
热门标签
热门文章
- 1uniapp 怎么设置凸起的底部tabbar_uniapp底部导航栏中间凸起
- 2第二周周报_入职培训第二周周报
- 3vue3 element-plus el-table:列表中相同名称的数据实现行合并_element-ui el-table span-method合并name相同的行
- 4【PyTorch][chapter 16][李宏毅深度学习][Neighbor Embedding][t-SNE]
- 5H264 码率控制原理
- 6Nightingale发布v5.9.2,新功能解决多个生产痛点,真香_夜莺监控( nightingale ) 新建监控大盘
- 7SQL Server 跨服务器同步或定时同步数据库
- 8es (brain split)脑裂问题导致重建索引速度缓慢_fatal error in thread
- 9汉诺塔问题—java详解(附源码)
- 10为什么 Linux 系统默认页大小是 4KB ?_linux为什么一页是4k
当前位置: article > 正文
使用yolov5进行图像分类、检测、分割任务(labelme转yolov5分割和检测数据集)_labelme制作高精度的分割数据集
作者:羊村懒王 | 2024-02-21 09:12:46
赞
踩
labelme制作高精度的分割数据集
使用yolov5进行图像分类任务
测试用的猫狗数据集
链接:https://pan.baidu.com/s/1p-P6-i58iplOusbI8s8gGA
提取码:1234
yolov5代码
https://github.com/ultralytics/yolov5/
1.分类数据集制作
1.1 首先创建存放分类数据的文件夹-my_dataset

1.2 然后在其文件夹分别创建train、val两个子文件夹

1.3 train和val文件夹下存放各个类别的缺陷图像
2.检测数据集制作
path: D:\BaiduPan\labelmeCatAndDog
train: images/train
val: images/val
names:
0: dog
1: cat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# -*- coding: utf-8 -*- import os import numpy as np import json from glob import glob import cv2 import shutil import yaml from sklearn.model_selection import train_test_split from tqdm import tqdm from PIL import Image ''' 统一图像格式 ''' def change_image_format(label_path, suffix='.jpg'): """ 统一当前文件夹下所有图像的格式,如'.jpg' :param suffix: 图像文件后缀 :param label_path:当前文件路径 :return: """ externs = ['png', 'jpg', 'JPEG', 'BMP', 'bmp'] files = list() # 获取尾缀在ecterns中的所有图像 for extern in externs: files.extend(glob(label_path + "\\*." + extern)) # 遍历所有图像,转换图像格式 for index,file in enumerate(tqdm(files)): name = ''.join(file.split('.')[:-1]) file_suffix = file.split('.')[-1] if file_suffix != suffix.split('.')[-1]: # 重命名为jpg new_name = name + suffix # 读取图像 image = Image.open(file) image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR) # 重新存图为jpg格式 cv2.imwrite(new_name, image) # 删除旧图像 os.remove(file) ''' 读取所有json文件,获取所有的类别 ''' def get_all_class(file_list, label_path): """ 从json文件中获取当前数据的所有类别 :param file_list:当前路径下的所有文件名 :param label_path:当前文件路径 :return: """ # 初始化类别列表 classes = list() # 遍历所有json,读取shape中的label值内容,添加到classes for filename in tqdm(file_list): json_path = os.path.join(label_path, filename + '.json') json_file = json.load(open(json_path, "r", encoding="utf-8")) for item in json_file["shapes"]: label_class = item['label'] if label_class not in classes: classes.append(label_class) print('read file done') return classes ''' 划分训练集、验证机、测试集 ''' def split_dataset(label_path, test_size=0.3, isUseTest=False, useNumpyShuffle=False): """ 将文件分为训练集,测试集和验证集 :param useNumpyShuffle: 使用numpy方法分割数据集 :param test_size: 分割测试集或验证集的比例 :param isUseTest: 是否使用测试集,默认为False :param label_path:当前文件路径 :return: """ # 获取所有json files = glob(label_path + "\\*.json") files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files] if useNumpyShuffle: file_length = len(files) index = np.arange(file_length) np.random.seed(32) np.random.shuffle(index) # 随机划分 test_files = None # 是否有测试集 if isUseTest: trainval_files, test_files = np.array(files)[index[:int(file_length * (1 - test_size))]], np.array(files)[ index[int(file_length * (1 - test_size)):]] else: trainval_files = files # 划分训练集和测试集 train_files, val_files = np.array(trainval_files)[index[:int(len(trainval_files) * (1 - test_size))]], \ np.array(trainval_files)[index[int(len(trainval_files) * (1 - test_size)):]] else: test_files = None if isUseTest: trainval_files, test_files = train_test_split(files, test_size=test_size, random_state=55) else: trainval_files = files train_files, val_files = train_test_split(trainval_files, test_size=test_size, random_state=55) return train_files, val_files, test_files, files ''' 生成yolov5的训练、验证、测试集的文件夹 ''' def create_save_file(ROOT_DIR): print('step6:生成yolov5的训练、验证、测试集的文件夹') # 生成训练集 train_image = os.path.join(ROOT_DIR, 'images','train') if not os.path.exists(train_image): os.makedirs(train_image) train_label = os.path.join(ROOT_DIR, 'labels','train') if not os.path.exists(train_label): os.makedirs(train_label) # 生成验证集 val_image = os.path.join(ROOT_DIR, 'images', 'val') if not os.path.exists(val_image): os.makedirs(val_image) val_label = os.path.join(ROOT_DIR, 'labels', 'val') if not os.path.exists(val_label): os.makedirs(val_label) # 生成测试集 test_image = os.path.join(ROOT_DIR, 'images', 'test') if not os.path.exists(test_image): os.makedirs(test_image) test_label = os.path.join(ROOT_DIR, 'labels', 'test') if not os.path.exists(test_label): os.makedirs(test_label) return train_image, train_label, val_image, val_label, test_image, test_label ''' 转换,根据图像大小,返回box框的中点和高宽信息 ''' def convert(size, box): # 宽 dw = 1. / (size[0]) # 高 dh = 1. / (size[1]) x = (box[0] + box[1]) / 2.0 - 1 y = (box[2] + box[3]) / 2.0 - 1 # 宽 w = box[1] - box[0] # 高 h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return x, y, w, h ''' 移动图像和标注文件到指定的训练集、验证集和测试集中 ''' def push_into_file(file, images, labels, ROOT_DIR, suffix='.jpg'): """ 最终生成在当前文件夹下的所有文件按image和label分别存在到训练集/验证集/测试集路径的文件夹下 :param file: 文件名列表 :param images: 存放images的路径 :param labels: 存放labels的路径 :param label_path: 当前文件路径 :param suffix: 图像文件后缀 :return: """ # 遍历所有文件 for filename in tqdm(file): # 图像文件 image_file = os.path.join(ROOT_DIR, filename + suffix) # 标注文件 label_file = os.path.join(ROOT_DIR, filename + '.txt') # yolov5存放图像文件夹 if not os.path.exists(os.path.join(images, filename + suffix)): try: shutil.move(image_file, images) except OSError: pass # yolov5存放标注文件夹 if not os.path.exists(os.path.join(labels, filename + suffix)): try: shutil.move(label_file, labels) except OSError: pass ''' ''' def json2txt(classes, txt_Name='allfiles', ROOT_DIR="", suffix='.jpg'): """ 将json文件转化为txt文件,并将json文件存放到指定文件夹 :param classes: 类别名 :param txt_Name:txt文件,用来存放所有文件的路径 :param label_path:当前文件路径 :param suffix:图像文件后缀 :return: """ store_json = os.path.join(ROOT_DIR, 'json') if not os.path.exists(store_json): os.makedirs(store_json) _, _, _, files = split_dataset(ROOT_DIR) if not os.path.exists(os.path.join(ROOT_DIR, 'tmp')): os.makedirs(os.path.join(ROOT_DIR, 'tmp')) list_file = open(os.path.join(ROOT_DIR,'tmp/%s.txt'% txt_Name) , 'w') for json_file_ in tqdm(files): # json路径 json_filename = os.path.join(ROOT_DIR, json_file_ + ".json") # 图像路径 imagePath = os.path.join(ROOT_DIR, json_file_ + suffix) # 写入图像文件夹路径 list_file.write('%s\n' % imagePath) # 转换后txt标签文件夹路径 out_file = open('%s/%s.txt' % (ROOT_DIR, json_file_), 'w') # 加载标签json文件 json_file = json.load(open(json_filename, "r", encoding="utf-8")) ''' 核心:标签转换(json转txt) ''' if os.path.exists(imagePath): height, width, channels = cv2.imread(imagePath).shape for multi in json_file["shapes"]: if len(multi["points"][0]) == 0: out_file.write('') continue points = np.array(multi["points"]) xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0 xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0 ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0 ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0 label = multi["label"] if xmax <= xmin: pass elif ymax <= ymin: pass else: cls_id = classes.index(label) b = (float(xmin), float(xmax), float(ymin), float(ymax)) bb = convert((width, height), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') # print(json_filename, xmin, ymin, xmax, ymax, cls_id) if not os.path.exists(os.path.join(store_json, json_file_ + '.json')): try: shutil.move(json_filename, store_json) except OSError: pass ''' 创建yaml文件 ''' def create_yaml(classes, ROOT_DIR, isUseTest=False,dataYamlName=""): print('step5:创建yolov5训练所需的yaml文件') classes_dict = {} for index, item in enumerate(classes): classes_dict[index] = item if not isUseTest: desired_caps = { 'path': ROOT_DIR, 'train': 'images/train', 'val': 'images/val', 'names': classes_dict } else: desired_caps = { 'path': ROOT_DIR, 'train': 'images/train', 'val': 'images/val', 'test': 'images/test', 'names': classes_dict } yamlpath = os.path.join(ROOT_DIR, dataYamlName + ".yaml") # 写入到yaml文件 with open(yamlpath, "w+", encoding="utf-8") as f: for key, val in desired_caps.items(): yaml.dump({key: val}, f, default_flow_style=False) # 首先确保当前文件夹下的所有图片统一后缀,如.jpg,如果为其他后缀,将suffix改为对应的后缀,如.png def ChangeToYoloDet(ROOT_DIR="", suffix='.bmp',classes="", test_size=0.1, isUseTest=False,useNumpyShuffle=False,auto_genClasses = False,dataYamlName=""): """ 生成最终标准格式的文件 :param test_size: 分割测试集或验证集的比例 :param label_path:当前文件路径 :param suffix: 文件后缀名 :param isUseTest: 是否使用测试集 :return: """ # step1:统一图像格式 change_image_format(ROOT_DIR) # step2:根据json文件划分训练集、验证集、测试集 train_files, val_files, test_file, files = split_dataset(ROOT_DIR, test_size=test_size, isUseTest=isUseTest) # step3:根据json文件,获取所有类别 classes = classes # 是否自动从数据集中获取类别数 if auto_genClasses: classes = get_all_class(files, ROOT_DIR) ''' step4:(***核心***)将json文件转化为txt文件,并将json文件存放到指定文件夹 ''' json2txt(classes, txt_Name='allfiles', ROOT_DIR=ROOT_DIR, suffix=suffix) # step5:创建yolov5训练所需的yaml文件 create_yaml(classes, ROOT_DIR, isUseTest=isUseTest,dataYamlName=dataYamlName) # step6:生成yolov5的训练、验证、测试集的文件夹 train_image_dir, train_label_dir, val_image_dir, val_label_dir, test_image_dir, test_label_dir = create_save_file(ROOT_DIR) # step7:将所有图像和标注文件,移动到对应的训练集、验证集、测试集 # 将文件移动到训练集文件中 push_into_file(train_files, train_image_dir, train_label_dir,ROOT_DIR=ROOT_DIR, suffix=suffix) # 将文件移动到验证集文件夹中 push_into_file(val_files, val_image_dir, val_label_dir,ROOT_DIR=ROOT_DIR, suffix=suffix) # 如果测试集存在,则将文件移动到测试集文件中 if test_file is not None: push_into_file(test_file, test_image_dir, test_label_dir, ROOT_DIR=ROOT_DIR, suffix=suffix) print('create dataset done') if __name__ == "__main__": ''' 1.ROOT_DIR:图像和json标签的路径 2.suffix:统一图像尾缀 3.classes=['dog', 'cat'], # 输入你标注的列表里的名称(注意区分大小写),用于自定义类别名称和id对应 4.test_size:测试集和验证集所占比例 5.isUseTest:是否启用测试集 6.useNumpyShuffle:是否随机打乱 7.auto_genClasses:是否自动根据json标签生成类别列表 8.dataYamlName:数据集yaml文件名称 ''' ChangeToYoloDet( ROOT_DIR = r'D:\BaiduPan\labelmeCatAndDog', # 注意数据集路径不要含中文 suffix='.jpg', # 确定图像尾缀,用于统一图像尾缀 classes=['dog', 'cat'], # 输入你标注的列表里的名称(注意区分大小写) test_size=0.1, # 测试集大小占比 isUseTest=False, # 是否启用测试集 useNumpyShuffle=False, # 是否乱序 auto_genClasses = False, # 是否根据数据集自动生成类别id dataYamlName= "catAndDog_data" # 数据集yaml文件名称 )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
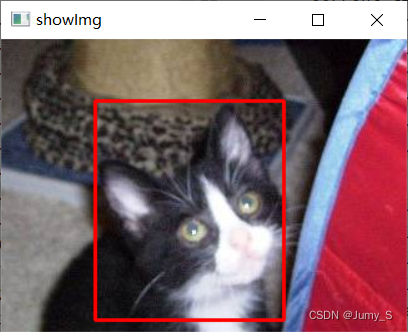
验证是否转换正确
import numpy as np import cv2 # 读取标签 label_path = r"D:\BaiduPan\labelmeCatAndDog\labels\val\8.txt" # 读取图像 img = cv2.imread(r'D:\YoloV8Manual\dataset\DogCat-det\images\val\8.jpg') height, width, channels = img.shape with open(label_path,'r') as f: current_line = f.readline() while current_line: temp_list = current_line.split(' ') x = int(float(temp_list[1])*width) y = int(float(temp_list[2])*height) w = int(float(temp_list[3])*width) h = int(float(temp_list[4])*height) x1 = int(x-w/2) y1 = int(y-h/2) x2 = int(x+w/2) y2 = int(x+h/2) cv2.rectangle(img, (x1, y1), (x2,y2), (0, 0, 255), 2 ) current_line = f.readline() winname = 'showImg' cv2.namedWindow(winname) cv2.imshow(winname, img) cv2.waitKey(0) cv2.destroyWindow(winname) # 保存图像 cv2.imwrite('test.jpg',img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
3.分割数据集制作
path: D:\datasets\DogCat-seg # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Classes
names:
0: dog
1: cat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
# -*- coding: utf-8 -*- import os import numpy as np import json from glob import glob import cv2 import shutil import yaml from sklearn.model_selection import train_test_split from tqdm import tqdm from PIL import Image ''' 辅助函数 ''' ''' 转换,根据图像大小,返回box框的中点和高宽信息 ''' def convert(size, points): # 转换后的返回列表 converted_points_list = [] # 宽 dw = 1. / (size[0]) # 高 dh = 1. / (size[1]) for point in points: x = point[0] * dw converted_points_list.append(x) y = point[1] * dh converted_points_list.append(y) return converted_points_list ''' # step1:统一图像格式 ''' def change_image_format(label_path, suffix='.jpg'): """ 统一当前文件夹下所有图像的格式,如'.jpg' :param suffix: 图像文件后缀 :param label_path:当前文件路径 :return: """ print("step1:统一图像格式") # 修改尾缀列表 externs = ['png', 'jpg', 'JPEG', 'bmp'] files = list() # 获取尾缀在externs中的所有图像 for extern in externs: files.extend(glob(label_path + "\\*." + extern)) # 遍历所有图像,转换图像格式 for index,file in enumerate(tqdm(files)): name = ''.join(file.split('.')[:-1]) file_suffix = file.split('.')[-1] if file_suffix != suffix.split('.')[-1]: # 重命名为jpg new_name = name + suffix # 读取图像 image = Image.open(file) image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR) # 重新存图为jpg格式 cv2.imwrite(new_name, image) # 删除旧图像 os.remove(file) ''' # step2:根据json文件划分训练集、验证集、测试集 ''' def split_dataset(ROOT_DIR, test_size=0.3, isUseTest=False, useNumpyShuffle=False): """ 将文件分为训练集,测试集和验证集 :param useNumpyShuffle: 使用numpy方法分割数据集 :param test_size: 分割测试集或验证集的比例 :param isUseTest: 是否使用测试集,默认为False :param label_path:当前文件路径 :return: """ # 获取所有json print('step2:根据json文件划分训练集、验证集、测试集') # 获取所有json文件路径 files = glob(ROOT_DIR + "\\*.json") # 转换为json名称 files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files] # 是否打乱 if useNumpyShuffle: file_length = len(files) index = np.arange(file_length) np.random.seed(32) np.random.shuffle(index) # 随机划分 test_files = None # 是否有测试集 if isUseTest: trainval_files, test_files = np.array(files)[index[:int(file_length * (1 - test_size))]], np.array(files)[ index[int(file_length * (1 - test_size)):]] else: trainval_files = files # 划分训练集和测试集 train_files, val_files = np.array(trainval_files)[index[:int(len(trainval_files) * (1 - test_size))]], \ np.array(trainval_files)[index[int(len(trainval_files) * (1 - test_size)):]] else: test_files = None # 判断是否启用测试集 if isUseTest: trainval_files, test_files = train_test_split(files, test_size=test_size, random_state=55) else: trainval_files = files if len(trainval_files) != 0: # 划分训练集和验证集 train_files, val_files = train_test_split(trainval_files, test_size=test_size, random_state=55) else: print("数据文件为空") return train_files, val_files, test_files, files ''' # step3:根据json文件,获取所有类别 ''' def get_all_class(file_list, ROOT_DIR): """ 从json文件中获取当前数据的所有类别 :param file_list:当前路径下的所有文件名 :param label_path:当前文件路径 :return: """ print('step3:根据json文件,获取所有类别') # 初始化类别列表 classes = list() # 遍历所有json,读取shape中的label值内容,添加到classes for filename in tqdm(file_list): json_path = os.path.join(ROOT_DIR, filename + '.json') json_file = json.load(open(json_path, "r", encoding="utf-8")) for item in json_file["shapes"]: label_class = item['label'] # 如果没有添加新的类型,则 if label_class not in classes: classes.append(label_class) print('read file done') return classes ''' # step4:将json文件转化为txt文件,并将json文件存放到指定文件夹 ''' def json2txt(classes, txt_Name='allfiles', ROOT_DIR="", suffix='.jpg'): """ 将json文件转化为txt文件,并将json文件存放到指定文件夹 :param classes: 类别名 :param txt_Name:txt文件,用来存放所有文件的路径 :param label_path:当前文件路径 :param suffix:图像文件后缀 :return: """ print('step4:将json文件转化为txt文件,并将json文件存放到指定文件夹') store_json = os.path.join(ROOT_DIR, 'json') if not os.path.exists(store_json): os.makedirs(store_json) _, _, _, files = split_dataset(ROOT_DIR) if not os.path.exists(os.path.join(ROOT_DIR, 'tmp')): os.makedirs(os.path.join(ROOT_DIR, 'tmp')) list_file = open(os.path.join(ROOT_DIR,'tmp/%s.txt'% txt_Name) , 'w') for json_file_ in tqdm(files): # json路径 json_filename = os.path.join(ROOT_DIR, json_file_ + ".json") # 图像路径 imagePath = os.path.join(ROOT_DIR, json_file_ + suffix) # 写入图像文件夹路径 list_file.write('%s\n' % imagePath) # 转换后txt标签文件夹路径 out_file = open('%s/%s.txt' % (ROOT_DIR, json_file_), 'w') # 加载标签json文件 json_file = json.load(open(json_filename, "r", encoding="utf-8")) ''' 核心:标签转换(json转txt) ''' if os.path.exists(imagePath): # 读取图像 image = Image.open(imagePath) image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR) # 获取图像高、宽、通道 height, width, channels = image.shape # 获取shapes的Value值 for multi in json_file["shapes"]: # 如果点位为空 if len(multi["points"][0]) == 0: out_file.write('') continue # 获取单个缺陷的点位(x,y的list) points = np.array(multi["points"]) # 标签 label = multi["label"] # 类别id cls_id = classes.index(label) # 根据图像大小,返回box框的中点和高宽信息 xy_list = convert((width, height), points) # 写txt标签文件 out_file.write(str(cls_id) + " " + " ".join([str(xy) for xy in xy_list]) + '\n') if not os.path.exists(os.path.join(store_json, json_file_ + '.json')): try: shutil.move(json_filename, store_json) except OSError: pass ''' # step5:创建yolov5训练所需的yaml文件 ''' def create_yaml(classes, ROOT_DIR, isUseTest=False,dataYamlName=""): print('step5:创建yolov5训练所需的yaml文件') classes_dict = {} for index, item in enumerate(classes): classes_dict[index] = item if not isUseTest: desired_caps = { 'path': ROOT_DIR, 'train': 'images/train', 'val': 'images/val', 'names': classes_dict } else: desired_caps = { 'path': ROOT_DIR, 'train': 'images/train', 'val': 'images/val', 'test': 'images/test', 'names': classes_dict } yamlpath = os.path.join(ROOT_DIR, dataYamlName + ".yaml") # 写入到yaml文件 with open(yamlpath, "w+", encoding="utf-8") as f: for key, val in desired_caps.items(): yaml.dump({key: val}, f, default_flow_style=False) ''' # step6:生成yolov5的训练、验证、测试集的文件夹 ''' def create_save_file(ROOT_DIR): """ 按照训练时的图像和标注路径创建文件夹 :param label_path:当前文件路径 :return: """ print('step6:生成yolov5的训练、验证、测试集的文件夹') # 生成训练集 train_image = os.path.join(ROOT_DIR, 'images','train') if not os.path.exists(train_image): os.makedirs(train_image) train_label = os.path.join(ROOT_DIR, 'labels','train') if not os.path.exists(train_label): os.makedirs(train_label) # 生成验证集 val_image = os.path.join(ROOT_DIR, 'images', 'val') if not os.path.exists(val_image): os.makedirs(val_image) val_label = os.path.join(ROOT_DIR, 'labels', 'val') if not os.path.exists(val_label): os.makedirs(val_label) # 生成测试集 test_image = os.path.join(ROOT_DIR, 'images', 'test') if not os.path.exists(test_image): os.makedirs(test_image) test_label = os.path.join(ROOT_DIR, 'labels', 'test') if not os.path.exists(test_label): os.makedirs(test_label) return train_image, train_label, val_image, val_label, test_image, test_label ''' # step7:将所有图像和标注文件,移动到对应的训练集、验证集、测试集 ''' def push_into_file(file, images, labels, ROOT_DIR, suffix='.jpg'): """ 最终生成在当前文件夹下的所有文件按image和label分别存在到训练集/验证集/测试集路径的文件夹下 :param file: 文件名列表 :param images: 存放images的路径 :param labels: 存放labels的路径 :param label_path: 当前文件路径 :param suffix: 图像文件后缀 :return: """ print('step7:将所有图像和标注文件,移动到对应的训练集、验证集、测试集') # 遍历所有文件 for filename in tqdm(file): # 图像文件 image_file = os.path.join(ROOT_DIR, filename + suffix) # 标注文件 label_file = os.path.join(ROOT_DIR, filename + '.txt') # yolov5存放图像文件夹 if not os.path.exists(os.path.join(images, filename + suffix)): try: shutil.move(image_file, images) except OSError: pass # yolov5存放标注文件夹 if not os.path.exists(os.path.join(labels, filename + suffix)): try: shutil.move(label_file, labels) except OSError: pass ''' labelme的json标签转yolo的txt标签 ''' def ChangeToYolo(ROOT_DIR="", suffix='.bmp',classes="", test_size=0.1, isUseTest=False,useNumpyShuffle=False,auto_genClasses = False,dataYamlName=""): """ 生成最终标准格式的文件 :param test_size: 分割测试集或验证集的比例 :param label_path:当前文件路径 :param suffix: 文件后缀名 :param isUseTest: 是否使用测试集 :return: """ # step1:统一图像格式 change_image_format(ROOT_DIR, suffix=suffix) # step2:根据json文件划分训练集、验证集、测试集 train_files, val_files, test_file, files = split_dataset(ROOT_DIR, test_size=test_size, isUseTest=isUseTest, useNumpyShuffle=useNumpyShuffle) # step3:根据json文件,获取所有类别 classes = classes # 是否自动从数据集中获取类别数 if auto_genClasses: classes = get_all_class(files, ROOT_DIR) ''' step4:(***核心***)将json文件转化为txt文件,并将json文件存放到指定文件夹 ''' json2txt(classes, txt_Name='allfiles', ROOT_DIR=ROOT_DIR, suffix=suffix) # step5:创建yolov5训练所需的yaml文件 create_yaml(classes, ROOT_DIR, isUseTest=isUseTest,dataYamlName=dataYamlName) # step6:生成yolov5的训练、验证、测试集的文件夹 train_image_dir, train_label_dir, val_image_dir, val_label_dir, test_image_dir, test_label_dir = create_save_file(ROOT_DIR) # step7:将所有图像和标注文件,移动到对应的训练集、验证集、测试集file, images, labels, ROOT_DIR, suffix='.jpg' # 将文件移动到训练集文件中 push_into_file(train_files, train_image_dir, train_label_dir,ROOT_DIR=ROOT_DIR, suffix=suffix) # 将文件移动到验证集文件夹中 push_into_file(val_files, val_image_dir, val_label_dir,ROOT_DIR=ROOT_DIR, suffix=suffix) # 如果测试集存在,则将文件移动到测试集文件中 if test_file is not None: push_into_file(test_file, test_image_dir, test_label_dir, ROOT_DIR=ROOT_DIR, suffix=suffix) print('create dataset done') if __name__ == "__main__": ''' 1.ROOT_DIR:图像和json标签的路径 2.suffix:统一图像尾缀 3.classes=['dog', 'cat'], # 输入你标注的列表里的名称(注意区分大小写),用于自定义类别名称和id对应 4.test_size:测试集和验证集所占比例 5.isUseTest:是否启用测试集 6.useNumpyShuffle:是否随机打乱 7.auto_genClasses:是否自动根据json标签生成类别列表 8.dataYamlName:数据集yaml文件名称 ''' ChangeToYolo( ROOT_DIR = r'D:\BaiduPan\labelmeCatAndDog', # 注意数据集路径不要含中文 suffix='.jpg', # 确定图像尾缀,用于统一图像尾缀 classes=['dog', 'cat'], # 输入你标注的列表里的名称(注意区分大小写) test_size=0.1, # 测试集大小占比 isUseTest=False, # 是否启用测试集 useNumpyShuffle=False, # 是否乱序 auto_genClasses = False, # 是否根据数据集自动生成类别id dataYamlName= "catAndDog_data" # 数据集yaml文件名称 )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
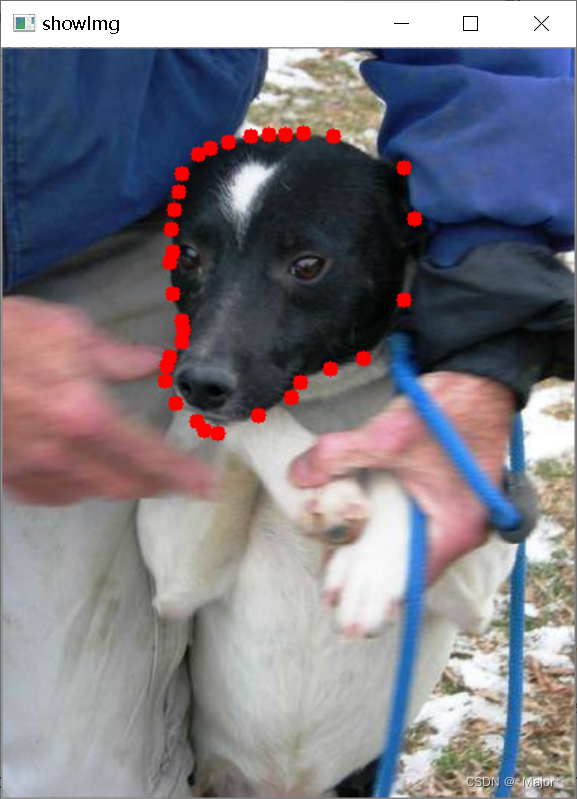
验证标注是否转换正确
showSeg.py
import numpy as np import cv2 # 读取标签 label_path = r"D:\dataset\Side_Line_Chang_DataSet\SegYolo2\labels\train\item_00000000.txt" # 读取图像 img = cv2.imread(r'D:\dataset\Side_Line_Chang_DataSet\SegYolo\train\images\item_00000000.jpg') height, width, channels = img.shape with open(label_path,'r') as f: current_line = f.readline() while current_line: temp_list = current_line.split(' ') for index in range(1,len(temp_list),2): num1 = float(temp_list[index]) num2 = float(temp_list[index+1]) # 圆点显示 cv2.circle(img,(int(width * num1), int(height * num2)), 5, (0, 0, 255), -1) current_line = f.readline() winname = 'showImg' cv2.namedWindow(winname) cv2.imshow(winname, img) cv2.waitKey(0) cv2.destroyWindow(winname) # 保存图像 cv2.imwrite('test.jpg',img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/122397
推荐阅读
相关标签

