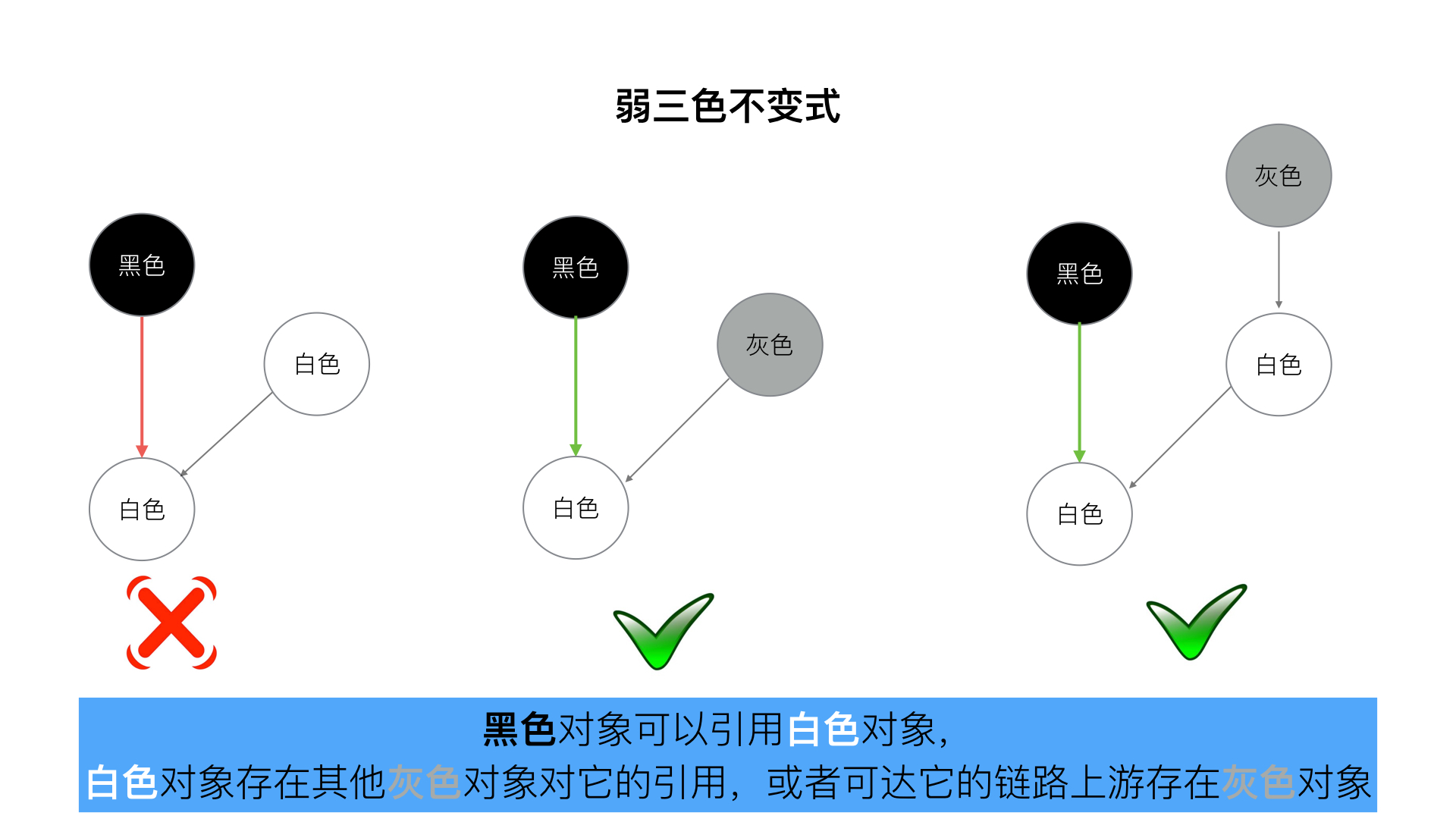
- 弱三色不变性:黑指向的白必须被灰间接或直接引用

内存屏障
为了遵循上述的两个方式,Go 团队初步得到了两种屏障方式“插入屏障”, “删除屏障”.
插入写屏障:满足强三色不变性(黑引用白色)
在更新和新增节点时,被引用的白色对象会被标记为灰色。
- 栈空间的特点是容量小,但是要求相应速度快,因为函数调用弹出频繁使用, 所以“插入屏障”机制,在栈空间的对象操作中不使用.
- 但是如果栈不添加,当全部三色标记扫描之后,栈上有可能依然存在白色对象被引用的情况(GC 过程中栈中新连接了一个)
删除写屏障:满足弱三色不变性(灰到白断开)
被删除的对象,如果自身为白色,那么被标记为灰色。
但是这样会导致一个节点即使被删除了最后一个指向它的指针也可以活过这一轮 GC。
所以并发标记清除整个流程就是全部节点并发三色标记一遍,堆空间增加写屏障,然后栈空间 STW 重新标记一遍,最后清除白色节点。
缺点
插入写屏障和删除写屏障的短板:
- 插入写屏障:结束时需要 STW 来重新扫描栈,标记栈上引用的白色对象的存活;
- 删除写屏障:回收精度低,一个对象即使被删除了最后一个指向它的指针也依旧可以活过这一轮,在下一轮GC中被清理掉。
Go1.8 混合写屏障
Go V1.8 版本引入了混合写屏障机制,避免了对栈 re-scan 的过程,极大的减少了 STW 的时间。结合了插入写和删除写的优点。
规则
1、GC开始将栈上的可达对象标记为黑色(之后不再进行第二次重复扫描,无需 STW),
2、GC期间,任何在栈上创建的新对象,均为黑色。
3、删除写:被删除的对象标记为灰色。
4、插入写:被添加的对象标记为灰色。
注意:屏障技术不在栈上使用
场景
GC 开始,扫描栈,将所有可达对象标记为黑。
- 对象被一个堆对象删除引用,成为栈对象的下游(灰色删除,黑色添加)
触发删除写,标记白色对象为灰
- 对象被一个栈对象删除引用,成为另一个栈对象的下游(栈空间无屏障)
反正也是黑色节点,无影响
- 对象被一个堆对象删除引用,成为另一个堆对象的下游(灰色删除,黑色添加)
触发屏障,标记白色对象为灰
- 对象从一个栈对象删除引用,成为另一个堆对象的下游(灰色断开)
触发插入写屏障,白色对象标记为灰
总结
只需要在开始时并发扫描各个 goroutine 的栈,使其变黑并一直保持,这个过程不需要 STW,而标记结束后,因为栈在扫描后始终是黑色的,也无需再进行 re-scan 操作了,减少了 STW 的时间。
Go 内存管理和优化
分块
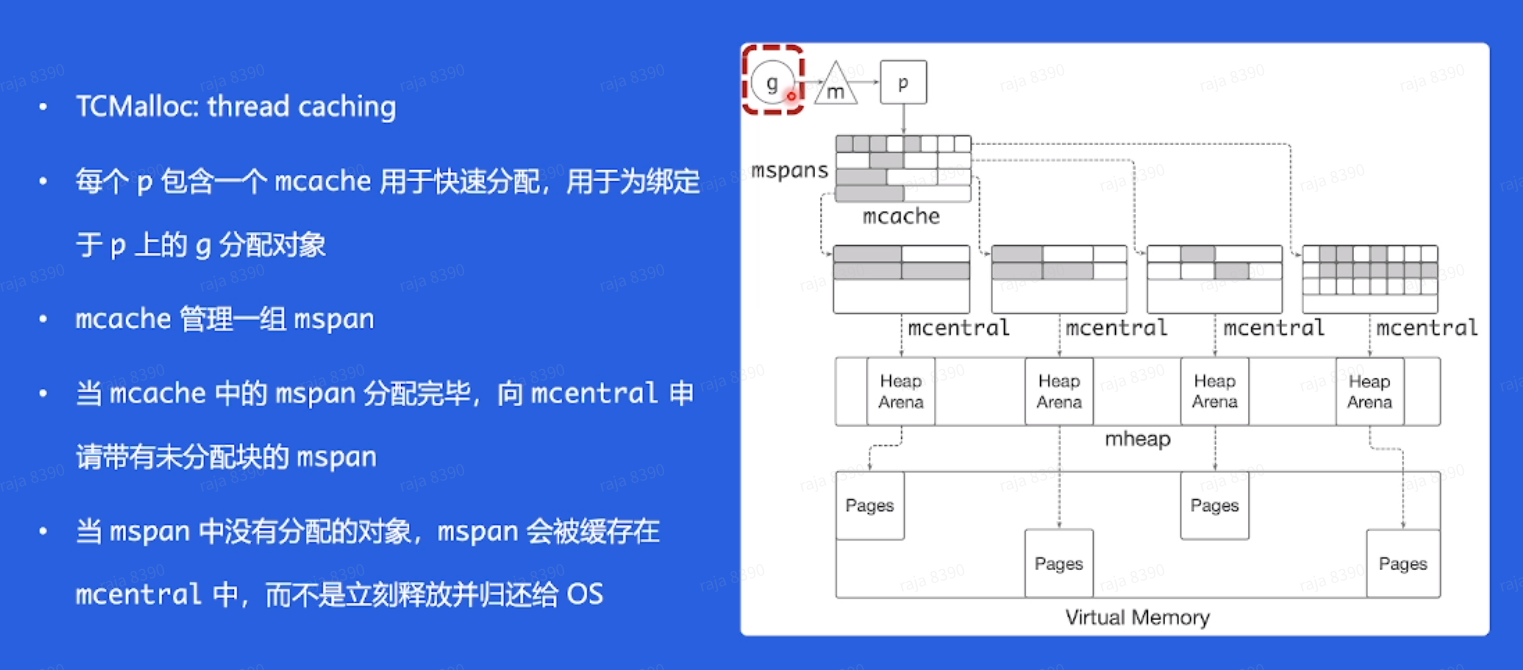
缓存

优化
小对象分配过多,分配路径过长

元编程
插件系统
设计原理
Go 语言的插件系统基于 C 语言动态库实现的,所以它也继承了 C 语言动态库的优点和缺点。
-
静态库或者静态链接库是由编译期决定的程序、外部函数和变量构成的,编译器或者链接器会将程序和变量等内容拷贝到目标的应用并生成一个独立的可执行对象文件;
- 可以独立运行,但是二进制文件较大
-
动态库或者共享对象可以在多个可执行文件之间共享,程序使用的模块会在运行时从共享对象中加载,而不是在编译程序时打包成独立的可执行文件;
- 可以在多个可执行文件之间共享,减少内存占用,一般在运行期间装载。
插件系统
通过在主程序和共享库直接定义一系列的约定或者接口,我们可以通过以下的代码动态加载其他人编译的 Go 语言共享对象,这样做的好处是主程序和共享库的开发者不需要共享代码,只要双方的约定不变,修改共享库后也不需要重新编译主程序。
type Driver interface { Name() string } func main() { p, err := plugin.Open("driver.so") if err != nil { panic(err) } newDriverSymbol, err := p.Lookup("NewDriver") if err != nil { panic(err) } // 寻找任何可以导出的变量或函数 newDriverFunc := newDriverSymbol.(func() Driver) newDriver := newDriverFunc() fmt.Println(newDriver.Name()) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
定义一个接口,并且动态库实现了它,当我们通过 plugin.Open 读取包含 Go 语言插件的共享库后,获取文件中的 NewDriver 符号并转换成正确的函数类型,可以通过该函数初始化新的 Driver 并获取它的名字了。
操作系统
Linux 中的共享对象会使用 ELF 格式并提供了一组操作动态链接器的接口
void *dlopen(const char *filename, int flag);
char *dlerror(void);
void *dlsym(void *handle, const char *symbol);
int dlclose(void *handle);
- 1
- 2
- 3
- 4
dlopen 会根据传入的文件名加载对应的动态库并返回一个句柄(Handle);我们可以直接使用 dlsym 函数在该句柄中搜索特定的符号,也就是函数或者变量,它会返回该符号被加载到内存中的地址。因为待查找的符号可能不存在于目标动态库中,所以在每次查找后我们都应该调用 dlerror 查看当前查找的结果。
动态库
Go 语言插件系统的全部实现都包含在 plugin 中,这个包实现了符号系统的加载和决议。插件是一个带有公开函数和变量的包,我们需要使用下面的命令编译插件:
go build -buildmode=plugin ...
该命令会生成一个共享对象 .so 文件,当该文件被加载到 Go 语言程序时会使用下面的结构体 plugin.Plugin 表示,该结构体中包含文件的路径以及包含的符号等信息:
type Plugin struct {
pluginpath string // 插件路径
syms map[string]interface{} // 符号信息
...
}
- 1
- 2
- 3
- 4
- 5
与插件系统相关的两个核心方法分别是用于加载共享文件的 plugin.Open 和在插件中查找符号的 plugin.Plugin.Lookup
CGO
包中使用的两个 C 语言函数 plugin.pluginOpen 和 plugin.pluginLookup;plugin.pluginOpen 只是简单包装了一下标准库中的 dlopen 和 dlerror 函数并在加载成功后返回指向动态库的句柄:
static uintptr_t pluginOpen(const char* path, char** err) {
void* h = dlopen(path, RTLD_NOW|RTLD_GLOBAL);
if (h == NULL) {
*err = (char*)dlerror();
}
return (uintptr_t)h;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
plugin.pluginLookup 使用了标准库中的 dlsym 和 dlerror 获取动态库句柄中的特定符号:
static void* pluginLookup(uintptr_t h, const char* name, char** err) {
void* r = dlsym((void*)h, name);
if (r == NULL) {
*err = (char*)dlerror();
}
return r;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
加载过程
用于加载共享对象的函数 plugin.Open 会将共享对象文件的路径作为参数并返回 plugin.Plugin 结构
func Open(path string) (*Plugin, error) {
return open(path)
}
- 1
- 2
- 3
上述函数会调用私有的函数 plugin.open 加载插件,它是插件加载过程的核心函数,我们可以将该函数拆分成以下几个步骤:
- 准备 C 语言函数 plugin.pluginOpen 的参数;
- 通过 cgo 调用 plugin.pluginOpen 并初始化加载的模块;
- 查找加载模块中的
init函数并调用该函数; - 通过插件的文件名和符号列表构建 plugin.Plugin 结构;
推荐阅读
代码生成
元编程:使用代码生成代码
Go 语言的代码生成机制会读取包含预编译指令的注释,然后执行注释中的命令读取包中的文件,然后生成新的 go 代码文件,最后一起编译运行
//go:generate command argument...
go generate 不会被 go build 等命令自动执行,该命令需要显式的触发,手动执行该命令时会在文件中扫描上述形式的注释并执行后面的执行命令,需要注意的是 go:generate 和前面的 // 之间没有空格,这种不包含空格的注释一般是 Go 语言的编译器指令,而我们在代码中的正常注释都应该保留这个空格。
代码生成最常见的例子就是官方提供的 stringer,这个工具可以扫描如下所示的常量定义,然后为当前常量类型 Piller 生成对应的 String() 方法:
package painkiller
//go:generate stringer -type=Pill
type Pill int
const (
Placebo Pill = iota
Aspirin
Ibuprofen
Paracetamol
Acetaminophen = Paracetamol
)
// 元编程: 为以上类型生成String()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
然后执行 go generate 会自动生成 pill_string.go 文件
代码生成的过程可以分成以下两个部分:
- 扫描 Go 语言源文件,查找待执行的
//go:generate预编译指令; - 执行预编译指令,再次扫描源文件并根据源文件中的代码生成代码;
包管理
Go Modules
https://learnku.com/docs/go-mod/1.17/intro/11438
Go modules 是 Go 语言的依赖解决方案,发布于 Go1.11,成长于 Go1.12,丰富于 Go1.13,正式于 Go1.14 推荐在生产上使用。
Go moudles 目前集成在 Go 的工具链中,只要安装了 Go,自然而然也就可以使用 Go moudles 了,而 Go modules 的出现也解决了在 Go1.11 前的几个常见争议问题:
- Go 语言长久以来的依赖管理问题。
- “淘汰”现有的 GOPATH 的使用模式。
- 统一社区中的其它的依赖管理工具(提供迁移功能)。
GOPATH 模式
// GOPATH下
go
├── bin // 存储所编译生成的二进制文件。
├── pkg // 存储预编译的目标文件,以加快程序的后续编译速度。
└── src // 存储所有.go文件或源代码
├── github.com
├── golang.org
├── google.golang.org
├── gopkg.in
....
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- A. 无版本控制概念. 在执行
go get的时候,你无法传达任何的版本信息的期望,也就是说你也无法知道自己当前更新的是哪一个版本,也无法通过指定来拉取自己所期望的具体版本。 - B.无法同步一致第三方版本号. 在运行 Go 应用程序的时候,你无法保证其它人与你所期望依赖的第三方库是相同的版本,也就是说在项目依赖库的管理上,你无法保证所有人的依赖版本都一致。
- C.无法指定当前项目引用的第三方版本号. 你没办法处理 v1、v2、v3 等等不同版本的引用问题,因为 GOPATH 模式下的导入路径都是一样的,都是
Go Modules 模式
go mod 环境变量
go mod 环境变量
$ go env
GO111MODULE="auto"
GOPROXY="https://proxy.golang.org,direct"
GONOPROXY=""
GOSUMDB="sum.golang.org"
GONOSUMDB=""
GOPRIVATE=""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
GO111MODULE
Go 语言提供了 GO111MODULE 这个环境变量来作为 Go modules 的开关,其允许设置以下参数:
- auto:只要项目包含了 go.mod 文件的话启用 Go modules,目前在 Go1.11 至 Go1.14 中仍然是默认值。
- on:启用 Go modules,推荐设置,将会是未来版本中的默认值。
- off:禁用 Go modules,不推荐设置。
设置:go env -w GO111MODULE=on
GOPROXY
这个环境变量主要是用于设置 Go 模块代理,其作用是用于使 Go 在后续拉取模块版本时直接通过镜像站点来快速拉取。
GOPROXY 的默认值是:https://proxy.golang.org,direct
proxy.golang.org 国内访问不了,需要设置国内的代理.
- 阿里云
- https://mirrors.aliyun.com/goproxy/
- 七牛云
- https://goproxy.cn,direct
eg:$ go env -w GOPROXY=``https://goproxy.cn``,direct
GOPROXY 的值是一个以英文逗号 , 分割的 Go 模块代理列表,允许设置多个模块代理,假设你不想使用,也可以将其设置为 “off” ,这将会禁止 Go 在后续操作中使用任何 Go 模块代理。
而在刚刚设置的值中,我们可以发现值列表中有 “direct” 标识,它又有什么作用呢?
实际上 “direct” 是一个特殊指示符,用于指示 Go 回源到模块版本的源地址去抓取(比如 GitHub 等),场景如下:当值列表中上一个 Go 模块代理返回 404 或 410 错误时,Go 自动尝试列表中的下一个,遇见 “direct” 时回源,也就是回到源地址去抓取,而遇见 EOF 时终止并抛出类似 “invalid version: unknown revision…” 的错误。
GOSUMDB
它的值是一个 Go checksum database,用于在拉取模块版本时(无论是从源站拉取还是通过 Go module proxy 拉取)保证拉取到的模块版本数据未经过篡改,若发现不一致,也就是可能存在篡改,将会立即中止。
GOSUMDB 的默认值为:sum.golang.org,在国内也是无法访问的,但是 GOSUMDB 可以被 Go 模块代理所代理(详见:Proxying a Checksum Database)。
因此我们可以通过设置 GOPROXY 来解决,而先前我们所设置的模块代理 goproxy.cn 就能支持代理 sum.golang.org,所以这一个问题在设置 GOPROXY 后,你可以不需要过度关心。
另外若对 GOSUMDB 的值有自定义需求,其支持如下格式:
- 格式 1:
<SUMDB_NAME>+<PUBLIC_KEY>。 - 格式 2:
<SUMDB_NAME>+<PUBLIC_KEY> <SUMDB_URL>。
也可以将其设置为“off”,也就是禁止 Go 在后续操作中校验模块版本。
GONOPROXY/GONOSUMDB/GOPRIVATE
这三个环境变量都是用在当前项目依赖了私有模块,例如像是你公司的私有 git 仓库,又或是 github 中的私有库,都是属于私有模块,都是要进行设置的,否则会拉取失败。
更细致来讲,就是依赖了由 GOPROXY 指定的 Go 模块代理或由 GOSUMDB 指定 Go checksum database 都无法访问到的模块时的场景。
而一般建议直接设置 GOPRIVATE,它的值将作为 GONOPROXY 和 GONOSUMDB 的默认值,所以建议的最佳姿势是直接使用 GOPRIVATE。
并且它们的值都是一个以英文逗号 “,” 分割的模块路径前缀,也就是可以设置多个,例如:
$ go env -w GOPRIVATE="git.example.com,github.com/eddycjy/mquote" 设置后,前缀为 git.xxx.com 和 github.com/eddycjy/mquote 的模块都会被认为是私有模块。
如果不想每次都重新设置,我们也可以利用通配符,例如:
$ go env -w GOPRIVATE="*.example.com"
这样子设置的话,所有模块路径为 example.com 的子域名(例如:git.example.com)都将不经过 Go module proxy 和 Go checksum database,需要注意的是不包括 example.com 本身。
初始化项目
- 开启 go mod
$ go env -w GO111MODULE=on
又或是可以通过直接设置系统环境变量(写入对应的~/.bash_profile 文件亦可)来实现这个目的:
$ export GO111MODULE=on
- 初始化项目
go mod init 项目仓库地址
- 之后创建
main.go
package main
import (
"fmt"
"github.com/aceld/zinx/znet"
"github.com/aceld/zinx/ziface"
)
func main(){
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
然后 go get github.com/aceld/zinx/znet 拉取依赖
项目目录下 go.mod 被修改,出现 go.sum
- go.mod
module github.com/aceld/modules_test // 项目基本路径 如果你的版本已经大于等于2.0.0,按照Go的规范,你应该加上major的后缀(例:module github.com/panicthis/modfile/v2)
go 1.14 // 标识最低支持go版本
require github.com/aceld/zinx v0.0.0-20200221135252-8a8954e75100 // indirect 间接依赖
- 1
- 2
- 3
- 4
- 5
// 语义化版本
// {MAJOR}.{MINOR}.{PATCH}
// {不兼容更新}.{新增功能}.{bug修复}
- 1
- 2
- 3
// indirect 间接依赖
// 当前项目依赖A,但是A的go.mod遗漏了B, 那么就会在当前项目的go.mod中补充B, 加indirect注释
// 当前项目依赖A,但是A没有go.mod,同样就会在当前项目的go.mod中补充B, 加indirect注释
// 当前项目依赖A,A又依赖B,当对A降级的时候,降级的A不再依赖B,这个时候B就标记indirect注释
- 1
- 2
- 3
- 4
// +incompatible 兼容一些没用mod管理的包或者版本>=2.0.0却没有加后缀的包
- 1
- go.sum
其详细罗列了当前项目直接或间接依赖的所有模块版本,并写明了那些模块版本的 SHA-256 哈希值以备 Go 在今后的操作中保证项目所依赖的那些模块版本不会被篡改。
最小版本控制 MVS
原文
MVS 在模块的有向图上运行,由 go.mod 文件 指定。 图中的每个顶点代表一个模块版本。 每条边代表依赖项的最低要求版本,使用 require 指令指定。 在主模块的 go.mod 文件中,使用 replace 和 exclude 指令修改图形。
MVS 从主模块开始(图中没有版本的特殊顶点),并遍历图,跟踪每个模块所需的最高版本。在遍历结束时,所需的最高版本构成构建列表:它们是满足所有要求的最低版本。
考虑下图中的示例。主模块需要模块 A 和 模块 B 最低 1.2 版本,A 1.2 和 B 1.2 分别依赖 C 1.3 和 C 1.4, C 1.3 和 C 1.4 都依赖 D 1.2。
MVS 访问并加载所有标蓝版本模块的 go.mod 文件。在图上遍历结束时,MVS 返回一个包含粗体版本的构建列表:A 1.2、B 1.2、C 1.4 和 D 1.2。请注意,可以使用更高版本的 B 和 D,但 MVS 不会选择它们,因为不需要它们。
go get 指令
原文
下载导入路径指定的包及其依赖项,然后安装命名包,即执行 go install 命令。 用法如下:
go get
go get [-d] [-f] [-t] [-u] [-fix] [-insecure] [build flags] [packages]
go install
和 go build 命令比较相似,go build 命令会编译包及其依赖,生成的文件存放在当前目录下。而且 go build 只对 main 包有效,其他包不起作用。
而 go install 对于非 main 包会生成静态文件放在 $GOPATH/pkg 目录下,文件扩展名为 a。 如果为 main 包,则会在 $GOPATH/bin 下生成一个和给定包名相同的可执行二进制文件。
具体语法如下:
go install [-i] [build flags] [packages]
拓展
Go 初始化顺序
init 初始化,变量初始化
- go 初始化顺序 包作用域变量->init()->main()
- runtime 需要解析包依赖关系,没有依赖的包最先初始化,没有依赖的变量先初始化
- 一个包内的 init()根据文件名字典序初始化
- 不同包根据依赖关系来加载包,先初始化包变量,再初始化包内 init()
// a.go of pack
package pack
import (
"fmt"
)
var _ = func() int {
fmt.Println("init var in a.go of pack")
return 0
}()
func init() {
fmt.Println("init in a.go of pack")
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
// pack.go of pack package pack import ( "fmt" "test" ) var Pack string = "pack.Val" var _ = func() int { fmt.Println("init var in pack.go of pack") return 1 }() func init() { fmt.Println("init in pack.go of pack:", test.Util) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
// test.go of test
import (
"fmt"
)
var Util string = "test.Val"
var _ = func() int {
fmt.Println("init var in test.go of test")
return 1
}()
func init() {
fmt.Println("init test.go of test")
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
// main.go package main import ( "fmt" "pack" "test" ) // main -> pack -> test // 由于 pack 包的初始化依赖 test,因此运行时先初始化 test 再初始化 pack 包; func main() { fmt.Println(pack.Pack) fmt.Println(test.Util) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
结果:
init var in test.go of test # test var
init test.go of test # test init()
init var in a.go of pack # pack var1
init var in pack.go of pack # pack var2
init in a.go of pack # pack init()
init in pack.go of pack: test.Val # pack init()
pack.Val # main
test.Val
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
fmt 占位符
func main() { var n = 100 fmt.Printf("%T\n", n) // 类型 fmt.Printf("%v\n", n) // 相应值的默认格式 fmt.Printf("%b\n", n) // 二进制表示 fmt.Printf("%d\n", n) // 十进制表示 fmt.Printf("%o\n", n) // 八进制表示 fmt.Printf("%x\n", n) // 十六进制表示,字母形式为小写 a-f var s = "Hello,你好!" fmt.Printf("%s\n", s) // 输出字符串表示(string类型或[]byte) fmt.Printf("%v\n", s) // 相应值的默认格式。 fmt.Printf("%#v\n", s) // %#v 输出字符串具体描述,相应值的Go语法表示 fmt.Printf("%#v\n", n) /* 但是,紧跟在verb之前的[n]符号表示应格式化第n个参数(索引从1开始)。 同样的在'*'之前的[n]符号表示采用第n个参数的值作为宽度或精度。 在处理完方括号表达式[n]后,除非另有指示,会接着处理参数n+1,n+2…… (就是说移动了当前处理位置) */ fmt.Printf("%[2]d %[1]d", 11, 2) fmt.Printf("%[3]*.[2]*[1]d", 12, 2, 6) fmt.Printf("%6.2d", 12) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
unsafe
*类型:普通指针类型,用于传递对象地址,不能进行指针运算。unsafe.Pointer: 通用指针类型,用于转换不同类型的指针,不能进行指针运算,不能读取内存存储的值(必须转换到某一类型的普通指针)。uintptr: 用于指针运算,GC 不把uintptr当指针,uintptr无法持有对象。uintptr类型的目标会被回收。
// 接受任意类型的值 (表达式),返回其占用的字节数
func Sizeof(x ArbitraryType) uintptr
// 返回类型 x 的对齐系数;若是结构体类型的字段的形式,它会返回字段 f 在该结构体中的对齐方式。
func Alignof(x ArbitraryType) uintptr
// 返回类型 x 所代表的结构体字段在结构体中的偏移量
func Offsetof(x ArbitraryType) uintptr
- 1
- 2
- 3
- 4
- 5
- 6
其包含四种核心操作:
- 任何类型的指针值都可以转换为 Pointer
- Pointer 可以转换为任何类型的指针值
- uintptr 可以转换为 Pointer
- Pointer 可以转换为 uintptr
// package priv type V struct { i int32 j int64 } func (v *V) PutI() { fmt.Printf("i=%d\n", v.i) } func (v *V) PutJ() { fmt.Printf("j=%d\n", v.j) } // package main // 访问结构体私有变量 func sample2() { v := new(priv.V) i := (*int32)(unsafe.Pointer(v)) j := (*int64)(unsafe.Pointer(uintptr(unsafe.Pointer(v)) + unsafe.Sizeof(int64(0)))) *i = int32(10) *j = int64(12) v.PutI() v.PutJ() } type tmp struct { a byte // 0-1 b int32 // 4-7 c int64 // 8-15 } // 16 // 计算偏移量 func sample3() { t := new(tmp) fmt.Printf("size:%d\n", unsafe.Sizeof(*t)) // 16 fmt.Printf("a:%d,b:%d,c:%d\n", unsafe.Offsetof(t.a), unsafe.Offsetof(t.b), unsafe.Offsetof(t.c)) fmt.Printf("a:%d,b:%d,c:%d\n", unsafe.Alignof(t.a), unsafe.Alignof(t.b), unsafe.Alignof(t.c)) // } // 通过偏移量取值 func sample4() { t := tmp{ a: 1, b: 2, c: 3, } // fmt.Println(*(*int32)(unsafe.Pointer(uintptr(unsafe.Pointer(&t.a)) + uintptr(4)))) fmt.Println(*(*int32)(unsafe.Add(unsafe.Pointer(&t), 4))) } // 字符串转切片 func sample5() { s := "123" sF := (*reflect.StringHeader)(unsafe.Pointer(&s)) sH := reflect.SliceHeader{ Data: sF.Data, Len: sF.Len, Cap: sF.Len, } sL := *(*[]byte)(unsafe.Pointer(&sH)) fmt.Println(sL) } // 切片转字符串 func sample6() { s := []byte{'1', '2', '3'} str := *(*string)(unsafe.Pointer(&s)) fmt.Println(str) }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70

